LLM性能最高60%提升!谷歌ICLR 2024力作:让大语言模型学会「图的语言」
 发布于2024-12-22 阅读(0)
发布于2024-12-22 阅读(0)
扫一扫,手机访问
在计算机科学领域,图形结构由节点(代表实体)和边(表示实体之间的关系)构成。
图无处不在。
互联网可以被视为一个庞大的网络,搜索引擎利用图形化的方式来组织和展示信息。
LLMs主要在常规文本上训练,因此将图转化为LLMs可理解的文本是一项具有挑战性的任务,因为图结构与文本有着根本的不同。
在ICLR 2024上,一支来自谷歌的团队探索了如何将图形数据转换为适合LLMs理解的形式。

论文地址:https://openreview.net/pdf?id=IuXR1CCrSi
使用两种不同的方法将图形编码为文本,并将文本和问题反馈给LLM的过程
他们还开发了一个名为GraphQA的基准,用于探究解决不同图推理问题的方法,并展示了如何以一种有利于LLM解决图形相关问题的方式来表达这些问题。
使用正确的方法,使得LLMs在图形任务上最高得以提升60%的性能。
GraphOA:一场对LLMs的「考试」
首先,谷歌团队设计了GraphQA基准测试,它可以被看作是一门考试,旨在评估LLM针对特定于图形问题的能力。
GraphOA通过使用多种类型的图表,确保广度和连接数量的多样性,以寻找LLMs在处理图形时可能存在的偏差情况,并使整个过程更接近LLMs在实际应用中可能遇到的情况。

使用GraphIQA对LLMs进行推理的框架
虽然任务很简单,比如检查边是否存在、计算节点或者边的数量等等,但这些任务都需要LLMs理解节点和边之间的关系,对于更复杂的图形推理至关重要。
同时,团队还探索了如何将图转换为LLMs可以处理的文本,比如解决了如下两个关键问题:
节点编码:我们如何表示单个节点?节点可以包括简单整数、常用名称(人名、字符)和字母。
边缘编码:我们如何描述节点之间的关系?方法可以包括括号符号、短语(如「是朋友」)和符号表示(如箭头)。
最终,研究人员通过系统地结合各种节点和边的编码方式,产生了像下图中展示的那些函数。

图形编码函数的例子
LLMs表现怎么样呢?
研究团队在GraphOA上进行了三个关键实验:
- 测试LLMs处理图形任务的能力
- 测试LLMs的大小对性能的影响
- 测试不同图形形状对性能的影响
在第一个实验中,LLMs表现平平,在大多数基本任务上,LLMs的表现并不比随机猜测好多少。
但编码方式显著影响结果,如下图所示,在大多数情况下,「incident」编码在大多数任务中表现出色。选择合适的编码函数可以极大的提高任务的准确度。
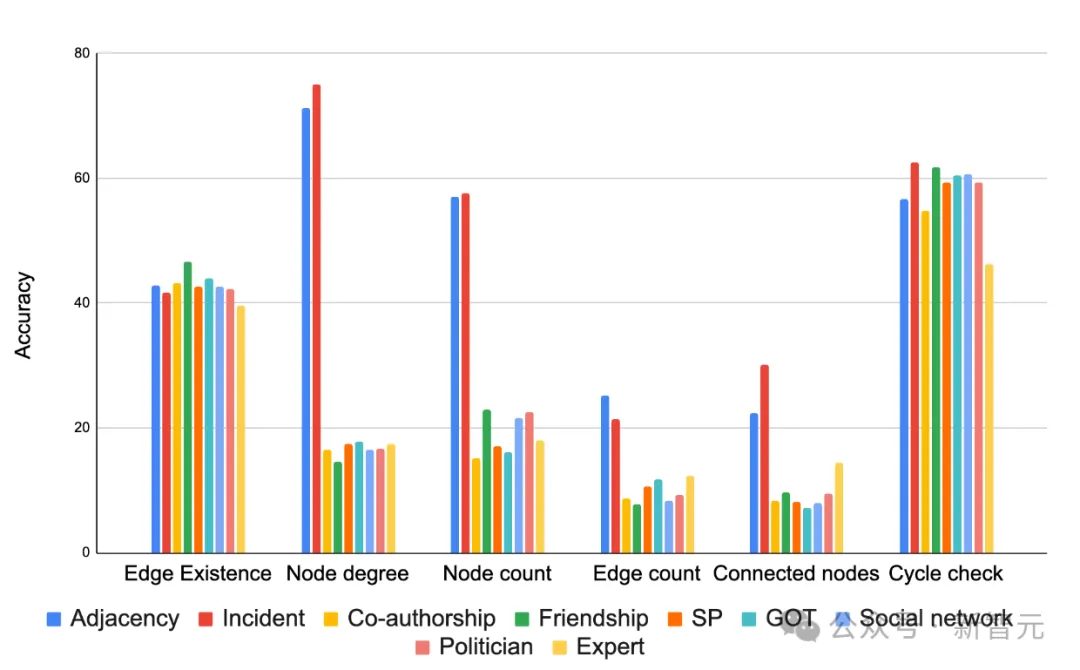
基于不同任务准确度的各种图编码器函数的比较
在第二个测试中,研究人员在不同大小的模型上测试了相同的图形任务。
就结论而言,在图形推理任务中,规模更大的模型表现更好,
然而有趣的是,在「边存在性」任务(确定图中两个节点是否相连)中,规模并不像其他任务那么重要。
即使是最大的LLM在循环检查问题上(确定图中是否存在循环)也无法始终击败简单的基线解决方案。这表明LLMs在某些图任务上仍有改进的空间。
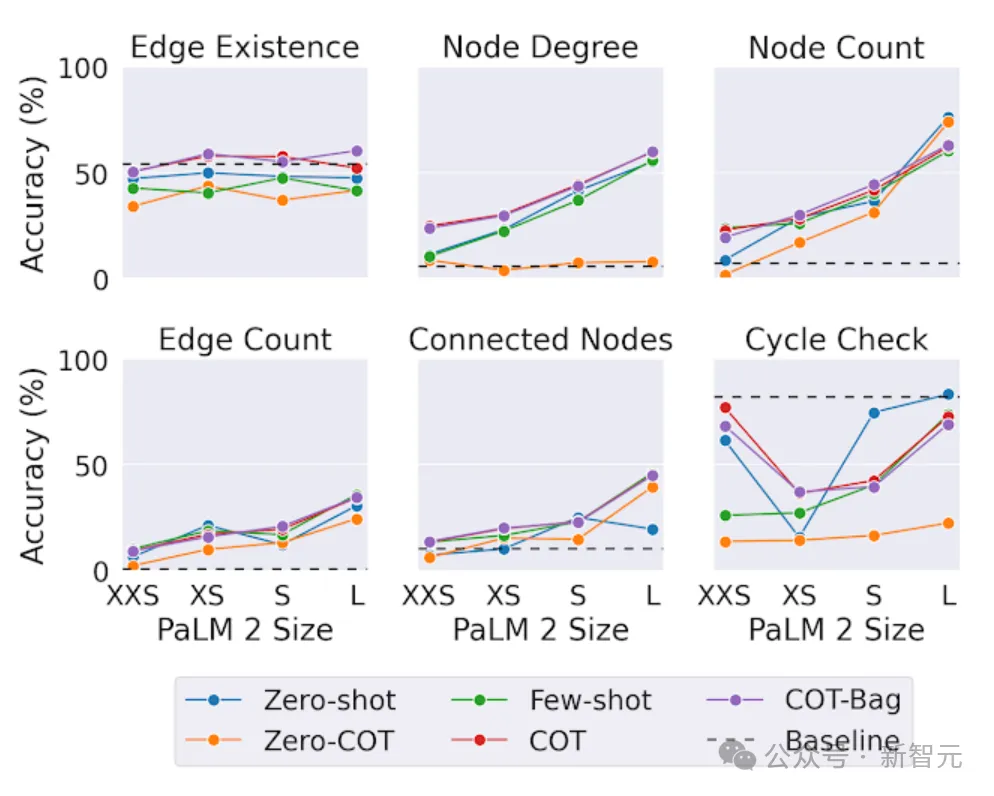
模型容量对PaLM 2-XXS、XS、S和L的图推理任务的影响
在第三个测试中,对于图形结构是否会影响LMMs解决问题的能力,研究人员通过GraphOA生成不同结构的图形进行分析。

GraphQA不同图形生成器生成的图形示例。ER、BA、SBM和SFN分别是Erdős-Rényi、Barabási-Albert、随机块模型和无标度网络。
结果得出,图的结构对LLMs的性能有很大影响。
例如,在一个询问循环是否存在的任务中,LLMs在紧密相连的图形中表现出色(这里循环很常见),但在路径图中表现不佳(循环从不发生)。
但同时提供一些混合样本有助于LLMs适应,比如在循环检测任务中,研究人员在提示中添加了一些包含循环和一些不包含循环的示例作为少样本学习的例子,通过这种方式提高了LLMs的性能。
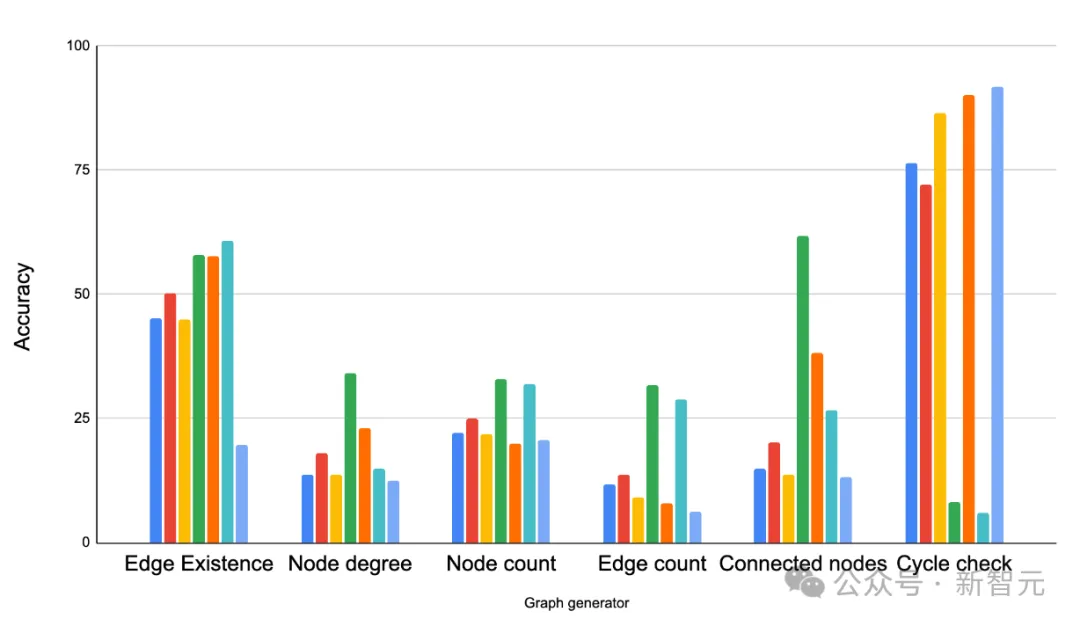
在不同的图任务上比较不同的图生成器。主要观察结果是,图结构对LLM的性能有显著影响。ER、BA、SBM和SFN分别指的是Erdős-Rényi、Barabási-Albert、随机块模型和无标度网络。
这仅仅是让LLMs理解图的开始
在论文中,谷歌团队初步探索了如何将图形最佳地表示为文本,以便LLMs能理解他们。
在正确编码技术的帮助下,显著提高了LLMs在图形问题上的准确性(从大约5%到超过60%的改进)。
同时也确定了三个主要的影响因子,分别为图形转换为文本的编码方式、不同图形的任务类型、以及图形的疏密结构。
这仅仅是让LLMs理解图的开始。在新基准测试GraphQA的帮助下,期待进一步研究,探索LLMs的更多可能性。
上一篇:PPT导出动图的操作教程
下一篇:快速启动U盘,轻松解决电脑故障
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 从300亿分子中筛出6款,结构新且易合成,斯坦福抗生素设计AI模型登Nature子刊
- 编辑|凯霞全球每年有近500万人死于抗生素耐药性,因此迫切需要新的方法来对抗耐药菌株。人工智能技术已经可以发现新的抗生素,但现有方法有明显的局限性。性质预测模型很难扩展到大型化学空间。直接设计分子的生成模型可以快速探索广阔的化学空间,但生成的分子难以组成。然而,分子生成模型的生产模型可以快速探索广阔的化学空间,但生成的分子难以组成。针对这一问题,研究人员正在直接生成可组成的分子来解决这一难题。斯坦福大学和麦克马斯特大学的研究人员发明了一种新的生成式AI模型SyntheMol,可设计数十亿种新的抗生素分子。
- 10分钟前 产业 0
-
 正版软件
正版软件
- 三星计划2025年推出microLED Galaxy Watch,成本挑战仍待解决
- 3月22日消息,三星目前仅将先进的microLED技术应用于高端大尺寸电视产品中,然而,最新传闻显示,该公司正计划将这项技术进一步拓展至其智能手表系列,即GalaxyWatch。据悉,三星设定的目标发布时间为2025年,期望能借此提升其智能手表的显示效果和用户体验。尽管三星对microLED技术的前景持乐观态度,但苹果在早前尝试将这一技术应用于手表产品时遭遇的挑战,无疑给三星的计划蒙上一层阴影。据悉,苹果曾计划在下一代AppleWatchUltra上采用microLED显示屏,但由于种种技术难题,该计划目
- 15分钟前 三星 0
-
 正版软件
正版软件
- Galaxy Watch将提供更准确的心电图测量功能,帮助用户监测心律异常
- 6月15日消息,三星电子宣布推出全新的健康监测应用——三星健康监测助手。这一应用将于今年夏天在全球范围内推出,覆盖了13个国家和地区。这些地区包括美国、韩国、阿根廷、阿塞拜疆、哥斯达黎加、多米尼加、厄瓜多尔、格鲁吉亚、危地马拉、中国香港、印度尼西亚、巴拿马和阿联酋。据小编了解,三星健康监测助手引入了心律不齐通知(IHRN)功能,以帮助用户监测心脏健康状况。通过与GalaxyWatch智能手表的生物活性传感器配合使用,该功能可以在后台检测心律异常情况。当连续多次检测到异常时,GalaxyWatch会发出警告
- 30分钟前 三星 0
-
 正版软件
正版软件
- 比亚迪驱逐舰07揭开面纱:豪华设计与智能科技完美结合!
- 6月15日消息,比亚迪的全新轿车驱逐舰07即将在7月份正式开始预售,给消费者带来全新的驾驶体验。这款车首次亮相于上海车展,引起了广泛的关注。预计驱逐舰07的售价将在20-25万元之间,并计划在今年第三季度正式上市。驱逐舰07被定位为中型轿车,整车尺寸为4980*1890*1495毫米,轴距达到了2900毫米,达到了主流B级轿车的水准。它以其海洋风的设计风格而闻名,充满力量感。前脸设计独特,凸显了其豪华气质。五根贯穿式散热口从中间向两侧延伸,搭配不规则的大灯组,使整个前脸更加凌厉有型。据了解,驱逐舰07将搭
- 45分钟前 比亚迪 0
-
 正版软件
正版软件
- iPhone销量疲软,国内市场份额持续下滑,苹果如何应对挑战?
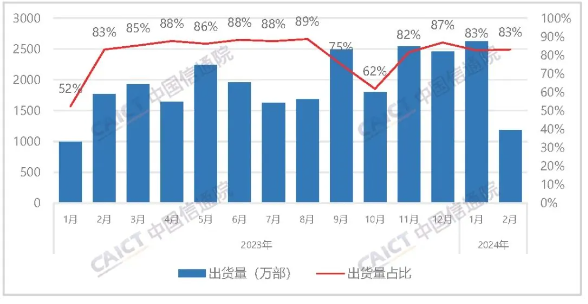
- 根据中国信息通信研究院(CAICT)最新发布的报告,显示苹果iPhone在今年1月在国内市场的出货量约为550万台,与去年同期相比减少了39%。而到了2月份,出货量继续下滑,降至约240万台,同比减少33%。这一数据反映了iPhone在中国市场面临的销售挑战,可能受到市场竞争激烈和消费者需求变化等因素的影响。随着国内手机市场的竞争日益激烈,苹果iPhone需要采取相应策略来稳定市场份额和提升销售业绩。根据彭博社的报道分析,出货量下滑的趋势似乎是从去年9月开始的。内部原因主要是iPhone销量疲软,消费者对
- 1小时前 14:15 苹果 0













