使用GaLore在本地GPU进行高效的LLM调优
 发布于2024-12-26 阅读(0)
发布于2024-12-26 阅读(0)
扫一扫,手机访问
训练大型语言模型(llm)是一项计算密集型的任务,即使是那些“只有”70亿个参数的模型也是如此。这种级别的训练需要的资源超出了大多数个人爱好者的能力范围。为了弥补这一差距,出现了低秩适应(LoRA)等参数高效方法,使得在消费级gpu上可以对大量模型进行微调。
GaLore是一种创新方法,它采用优化参数训练方式来减少VRAM需求,而非简单减少参数数量。这意味着GaLore是一种新的模型训练策略,允许模型充分利用全部参数进行学习,并比LoRA更有效地节省内存。
GaLore通过将这些梯度映射到低维空间,有效减轻了计算负担,同时保留了关键的训练信息。与传统优化器在反向传播时一次性更新所有层不同,GaLore采用逐层更新的方式进行反向传播。这种策略显著减少了训练过程中的内存占用,进一步优化了性能。
就像LoRA一样,GaLore使我们能够在消费级GPU上微调7B模型,该GPU配备了高达24 GB的VRAM。结果显示,模型的性能与全参数微调相当,甚至似乎优于LoRA。
优于目前Hugging Face还没有官方代码,我们就来手动使用论文的代码进行训练,并与LoRA进行对比
安装依赖
首先就要安装GaLore
pip install galore-torch
然后我们还要一下这些库,并且请注意版本
datasets==2.18.0 transformers==4.39.1 trl==0.8.1 accelerate==0.28.0 torch==2.2.1
调度器和优化器的类
Galore分层优化器是通过模型权重挂钩激活的。由于我们使用Hugging Face Trainer,还需要自己实现一个优化器和调度器的抽象类。这些类的结构不执行任何操作。
from typing import Optional import torch # Approach taken from Hugging Face transformers https://github.com/huggingface/transformers/blob/main/src/transformers/optimization.py class LayerWiseDummyOptimizer(torch.optim.Optimizer):def __init__(self, optimizer_dict=None, *args, **kwargs):dummy_tensor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrs加载GaLore优化器
GaLore优化器的目标是特定的参数,主要是那些在线性层中以attn或mlp命名的参数。通过系统地将函数与这些目标参数挂钩,GaLore 8位优化器就会开始工作。
from transformers import get_constant_schedule from functools import partial import torch.nn import bitsandbytes as bnb from galore_torch import GaLoreAdamW8bit def load_galore_optimizer(model, lr, galore_config):# function to hook optimizer and scheduler to a given parameter def optimizer_hook(p, optimizer, scheduler):if p.grad is not None: optimizer.step()optimizer.zero_grad()scheduler.step() # Parameters to optimize with Galoregalore_params = [(module.weight, module_name) for module_name, module in model.named_modules() if isinstance(module, nn.Linear) and any(target_key in module_name for target_key in galore_config["target_modules_list"])] id_galore_params = {id(p) for p, _ in galore_params} # Hook Galore optim to all target params, Adam8bit to all othersfor p in model.parameters():if p.requires_grad:if id(p) in id_galore_params:optimizer = GaLoreAdamW8bit([dict(params=[p], **galore_config)], lr=lr)else:optimizer = bnb.optim.Adam8bit([p], lr = lr)scheduler = get_constant_schedule(optimizer) p.register_post_accumulate_grad_hook(partial(optimizer_hook, optimizer=optimizer, scheduler=scheduler)) # return dummies, stepping is done with hooks return LayerWiseDummyOptimizer(), LayerWiseDummyScheduler()HF Trainer
准备好优化器后,我们开始使用Trainer进行训练。下面是一个简单的例子,使用TRL的SFTTrainer (Trainer的子类)在Open Assistant数据集上微调llama2-7b,并在RTX 3090/4090等24 GB VRAM GPU上运行。
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, set_seed, get_constant_schedule from trl import SFTTrainer, setup_chat_format, DataCollatorForCompletionOnlyLM from datasets import load_dataset import torch, torch.nn as nn, uuid, wandb lr = 1e-5 # GaLore optimizer hyperparameters galore_config = dict(target_modules_list = ["attn", "mlp"], rank = 1024, update_proj_gap = 200, scale = 2, proj_type="std" ) modelpath = "meta-llama/Llama-2-7b" model = AutoModelForCausalLM.from_pretrained(modelpath,torch_dtype=torch.bfloat16,attn_implementation = "flash_attention_2",device_map = "auto",use_cache = False, ) tokenizer = AutoTokenizer.from_pretrained(modelpath, use_fast = False) # Setup for ChatML model, tokenizer = setup_chat_format(model, tokenizer) if tokenizer.pad_token in [None, tokenizer.eos_token]: tokenizer.pad_token = tokenizer.unk_token # subset of the Open Assistant 2 dataset, 4000 of the top ranking conversations dataset = load_dataset("g-ronimo/oasst2_top4k_en") training_arguments = TrainingArguments(output_dir = f"out_{run_id}",evaluation_strategy = "steps",label_names = ["labels"],per_device_train_batch_size = 16,gradient_accumulation_steps = 1,save_steps = 250,eval_steps = 250,logging_steps = 1, learning_rate = lr,num_train_epochs = 3,lr_scheduler_type = "constant",gradient_checkpointing = True,group_by_length = False, ) optimizers = load_galore_optimizer(model, lr, galore_config) trainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset["train"],eval_dataset = dataset['test'],data_collator = DataCollatorForCompletionOnlyLM(instruction_template = "<|im_start|>user", response_template = "<|im_start|>assistant", tokenizer = tokenizer, mlm = False),max_seq_length = 256,dataset_kwargs = dict(add_special_tokens = False),optimizers = optimizers,args = training_arguments, ) trainer.train()GaLore优化器带有一些需要设置的超参数如下:
target_modules_list:指定GaLore针对的层
rank:投影矩阵的秩。与LoRA类似,秩越高,微调就越接近全参数微调。GaLore的作者建议7B使用1024
update_proj_gap:更新投影的步骤数。这是一个昂贵的步骤,对于7B来说大约需要15分钟。定义更新投影的间隔,建议范围在50到1000步之间。
scale:类似于LoRA的alpha的比例因子,用于调整更新强度。在尝试了几个值之后,我发现scale=2最接近于经典的全参数微调。
微调效果对比
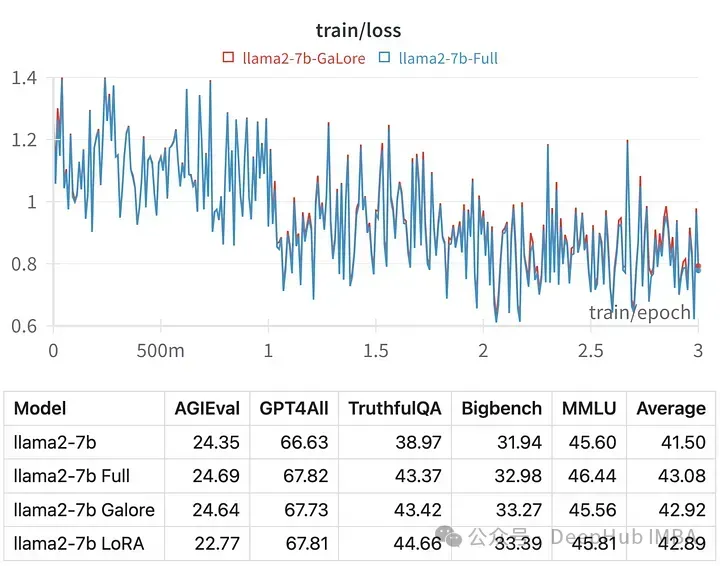
给定超参数的训练损失与全参数调优的轨迹非常相似,表明GaLore分层方法确实是等效的。
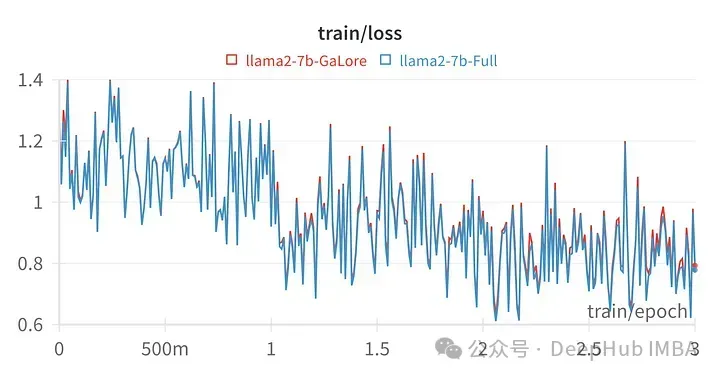
用GaLore训练的模型得分与全参数微调非常相似。
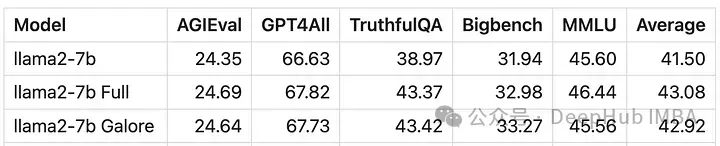
GaLore可以节省大约15 GB的VRAM,但由于定期投影更新,它需要更长的训练时间。
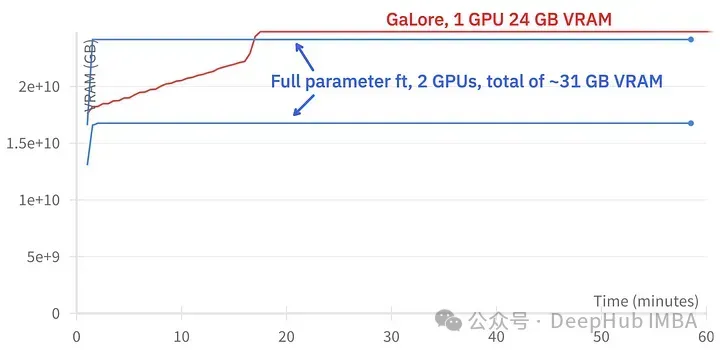
上图为2个3090的内存占用对比
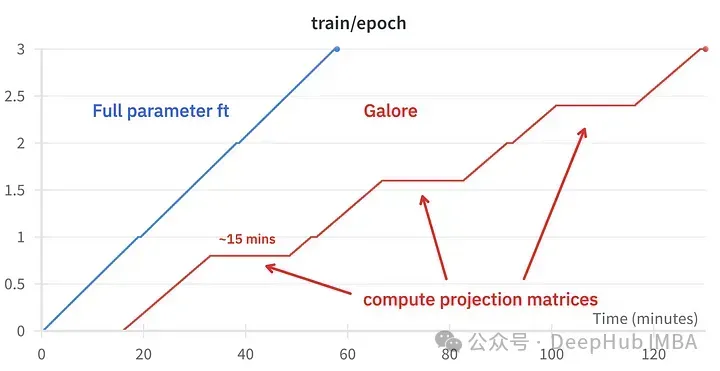
训练事件对比,微调:~58分钟。GaLore:约130分钟
最后我们再看看GaLore和LoRA的对比
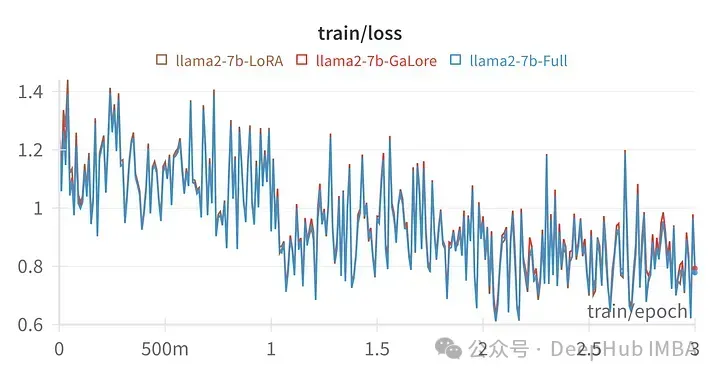
上图为LoRA微调所有线性层,rank64,alpha 16的损失图
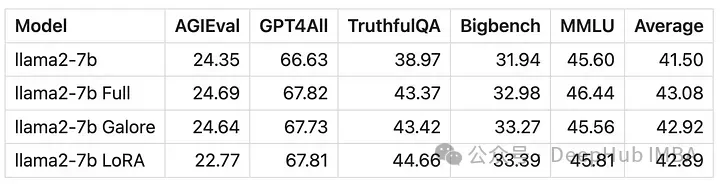
从数值上可以看到GaLore是一种近似全参数训练的新方法,性能与微调相当,比LoRA要好得多。
总结
GaLore可以节省VRAM,允许在消费级GPU上训练7B模型,但是速度较慢,比微调和LoRA的时间要长差不多两倍的时间。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 消息称三星建议所有子公司高管单双休,部门主管以下级别员工无影响
- 根据《朝鲜日报》报道,三星集团已确认将适用于三星电子等部分关联公司的“高管每周工作6天”扩大到整个集团。据报道,三星SDI、三星电机、三星SDS和三星显示的高管被建议每两个周末工作一天(本站注:俗称“大小周”)。作为回应,三星公司的高管们取消了提前预约的周末工作。三星子公司的人力资源团队直接通过口头、群聊和电子邮件向高管传达了这一新政,而非正式信函的形式。其中一家子公司的高管表示,“当前电子产品形势很糟糕。若是对电子产品不利,就会对整个公司和国家经济都造成影响。”据悉,三星子公司的内部对此反应不一,有人称
- 7分钟前 三星 0
-
 正版软件
正版软件
- IDC报告:iPhone全球出货量下滑,华为Mate 60系列势头强劲
- 据市场调研机构IDC最新发布的报告指出,2019年1月至3月期间,苹果iPhone的全球出货量出现了下滑,下降了9.6%。这是4月15日消费消息的微调。这一趋势实际早有预兆,从苹果近期的一系列促销活动中可窥一斑。在圣诞节以及中国新年的促销季中,苹果对iPhone进行了降价销售,甚至在其官方网站上直接推出了优惠活动。而在第三方销售渠道,iPhone的价格更是进一步下滑,原本7899元的iPhone15Pro256GB版本,现在消费者大约只需7200元左右即可入手,价格差接近2000元。然而,即使有如此明显的
- 17分钟前 苹果 0
-
 正版软件
正版软件
- 苹果终止电车项目后大裁员,押注家用机器人,这会是Next Big Thing吗?
- 新的出路,苹果能让我们耳目一新吗?苹果公司压力山大,何以见得?苹果公司的电动汽车项目在今年二月份取消了,他们还决定放弃为AppleWatch自主生产下一代屏幕的尝试。这两个项目都因成本超支和上市延迟而受阻。此外,混合现实眼镜还需要多年时间才能成为苹果主要的盈利点。在这样的情况下,苹果面临着巨大的收入压力。图源:彭博社一些电动汽车项目的少数剩余员工将被转移至苹果公司的生产式AI项目。其他人将有90天时间在公司内部找到其他角色的重新分配,否则就会被解雇。内部员工透露,在取消前,汽车项目仍有大约1400名员工在
- 32分钟前 产业 苹果公司 家用机器人 0
-
 正版软件
正版软件
- 比亚迪“豹 3”预告图曝光,春季发布会引爆期待
- 4月13日消息,比亚迪旗下品牌程豹近日发布了旗下新款车型“豹3”的预告图,引起了车迷们的热烈关注。据悉,这款备受期待的新车将在即将到来的4月16日方程豹汽车春季发布会上揭开神秘面纱。豹3以独特的设计理念和鲜明的个性特点吸引了众多目光。其设计理念可概括为以潮酷之“方”,创造张扬灵动的个性之“华”。这款车型定位为纯电动硬派SUV,是基于DMO超级混动越野平台精心打造的杰作。相较于豹5,豹3的车身尺寸更为紧凑,成为方程豹“583硬派家族”中的全新一员。数据小编了解到,从先前曝光的谍照中可以看出,豪华的外观设计与
- 47分钟前 0
-
 正版软件
正版软件
- 明天起这些新规将影响你我生活:含新的《快递服务》国家标准等
- 本站3月31日消息,本站从中国政府网获悉,4月起,一系列新规将实施,影响你我生活。新修订的《快递服务》国家标准4月1日起实施市场监管总局日前发布了新修订的《快递服务》国家标准,自2024年4月1日起实施。《标准》对用户下单和投递方式进行了细分,更好适应寄递用户个性化需求。增加智能化服务要求,包括智能安检系统和智能邮箱、智能快件箱、无人车等智能投递服务终端相关要求,推动新技术在快递行业的应用。《限制商品过度包装要求生鲜食用农产品》自4月1日起实施该标准明确主要技术指标包括三方面:一是针对不同类别和不同销售包
- 1小时前 14:10 人脸识别 快递 0













