Llama架构比不上GPT2?神奇token提升10倍记忆?
 发布于2024-12-26 阅读(0)
发布于2024-12-26 阅读(0)
扫一扫,手机访问
一个 7B 规模的语言模型 LLM 能存储多少人类知识?如何量化这一数值?训练时间、模型架构的不同将如何影响这一数值?浮点数压缩 quantization、混合专家模型 MoE、以及数据质量的差异 (百科知识 vs 网络垃圾) 又将对 LLM 的知识容量产生何种影响?
朱泽园(Meta AI)和李远志(MBZUAI)最新研究《语言模型物理学 Part 3.3:知识的Scaling Laws》用海量实验(50,000条任务,总计4,200,000 GPU小时)总结了12条定律,为LLM在不同文件下的知识容量提供了较为精确的计量方法。

作者首先指出,通过开源模型在基准数据集(benchmark)上的表现来衡量LLM的scaling law是不现实的。举例来说,LLaMA-70B在知识数据集上的表现比LLaMA-7B好30%,这并不能说明模型扩大10倍仅能在容量上提高30%。如果使用网络数据训练模型,我们也将很难估计其中包含的知识总量。
再举个例子,我们比较 Mistral 和 Llama 模型的好坏之时,到底是他们的模型架构不同导致的区别,还是他们训练数据的制备不同导致的?
在以上考量,作者采用了他们《语言模型物理学》系列论文的核心思路,即制造人工合成数据,通过控制数据中知识的数量和类型,来严格调控数据中的知识比特(bits)。同时,作者使用不同大小和构架的 LLM 在人工合成数据上进行训练,并给出数学定义,来精确计算训练好的模型从数据中学到了多少比特的知识。

- 论文地址:https://arxiv.org/pdf/2404.05405.pdf
- 论文标题:Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
对于这项研究,有人表示这个方向似乎是合理的。我们可以使用非常科学的方式对scaling law 进行分析。
也有人认为,这项研究将 scaling law 提升到了不同的层次。当然,对于从业者来说是一篇必读论文。
研究概览
作者研究了三种类型的合成数据:bioS、bioR、bioD。bioS 是使用英语模板编写的人物传记,bioR 是由 LlaMA2 模型协助撰写的人物传记(22GB 总量),bioD 则是一种虚拟但可以进一步控制细节的知识数据(譬如可以控制知识的长度、词汇量等等细节)。作者重点研究了基于 GPT2、LlaMA、Mistral 的语言模型架构,其中 GPT2 采用了更新的 Rotary Position Embedding (RoPE) 技术。
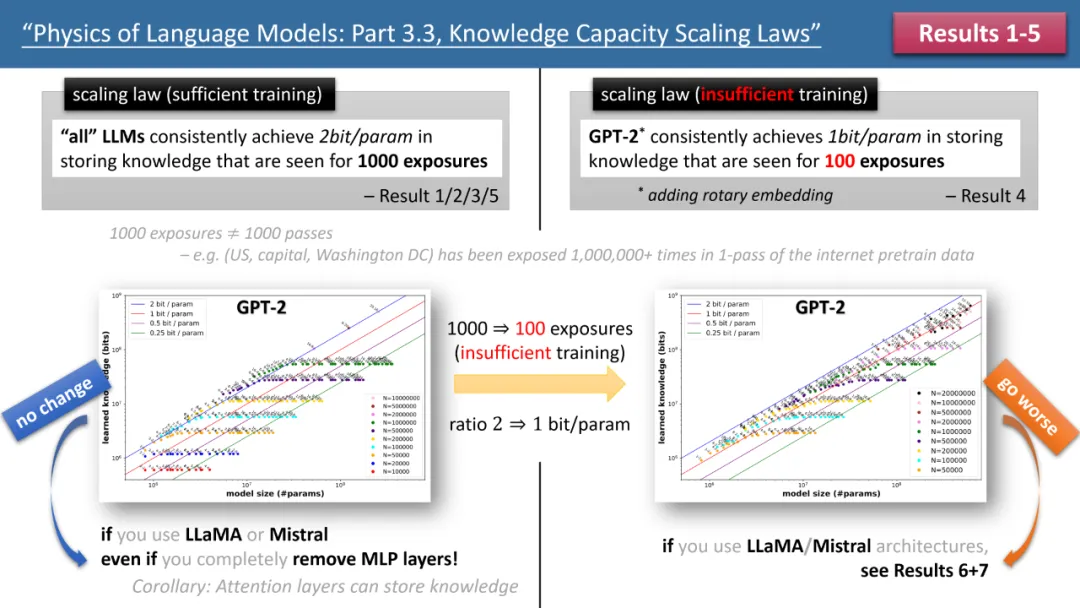
左图为训练时间充足,右图为训练时间不足的 scaling laws
上图 1 简要概述了作者提出的前 5 条定律,其中左 / 右分别对应了「训练时间充足」和 「训练时间不足」两种情况,分别对应了常见知识(如中国首都是北京)和较少出现的知识(如清华物理系成立于 1926 年)。
如果训练时间充足,作者发现,不论使用何种模型架构,GPT2 或 LlaMA/Mistral,模型的存储效率均可以达到 2bit/param—— 即平均每个模型参数可以存储 2 比特的信息。这与模型的深度无关,仅与模型大小有关。换言之,一个 7B 大小的模型,如果训练充足,可以存储 14B 比特的知识,这超过了维基百科和所有英文教科书中人类知识的总和!
更令人惊讶的是,尽管传统理论认为 transformer 模型中的知识主要存储在 MLP 层,但作者的研究反驳了这一观点,他们发现即便移除了所有 MLP 层,模型仍能达到 2bit/param 的存储效率。
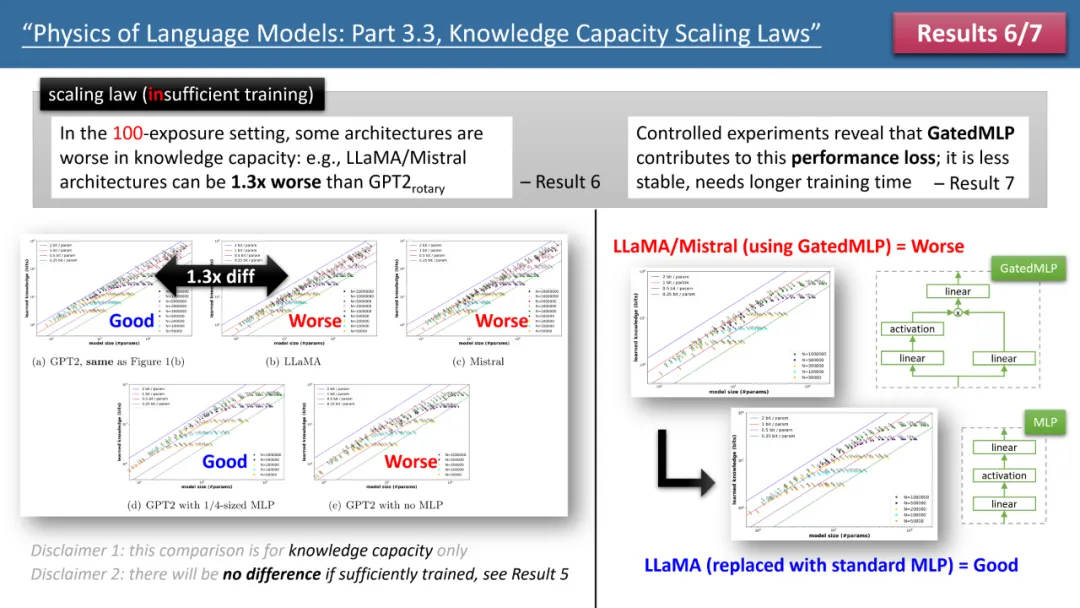
图 2:训练时间不足情况下的 scaling laws
然而,当我们观察训练时间不足的情况时,模型间的差异就显现出来了。如上图 2 所示,在这种情况下,GPT2 模型能比 LlaMA/Mistral 存储超过 30% 的知识,这意味着几年前的模型在某些方面超越了今天的模型。为什么会这样?作者通过在 LlaMA 模型上进行架构调整,将模型与 GPT2 的每个差异进行增减,最终发现是 GatedMLP 导致了这 30% 的损失。
强调一下,GatedMLP 并不会导致模型的「最终」存储率变化 —— 因为图 1 告诉我们如果训练充足它们就不会有差。但是,GatedMLP 会导致训练不稳定,因此对同样的知识,需要更长的训练时间;换句话说,对于较少出现在训练集里的知识,模型的存储效率就会下降。
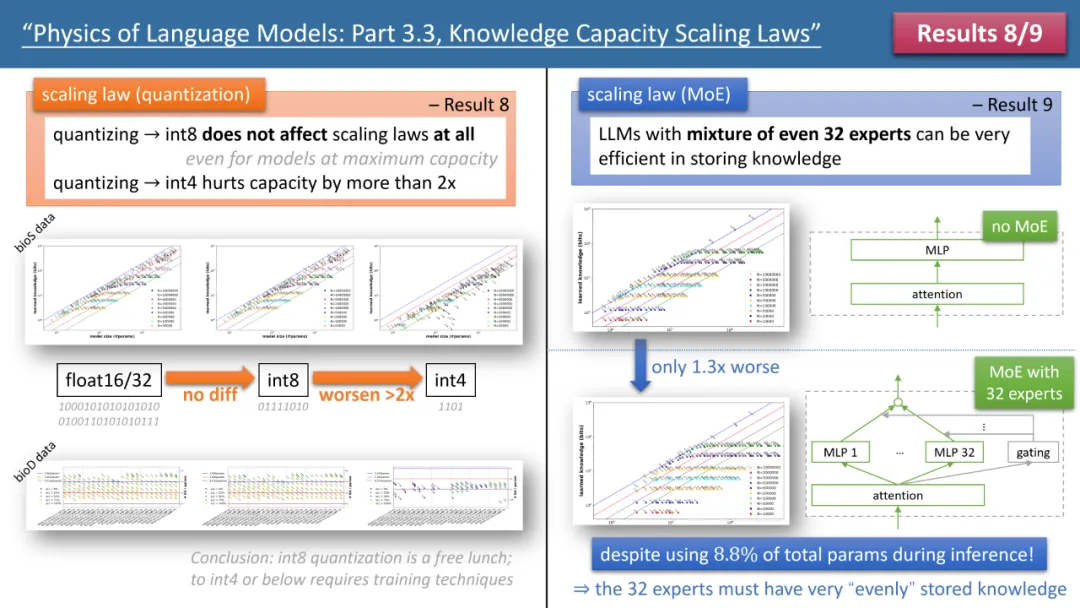
图 3:quantization 和 MoE 对模型 scaling laws 的影响
作者的定律 8 和定律 9 分别研究了 quantization 和 MoE 对模型 scaling law 的影响,结论如上图 3 所示。其中一个结果是,将训练好的模型从 float32/16 压缩到 int8,竟然对知识的存储毫无影响,即便对已经达到 2bit/param 存储极限的模型也是如此。
这意味着,LLM 可以达到「信息论极限」的 1/4—— 因为 int8 参数只有 8 比特,但平均每个参数可以存储 2 比特的知识。作者指出,这是一个普遍法则(universal law),和知识的表现形式无关。
最引人注目的结果来自于作者的定律 10-12(见图 4)。如果我们的 (预) 训练数据中,有 1/8 来自高质量知识库(如百度百科),7/8 来自低质量数据(如 common crawl 或论坛对话,甚至是完全随机的垃圾数据)。
那么,低质量数据是否会影响 LLM 对高质量知识的吸收呢?结果令人惊讶,即使对高质量数据的训练时间保持一致,低质量数据的「存在本身」,可能会让模型对高质量知识的存储量下降 20 倍!即便将高质量数据的训练时间延长 3 倍,知识储量仍会降低 3 倍。这就像是将金子丢进沙子里,高质量数据被严重浪费了。
有什么办法修复呢?作者提出了一个简单但极其有效的策略,只需给所有的 (预) 训练数据加上自己的网站域名 token 即可。例如,将 Wiki 百科数据统统加上 wikipedia.org。模型不需要任何先验知识来识别哪些网站上的知识是「金子」,而可以在预训练过程中,自动发现高质量知识的网站,并自动为这些高质量数据腾出存储空间。
作者提出了一个简单的实验来验证:如果高质量数据都加上一个特殊 token(任何特殊 token 都行,模型不需要提前知道是哪个 token),那么模型的知识存储量可以立即回升 10 倍,是不是很神奇?所以说对预训练数据增加域名 token,是一个极其重要的数据制备操作。
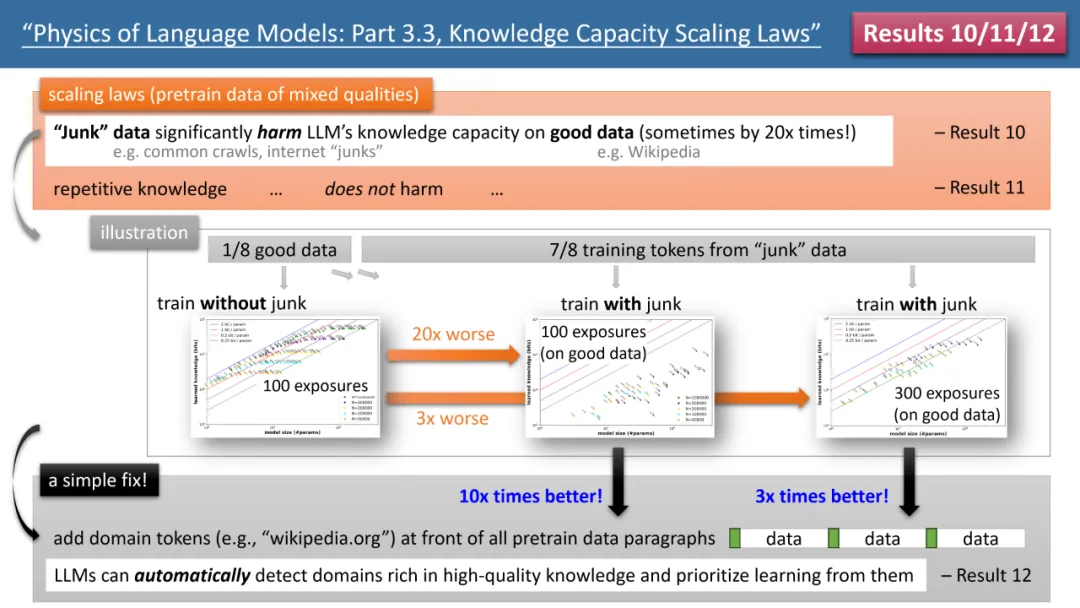
图 4:预训练数据「知识质量不齐」情形下的 scaling laws,模型缺陷以及如何修复
结语
作者认为,通过合成数据,计算模型在训练过程中获得的知识总量的方法,可以为「评估模型架构、训练方法和数据制备」提供了一套系统且精确的打分体系。这和传统的 benchmark 比较完全不同,并且更可靠。他们希望这能帮助未来 LLM 的设计者做出更明智的决策。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 全面突围,谷歌昨晚更新了一大波大模型产品
- 这周二,谷歌在Google的CloudNext2024上发布了一系列AI相关的模型更新和产品,其中包括Gemini1.5Pro首次提供了本地语音(语音)理解功能、代码生成新模型CodeGemma、首款自研Arm处理器Axion等等。Gemini1.5ProGemini1.5Pro是Google功能最强大的生成式AI模型,现已在Google以企业为中心的AI开发平台VertexAI上提供公共预览版。这是谷歌面向企业的AI开发平台。它能处理的上下文从12.8万个token增加到100万个token。100万个
- 7分钟前 模型 AI 0
-
 正版软件
正版软件
- 谷歌承诺投入1500万美元支持人工智能技能培训计划
- 根据外媒报道,谷歌发布了一份名为《人工智能短跑选手》(AISprinters)的新报告,为新兴市场提供了利用人工智能改革潜力的战略路线图。除了这份报告,谷歌还承诺投入1.5亿美元支持人工智能技能培训计划,强调该公司致力于在人工智能时代赋予中国国家权力。人工智能有可能极大地造福世界各地的人们,特别是在拉丁美洲、中东、亚洲和非洲的发展中国家。并且,还可以为基础设施落后、青年失业、教育和医疗机会不均等问题提供创新解决方案。该报告概述了政策制定者利用数字技术推进经济增长的战略。这份最新报告强调,要成为“人工智能短
- 12分钟前 人工智能 0
-
 正版软件
正版软件
- 物联网传感器和人工智能如何彻底改变智能建筑
- 在过去几年中,特别是在COVID-19大流行之后,随着对设施管理人员的期望发生变化以及可持续需求的扩大,建筑管理面临着不断增加和演变。从办公室到更加混合和灵活的工作环境的转变改变了商业建筑的使用方式,需要实时了解建筑使用情况、居住趋势等。不断变化的建筑管理格局表明,迅捷适应新的灵活环境,同时提高整体生产力和性能的解决方案。智能建筑评估自己的设施和改进机会,智能建筑成为一种日益增长的趋势,它不仅有可能简化运营,还可以降低成本并提高所有人的可见性。利用物联网(IoT)、人工智能(AI)、自动化等技术,智能建筑
- 27分钟前 人工智能 物联网 0
-
 正版软件
正版软件
- 鸿蒙生态系统迅猛壮大:原生应用数量激增20倍
- 华为官方最新数据显示,截至8月4日,已有逾4000款应用接入了鸿蒙生态系统。相较于1月18日宣布的首批200个应用,短短两个月内,鸿蒙原生应用的数量急剧增长了20倍,这一显著增长标志着鸿蒙生态系统的迅猛发展和持续壮大。华为对于鸿蒙生态系统的发展寄予了厚望。华为终端云总裁朱勇刚在今年初就明确表示,公司的目标是在2024年和众多合作伙伴携手打造5000款纯粹的鸿蒙原生应用,以继续推动鸿蒙生态的快速发展。同时,华为也计划在今年第四季度正式向消费者推出鸿蒙河版,以满足消费者对于更加便捷、高效的操作系统的需求。华为
- 42分钟前 华为 0
-
 正版软件
正版软件
- 苹果重视用户反馈,持续优化watchOS 10系统
- 7月12日消息,苹果全球产品营销团队成员埃里克・查尔斯(EricCharles)最近接受Tom'sGuide媒体采访,就watchOS10系统的重大改进进行了深入探讨,并特别关注了这些新功能对第三方开发人员及其watchOS应用生态的发展。据了解,watchOS10旨在让用户在抬起手腕时能更加便捷地获取信息,比以往更加直观。为了实现这个目标,苹果通过最大化利用屏幕空间来更丰富地展示内容。其中,Weather应用就是一个成功案例,用户无需深入应用程序即可轻松查看最新的AQI(空气质量指数)、风速等数
- 57分钟前 苹果 0













