「有效上下文」提升20倍!DeepMind发布ReadAgent框架
 发布于2024-12-25 阅读(0)
发布于2024-12-25 阅读(0)
扫一扫,手机访问
想了解更多AIGC的内容,
请访问:51CTO AI.x社区
https://www.51cto.com/aigc/
基于Transformer的大语言模型(LLM)具有很强的语言理解能力,但LLM一次能够读取的文本量仍然受到极大限制。
LLM模型的性能受输入内容长度的影响,上下文窗口口较小外,性能会随着输入内容长度的增加而下降,即使输入内容未超过模型的上下文窗口长度限制也是如此。
相比之下,人类却可以阅读、理解和推理很长的文本。
阅读长度上存在差异的主要原因在于阅读法:LLM逐字地输入精确的内容,并且该过程相对被动;然而准确的信息往往会被遗忘,而阅读过程更注重理解模糊的要点信息,即不考虑准确单词的内容能记忆更长时间。
人类阅读也是一个互动的过程,比如回答问题时还需要从原文中进行检索。
为了解决这些限制,Google+DeepMind和Google Research的研究人员提出了一个全新的LLM系统ReadAgent,使人类如何交互式阅读长文档的启发,将有助于上下文长文档长度增加20倍。

论文链接:https://arxiv.org/abs/2402.09727
受人类交互式阅读长文档的启发,研究人员将ReadAgent实现为一个简单的提示系统,使用LLMs的高级语言功能:
1. 决定将哪些内容存储在记忆片段(memory episode)中;
2. 将记忆片段压缩成称为要点记忆的简短片段记忆,
3. 如果ReadAgent需要提醒自己完成任务的相关细节,则采取行动(action)来查找原始文本中的段落。
在实验评估中,相比检索、原始长上下文、要点记忆(gist memories)方法,ReadAgent在三个长文档阅读理解任务(QuALITY,NarrativeQA和QMSum)上的性能表现都优于基线,同时将有效上下文窗口扩展了3-20倍。
ReadAgent框架
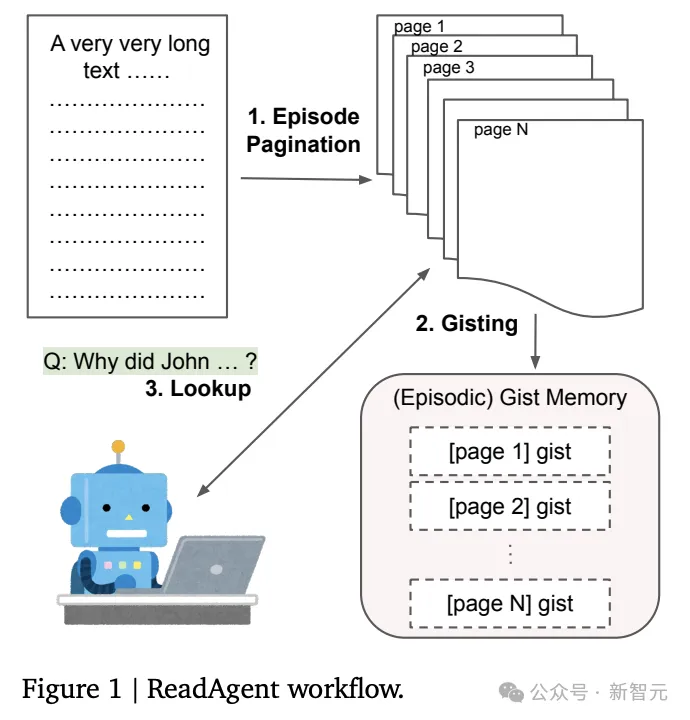
1. 要点记忆(gist memory)
要点记忆是原始长上下文中文本块的短要点的有序集合,构建gist记忆有两个步骤:分页(pagination)和记忆提要(memory gisting)。
片段分页(episode pagination)
当ReadAgent阅读长文本时,通过选择暂停阅读的位置来决定在记忆片段中存储哪些内容。

每一步都会为LLM提供部分文本,从上一个暂停点开始,并在达到最大单词数限制时结束;提示LLM选择段落之间的哪个点将是自然的暂停点,然后将前一个和当前暂停点之间的内容视为一个episode,也可以叫做页(page)。
记忆提要(memory gisting)
对于每一页,提示LLM将确切的内容缩短为要点或摘要。

2. 并行和顺序交互查找
由于要点记忆与页相关,所以只需提示LLM来找出哪一页更像是答案,并在给定特定任务的情况下再次阅读,主要有两种查找策略:同时并行查找所有页面(ReadAgent-P)和每次查找一个页面(ReadAgent-S)。
ReadAgent-P
比如说,在问答任务中,通常会给LLM输入一个可以查找的最大页数,但也会指示其使用尽可能少的页面,以避免不必要的计算开销和干扰信息(distracting information)。

ReadAgent-S
顺序查找策略中,模型一次请求一页,在决定展开(expand)哪个页面之前,先查看之前展开过的页面,从而使模型能够访问比并行查找更多的信息,预期在某些特殊情况下表现得更好。

但与模型的交互次数越多,其计算成本也越高。
3. 计算开销和可扩展性
片段分页、记忆提要和交互式查找需要迭代推理,也存在潜在的计算开销,但具体开销由一个小因子线性约束,使得该方法的计算开销不会输入长度的增加而剧烈提升。
由于查找和响应大多是条件要点(conditioned gists)而非全文,所以在同一上下文中的任务越多,成本也就越低。
4. ReadAgent变体
当使用长文本时,用户可能会提前知道要解决的任务:在这种情况下,提要步骤可以在提示中包括任务描述,使得LLM可以更好地压缩与任务无关的信息,从而提高效率并减少干扰信息,即条件ReadAgent
更通用的任务设置下,在准备提要时可能不知道具体任务,或者可能知道提出的要点需要用于多个不同的任务,例如回答关于文本的问题等。
因此,通过排除注册步骤中的任务,LLM可以产生更广泛有用的提要,代价是减少压缩和增加干扰注意力的信息,即非条件ReadAgent。
这篇论文中只探讨了无条件设置,但在某些情况下,条件设置可能更有优势。
迭代提要(iterative gisting)
对于一段很长的事件历史,例如对话等,可以考虑通过迭代提要来进一步压缩旧记忆来实现更长的上下文,对应于人类的话,旧记忆更模糊。
实验结果
研究人员评估了ReadAgent在三个长上下文问答挑战中的长文档阅读理解能力:QuALITY、NarrativeQA和QMSum。
虽然ReadAgent不需要训练,但研究人员仍然选择在训练集上开发了一个模型并在验证、测试和/或开发集上进行了测试,以避免过拟合系统超参数的风险。
选用的模型为指令微调后的PaLM 2-L模型。
评估指标为压缩率(compression rate, CR),计算方法如下:
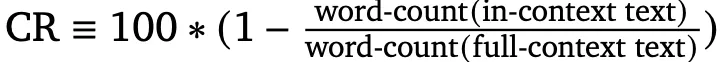
LLM评分器
NarrativeQA和QMSum都有一个或多个自由形式的参考回复,通常使用诸如ROUGE-F之类的语法匹配度量来评估。
除此之外,研究人员使用自动LLM评分器来评估这些数据集,作为人工评估的替代方法。

上面两个提示中,「严格LLM评分器提示」用于判断是否存在精确匹配,「许可LLM评分器提示」用于判断是否存在精确匹配或部分匹配。
基于此,研究人员提出了两个评价指标:LLM-Rating-1(LR-1)是一个严格的评估分数,计算所有示例中精确匹配的百分比;LLM-Rating-2(LR-2)计算精确匹配和部分匹配的百分比。
长上下文阅读理解
QuALITY
QuALITY是一个多选问答任务,每个问题包含四个答案,使用来自多个不同来源的文本数据。
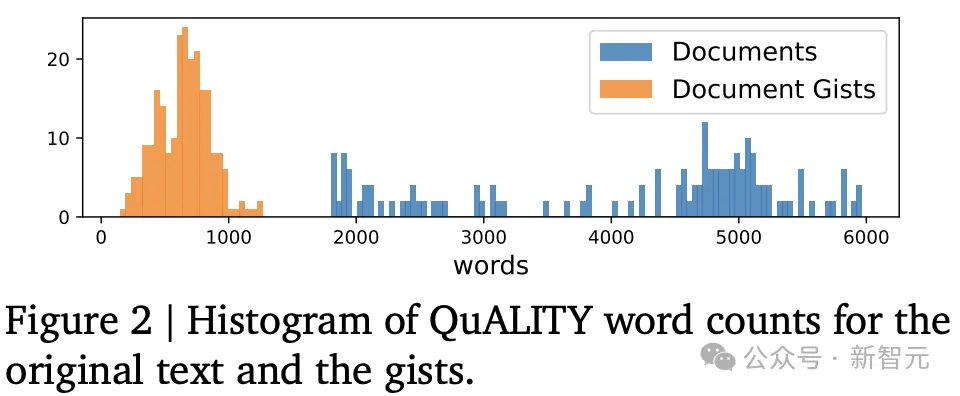
实验结果显示,ReadAgent(查找1-5页)实现了最好的结果,压缩率为66.97%(即提要后上下文窗口中可以容纳3倍的token)。
当增加允许查找的最大页数(最多5页)时,性能会不断提高;在6页时,性能开始略有下降,即6页上下文可能会增加干扰信息。
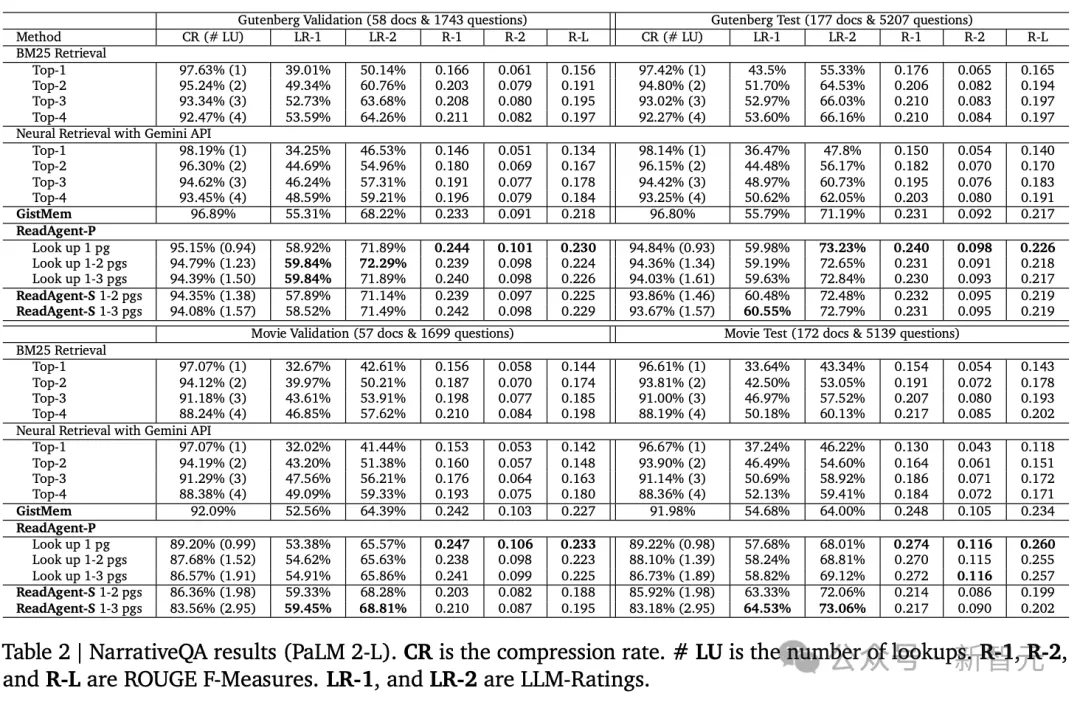
NarrativeQA
在三个阅读理解数据集中,NarrativeQA的平均上下文长度最长,为了将gists放入上下文窗口,需要扩展页面的尺寸大小。
提要对Gutenburg文本(书籍)的压缩率为96.80%,对电影剧本的压缩率为91.98%
QMSum
QMSum由各种主题的会议记录以及相关问题或说明组成,长度从1,000字到26,300字不等,平均长度约为10,000字,其答案是自由形式的文本,标准的评估指标是ROUGE-F
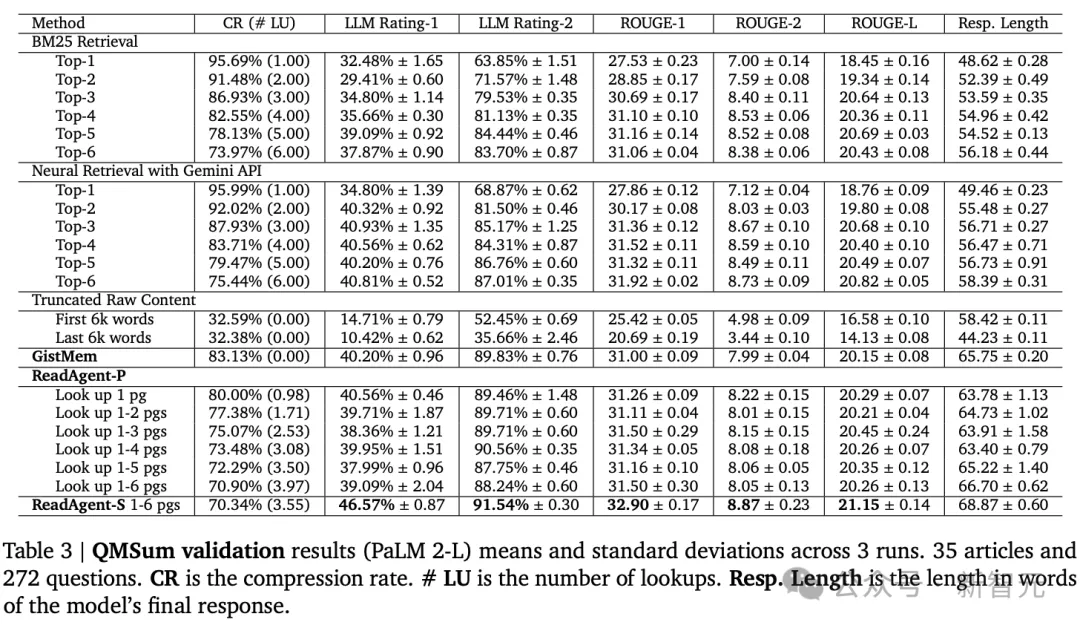
可以看到性能随着压缩率的降低而提高,因此查找更多页面的技术往往比查找更少页面的技术做得更好。
还可以看到ReadAgentS大大优于ReadAgent-P(以及所有基线),性能改进的代价是检索阶段的请求数量增加了六倍。
想了解更多AIGC的内容,
请访问:51CTO AI.x社区
https://www.51cto.com/aigc/
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 加密货币行情软件有哪些好用
- 推荐的加密货币行情软件包括:TradingView:提供全面的图表工具和高级分析功能;Coinigy:适用于专业交易者,提供高级图表功能和市场深度数据;Blockfolio:移动友好的应用程序,用于跟踪投资组合和市场趋势;Delta:多资产跟踪应用程序,提供详细的市场分析和交易历史;Kraken:由领先交易所提供的专业级图表和交易工具;Bitstamp:提供清晰图表和实时交易数据的简洁软件;Bin
- 6分钟前 0
-
 正版软件
正版软件
- imtoken钱包btc地址
- 可以通过访问imToken官网[导入钱包](https://token.im/restore-wallet)导入助记词来找回遗忘的BTC地址。如果无法通过导入助记词找回地址,可联系imToken官方客服提供交易历史记录等信息。其他方式包括检查旧设备、查看交易记录和使用第三方工具。
- 21分钟前 0
-
 正版软件
正版软件
- chz币是什么链上的币
- Chiliz链上的原生代币是CHZ币。该代币用于治理、支付交易费用、质押以获得奖励,并访问合作伙伴提供的独家内容和优惠。
- 36分钟前 0
-
 正版软件
正版软件
- 数字货币是如何交易的
- 数字货币交易包括在交易平台上买卖数字资产。步骤如下:创建数字货币钱包;选择交易平台;资金账户;下单(买单或卖单);匹配订单;执行交易(数字货币和资金转移);确认交易;存储或出售数字货币。
- 46分钟前 0
-
 正版软件
正版软件
- 比特比币交易平台
- 选择比特币交易平台时,应考虑安全性、流动性、交易费用、可用性和客户支持等因素。比特比币交易平台有两种类型:中心化和去中心化。中心化平台由中央实体管理,而去中心化平台基于区块链技术。平台通常提供即时购买和出售比特币、创建和管理交易所订单、查看实时市场数据和图表以及存储加密货币等功能。最佳平台取决于个人的需求和偏好。
- 1小时前 03:50 0













