谷歌更新Transformer架构,更节省计算资源!50%性能提升
 发布于2024-12-23 阅读(0)
发布于2024-12-23 阅读(0)
扫一扫,手机访问
想了解更多AIGC的内容,
请访问:51CTO AI.x社区
https://www.51cto.com/aigc/
谷歌终于更新了Transformer架构。
最新发布的Mixture-of-Depths(MoD),改变了以往Transformer计算模式。
它通过动态分配大模型中的计算资源,跳过一些不必要计算,显著提高训练效率和推理速度。
结果显示,在等效计算量和训练时间上,MoD每次向前传播所需的计算量更小,而且后训练采样过程中步进速度提高50%。
这一方法刚刚发布,就马上引发关注。
MoE风头正盛,MoD已经来后浪拍前浪了?

还有人开始“算账”:
听说GPT-4 Turbo在Blackwell上提速30倍,再加上这个方法和其他各种加速,下一代生成模型可以走多远?

所以MoD如何实现?
迫使大模型关注真正重要信息
这项研究提出,现在的大模型训练和推理中,有很多计算是没必要的。
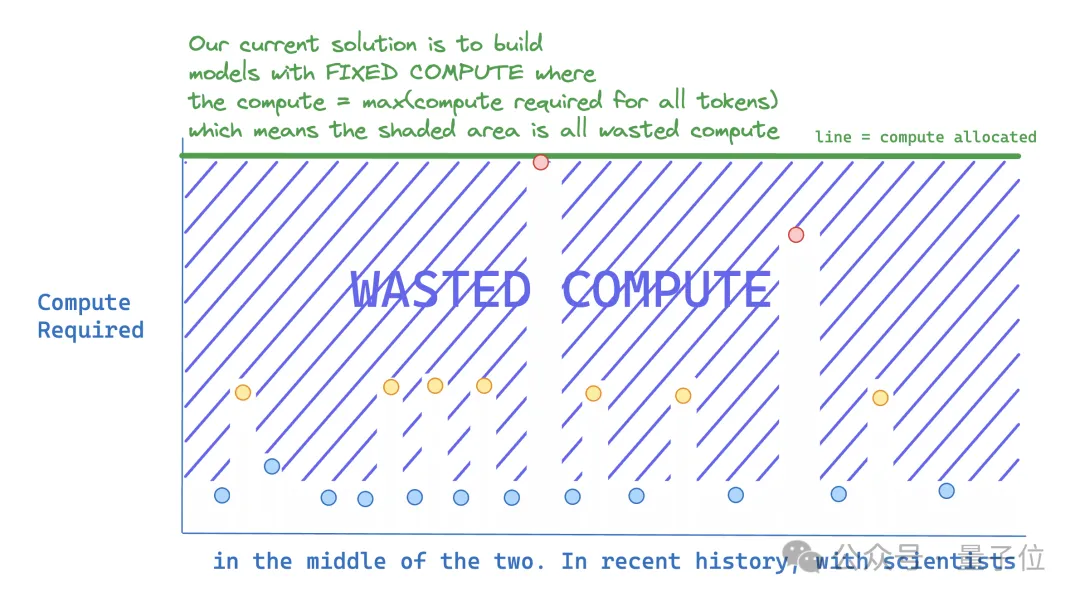
比如预测下一个句子很难,但是预测句子结束的标点符号很简单。如果给它们分配同样的计算资源,那么后者明显浪费了。
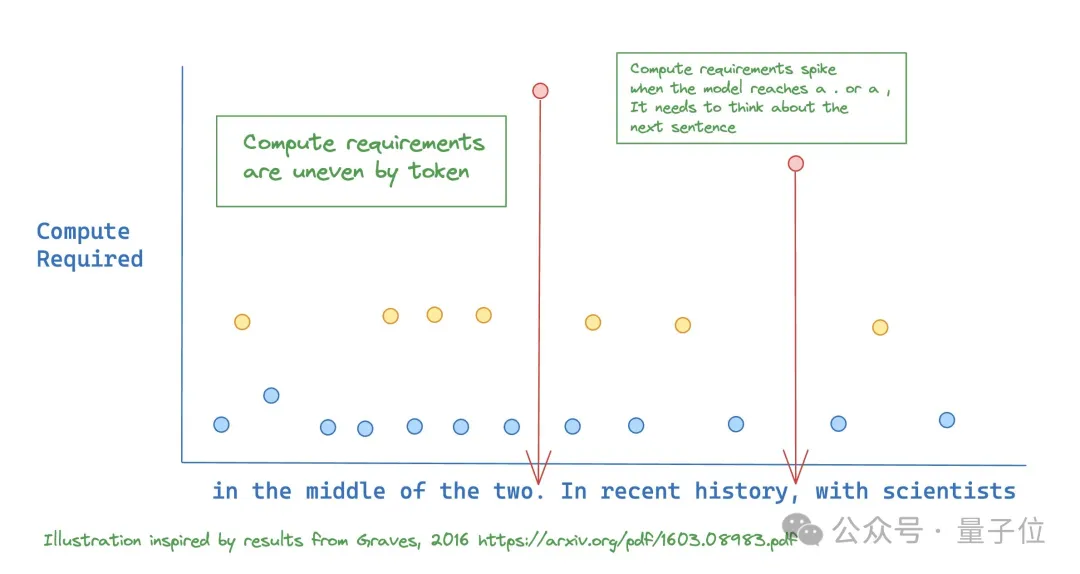
在理想情况下, 模型应该只给需要准确预测的token分配更多计算资源。

所以研究人员提出了MoD。
它在输入序列中的特定位置动态分配FLOPs(运算次数或计算资源),优化不同层次的模型深度中的分配。
通过限制给定层的自注意力和MLP计算的token数量,迫使神经网络学会主要关注真正重要的信息。
因为token数量是事先定义好的,所以这个过程使用一个已知张量大小的静态计算图,可以在时间和模型深度上动态扩展计算量。
下图右上图中的橙色部分,表示没有使用全部计算资源。
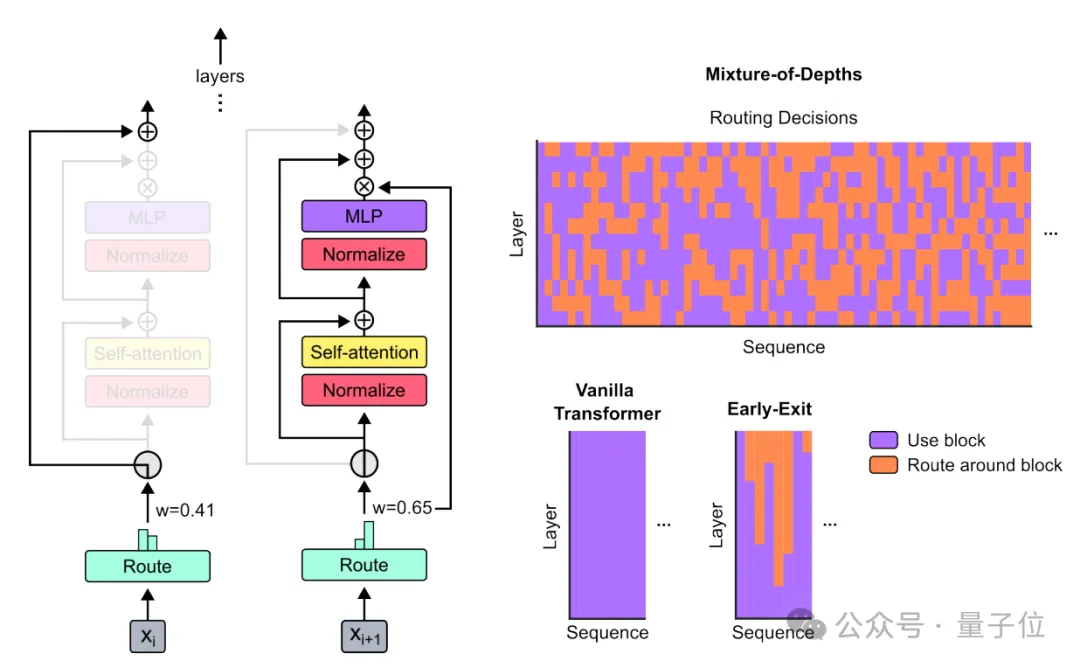
这种方法在节省计算资源的同时,还能提高效率。
这些模型在等效的FLOPS和训练时间上与基线性能相匹配,但每次前向传播所需的FLOP更少,并且在训练后采样时提速50%。
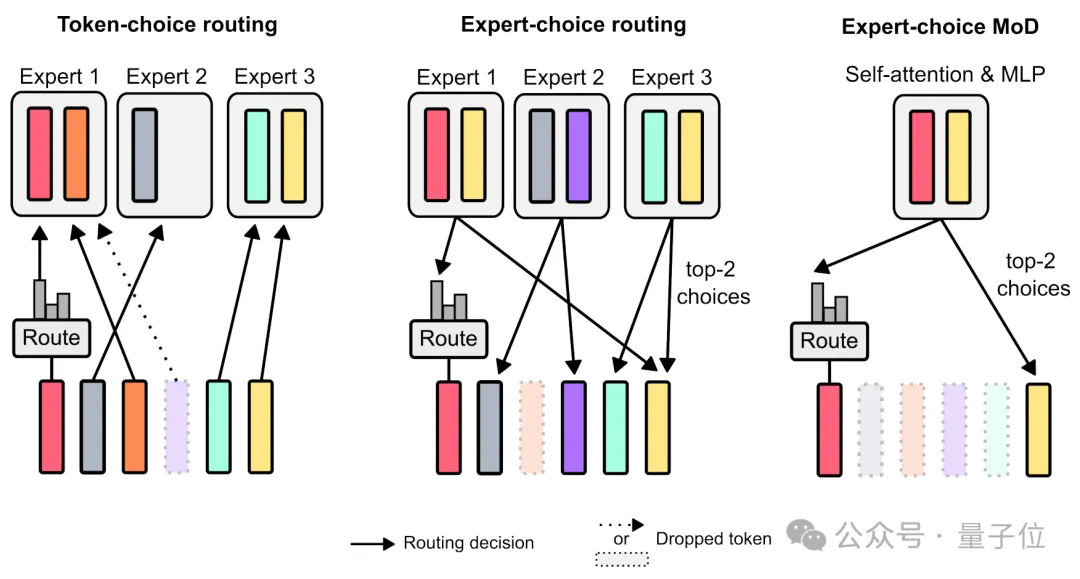
对比来看,如果为每一个token生成一个概率分布,每个token根据最高概率被送去对应的“专家”,可能会导致负载不平衡。
如果反过来,这能保障负载平衡,但是可能导致某些token被过度处理或处理不足。
最后来看论文中使用的Expert-choice MoD,router输出的权重被用于确定哪些token将使用transformer亏啊计算。权重较大的token将参与计算,权重较小的token将通过残差连接绕过计算,从而解决每次向前传播的FLOPs。
最后,研究团队展示了MoD在不同实验中的性能表现。
首先,他们使用相对较小的FLOP预算(6e18),以确定最佳超参数配置。
通过这些实验,作者发现MoD方法能够“拉低并向右推移”isoFLOP基线曲线,这意味着最优的MoD方法在更低的损失水平上拥有更多的参数。
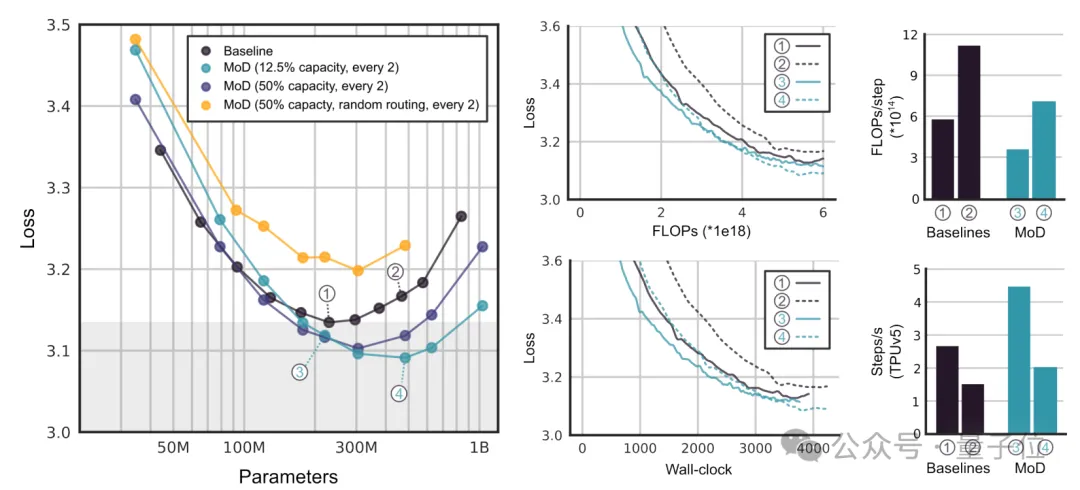
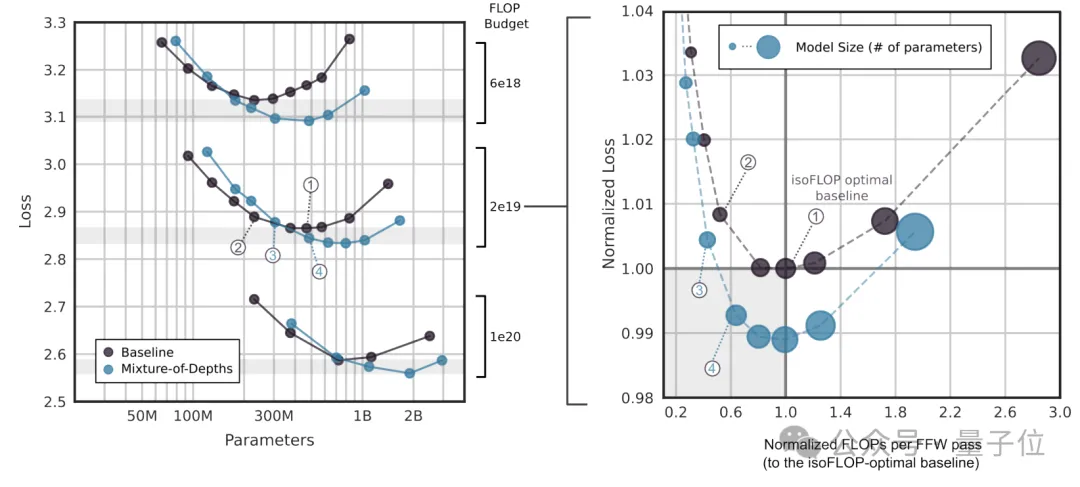
通过isoFLOP分析,比较6e18、2e19和1e20 FLOPs的总计算预算下的模型性能。
结果显示,在更多FLOP预算下,FLOP最优的MoD仍然比基线模型有更多的参数。
存在一些MoD变体,在步骤速度上比isoFLOP最优基线模型更快,同时实现更低的损失。这表明在训练之外,MoD的计算节省仍然有效。
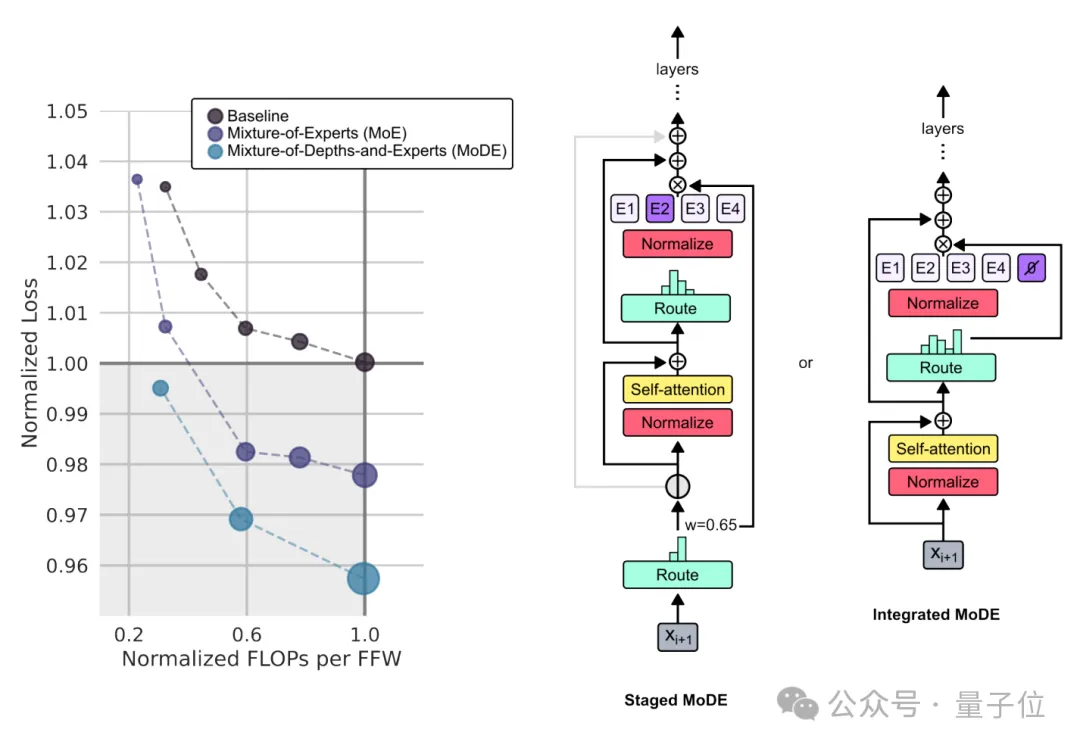
同时,研究团队还探讨了MoD和MoE结合的可能性——MoDE。
结果表明而这结合能提供更好的性能和更快的推理速度。
网友:联想到了ResNet
MoD推出后马上引发了不小关注。
有人感慨,MoE还没有弄清楚呢,MoD都已经来了!

这么高效的方法,让人马上联想到了ResNet。

不过和ResNet不同,MoD跳过连接是完全绕过层的。

还有人表示,希望这种方法是完全动态的,而不是每个层固定百分比。

这项研究由DeepMind和麦吉尔大学共同带来。
主要贡献者是David Raposo和Adam Santoro。

他们二人都是DeepMind的研究科学家。此前共同带来了神作《Relational inductive biases, deep learning, and graph networks》。
这篇论文目前被引次数超过3500次,论文核心定义了Inductive bias(归纳偏置)概念。
论文地址:https://arxiv.org/abs/2404.02258
想了解更多AIGC的内容,
请访问:51CTO AI.x社区
https://www.51cto.com/aigc/
上一篇:平板电脑便宜又好用
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 荣耀Magic V2:突破续航、信号和护眼的顶尖技术
- 7月6日消息,荣耀赵明在上月底的MWC上海展会上发表了演讲,同时宣布荣耀将于7月12日在北京发布其新一代折叠屏手机荣耀MagicV2。随着发布日期的临近,荣耀官方对该手机的预热活动也变得更加密集。近期有最新消息称,荣耀CEO赵明再度发布视频,进一步解答了消费者对该手机配置和功能的疑问。据荣耀CEO赵明透露,全新的荣耀MagicV2将一次性解决续航、信号和护眼等三大问题。该手机将搭载荣耀最新的通讯技术,被称为行业顶级,预计在特殊环境下(如高铁)能提供顶尖的信号表现。此外,荣耀MagicV2还将带来突破性的屏
- 4分钟前 0
-
 正版软件
正版软件
- 宇通携手宁德时代发布15年150万公里长寿命电池,共推商用车技术创新
- 宇通集团于今日中午举办的新能源商用车全系新品发布会上,携手宁德时代共同发布了一款寿命长达15年、可行驶150万公里的长寿命电池。这款电池产品将覆盖客车、轻卡、重卡等多个细分市场,并计划应用于宇通客车和宇通重工的相关系列产品。该电池在前1000次循环中实现了零衰减的出色表现。除此之外,为了满足不同用户群体的差异化需求,宇通还推出了质保期为10年或10万公里的动力电池产品。经小编解析,此次发布会还宣布了宇通推出的12款全新商用车产品,这些新品将从即日起正式进入市场,为消费者提供更多选择。宁德时代与宇通通讯于2
- 14分钟前 宁德时代 宇通集团 0
-
 正版软件
正版软件
- CVPR 2024录用结果出炉!2719篇论文被接收,录用率23.6%
- 想了解更多AIGC的内容:请访问:51CTOAI.x社区https://www.51cto.com/aigc/CVPR2024最终录用结果公布了!刚刚,CVPR官方发文称,今年共提交了11532份有效论文,2719篇论文被接收,录用率为23.6%。与去年相比,共有9155篇论文提交,2359篇论文接收,录用率降低2.2%。官方给的回复是,数据每年都会有波动的。据统计,CVPR的投稿量在2010-2016的7年间仅从1724份增加到2145份,在2017年后则迅速飙升,进入快速增长期。2019年首次突破50
- 29分钟前 论文 录用 0
-
 正版软件
正版软件
- 天玑6100+处理器加持!荣耀畅玩50/50m新机亮相,售价亲民
- 3月28日消息,荣耀官网近日推出了两款新机——畅玩50和畅玩50m,起售价分别为1199元和1499元。虽然具体的开售时间尚未公布,但这两款新机已经引起了广泛关注。小编解释了,畅玩50和畅玩50m都搭载了天王6100+处理器,该处理器包含2个A76+2.2GHz核心和6个A55+2.0GHz核心组成,性能表现值得期待。同时,这两款新机还运行了基于Android14开发的MagicOS8.0系统,支持手势导航、人脸解锁、YOYO建议等实用功能,为用户带来更加便捷的操作体验。在外观方面,畅玩50提供了星辰紫、
- 44分钟前 荣耀 0
-
 正版软件
正版软件
- 台北电脑展首秀!14代酷睿处理器实机展示,性能亮点抢先揭晓
- 5月30日消息,Intel即将在下半年发布第14代酷睿处理器MeteorLake,为消费者带来一系列令人期待的创新。此次新处理器将首次采用Intel4制造工艺(原7nm),引入了先进的chiplet小芯片架构,并进行了全新的CPU/GPU架构升级。此外,MeteorLake还引入了四级缓存,为性能提供了进一步的提升。据小编了解,这款新处理器的亮点之一是其创新的核心配置。MeteorLake将搭载16核心22线程,其中包括6个性能核心(RedwoodCove)、8个能效核心(Crestmont)以及2个超低
- 54分钟前 Intel 0













