什么是生成式AI?有哪些特征类型
 发布于2024-12-22 阅读(0)
发布于2024-12-22 阅读(0)
扫一扫,手机访问
生成式AI是人类一种人工智能技术,可以生成各种类型的内容,包括文本、图像、音频和合成数据。那么什么是人工智能?人工智能和机器学习之间的区别是什么?有哪些技术特征?
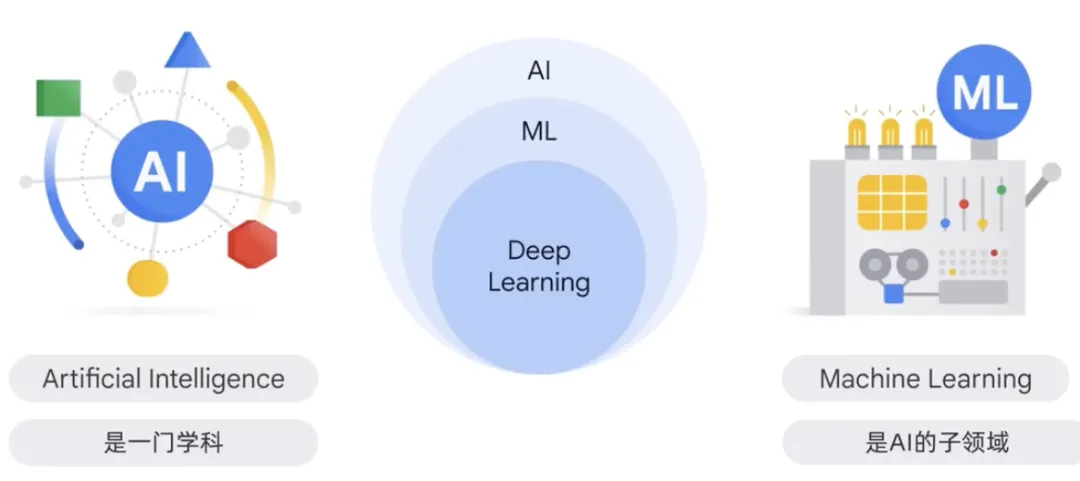
人工智能是学科,是计算机科学的一个分支,研究智能代理的创造。这些智能代理可以推理、学习和自主行动的系统。智能代理的研究是可以推理、学习和自主行动的系统的研究。
人工智能和构建像人类一样思考和行动的机器的理论和方法有关。在这个学科中,机器学习是人工智能的一个领域。它是根据输入数据训练模型的程序或系统,经过训练的模型可以从新的或未见过的数据中做出有用的预测,这些数据可以来自自己训练模型的统一数据。通过训练模型,这些数据来自于自己训练模型的统一数据,这些数据可以用于预测模型未见过的数据。这些数据来自于自己训练模型的统一数据,从而可以得到有用的预测。这种方法被广泛应用于图像、语音识别、自然语言处理等领域的问题中。
机器学习赋予计算机无需显式编程即可学习的能力。最常见的两类机器学习模型是无监督学习和监督ML模型。两者之间的主要区别在于,对于监督模型,我们有标签,标记数据是带有名称、类型或数字等标签的数据,无监督数据是没有标记的数据。
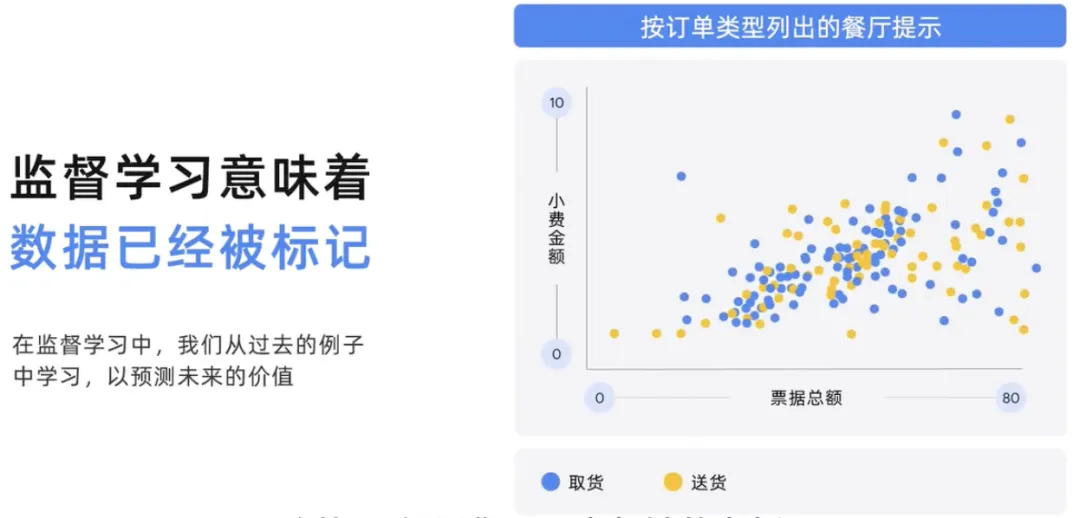
该图是监督模型可能尝试解决问题的事例。
假设您是一家餐馆的老板,您有账单金额的历史数据,根据订单类型,不同的人给了多少小费,根据订单类型是取货还是送货给了多少不同的人。在监督学习中,模型从过去的数据中学习,并预测未来的价值。因此,在这个模型中,根据订单类型,使用总账单金额来预测未来的消费金额可能是取货还是送货,以及可能给多少小费。根据过去的模型进行预测,有望准确预测即将到来的消费金额。因此,这里的模型根据订单类型,使用总账单金额来预测未来的消费金额和小费。
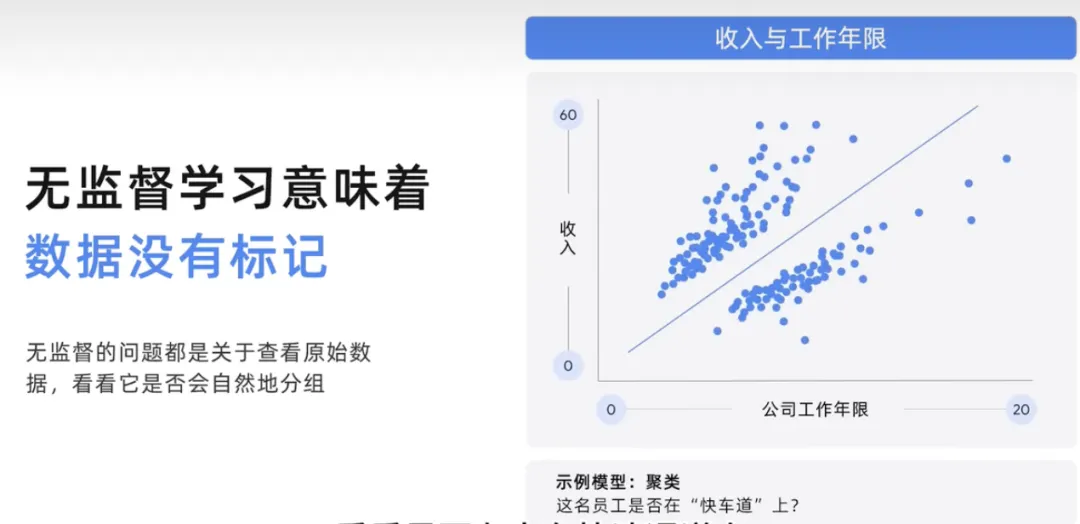
这种无监督模型可能会有助于解决问题示例,在这里需要查看任期和收入,然后将员工分组获得群组,看看是否有人在快速通道上。无监督的问题都是关于查看原始数据,并查看他是否自然分组,让我们更深入一点以图形方式展示。
上面这些概念是理解生成式AI的基础。

在监督学习中,测试数据值被输入到模型中,该模型输出预测,并将该预测与用于训练模型的训练数据进行比较。
如果预测的测试数据值和实际训练数据值相距甚远,则称为错误,且该模型会尝试减少此错误,直到预测值和实际值更接近为止。
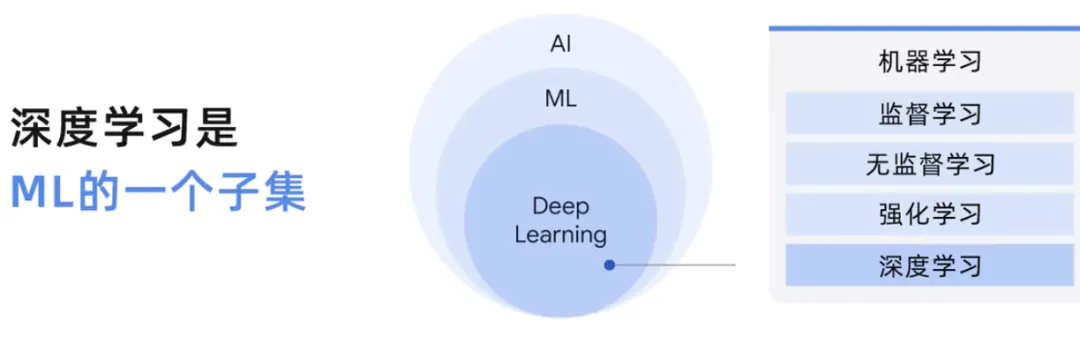
我们已经探讨了人工智能和机器学习、监督学习和无监督学习之间的区别。那么,让我们简要探讨一下深度学习的知识。
虽然机器学习是一个包含许多不同技术的广泛领域,但深度学习是一种使用人工神经网络的机器学习,允许他们处理比机器学习更复杂的模式。
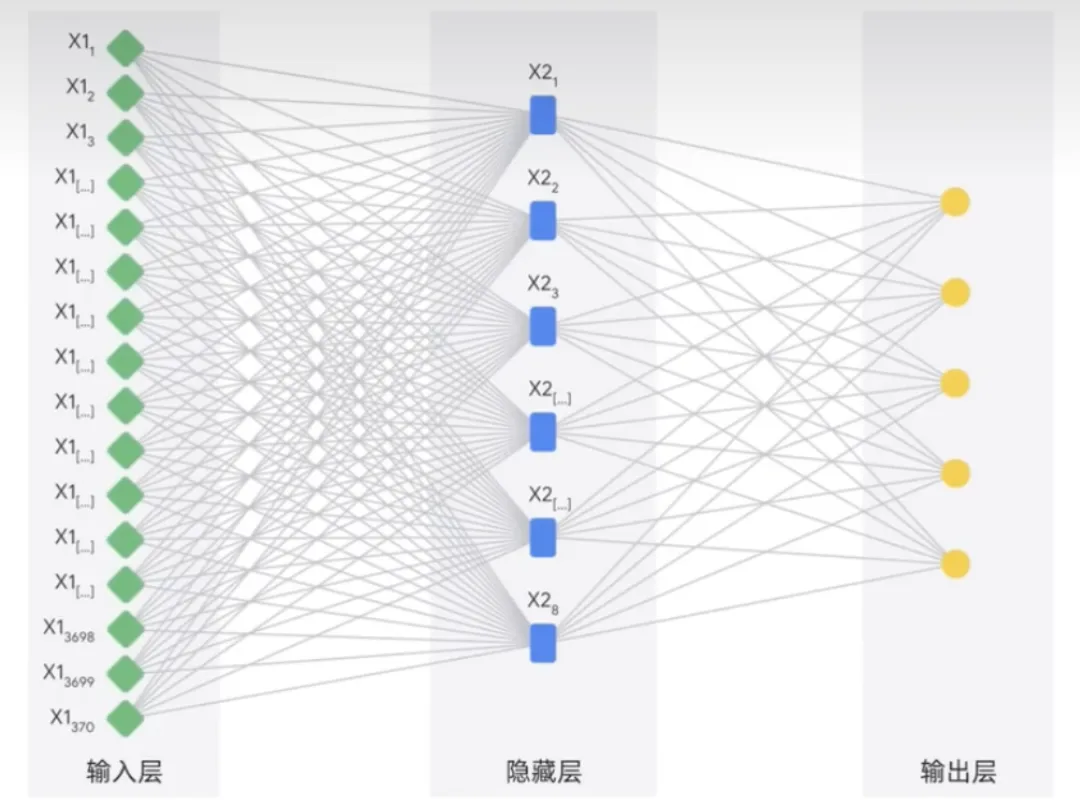
人工神经网络的灵感来自于人脑,它们有许多相互连接的节点或神经元组成,这些节点或神经元可以通过处理数据和做出预测来学习执行任务。
深度学习模型通常具有多层神经元。这使他们能够学习比传统机器学习模型更复杂的模式。神经网络可以使用标记和未标记的数据,这称为半监督学习。在半监督学习中,神经网络在少量标记数据和大量未标记数据上进行训练。标记数据有助于神经网络学习任务的基本概念。而未标记的数据有助于神经网络泛化到新的例子。
在这个人工智能学科中的地位,这意味着使用人工神经网络,可以用监督、非监督和半监督方法处理标记和未标记数据。大型语言模型也是深度学习的一个子集,深度学习模型或者一般意义上的机器学习模型。
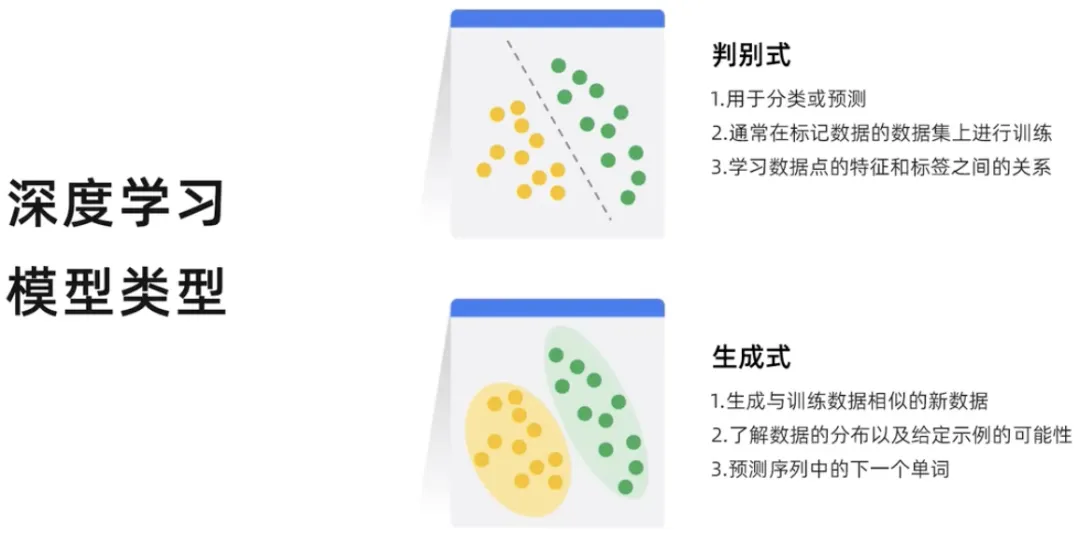
深度学习可以分为判别式和生成式两种。判别模型是一种用于分类或预测数据点标签的模型。判别模型通常在标记数据点的数据集上进行训练。他们学习数据点的特征和标签之间的关系,一旦训练了判别模型,它就可以用来预测新数据点的标签。而生成模型根据现有数据的学习概率分布生成新的数据实例,因此生成模型产出新的内容。
生成模型可以输出新的数据实例,而判别模型可以区分不同类型的数据实例。
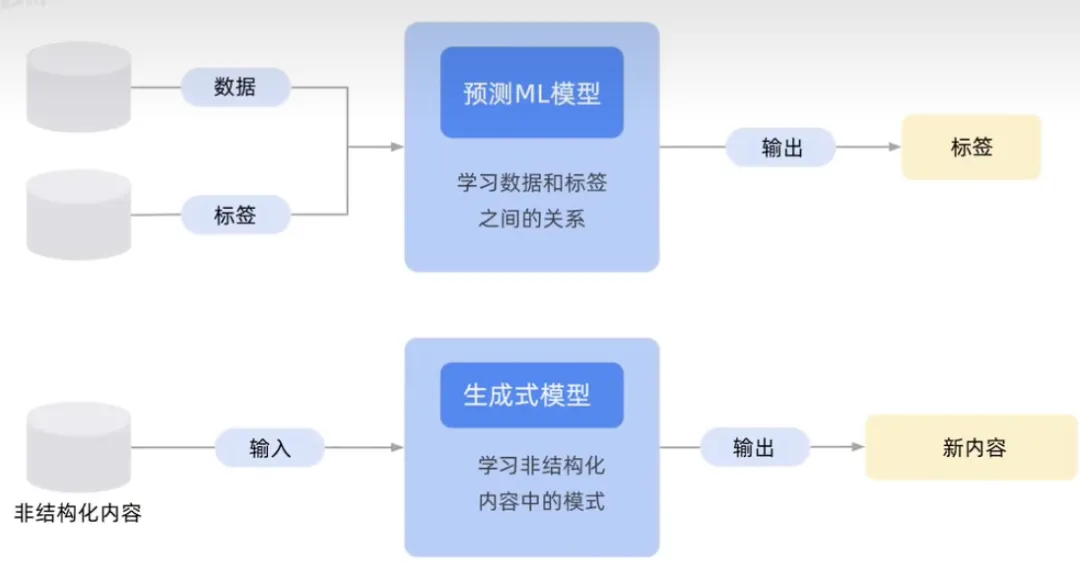
该图显示了一个传统的机器学习模型,区别在于数据和标签之间的关系 ,或者你想要预测的内容。底部图片显示了一个生成式AI模型,尝试学习内容模式,以便生成输出新内容。
当输出外标签是数字或概率时为非生成式AI,例如垃圾邮件、非垃圾邮件。当输出是自然语言为生成式AI,例如语音、文本、图像视频。
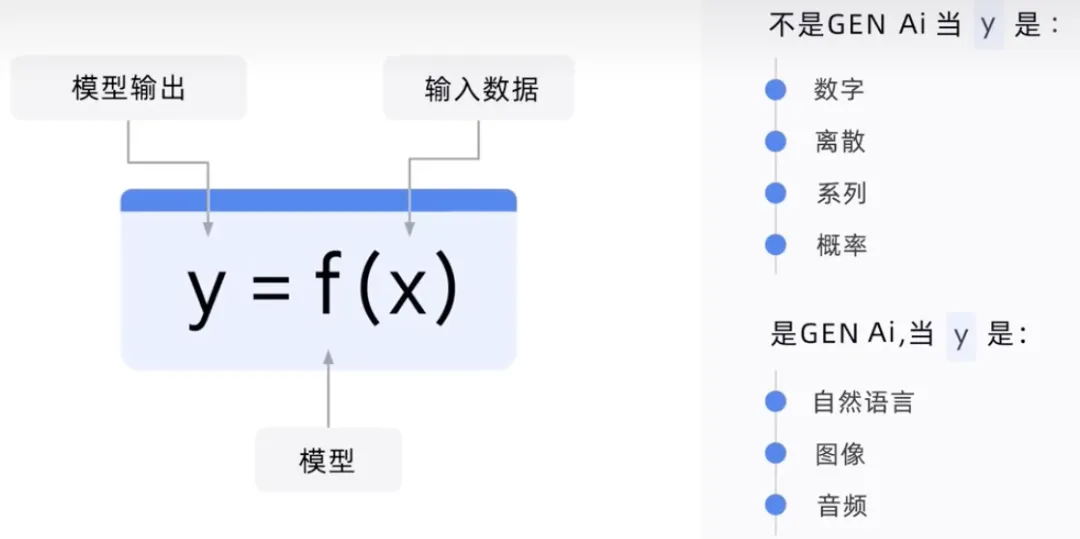
模型输出是所有输入的函数,如果Y是数字,如预测的销售额,则它不是GenAI。如果Y是一个句子,就像定义销售一样。它是生成性的,因为问题会引发文本响应。他的反应将基于该模型已经训练过的所有海量大数据。
总而言之,传统的、经典的有监督和无监督学习过程,采用训练代码和标签数据来构建模型。根据用例或问题,模型可以为你提供预测,它可以对某些东西进行分类或聚集,使用此势力展示生成该过程的稳健程度。
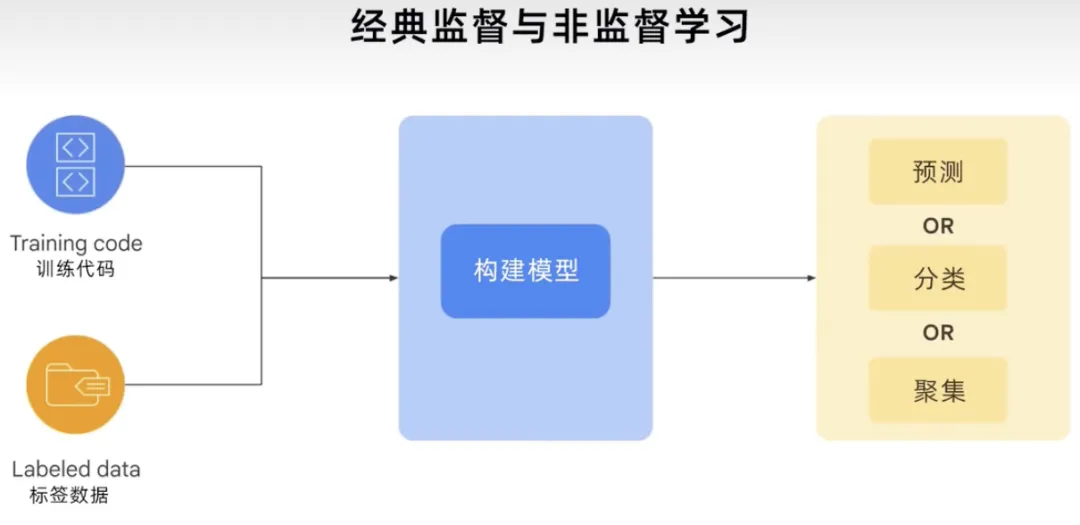
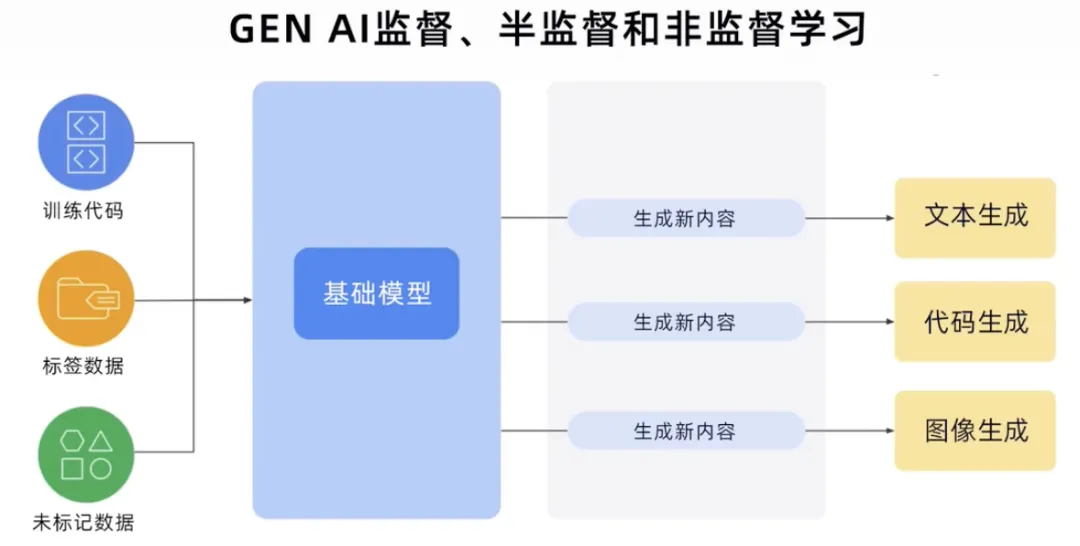
GenAI过程可以获取所有数据类型的训练代码、标签数据和未标签数据,构建基础模型,然后基础模型可以生成新内容。例如文本、代码、图像、音频、视频等。
从传统编程到神经网络,再到生成模型, 我们已经走了很长一段路。在传统的编程中,我们过去不得不编码区分猫的规则。类型是动物,腿有4条,耳朵有2个,毛皮是有的等等。
在神经网络的浪潮中,我们可以给网络提供猫和狗的图片。并询问这是一只猫。他会预测出一只猫。在生成式AI浪潮中,我们作为用户,可以生成我们自己的内容。

无论是文本、图像、音频、视频等等,例如Python语言模型或对话应用程序语言模型等模型。从互联网上的多个来源获取非常大的数据。构建可以简单的通过提问来使用的基础语言模型。所以,当你问他什么是猫时,他可以告诉你他所了解的关于猫的一切。
GenAI生成式AI是一种人工智能技术,它根据从现有内容中学到的知识来创建新内容,从现有内容中学习的过程称为训练。并在给出提示时创建统计模型,使用该模型来预测预期的响应可能是什么,并生成新的内容。
从本质上讲,它学习数据的底层结构内容,然后可生成与训练数据相似的新样本。如之前所述,生成语言模型可以利用他从展示的事例中学到的知识,并根据该信息创建全新的东西。
大型语言模型是一种生成式人工智能,因为他们以自然发音的语言形式生成新颖的文本组合,生成图像模型,将图像作为输入,并可以输出文本、另一幅图像或视频。例如,在输出文本下,你可以获得视觉问答,而在输出图像下生成图像补全,并在输出视频下生成动画。
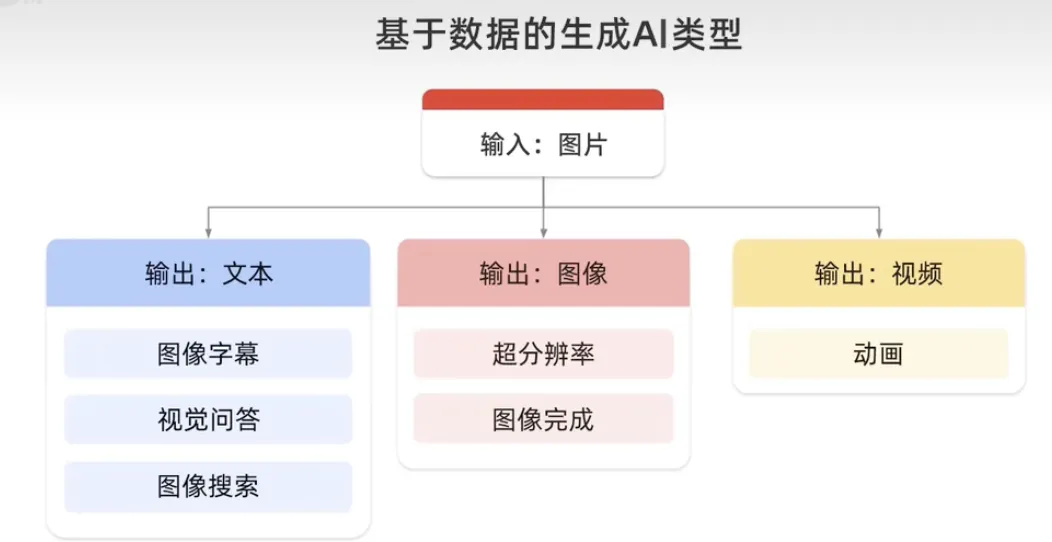
生成语言模型,以文本作为输入,可以输出更多的文本、图像、音频或决策。例如,在输出文本下生成问答,并在输出图像下生成视频。

我们已经说过,生成语言模型通过训练数据了解模式和语言,然后给定一些文本,他们会预测接下来会发生什么。
生成语言模型是模式匹配系统,他们根据您提供的数据了解模式。根据他从训练数据中学到的东西,他提供了如何完成这句话的预测。它接受了大量文本数据的训练,能够针对各种提示和问题进行交流,并生成像人类的文本。
在transformer中,Hallucin是由模型生成的单词或短语,通常是无意义的或语法错误的。幻觉可能由多种因素引起,包括模型没有在足够的数据上训练,或者模型是在嘈杂或肮脏的数据上训练的,又或者没有给模型足够的上下文,还存在,没有给模型足够的约束。

他们还可以使模型更有可能生成不正确或误导性的信息,例如杂TPT3.5有时可能生成的信息未必正确。提示词是作为输入提供给大型语言模型的一小段文本。并且它可以用于多种方式控制模型的输出。
提示设计是创建提示的过程,该提示将从大型语言模型生成所需的输出内容。如之前所述,LLM在很大程度上取决于你输入的训练数据。他分析输入数据的模式和结构,从而进行学习。但是通过访问基于浏览器的提示,用户可以生成自己的内容。

我们已经展示了基于数据的输入类型的路线图,以下是相关的模型类型。
文本到文本模型。采用自然语言输入并生成文本输出。这些模型被训练学习文本之间的映射。例如,从一种语言到另一种语言的翻译。
文本到图像模型。因为文本到图像模型是在大量图像上训练的。每个图像都带有简短的文本描述。扩散是用于实现此目的的一种方法。

文本到视频和文本到3D。文本到视频模型只在文本输入生成视频内容,输入文本可以是从单个句子到完整脚本的任何内容。输出是与输入文本相对应的视频类似的文本到3D模型生成对应于用户文本描述的三位对象。例如,这可以用于游戏或其他3D世界。
文本到任务模型。经过训练,可以根据文本输入执行定义的任务或操作。此任务可以是广泛的采取操作。例如回答问题、执行搜索、进行预测或采取某种操作,也可以训练文本到任务模型来指导外B问或通过可以更改文档。
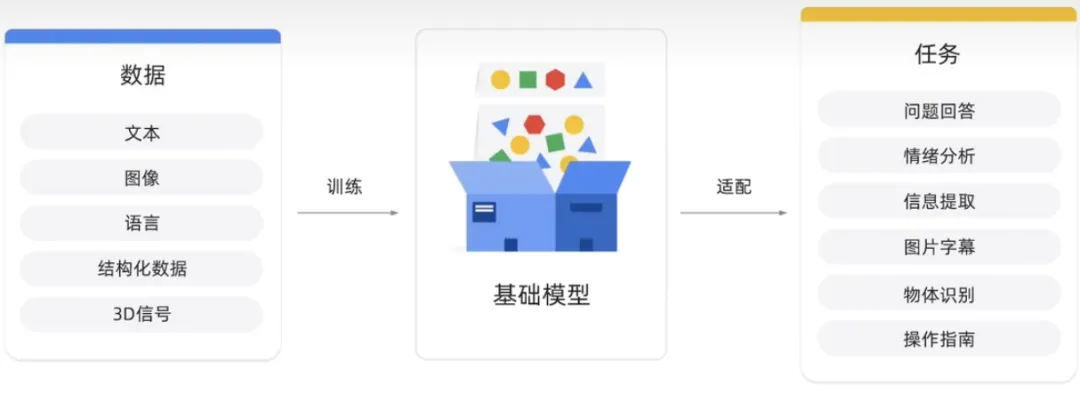
基础模型是在大量数据上进行预训练的大型AI模型。目的在适应或微调各种下游任务,例如情感分析、图像、字幕和对象识别。
基础模型有可能彻底改变许多行业,包括医疗保健、金融和客户服务等,它们可用于检测预测,并提供个性化的客户支持。OpenAI提供了一个包含基础的模型源语言,基础模型包括用于聊天和文本的。

视觉基础模型包括稳定扩散,可以有效的从文本描述生成包质量图像。假设你有一个案例,需要收集有关客户对您的产品或服务的感受。

生成式AI Studio,在开发者来看,让您无需编写任何代码即能轻松设计和构建应用程序。它有一个可视化编辑器,可以轻松创建和编辑应用程序内容。还有一个内置的搜索引擎,允许用户在应用程序内搜索信息。
还有一个对话式人工智能引擎,可以帮助用户使用自然语言与应用程序进行交互。您可以创建自己的数字助理、自定义搜索引擎、知识库、培训应用程序等等。

模型部署工具可帮助开发人员使用多种不同的部署选项,将在模型部署到生产环境中。而模型监控工具帮助开发人员使用仪表板和许多不同的度量来监控ML模型在生产中的性能。
如果把生成式AI应用开发看作一个复杂拼图的组装,其需要的数据科学、机器学习、编程等每一项技术能力就相当于拼图的每一块。
没有技术积累的企业理解这些拼图块本身就已经是很困难的事,将它们组合在一起就变成了一项更为艰巨的任务。但如果有服务方能给这些技术能力薄弱的传统企业提供一些预拼好的拼图部分,这些传统企业就能够更容易、更快速地完成整幅拼图。
从国内市场真实的情况来看,生成式AI的发展既不像当初追风口的从业者预估的那样乐观,也没有唱衰者形容的那么悲观。
企业用户追求应用的稳健性、经济性、安全性和可用性,这和大语言模型等生成式AI在训练过程中不惜花费高昂算力成本达成更高的能力是完全不同的路径。
这背后一个核心的问题是,在想象空间更大的企业级生成式AI领域,最重要的不是大模型能力有多强,而是如何能够从基础模型演变成各个领域中的具体应用,从而赋能整个经济社会的发展。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 2024 年投影仪销量预计突破 2000 万台,中国占全球市场份额第一
- 本站3月25日消息,洛图科技(RUNTO)数据显示,2023年,全球投影机市场出货量为1875.2万台,同比增长5.2%。报告中显示,全球投影机市场的2024年规模增速预测上调至9.7%。整体出货量将突破2000万台,达到2057万台。预计到2027年,全球投影机市场的规模有望达到3000万台。▲图源洛图科技(RUNTO),下同本站从报告获悉,2023年,中国大陆投影机市场出货量为711.4万台,同比下降6.9%;在全球市场中的占比从2022年的42.8%降至37.9%。但中国大陆仍保持全球最大的投影机市
- 3分钟前 投影仪 投影仪市场份额 0
-
 正版软件
正版软件
- 坦克品牌再发力,坦克330火爆上市72小时订单破3500
- 在3月31日消息中,坦克汽车品牌于昨日正式启动新车型坦克330的交付工作。这款备受瞩目的车型,以其独特的“用户共创”理念和强劲的动力性能,吸引了大量消费者的关注。坦克330是基于坦克300边境限定版进一步研发而成的,作为坦克品牌的首款“用户共创”车型,它充分汲取了用户的创意与智慧。在售价方面,坦克330定价为33万元,并且首批限量发售1000台,以满足广大车迷的热烈期待。在动力系统上,坦克330展现了卓越的性能。它搭载了3.0TV6双涡轮增压发动机,拥有265千瓦的最大功率和500牛·米的峰值扭矩,为驾驶
- 13分钟前 坦克 0
-
 正版软件
正版软件
- 尼康全新高倍变焦镜头尼克尔Z 28-400mm f/4-8 VR即将上市,售价10399元
- 尼康最近发布了备受关注的新产品——尼克尔Z28-400mmf/4-8VR高倍率变焦镜头。根据官方消息,这款镜头将于4月18日开始正式发售,售价为10399元。尼克尔Z28-400mmf/4-8VR镜头的问世,为摄影爱好者们带来了全新的拍摄体验。其焦距范围之广,覆盖了从28毫米到400毫米的全焦段,这在尼克尔Z系列镜头中尚属首次。无论是拍摄广阔的自然风光、紧张刺激的体育赛事,还是记录欢乐的游乐园瞬间,这款镜头都能以出色的成像质量捕捉到每一个精彩细节。据了解,尼克尔Z28-400mmf/4-8VR镜头在不同焦
- 23分钟前 尼克尔 0
-
 正版软件
正版软件
- 荣耀畅玩40C即将上市,配置与价格双优势引发期待
- 7月14日消息,荣耀畅玩40C即将在荣耀商城正式上市。根据官方披露,这款手机将于7月18日开始发货,售价为899元。荣耀畅玩40C提供墨玉青、幻夜黑和碧空蓝三种时尚配色,配备了一系列出色的功能和配置。荣耀畅玩40C拥有一块6.56英寸屏幕,分辨率为720×1612。该屏幕支持1670万色、70%NTSC色域和90Hz刷新率,同时搭载了“类自然光护眼”技术,可以模拟自然光的动态变化,减轻眼部疲劳,提升用户的视觉体验。在性能方面,荣耀畅玩40C搭载了高通骁龙480+处理器,其CPU频率为2*A76*2.2GH
- 1小时前 23:00 荣耀 0
-
 正版软件
正版软件
- 河北建新飞行汽车签署协议,获 Klein Vision AirCar 制造分销授权
- 根据BBC报道,据悉,河北建新飞行汽车近日与斯洛伐克企业KleinVision签署协议,获得后者AirCar飞行汽车在有限地理区域的制造和分销许可。双方并未透露最终交易金额。▲图源KleinVision官网AirCar是全球首款拿到适航许可的汽车,其采用宝马发动机和普通燃料,使用跑道进行起飞和降落,于2021年在斯洛伐克的两座机场之间进行了35分钟的城际试飞。AirCar概念车型包含多个版本,除了进行测试的双座款外还包括四座款、双引擎款和水陆两栖款。本站从KleinVision官网了解到,AirCar设计
- 1小时前 22:45 飞行汽车 AirCar 河北建新 0













