Redis 简介
Redis 是完全开源免费的,遵守 BSD 协议,是一个高性能的 key - value 数据库
Redis 与 其他 key - value 缓存产品有以下三个特点:
Redis 支持数据持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis 不仅仅支持简单的 key - value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储
Redis 支持数据的备份,即 master - slave 模式的数据备份
Redis 优势
性能极高 – Redis 读的速度是 110000 次 /s, 写的速度是 81000 次 /s 。
丰富的数据类型 - Redis 支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子性 - Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。
其他特性 - Redis 还支持 publish/subscribe 通知,key 过期等特性。
Redis 数据类型
Redis 支持 5 中数据类型:string(字符串),hash(哈希),list(列表),set(集合),zset(sorted set:有序集合)
string
string 是 redis 最基本的数据类型。一个 key 对应一个 value。
string 是二进制安全的。也就是说 redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象。
string 类型是 redis 最基本的数据类型,string 类型的值最大能存储 512 MB。
理解:string 就像是 java 中的 map 一样,一个 key 对应一个 value
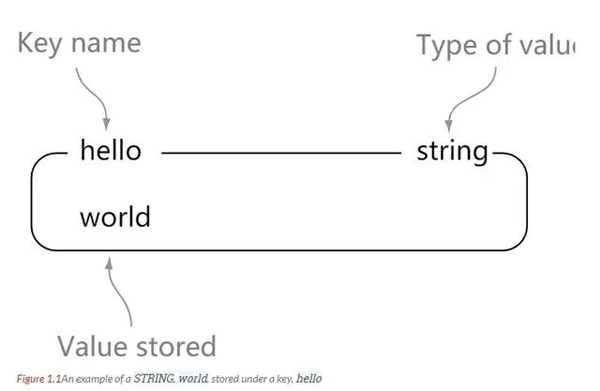
127.0.0.1:6379> set hello world OK 127.0.0.1:6379> get hello "world"
hash
Redis hash 是一个键值对(key - value)集合。Redis hash 是一个 string 类型的 key 和 value 的映射表,hash 特别适合用于存储对象。
理解:可以将 hash 看成一个 key - value 的集合。也可以将其想成一个 hash 对应着多个 string。
与 string 区别:string 是 一个 key - value 键值对,而 hash 是多个 key - value 键值对。
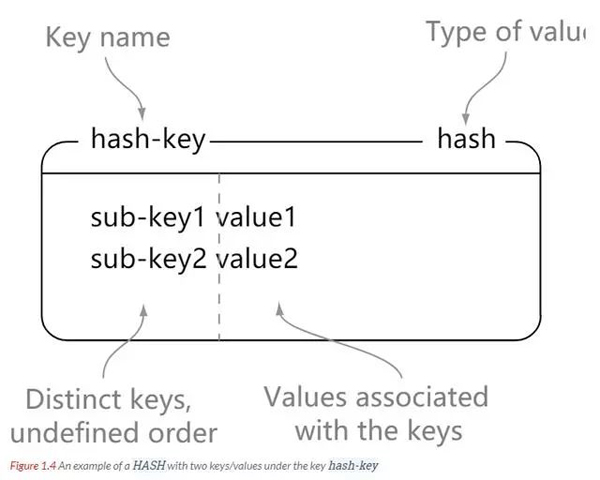
// hash-key 可以看成是一个键值对集合的名字,在这里分别为其添加了 sub-key1 : value1、 sub-key2 : value2、sub-key3 : value3 这三个键值对 127.0.0.1:6379> hset hash-key sub-key1 value1 (integer) 1 127.0.0.1:6379> hset hash-key sub-key2 value2 (integer) 1 127.0.0.1:6379> hset hash-key sub-key3 value3 (integer) 1 // 获取 hash-key 这个 hash 里面的所有键值对 127.0.0.1:6379> hgetall hash-key 1) "sub-key1" 2) "value1" 3) "sub-key2" 4) "value2" 5) "sub-key3" 6) "value3" // 删除 hash-key 这个 hash 里面的 sub-key2 键值对 127.0.0.1:6379> hdel hash-key sub-key2 (integer) 1 127.0.0.1:6379> hget hash-key sub-key2 (nil) 127.0.0.1:6379> hget hash-key sub-key1 "value1" 127.0.0.1:6379> hgetall hash-key 1) "sub-key1" 2) "value1" 3) "sub-key3" 4) "value3"
list
Redis 列表是简单的字符串列表,按照插入顺序排序。我们可以网列表的左边或者右边添加元素。
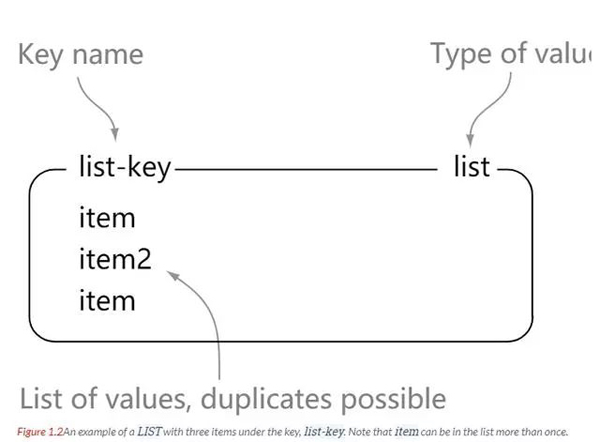
127.0.0.1:6379> rpush list-key v1 (integer) 1 127.0.0.1:6379> rpush list-key v2 (integer) 2 127.0.0.1:6379> rpush list-key v1 (integer) 3 127.0.0.1:6379> lrange list-key 0 -1 1) "v1" 2) "v2" 3) "v1" 127.0.0.1:6379> lindex list-key 1 "v2" 127.0.0.1:6379> lpop list (nil) 127.0.0.1:6379> lpop list-key "v1" 127.0.0.1:6379> lrange list-key 0 -1 1) "v2" 2) "v1"
我们可以看出 list 就是一个简单的字符串集合,和 Java 中的 list 相差不大,区别就是这里的 list 存放的是字符串。list 内的元素是可重复的。
set
redis 的 set 是字符串类型的无序集合。集合是通过哈希表实现的,因此添加、删除、查找的复杂度都是 O(1)
127.0.0.1:6379> sadd k1 v1 (integer) 1 127.0.0.1:6379> sadd k1 v2 (integer) 1 127.0.0.1:6379> sadd k1 v3 (integer) 1 127.0.0.1:6379> sadd k1 v1 (integer) 0 127.0.0.1:6379> smembers k1 1) "v3" 2) "v2" 3) "v1" 127.0.0.1:6379> 127.0.0.1:6379> sismember k1 k4 (integer) 0 127.0.0.1:6379> sismember k1 v1 (integer) 1 127.0.0.1:6379> srem k1 v2 (integer) 1 127.0.0.1:6379> srem k1 v2 (integer) 0 127.0.0.1:6379> smembers k1 1) "v3" 2) "v1"
redis 的 set 与 java 中的 set 还是有点区别的。
redis 的 set 是一个 key 对应着 多个字符串类型的 value,也是一个字符串类型的集合,但是和 redis 的 list 不同的是 set 中的字符串集合元素不能重复,但是 list 可以。
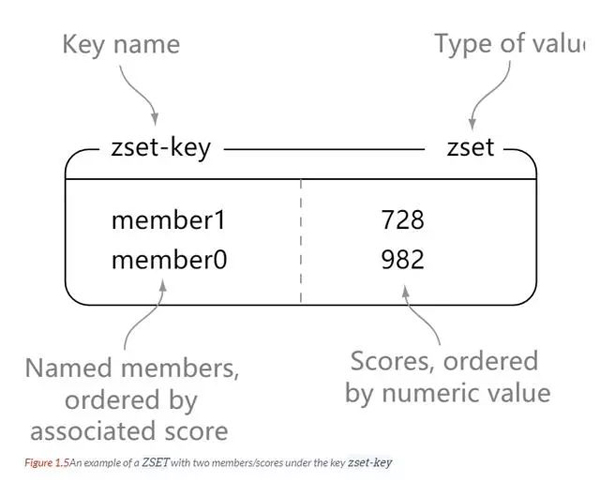
Zset
redis zset 和 set 一样都是 字符串类型元素的集合,并且集合内的元素不能重复。
不同的是,zset 每个元素都会关联一个 double 类型的分数。redis 通过分数来为集合中的成员进行从小到大的排序。
zset 的元素是唯一的,但是分数(score)却可以重复。
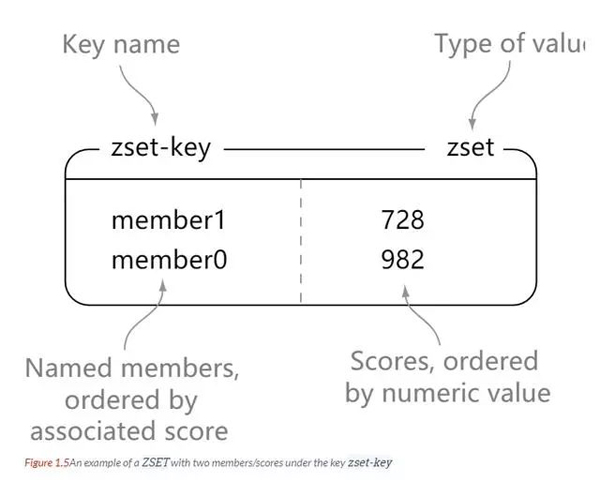
127.0.0.1:6379> zadd zset-key 728 member1 (integer) 1 127.0.0.1:6379> zadd zset-key 982 member0 (integer) 1 127.0.0.1:6379> zadd zset-key 982 member0 (integer) 0 127.0.0.1:6379> zrange zset-key 0 -1 withscores 1) "member1" 2) "728" 3) "member0" 4) "982" 127.0.0.1:6379> zrangebyscore zset-key 0 800 withscores 1) "member1" 2) "728" 127.0.0.1:6379> zrem zset-key member1 (integer) 1 127.0.0.1:6379> zrem zset-key member1 (integer) 0 127.0.0.1:6379> zrange zset-key 0 -1 withscores 1) "member0" 2) "982"
zset 是按照分数的大小来排序的。
发布订阅
一般不用 Redis 做消息发布订阅。
简介
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
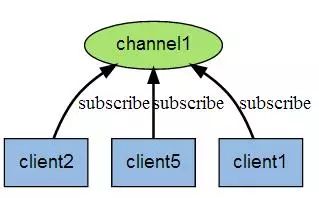
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
学Redis这篇就够了
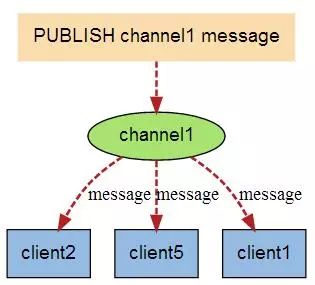
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
学Redis这篇就够了
实例
以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
127.0.0.1:6379> SUBsCRIBE redisChat Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "redisChat"
现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
127.0.0.1:6379> PUBLISH redisChat "send message" (integer) 1 127.0.0.1:6379> PUBLISH redisChat "hello world" (integer) 1 # 订阅者的客户端显示如下 1) "message" 2) "redisChat" 3) "send message" 1) "message" 2) "redisChat" 3) "hello world"
事务
redis 事务一次可以执行多条命令,服务器在执行命令期间,不会去执行其他客户端的命令请求。
事务中的多条命令被一次性发送给服务器,而不是一条一条地发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
批量操作在发送 EXEC 命令前被放入队列缓存。
收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余命令依然被执行。也就是说 Redis 事务不保证原子性。
在事务执行过程中,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
开始事务。
命令入队。
执行事务。
实例
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:
redis 127.0.0.1:6379> MULTI OK redis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days" QUEUED redis 127.0.0.1:6379> GET book-name QUEUED redis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series" QUEUED redis 127.0.0.1:6379> SMEMBERS tag QUEUED redis 127.0.0.1:6379> EXEC 1) OK 2) "Mastering C++ in 21 days" 3) (integer) 3 4) 1) "Mastering Series" 2) "C++" 3) "Programming"
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
这是官网上的说明 From redis docs on transactions:
It's important to note that even when a command fails, all the other commands in the queue are processed – Redis will not stop the processing of commands.
比如:
redis 127.0.0.1:7000> multi OK redis 127.0.0.1:7000> set a aaa QUEUED redis 127.0.0.1:7000> set b bbb QUEUED redis 127.0.0.1:7000> set c ccc QUEUED redis 127.0.0.1:7000> exec 1) OK 2) OK 3) OK
如果在 set b bbb 处失败,set a 已成功不会回滚,set c 还会继续执行。
Redis 事务命令
下表列出了 redis 事务的相关命令:
序号命令及描述:
1. DISCARD 取消事务,放弃执行事务块内的所有命令。
2. EXEC 执行所有事务块内的命令。
3. MULTI 标记一个事务块的开始。
4. UNWATCH 取消 WATCH 命令对所有 key 的监视。
5. WATCH key [key …]监视一个 (或多个) key ,如果在事务执行之前这个 (或这些) key 被其他命令所改动,那么事务将被打断。
持久化
Redis 是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。
RDB 持久化
将某个时间点的所有数据都存放到硬盘上。
可以将快照复制到其他服务器从而创建具有相同数据的服务器副本。
如果系统发生故障,将会丢失最后一次创建快照之后的数据。
如果数据量大,保存快照的时间会很长。
AOF 持久化
将写命令添加到 AOF 文件(append only file)末尾。
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。
这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。
选项同步频率always每个写命令都同步eyerysec每秒同步一次no让操作系统来决定何时同步
always 选项会严重减低服务器的性能
everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器几乎没有任何影响。
no 选项并不能给服务器性能带来多大的提升,而且会增加系统崩溃时数据丢失的数量。
随着服务器写请求的增多,AOF 文件会越来越大。Redis 提供了一种将 AOF 重写的特性,能够去除 AOF 文件中的冗余写命令。
复制
通过使用 slaveof host port 命令来让一个服务器成为另一个服务器的从服务器。
连接过程
快照文件发送完毕之后,开始像从服务器发送存储在缓冲区的写命令。
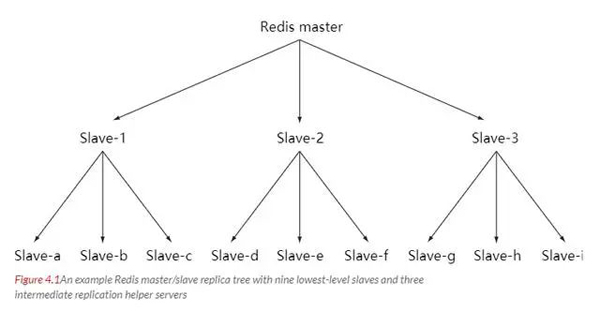
主从链
随着负载不断上升,主服务器无法很快的更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。
为了解决这个问题,可以创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。
哨兵
Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入下线状态时,自动从从服务器中选举处新的主服务器。
分片
分片是将数据划分为多个部分的方法,可以将数据存储到多台机器里面,这种方法在解决某些问题时可以获得线性级别的性能提升。
假设有 4 个 Redis 实例 R0, R1, R2, R3, 还有很多表示用户的键 user:1, user:2, … , 有不同的方式来选择一个指定的键存储在哪个实例中。
最简单的是范围分片,例如用户 id 从 0 ~ 1000 的存储到实例 R0 中,用户 id 从 1001 ~ 2000 的存储到实例 R1中,等等。但是这样需要维护一张映射范围表,维护操作代价高。
还有一种是哈希分片。使用 CRC32 哈希函数将键转换为一个数字,再对实例数量求模就能知道存储的实例。
根据执行分片的位置,可以分为三种分片方式:
客户端分片:客户端使用一致性哈希等算法决定应当分布到哪个节点。
代理分片:将客户端的请求发送到代理上,由代理转发到正确的节点上。
服务器分片:Redis Cluster。



