元象首个MoE大模型开源:4.2B激活参数,效果堪比13B模型
 发布于2024-12-24 阅读(0)
发布于2024-12-24 阅读(0)
扫一扫,手机访问
元象发布XVERSE-MoE-A4.2B大模型 , 采用业界最前沿的混合专家模型架构 (Mixture of Experts),激活参数4.2B,效果即可媲美13B模型。该模型全开源,无条件免费商用,让海量中小企业、研究者和开发者可在元象高性能“全家桶”中按需选用,推动低成本部署。

GPT3、Llama与XVERSE等主流大模型发展遵循规模理论(Scaling Law), 在模型训练和推理的过程中,单次前向、反向计算时,所有参数都被激活,这被称为稠密激活 (densely activated)。 当 模型规模增大时,算力成本 会急剧升高。
随着越来越多的研究人员认为,稀疏激活(sparsely activated)的MoE模型,在增大模型规模时,可不显著增加训练和推理的计算成本,是一种更有效的方法。由于技术较新,目前国内大部分开源模型或学术研究尚未普及。
在元素自研中,使用相同语料训练2.7百万亿token,XVERSE-MoE-A4.2B实际激活参数量4.2B,性能“跳级”超越XVERSE-13B-2,仅计算量,并减少50%训练时间。与多个开源标杆Llama相比,该模型大幅超越Llama2-13B、接近Llama1-65B(下图)。
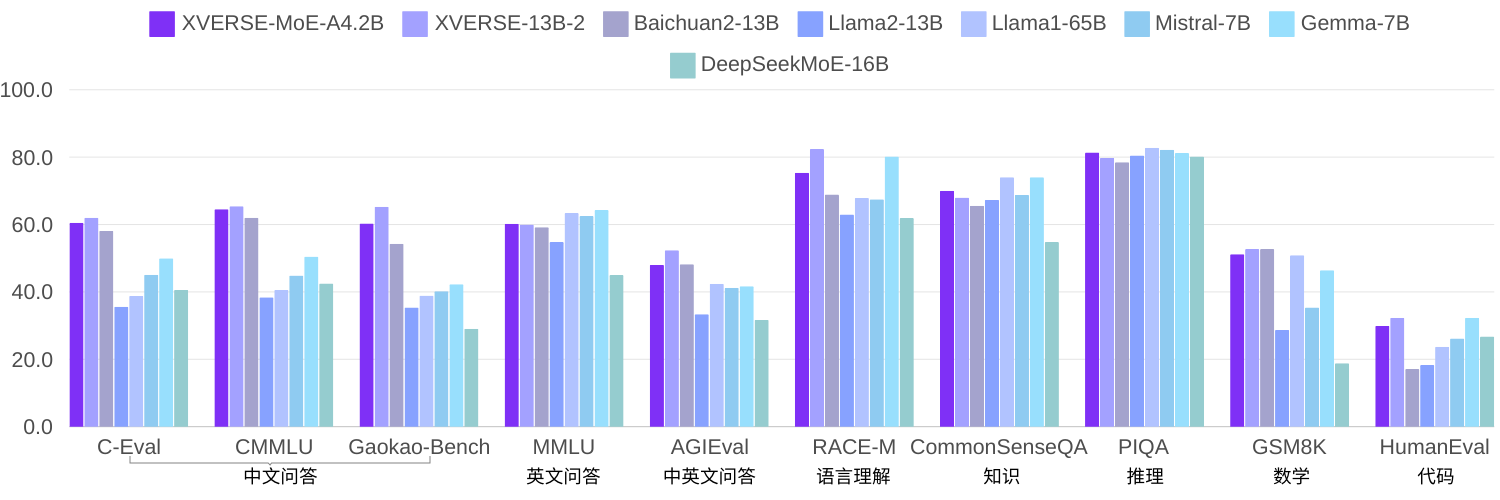
查看多项权威评测
在开源上,元素大模型"全家桶"持续迭代,将国产开源引领至国际一流水平。应用上,元素发挥AI+3D独特技术独特优势,推出大模型3D空间、AIGC工具等一站式解决方案,赋能文娱、旅游、金融等各行各业,在智能客服、创意体验、提效工具等多场景打造领先用户体验。
MoE技术自研与创新
教育部(MoE)是当前业界最前沿的模型框架,由于技术较新,国内开源模型或学术研究尚未普及。元对象自主研发了MoE的高效训练和推理框架,并在三个方向创新:
性能上,针对MoE架构中独特专家路由和权重计算逻辑,研发一套高效融合算子,显著提升了计算效率;针对MoE模型高显存使用和大通信量挑战,设计出计算、通信和显存卸载的重叠操作,有效提高整体处理吞吐量。
架构上,与传统MoE(如Mixtral 8x7B)将每个专家大小等同于标准FFN不同,元象采用更细粒度的专家设计,每个专家大小仅为标准FFN的四分之一,提高了模型灵活性与性能;还将专家分为共享专家(Shared Expert)和非共享专家(Non-shared Expert)两类。共享专家在计算过程中始终保持激活状态,而非共享专家则根据需要选择性激活。这种设计有利于将通用知识压缩至共享专家参数中,减少非共享专家参数间的知识冗余。
训练上,受Switch Transformers、ST-MoE和DeepSeekMoE等启发,元象引入负载均衡损失项,更好均衡专家间的负载;采用路由器z-loss项,确保训练高效和稳定。
架构选择则经过一系列对比实验得出(下图),在 实验3与实验2中,总参数量和激活参数量相同,但前者的细粒度专家设计带来了更高的性能表现。实验4在此基础上,进一步划分共享和非共享两类专家,使得效果显著提升。实验5探索了专家大小等于标准FFN时,引入共享专家的做法,效果不甚理想。
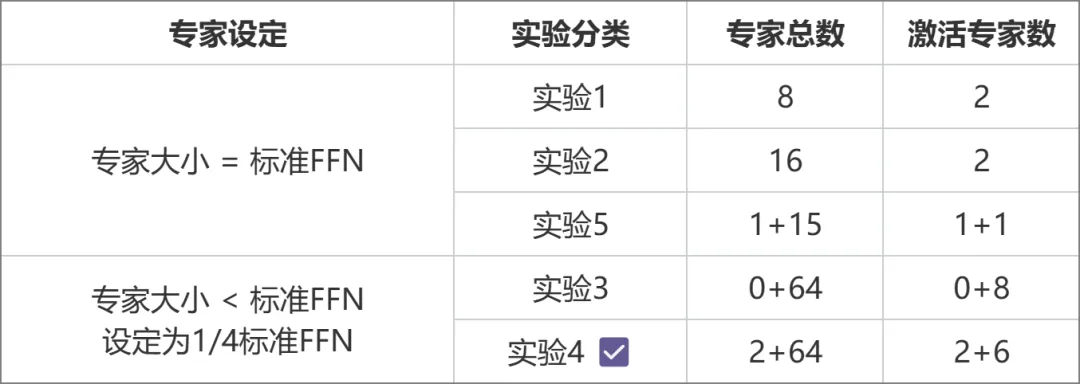
对比实验设计方案
综合试验结果(下图),元象最终采用实验4对应的架构设置。展望未来,新近开源的Google Gemma与X(前Twitter)Grok等项目采用了比标准FFN更大的设定,元象也将在后续继续深入探索相关方向探索研,保持技术引领性。
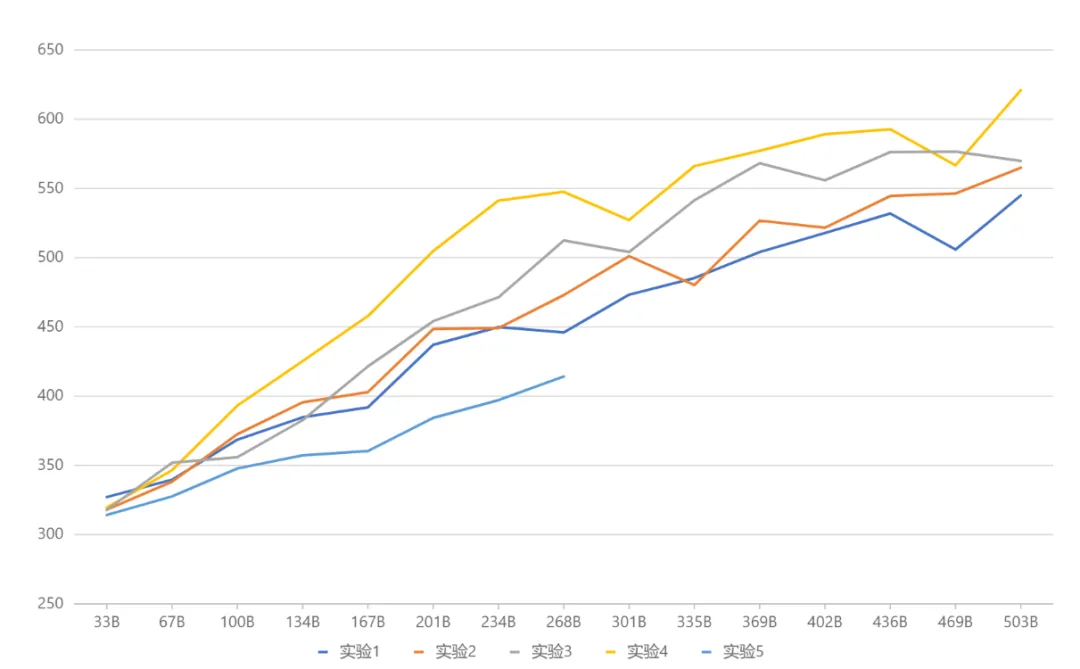
对比实验效果
免费下载大模型
- Hugging Face:https://huggingface.co/xverse/XVERSE-MoE-A4.2B
- ModelScope魔搭:https://modelscope.cn/models/xverse/XVERSE-MoE-A4.2B
- Github:https://github.com/xverse-ai/XVERSE-MoE-A4.2B
- 问询发送:opensource@xverse.cn
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 小米牵头华为、腾讯、OPPO、荣耀联合申请制定单层 HDR 图像格式标准
- 本站3月21日消息,世界超高清视频产业联盟(UWA联盟)日前发布公告,由北京小米电子产品有限公司等单位牵头的《高动态范围(HDR)静态图像第2部分:单层格式》团体标准符合立项要求,现予以批准立项,同时面向会员单位征集参编单位。本站获取到的申请书显示,这一标准立项由小米牵头,小米、中国电子技术标准化研究院、华为、腾讯、OPPO、荣耀联合申请,计划起止时间为2024年3月到2024年12月。根据立项标准,HDR静态图像分发格式将分为单层和双层,其中双层就是HDR+SDR,单层仅有HDR。申请书显示,双层HDR
- 2分钟前 hdr 小米标准 0
-
 正版软件
正版软件
- 蓝鸟将大规模引入比亚迪电动车,推动印尼电动汽车市场发展
- 5月30日消息,印尼最大的出租车运营商蓝鸟(BlueBird)计划大幅采购电动车,其中80%的新增车队将由比亚迪(BYD)提供,而特斯拉(Tesla)的订单也将被重新评估,因为在印尼市场上,更受欢迎的是价格较低的电动车型。蓝鸟总裁SigitPriawanDjokosoetono在接受采访时表示,今年蓝鸟将收到500辆电动车的交付,其中大部分将由比亚迪生产,尤其是E6和T3车型,因为这些车型更适合印尼市场。印尼是全球最大的镍储备国之一,而镍是电池制造的关键材料。目前,印尼正积极发展电动汽车产业,并出台多项措
- 12分钟前 比亚迪 0
-
 正版软件
正版软件
- 小米Redmi Pad Pro曝光:12.1英寸大屏配10000mAh大电池
- 近日,小米旗下子品牌Redmi发布了一则消息,宣布将于4月10日晚发布新款手术RedmiTurbo3。同时,还将推出一款全新的平板设备——RedmiPadPro。这款平板设备备受瞩目,知名数码博主@数码闲聊站提前曝光了这款平板的主要配置。RedmiTurbo3是一款高性能的手机,内置强大的处理器和大容量的存储空间,能够满足用户对于速度和储存的需求。而RedmiPadPro则是一款全新的平板设备,据悉在配置上更加强大,用户可以期待更好的使用体验。由于发布会时间尚未到来,更多关于Redmi这款博主透露,Red
- 27分钟前 0
-
 正版软件
正版软件
- 刚刚发布!一键生成动漫风格图片的开源模型
- 向大家介绍一个最新的AIGC开源项目——AnimagineXL3.1。这个项目是动漫主题文本到图像模型的最新迭代,旨在为用户提供更加优化和强大的动漫图像生成体验。在AnimagineXL3.1中,开发团队着重优化了几个关键方面,以确保模型在性能和功能上达到新的高度。首先,他们扩展了训练数据,不仅包括了之前版本中的游戏角色数据,还加入许多其他知名动漫系列的数据纳入训练集中。这一举措丰富了模型的知识库,使其能够更全面地理解各种动漫风格和角色。AnimagineXL3.1引入了一组新的特殊标签和美学标签,以更好
- 37分钟前 开源 0
-
 正版软件
正版软件
- 苹果获得技术专利,为Apple Car引入创新安全带扣具
- 6月21日消息,根据美国商标和专利局(USPTO)公示的清单,苹果最近获得了一项关于AppleCar的技术专利。该专利展示了一种配有灯光指示的安全带扣具。据悉,斯柯达(Skoda)已经推出了一种类似的亮起安全带扣具。这项名为"带有指示区域的安全带扣具"的专利描述了在AppleCar(尚未确认)汽车中,用户进入后将看到一个红色安全带扣具指示灯,以引导用户正确佩戴安全带。一旦用户将安全带插入扣具,红色指示灯将自动熄灭。据小编了解,苹果的专利描述表示,这种指示灯设计的目的是使司机无需低头摸索,从而更容易找到安全
- 47分钟前 苹果 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1840天前
-
 2
2
- Overture设置踏板标记的方法
- 1677天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1667天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1865天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1831天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1827天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1842天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1863天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00