大佬出走后首个发布!Stability官宣代码模型Stable Code Instruct 3B
 发布于2024-12-23 阅读(0)
发布于2024-12-23 阅读(0)
扫一扫,手机访问
大佬出走后,第一个模型来了!
就在今天,Stability AI官宣了新的代码模型Stable Code Instruct 3B。
 图片
图片
Stability是非常重要的,首席执行官离职对Stable Diffusion造成了一些困扰,投资公司出了点故障,自己的工资也可能有问题了。
然而,楼外风雨飘摇,实验室里岿然不动,研究该做做,讨论该发发,模型该调调,大模型各领域的战争是一个没落下。
不仅仅是铺开摊子搞全面战争,每项研究也都在不断前进,比如今天的Stable Code Instruct 3B就是在之前的Stable Code 3B的基础上做了指令调优。
 图片
图片
论文地址:https://static1.squarespace.com/static/6213c340453c3f502425776e/t/6601c5713150412edcd56f8e/1711392114564/Stable_Code_TechReport_release.pdf
通过自然语言提示,Stable Code Instruct 3B可以处理各种任务,例如代码生成、数学和其他与软件开发相关的查询。
 图片
图片
同阶无敌,越级强杀
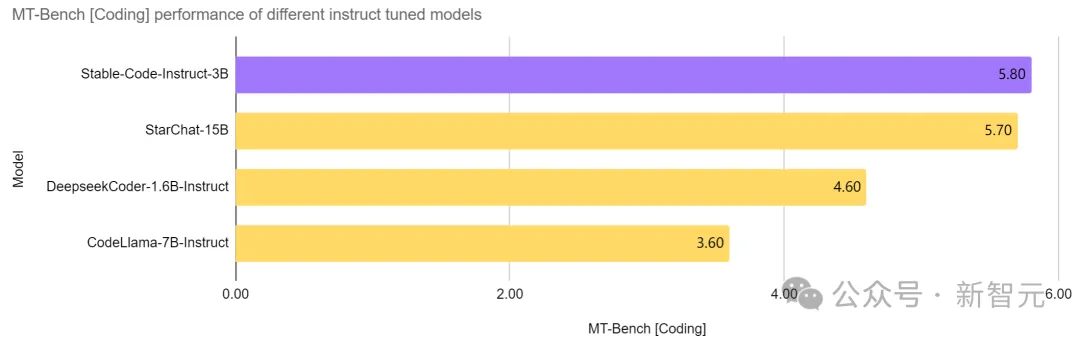
Stable Code Instruct 3B在同等参数量的模型中,做到了当前的SOTA,甚至优于比自己大两倍多的CodeLlama 7B Instruct等模型,并且在软件工程相关任务中的表现与StarChat 15B相当。
 图片
图片
从上图可以看出,与Codellama 7B Instruct和DeepSeek-Coder Instruct 1.3B等领先模型相比,Stable Code Instruct 3B在一系列编码任务中性能优异。
测试表明,Stable Code Instruct 3B在代码完成准确性、对自然语言指令的理解、以及跨不同编程语言的多功能性方面,都能够打平甚至超越竞争对手。
 图片
图片
Stable Code Instruct 3B根据Stack Overflow 2023开发者调查的结果,将训练专注于 Python、Javascript、Java、C、C++和Go等编程语言。
上图使用Multi-PL基准测试,比较了三个模型以各种编程语言生成输出的强度。可以发现Stable Code Instruct 3B在所有语言中都明显优于CodeLlama,并且参数量还少了一半多。
除了上述的热门编程语言,Stable Code Instruct 3B还包括对其他语言(如SQL、PHP和Rust)的训练,并且即使在没有经过训练的的语言(如Lua)中,也能提供强大的测试性能。
Stable Code Instruct 3B不仅精通代码生成,还精通FIM(代码中间填充)任务、数据库查询、代码翻译、解释和创建。
通过指令调优,模型能够理解细微的指令并采取行动,促进了除了简单代码完成之外的广泛编码任务,比如数学理解、逻辑推理和处理软件开发的复杂技术。
 图片
图片
模型下载:https://huggingface.co/stabilityai/stable-code-instruct-3b
Stable Code Instruct 3B现在可以通过Stability AI会员资格,用于商业目的。对于非商业用途,可以在Hugging Face上下载模型重量和代码。
技术细节
 图片
图片
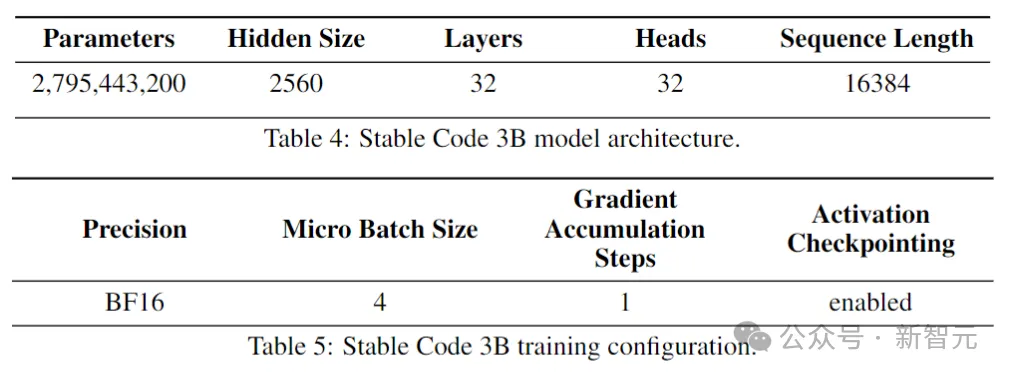
模型架构
Stable Code建立在Stable LM 3B之上,是一个decoder-only Transformer结构,设计类似于LLaMA。下表是一些关键的结构信息:
 图片
图片
与LLaMA的主要区别包括:
位置嵌入:在头部嵌入的前25%使用旋转位置嵌入,以提高后续的吞吐量。
正则化:使用带学习偏差项的LayerNorm,而非RMSNorm。
偏置项:删除了前馈网络和多头自注意力层中所有的偏置项,除了KQV的。
使用与Stable LM 3B模型相同的分词器(BPE),大小为50,257;另外还参照了StarCoder的特殊标记,包括用于指示文件名称、存储库的星数、中间填充(FIM)等。
对于长上下文训练,使用特殊标记来指示两个串联文件何时属于同一存储库。
训练过程
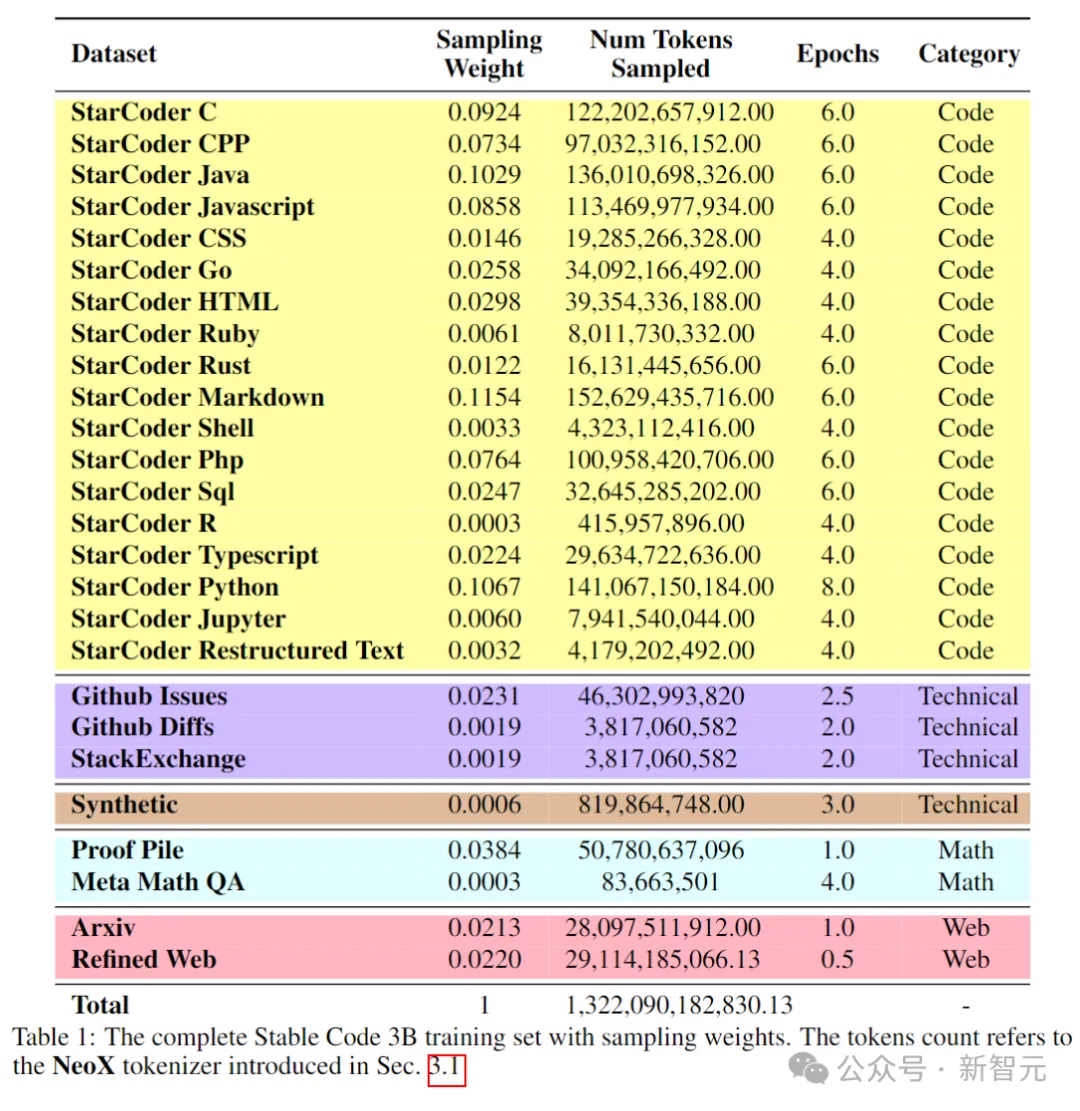
训练数据
预训练数据集收集了各种可公开访问的大规模数据源,包括代码存储库、技术文档(如readthedocs)、以数学为重点的文本,和大量Web数据集。
初始预训练阶段的主要目标是学习丰富的内部表示,以显著提高模型在数学理解、逻辑推理、和处理软件开发相关复杂技术文本方面的能力。
此外,训练数据还包含通用文本数据集,以便为模型提供更广泛的语言知识和上下文,最终使模型能够以对话方式处理更广泛的查询和任务。
下表展示了预训练语料库的数据源、类别和采样权重等,其中代码和自然语言数据的比例为80:20。
 图片
图片
另外,研究人员还引入了一个小型合成数据集,数据由CodeAlpacadataset的种子提示合成生成,包含174,000个提示。
并且参照WizardLM的方式,逐步增加给定种子提示的复杂性,又额外获得了100,000个提示。
作者认为,在预训练阶段早期引入这些合成数据有助于模型更好地响应自然语言文本。
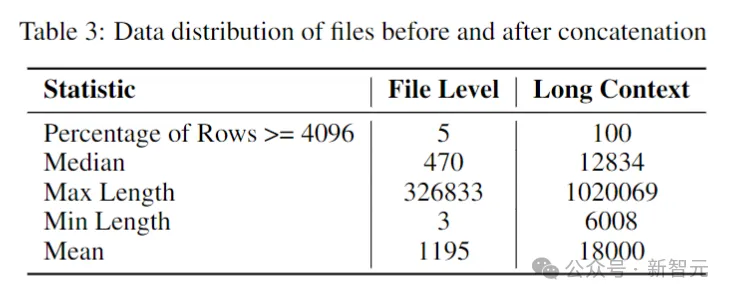
长上下文数据集
由于存储库中多个文件通常相互依赖,因此上下文长度对于编码模型很重要。
研究人员估计了软件存储库中token的中位数和平均数分别为12k和18k,因此选择16,384作为上下文长度。
接下来就是创建一个长上下文数据集,研究人员在存储库中获取了一些热门语言编写的文件并将它们组合在一起,在每个文件之间插入一个特殊的标记,以保持分离,同时保留内容流。
为了规避因文件的固定顺序而可能产生的任何潜在偏差,作者采用了一种随机策略。对于每个存储库,生成两个不同的连接文件顺序。
 图片
图片
分阶段训练
Stable Code使用32个Amazon P4d实例进行训练,包含256个NVIDIA A100(40GB HBM2)GPU,并使用ZeRO进行分布式优化。
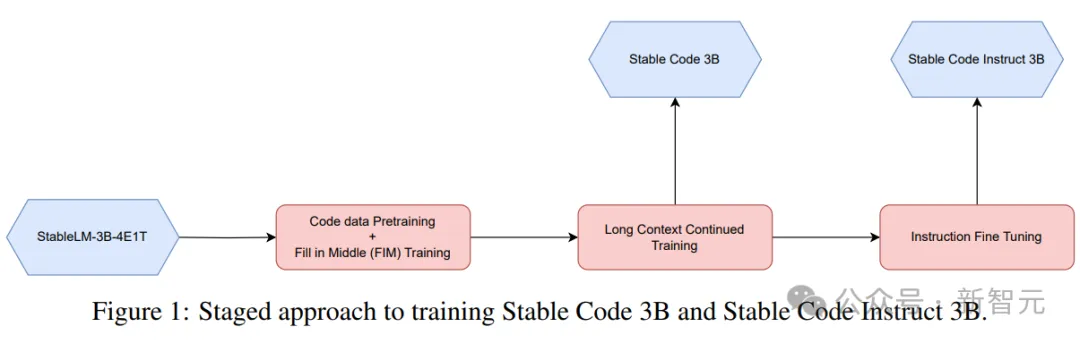 图片
图片
这里采用了一种分阶段的训练方法,如上图所示。
训练按照标准的自回归序列建模预测下一个标记。使用Stable LM 3B的checkpoint初始化模型,第一阶段训练的上下文长度为4096,然后进行持续的预训练。
训练以BFloat16混合精度执行,all-reduce时采用FP32。AdamW 优化器设置为:β1=0.9,β2=0.95,ε=1e−6,λ(权重衰减)=0.1。从学习率=3.2e-4开始,设置最小学习率为3.2e-5,使用余弦衰减。
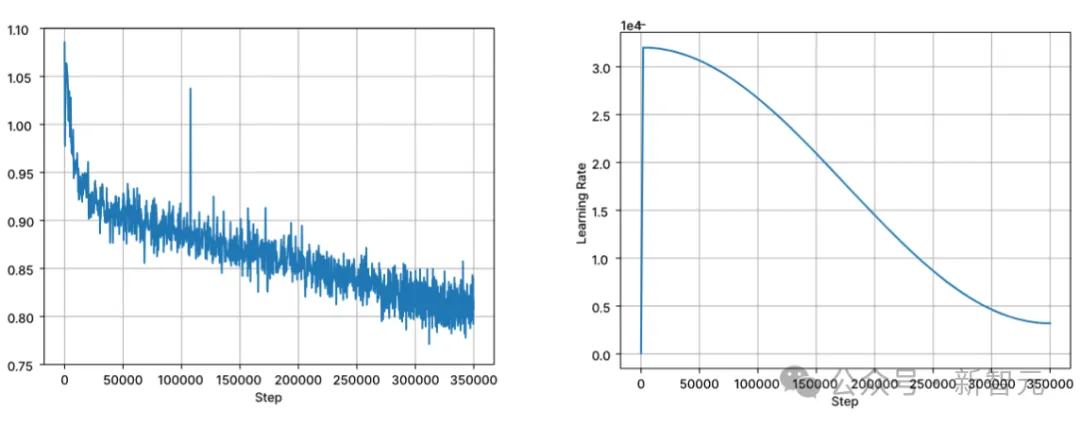 图片
图片
自然语言模型训练的核心假设之一是从左到右的因果顺序,不过对于代码来说,这种假设并不总是成立(例如,函数调用和函数声明对于许多函数来说可以是任意顺序的)。
为了解决这个问题,研究人员使用了FIM(中间填充)。将文档随机拆分为三个段:前缀、中间段和后缀,然后将中间段移动到文档的末尾。重新排列后,遵循相同的自回归训练过程。
指令微调
在预训练之后,作者通过微调阶段进一步提高模型的对话技能,该阶段包括监督微调(SFT)和直接偏好优化(DPO)。
首先使用在Hugging Face上公开可用的数据集进行SFT微调:包括OpenHermes,Code Feedback,CodeAlpaca。
在执行精确匹配重复数据删除后,三个数据集总共提供了大约500000个训练样本。
使用余弦学习速率调度器控制训练过程,并将全局批处理大小设置为512,将输入打包到长度不超过4096的序列中。
在SFT之后,开始DPO阶段,利用来自UltraFeedback的数据,策划了一个包含大约7,000个样本的数据集。此外,为了提高模型的安全性,作者还纳入了Helpful and Harmless RLFH数据集。
研究人员采用RMSProp作为优化算法,DPO训练的初始阶段将学习率提高到5e-7的峰值。
性能测试
下面比较模型在代码完成任务上的性能,使用Multi-PL基准来评估模型。
Stable Code Base
下表显示了在Multi-PL上,大小为3B参数及以下的不同代码模型的性能。
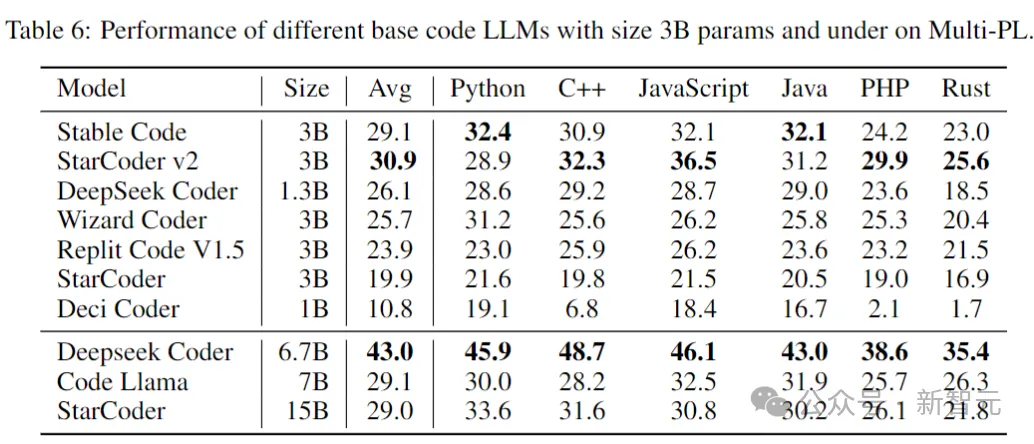 图片
图片
尽管Stable Code的参数量分别不到Code Llama和StarCoder 15B的40%和20%,但模型在各种编程语言中的平均性能与它们持平。
Stable Code Instruct
下表在Multi-PL基准测试中,评估了几个模型的instruct微调版本。
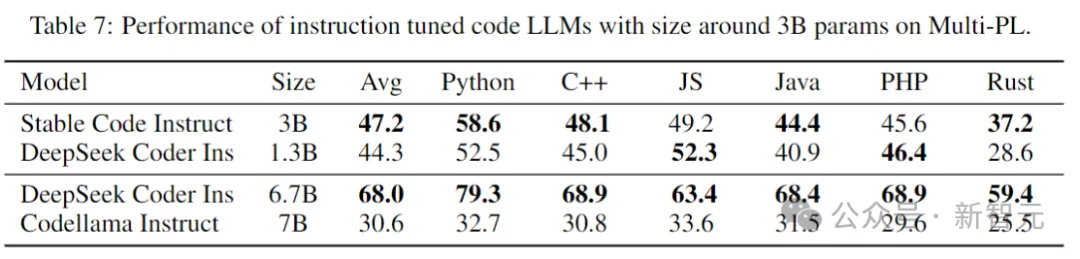 图片
图片
SQL Performance
代码语言模型的一个重要应用是数据库查询任务。在这个领域,将Stable Code Instruct的性能与其他流行的指令调优模型,和专门为SQL训练的模型进行比较。这里使用Defog AI创建的基准。
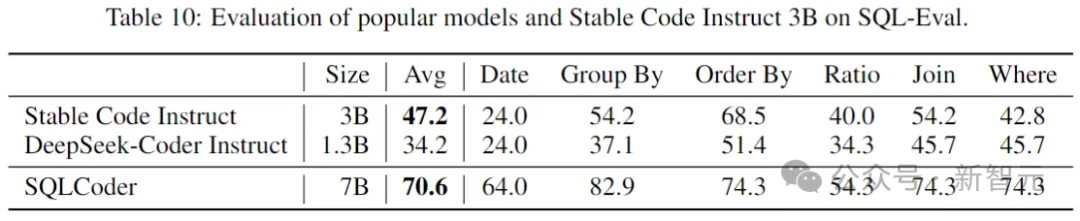 图片
图片
推理性能
下表给出了在消费级设备和相应的系统环境中运行Stable Code时的吞吐量和功耗。
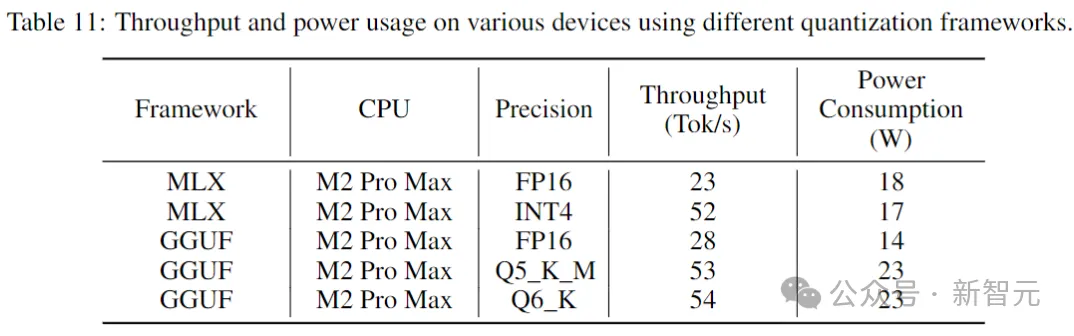 图片
图片
结果表明,当采用较低的精度时,吞吐量增加了近两倍。但需要注意的是,实施较低精度的量化可能会导致模型性能有所下降(可能很大)。
参考资料:https://stability.ai/news/introducing-stable-code-instruct-3b
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- HiPhi Y揭秘:展翼门、810公里续航,打造智能出行新标杆
- 7月15日消息,华人运通旗下高合汽车宣布即将推出旗下全新纯电中型SUV——高合HiPhiY。这款车型于今天开始进行预热,展示了多项引人注目的特性,包括展翼门、高达810公里的续航里程以及后轮转向等。据高合官方透露,HiPhiY将于全球同步上市,为消费者带来豪华大五座空间的全新驾乘体验。HiPhiY是高合汽车品牌推出的第三款车型,相较于旗下的HiPhiX和HiPhiZ,其外观设计更偏向传统汽车风格,不再强调过于激进的“未来感”。不过,HiPhiY依然采用了家族式的展翼门设计,被称为“移动衣帽间”,彰显独特魅
- 3分钟前 高合 0
-
 正版软件
正版软件
- 特斯拉OTA 2024.8.4版本更新,多款车型新增实用功能
- 特斯拉最近发布了2024.8.4版本的OTA更新,为其海外版汽车增加了多项实用功能,并对用户界面进行了优化。据小编了解,本次更新中,特斯拉Cybertruck车型新增了“车辆警报器”功能,该功能可监控拖车是否已插入挂车,并通过车辆设置中的相关选项进行启用或禁用,提升了车辆的安全性。同时,该车还新增了“查看或重置轮胎里程”功能,便于车主了解轮胎使用情况,并在更换或调换轮胎时重置计数器。除此之外,Cybertruck还新增了“后排乘客耳机”管理功能,允许后座乘客在后排触摸屏上观看电视或游玩游戏时,通过蓝牙耳机
- 8分钟前 特斯拉 0
-
 正版软件
正版软件
- 抢购热潮来袭!真我GT Neo5、GT Neo5 SE等热门机型优惠放送!
- 5月31日消息,真我618即将开启,手机品牌真我发布了最新的抢购攻略。根据官方介绍,真我618将于今晚8点正式开启,并将全程提供价保政策,爆款单品最高可享受800元的立减优惠,新机更有6期免息购买的机会,同时还有千元神券大放送。据小编了解,真我品牌旗下的热门机型在本次618活动中也享有优惠。其中,真我GTNeo5的不同版本都可享受高达300元的立省优惠。150W秒充版本的12GB+256GB版本售价2499元,16GB+1TB版本售价3099元,而240W秒充版本的16GB+1TB版本则售价3199元。真
- 23分钟前 0
-
 正版软件
正版软件
- 我国科研团队完成新型光刻胶技术初步验证,性能优于大多数商用光刻胶
- 根据湖北九峰山实验室消息,作为半导体制造不可或缺的材料,光刻胶质量和性能是影响集成电路电路电性能、成品率及可靠性的关键因素。然而,光刻胶技术门槛高,市场上制程稳定性高、工艺宽容度大、普适性强的光刻胶产品屈指可数。当半导体制造芯片进入到100nm甚至是10nm以下,如何产生辨识率高且截面形貌优良、线边缺陷度低的光刻图形,成为光刻制造的共性难题。针对上述瓶颈问题,九峰山实验室、华中科技大学组成联合研究团队,支持华中科技大学团队突破“双非离子型光酸协同增强响应的化学放大光刻胶”技术。该研究通过巧妙的化学结构设计
- 33分钟前 半导体 芯片 光刻胶 九峰山 华中科技大学 0
-
 正版软件
正版软件
- iPhone 16系列新机抢先看:拍照按键成亮点,屏幕尺寸再升级
- 苹果公司最近正式宣布,2024年的全球开发者大会(WWDC)将于美国太平洋时间的6月10日至14日举行。届时,苹果预计将发布最新一代的iOS18、iPadOS18等操作系统,这一消息引起了全球科技界的高度关注。与此同时,科技媒体Macrumors也曝光了关于将首发预装iOS18的iPhone16系列的新信息。据其报道,iPhone16系列的机模已经提前曝光,整体设计上与此前传闻基本一致,沿用了当前的灵动岛+后摄方案。Pro版的中框材质依然是钛金属,这种材质在保持强度的同时,也能有效减轻机身重量。在细节上,
- 48分钟前 苹果 0













