CVPR 2024 | 零样本6D物体姿态估计框架SAM-6D,向具身智能更进一步
 发布于2024-12-22 阅读(0)
发布于2024-12-22 阅读(0)
扫一扫,手机访问
在许多实际应用中,物体姿态估计扮演着关键角色,比如在具身智能、机器人操作和增强现实等领域。
在这一领域中,最先受到关注的任务是实例级别 6D 姿态估计,其需要关于目标物体的带标注数据进行模型训练,使深度模型具有物体特定性,无法迁移应用到新物体上。后来研究热点逐步转向类别级别 6D 姿态估计,用于处理未见过的物体,但要求该物体属于已知的感兴趣类别。
而零样本 6D 姿态估计是一种更具泛化性的任务设置,给定任意物体的 CAD 模型,旨在场景中检测出该目标物体,并估计其 6D 姿态。尽管其具有重要意义,这种零样本的任务设置在物体检测和姿态估计方面都面临着巨大的挑战。

图 1. 零样本 6D 物体姿态估计任务示意
最近,分割一切模型 SAM [1] 备受关注,其出色的零样本分割能力令人瞩目。SAM 通过各种提示,如像素点、包围框、文本和掩膜等,实现高精度的分割,这也为零样本 6D 物体姿态估计任务提供了可靠的支撑, 展现了其前景的潜力。
因此,一项新的零样本 6D 物体姿态估计框架 SAM-6D 被跨维智能、香港中文大学(深圳)、华南理工大学的研究人员提出。这一研究成果已经受到 CVPR 2024 的认可。

论文链接: https://arxiv.org/pdf/2311.15707.pdf
代码链接: https://github.com/JiehongLin/SAM-6D
SAM-6D 通过两个步骤来实现零样本 6D 物体姿态估计,包括实例分割和姿态估计。相应地,给定任意目标物体,SAM-6D 利用两个专用子网络,即实例分割模型(ISM)和姿态估计模型(PEM),来从 RGB-D 场景图像中实现目标;其中,ISM 将 SAM 作为一个优秀的起点,结合精心设计的物体匹配分数来实现对任意物体的实例分割,PEM 通过局部到局部的两阶段点集匹配过程来解决物体姿态问题。SAM-6D 的总览如图 2 所示。

图 2. SAM-6D 总览图
总体来说,SAM-6D 的技术贡献可概括如下:
SAM-6D 是一个创新的零样本 6D 姿态估计框架,通过给定任意物体的 CAD 模型,实现了从 RGB-D 图像中对目标物体进行实例分割和姿态估计,并在 BOP [2] 的七个核心数据集上表现优异。
SAM-6D 利用分割一切模型的零样本分割能力,生成了所有可能的候选对象,并设计了一个新颖的物体匹配分数,以识别与目标物体对应的候选对象。
SAM-6D 将姿态估计视为一个局部到局部的点集匹配问题,采用了一个简单但有效的 Background Token 设计,并提出了一个针对任意物体的两阶段点集匹配模型;第一阶段实现粗糙的点集匹配以获得初始物体姿态,第二阶段使用一个新颖的稀疏到稠密点集变换器以进行精细点集匹配,从而对姿态进一步优化。
实例分割模型 (ISM)
SAM-6D 使用实例分割模型(ISM)来检测和分割出任意物体的掩膜。
给定一个由 RGB 图像表征的杂乱场景,ISM 利用分割一切模型(SAM)的零样本迁移能力生成所有可能的候选对象。对于每个候选对象,ISM 为其计算一个物体匹配分数,以估计其与目标物体之间在语义、外观和几何方面的匹配程度。最后通过简单设置一个匹配阈值,即可识别出与目标物体所匹配的实例。
物体匹配分数的计算通过三个匹配项的加权求和得到:
语义匹配项 —— 针对目标物体,ISM 渲染了多个视角下的物体模板,并利用 DINOv2 [3] 预训练的 ViT 模型提取候选对象和物体模板的语义特征,计算它们之间的相关性分数。对前 K 个最高的分数进行平均即可得到语义匹配项分数,而最高相关性分数对应的物体模板视为最匹配模板。
外观匹配项 —— 对于最匹配模板,利用 ViT 模型提取图像块特征,并计算其与候选对象的块特征之间的相关性,从而获得外观匹配项分数,用于区分语义相似但外观不同的物体。
几何匹配项 —— 鉴于不同物体的形状和大小差异等因素,ISM 还设计了几何匹配项分数。最匹配模板对应的旋转与候选对象点云的平均值可以给出粗略的物体姿态,利用该姿态对物体 CAD 模型进行刚性变换并投影可以得到边界框。计算该边界框与候选边界框的交并比(IoU)则可得几何匹配项分数。
姿态估计模型 (PEM)
对于每个与目标物体匹配的候选对象,SAM-6D 利用姿态估计模型(PEM)来预测其相对于物体 CAD 模型的 6D 姿态。
将分割的候选对象和物体 CAD 模型的采样点集分别表示为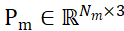 和
和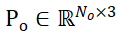 ,其中 N_m 和 N_o 表示它们点的数量;同时,将这两个点集的特征表示为
,其中 N_m 和 N_o 表示它们点的数量;同时,将这两个点集的特征表示为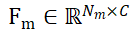 和
和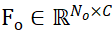 ,C 表示特征的通道数。PEM 的目标是得到一个分配矩阵,用于表示从 P_m 到 P_o 之间的局部到局部对应关系;由于遮挡的原因,P_o 只部分与匹配 P_m,而由于分割不准确性和传感器噪声,P_m 也只部分与匹配 P_o。
,C 表示特征的通道数。PEM 的目标是得到一个分配矩阵,用于表示从 P_m 到 P_o 之间的局部到局部对应关系;由于遮挡的原因,P_o 只部分与匹配 P_m,而由于分割不准确性和传感器噪声,P_m 也只部分与匹配 P_o。
为了解决两个点集非重叠点的分配问题,ISM 为它们分别配备了 Background Token,记为 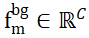 和
和 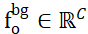 ,则可以基于特征相似性有效地建立局部到局部对应关系。具体来说,首先可以计算注意力矩阵如下:
,则可以基于特征相似性有效地建立局部到局部对应关系。具体来说,首先可以计算注意力矩阵如下:
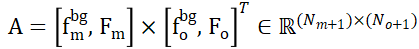
接着可得分配矩阵
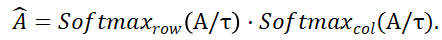
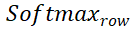 和
和 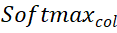 分别表示沿着行和列的 softmax 操作,
分别表示沿着行和列的 softmax 操作,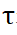 表示一个常数。
表示一个常数。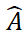 中的每一行的值(除了首行),表示点集 P_m 中每个点 P_m 与背景及 P_o 中点的匹配概率,通过定位最大分数的索引,则可以找到与 P_m 匹配的点(包括背景)。
中的每一行的值(除了首行),表示点集 P_m 中每个点 P_m 与背景及 P_o 中点的匹配概率,通过定位最大分数的索引,则可以找到与 P_m 匹配的点(包括背景)。
一旦计算获得  ,则可以聚集所有匹配点对 {(P_m,P_o)} 以及它们的匹配分数,最终利用加权 SVD 计算物体姿态。
,则可以聚集所有匹配点对 {(P_m,P_o)} 以及它们的匹配分数,最终利用加权 SVD 计算物体姿态。
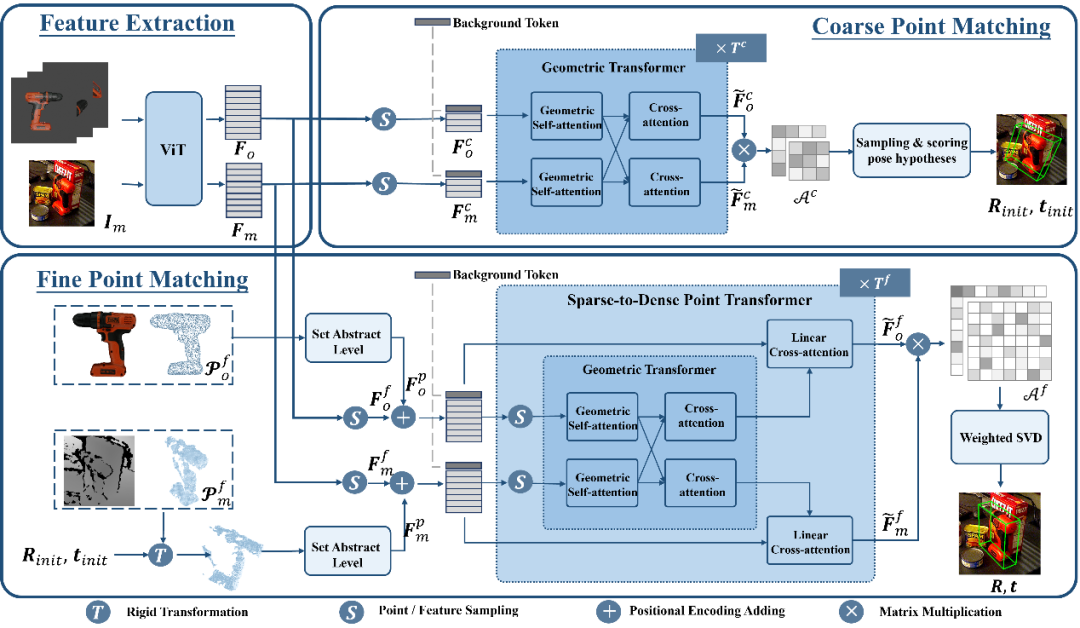
图 3. SAM-6D 中姿态估计模型 (PEM) 的示意图
利用上述基于 Background Token 的策略,PEM 中设计了两个点集匹配阶段,其模型结构如图 3 所示,包含了特征提取、粗略点集匹配和精细点集匹配三个模块。
粗糙点集匹配模块实现稀疏对应关系,以计算初始物体姿态,随后利用该姿态来对候选对象的点集进行变换,从而实现位置编码的学习。
精细点集匹配模块结合候选对象和目标物体的采样点集的位置编码,从而注入第一阶段的粗糙对应关系,并进一步建立密集对应关系以得到更精确的物体姿态。为了在这一阶段有效地学习密集交互,PEM 引入了一个新颖的稀疏到稠密点集变换器,它实现在密集特征的稀疏版本上的交互,并利用 Linear Transformer [5] 将增强后的稀疏特征扩散回密集特征。
实验结果
对于 SAM-6D 的两个子模型,实例分割模型(ISM)是基于 SAM 构建而成的,无需进行网络的重新训练和 finetune,而姿态估计模型(PEM)则利用 MegaPose [4] 提供的大规模 ShapeNet-Objects 和 Google-Scanned-Objects 合成数据集进行训练。
为验证其零样本能力,SAM-6D 在 BOP [2] 的七个核心数据集上进行了测试,包括了 LM-O,T-LESS,TUD-L,IC-BIN,ITODD,HB 和 YCB-V。表 1 和表 2 分别展示了不同方法在这七个数据集上的实例分割和姿态估计结果的比较。相较于其他方法,SAM-6D 在两个方法上的表现均十分优异,充分展现其强大的泛化能力。
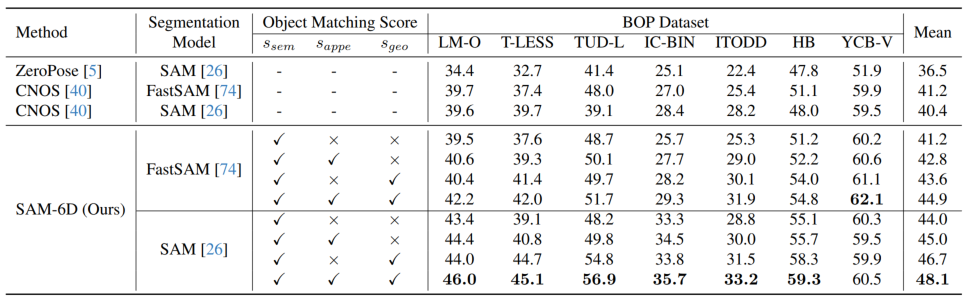
表 1. 不同方法在 BOP 七个核心数据集上的实例分割结果比较
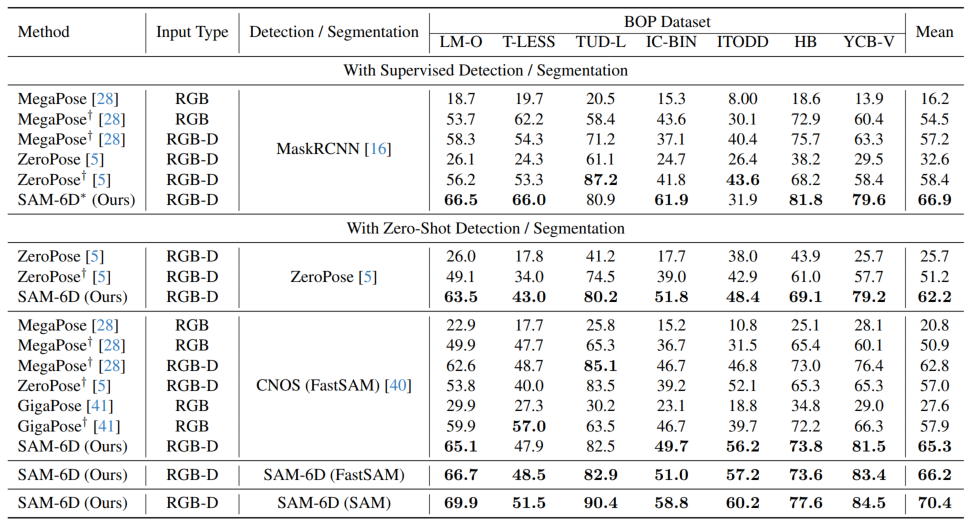
表 2. 不同方法在 BOP 七个核心数据集上的姿态估计结果比较
图 4 展示了 SAM-6D 在 BOP 七个数据集上的检测分割以及 6D 姿态估计的可视化结果,其中 (a) 和 (b) 分别为测试的 RGB 图像和深度图,(c) 为给定的目标物体,而 (d) 和 (e) 则分别为检测分割和 6D 姿态的可视化结果。

图 4. SAM-6D 在 BOP 的七个核心数据集上的可视化结果。
关于 SAM-6D 的更多实现细节, 欢迎阅读原论文.
参考文献:
[1] Alexander Kirillov et. al.,“Segment anything.”
[2] Martin Sundermeyer et. al.,“Bop challenge 2022 on detection, segmentation and pose estimation of specific rigid objects.”
[3] Maxime Oquab et. al.,“Dinov2: Learning robust visual features without supervision.”
[4] Yann Labbe et. al.,“Megapose: 6d pose estimation of novel objects via render & compare.”
[5] Angelos Katharopoulos et. al., “Transformers are rnns: Fast autoregressive
transformers with linear attention.”
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 618狂欢,华为Mate X3成为折叠屏手机市场亮点
- 6月15日消息,一年一度的618大促正在全国范围内火热展开。这个时候,消费者们都迫不及待地投入到疯狂的购物狂欢中。其中,折叠屏手机成为众多消费者关注的焦点。据小编了解,华为的最新折叠屏旗舰MateX3成为很多消费者的首选。华为MateX3作为华为今年3月发布的折叠屏旗舰手机,采用了华为自研的材料和专利技术,受到了广大消费者的赞誉。机身轻薄,重量仅为239克,折叠时厚度仅11.08毫米,展开时薄至5.3毫米,比前代产品厚度减薄了一半以上。这款手机拿在手上和其他直屏旗舰机几乎没有区别,使用起来非常轻松,受到用
- 10分钟前 0
-
 正版软件
正版软件
- 宏碁进军显卡市场,推出Predator BiFrost品牌显卡
- 7月15日消息,宏碁(Acer)计划进一步扩大其产品线,正式进军显卡市场。根据最新消息,宏碁在2022年推出了全新的PredatorBiFrost品牌,其中包括英特尔A770、A750和AMDRX7600等四款显卡。据宏碁官网显示,这三款PredatorBiFrost品牌显卡在设计上相似,而旗舰型号A770更是加入了RGB灯效。而A770的售价为11900新台币(约合2749元人民币),A750售价为7990新台币(约合1846元人民币),RX7600售价为8490新台币(约合1961元人民币)。据小编了
- 20分钟前 宏碁 0
-
 正版软件
正版软件
- 《功夫熊猫 4》电影豆瓣开分 6.7,成系列最低
- 本站3月25日消息,梦工厂动画《功夫熊猫4》电影内地定档3月22日,目前豆瓣评分已公布,开分只有6.7分(截至本站发文已降至6.6),成为系列四部中评分最低的一部。▲豆瓣页面截图《功夫熊猫》豆瓣评分8.2《功夫熊猫2》豆瓣评分8.1《功夫熊猫3》豆瓣评分7.8《功夫熊猫4》豆瓣评分6.6此外,《功夫熊猫4》在IMDB评分为6.5,同样是系列四部中最低的一部。▲IMDB截图《功夫熊猫4》由《怪物史瑞克4》导演迈克・米切尔执导,讲述神龙大侠阿宝晋升为和平谷的精神领袖,而新反派变色龙变形女巫“魅影妖后”带来前所
- 35分钟前 功夫熊猫 0
-
 正版软件
正版软件
- 小米汽车严正声明:SU7官方无额外优惠,警惕非官方欺诈
- 近日备受瞩目的小米SU7汽车因其超越的性价比和先进的科技配置,在市场上引起了热烈反响。然而,这也引来了一些不能分子的关注。他们在社交平台上声称可以提供购车优惠,并试图进行诈骗活动。虽然市场上的竞争激烈,但消费者应保持警惕,不要因为便宜而上当受骗。建议大家选择正规的渠道购车,并在试图参加抢购活动时,寻求可靠渠道的支持。对于这一现象,小米汽车官方发布严正声明,明确表示目前官方渠道并未提供任何额外的购车优惠。小米汽车提醒广大消费者,若遇到非官方渠道宣传提供额外优惠的情况,务必保持警惕,仔细甄别,以免遭受财产损失
- 55分钟前 小米 0
-
 正版软件
正版软件
- 腾讯《元梦之星》回应被网易《蛋仔派对》地图作者起诉:已将相关地图全量下架
- 本站3月28日消息,网易《蛋仔仔派对》知名UGC地图《因蓝》的创作者@仟中酒日前在抖音发布视频称,因为创作的地图在《元梦之星》中被长期、多次地抄袭,已经向腾讯发起诉讼,案件已被受理,将于5月开庭。今日下午,腾讯《元梦之星》游戏官方微博发布《关于地图创作原创保护的声明》,在收到《因蓝》地图作者的维权投诉后,经人工审核,我们已将被投诉的相关创作地图全量下架,并依据《元梦之星侵权投诉通知指引》中的处理原则,以游戏内邮件通知了被投诉玩家。随后《元梦之星》运营团队更进一步升级了处理政策,禁止所有玩家发布、使用含“因
- 1小时前 02:35 蛋仔派对 元梦之星 腾讯网易 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1839天前
-
 2
2
- Overture设置踏板标记的方法
- 1676天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1665天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1864天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1830天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1826天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1840天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1862天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00