谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
 发布于2024-12-27 阅读(0)
发布于2024-12-27 阅读(0)
扫一扫,手机访问
谷歌力推的JAX在最近的基准测试中性能已经超过Pytorch和TensorFlow,7项指标排名第一。

而且测试并不是在JAX性能表现最好的TPU上完成的。

虽然现在在开发者中,Pytorch依然比Tensorflow更受欢迎。
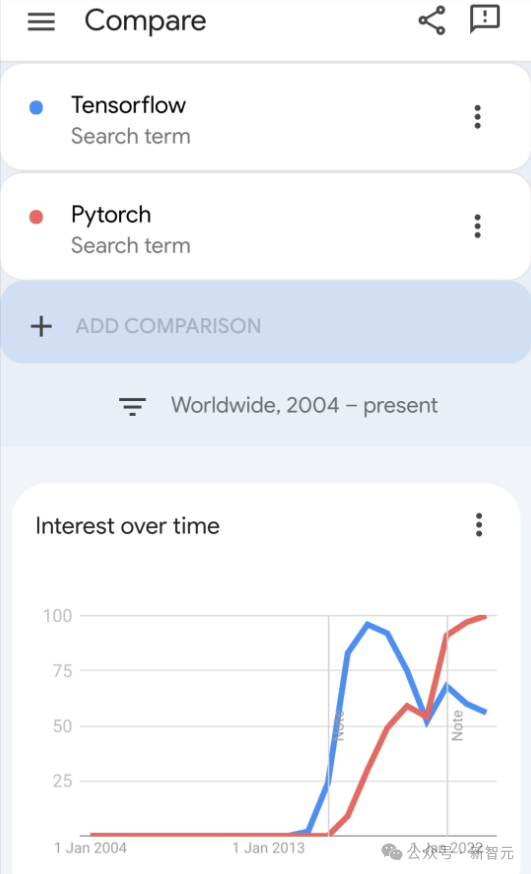
但未来,也许有更多的大模型会基于JAX平台进行训练和运行。
模型
最近,Keras团队为三个后端(TensorFlow、JAX、PyTorch)与原生PyTorch实现以及搭配TensorFlow的Keras 2进行了基准测试。
首先,他们为生成式和非生成式人工智能任务选择了一组主流的计算机视觉和自然语言处理模型:

对于模型的Keras版本,其采用了KerasCV和KerasNLP中已有的实现进行构建。而对于原生的PyTorch版本,则选择了网络上最流行的几个选项:
- 来自HuggingFace Transformers的BERT、Gemma、Mistral
- 来自HuggingFace Diffusers的StableDiffusion
- 来自Meta的SegmentAnything
他们将这组模型称作「Native PyTorch」,以便与使用PyTorch后端的Keras 3版本进行区分。
他们对所有基准测试都使用了合成数据,并在所有LLM训练和推理中使用了bfloat16精度,同时在所有LLM训练中使用了LoRA(微调)。
根据PyTorch团队的建议,他们在原生PyTorch实现中使用了torch.compile(model, mode="reduce-overhead")(由于不兼容,Gemma和Mistral训练除外)。
为了衡量开箱即用的性能,他们使用高级API(例如HuggingFace的Trainer()、标准PyTorch训练循环和Keras model.fit()),并尽可能减少配置。
硬件配置
所有基准测试均使用Google Cloud Compute Engine进行,配置为:一块拥有40GB显存的NVIDIA A100 GPU、12个虚拟CPU和85GB的主机内存。
基准测试结果
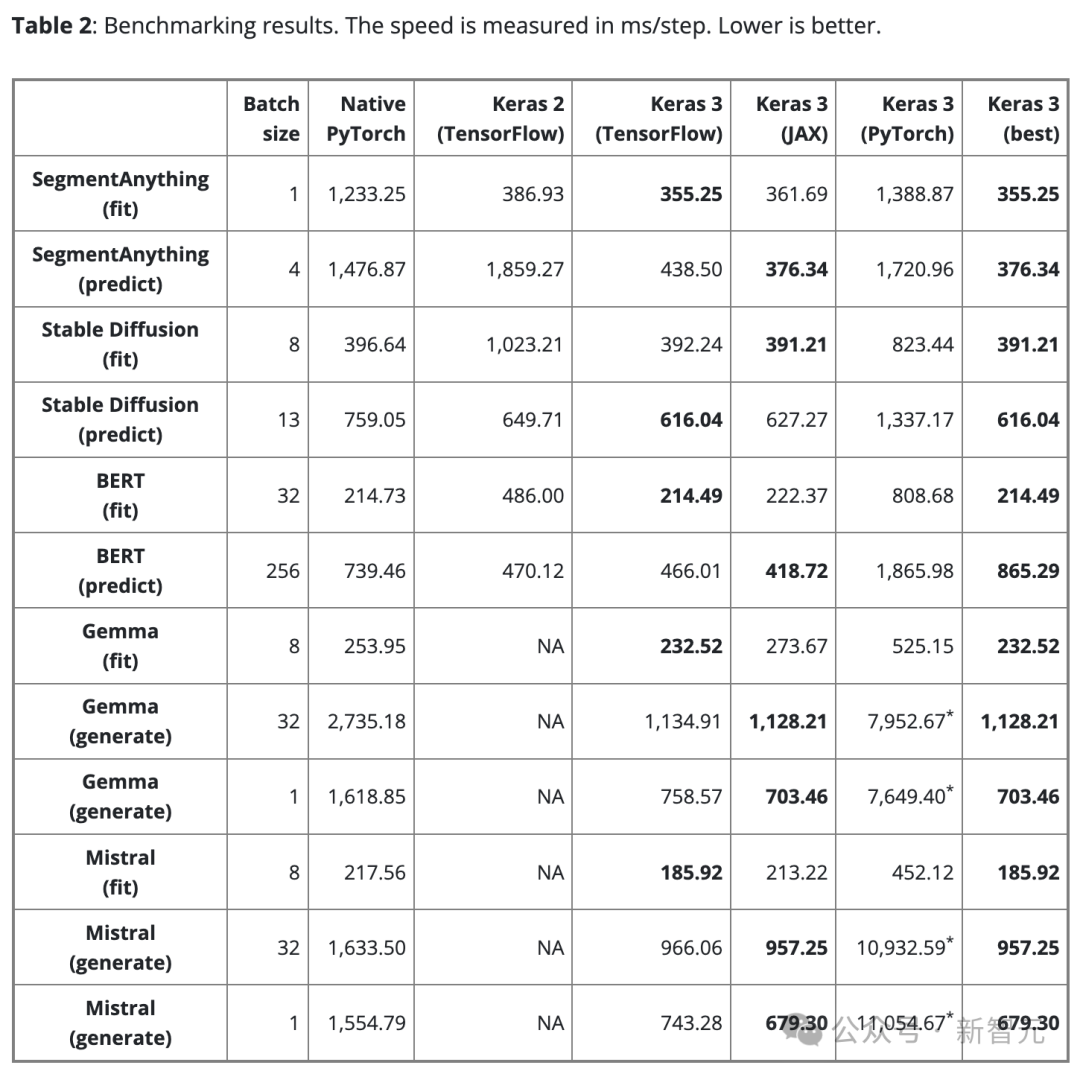
表2显示了基准测试结果(以步/毫秒为单位)。每步都涉及对单个数据批次进行训练或预测。
结果是100步的平均值,但排除了第一个步,因为第一步包括了模型创建和编译,这会额外花费时间。
为了确保比较的公平性,对于相同的模型和任务(不论是训练还是推理)都使用相同的批大小。
然而,对于不同的模型和任务,由于它们的规模和架构有所不同,可根据需要调整数据批大小,从而避免因过大而导致内存溢出,或是批过小而导致GPU使用不足。
过小的批大小也会使PyTorch看起来较慢,因为会增加Python的开销。
对于大型语言模型(Gemma和Mistral),测试时也使用了相同的批处理大小,因为它们是相同类型的模型,具有类似数量的参数(7B)。
考虑到用户对单批文本生成的需求,也对批大小为1的文本生成情况进行了基准测试。
关键发现
发现1
不存在「最优」后端。
Keras的三种后端各展所长,重要的是,就性能而言,并没有哪一个后端能够始终胜出。
选择哪个后端最快,往往取决于模型的架构。
这一点突出了选择不同框架以追求最佳性能的重要性。Keras 3可以帮助轻松切换后端,以便为模型找到最合适的选择。
发现2
Keras 3的性能普遍超过PyTorch的标准实现。
相对于原生PyTorch,Keras 3在吞吐量(步/毫秒)上有明显的提升。
特别是,在10个测试任务中,有5个的速度提升超过了50%。其中,最高更是达到了290%。
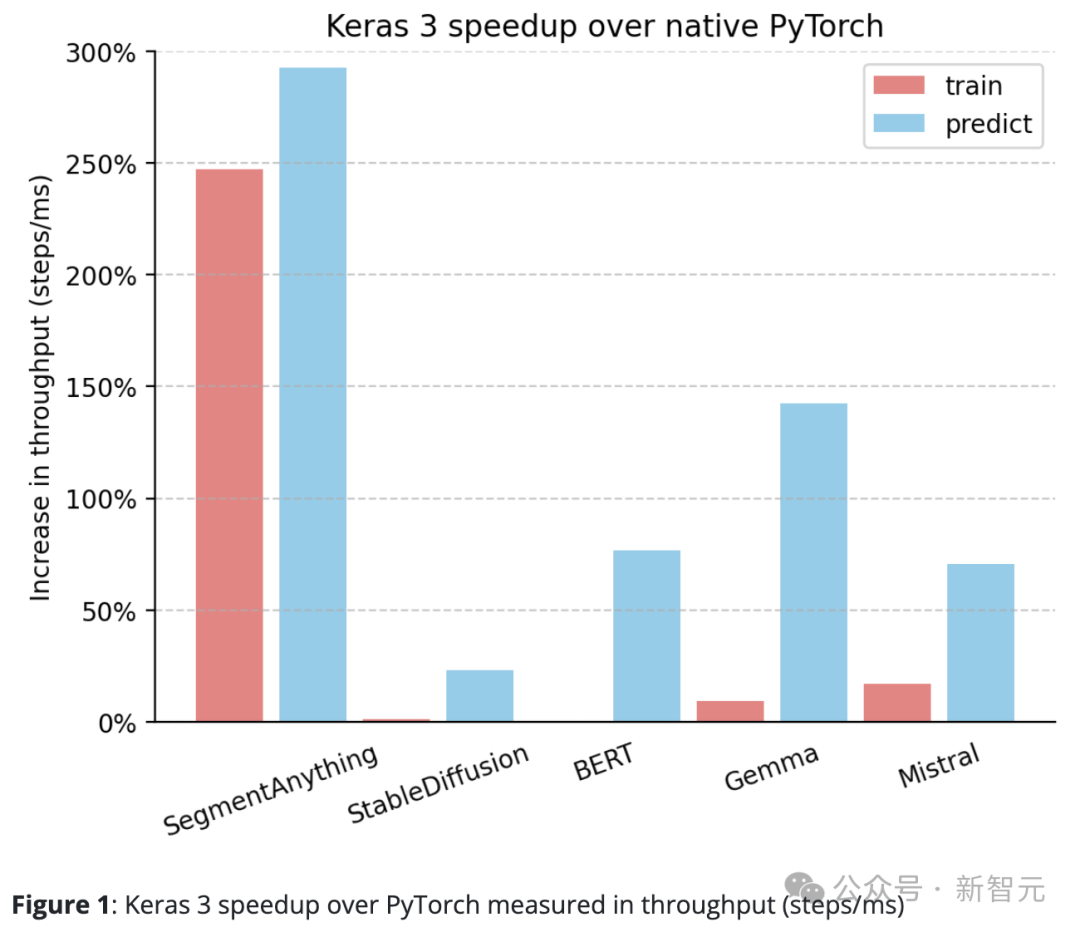
如果是100%,意味着Keras 3的速度是PyTorch的2倍;如果是0%,则表示两者性能相当
发现3
Keras 3提供一流的「开箱即用」性能。
也就是,所有参与测试的Keras模型都未进行过任何优化。相比之下,使用原生PyTorch实现时,通常需要用户自行进行更多性能优化。
除了上面分享的数据,测试中还注意到在HuggingFace Diffusers的StableDiffusion推理功能上,从版本0.25.0升级到0.3.0时,性能提升超过了100%。
同样,在HuggingFace Transformers中,Gemma从4.38.1版本升级至4.38.2版本也显著提高了性能。
这些性能的提升凸显了HuggingFace在性能优化方面的专注和努力。
对于一些手动优化较少的模型,如SegmentAnything,则使用了研究作者提供的实现。在这种情况下,与Keras相比,性能差距比大多数其他模型更大。
这表明,Keras能够提供卓越的开箱即用性能,用户无需深入了解所有优化技巧即可享受到快速的模型运行速度。
发现4
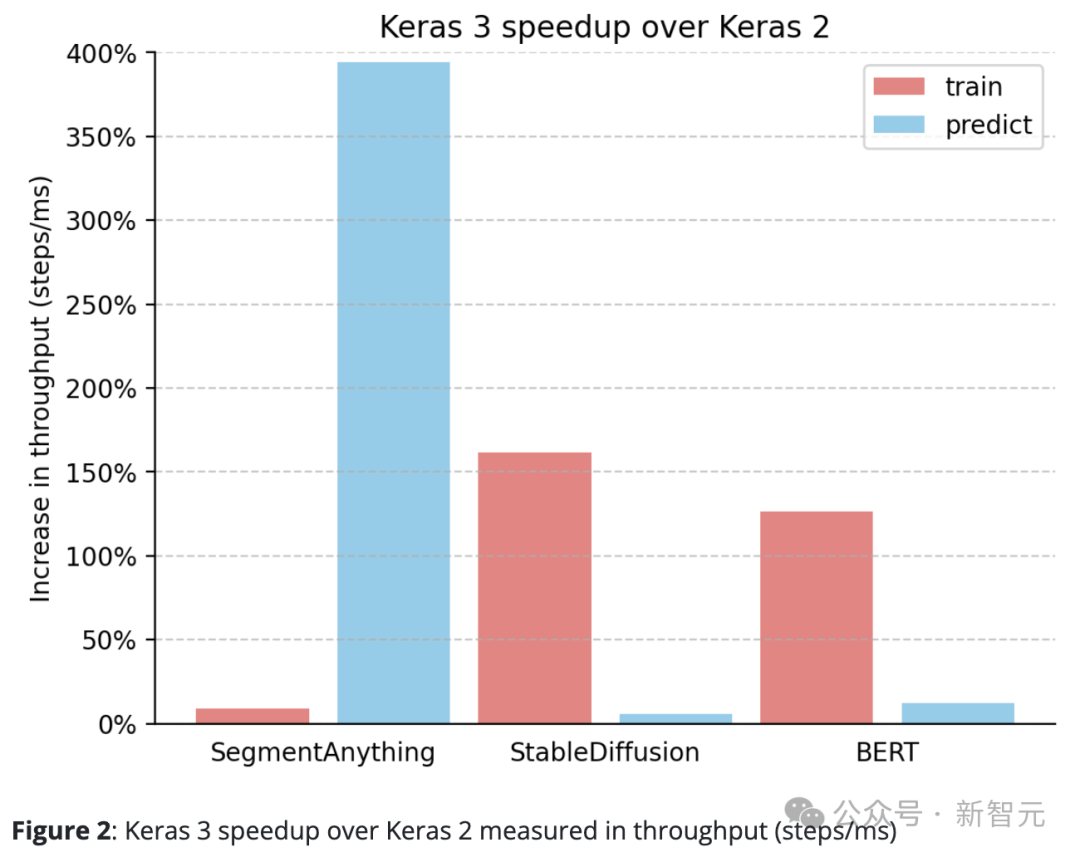
Keras 3的表现始终优于Keras 2。
例如,SegmentAnything的推理速度提升了惊人的380%,StableDiffusion的训练处理速度提升了150%以上,BERT的训练处理速度也提升了100%以上。
这主要是因为Keras 2在某些情况下直接使用了更多的TensorFlow融合操作,而这可能对于XLA的编译并不是最佳选择。
值得注意的是,即使仅升级到Keras 3并继续使用TensorFlow后端,也能显著提升性能。
结论
框架的性能在很大程度上取决于具体使用的模型。
Keras 3能够帮助为任务选择最快的框架,这种选择几乎总能超越Keras 2和PyTorch实现。
更为重要的是,Keras 3模型无需进行复杂的底层优化,即可提供卓越的开箱即用性能。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- OLED屏幕加持!下一代iPad Pro即将登场
- 最新报道指出,4月10日消息,据最新报道,即将推出的下一代iPadPro将首次配备OLED显示屏。这一消息在iPadOS17.5的首个测试版本代码中得到了进一步证实。知名科技网站9to5Mac深入挖掘了该测试版本代码,并发现了四款尚未公开发布的iPad机型,其中明确提及了新的显示技术。这一技术将为iPadPro带来更出色的显示效果,为用户提供更加流畅的操作体验。这些新发布的iPad型号,即iPad16,3、iPad16,4、iPad16,5和iPad16,6,极有可能是即将面世的下一代iPadPro系列。
- 8分钟前 苹果 0
-
 正版软件
正版软件
- W377智能手表芯片亮点揭秘:性能升级、安全加固
- 5月31日消息,紫光展锐今日发布了一款全新的智能手表芯片W377。该芯片以安全防护为核心升级,采用安卓8.1操作系统,引入更加安全的机制,并对后台服务做出更严格的限制,从而全面提升身份鉴别、访问控制、数据安全、安全审计和个人信息保护等信息安全方面的防护水平。W377智能手表芯片采用双核ArmCortexA53处理器,主频高达1.3GHz。与上一代产品相比,W377在尺寸更小的封装中显著提升了多媒体能力。此外,W377集成了2G/3G/4G、蓝牙、Wi-Fi和GNSS功能,采用灵活的PCB布局,并采用了28
- 23分钟前 紫光展锐 0
-
 正版软件
正版软件
- AI武器化成为地下论坛的热门话题
- 根据传统观念,驱动式攻击被定义为从受损网站自动下载恶意文件而无需用户交互。然而,在报告期间审查的大多数情况中,都涉及用户操作——在超过30%的事件中促进了初步访问。威胁行为者用AI自动化攻击在主要的网络犯罪论坛上,使用人工智能加速这些攻击正受到越来越多的关注,对武器化这项技术的兴趣也在增长。研究人员在这些网站的专业AI和机器学习部分发现了犯罪分子对主流聊天机器人的替代选择,如FraudGPT和WormGPT,并暗示使用这些选项开发简单恶意软件和分布式拒绝服务(DDoS)查询。AI系统现在可以使用样本复制声
- 38分钟前 人工智能 网络攻击 0
-
 正版软件
正版软件
- 工业自动值得关注的趋势和技术
- 每天都有工业自动化技术在发展和变化。企业利用先进的技术来解决日常工作流程的挑战。数字技术的发展和集成不断推动着新的工业自动化市场。到2028年,工业自动化领域的规模将超过2950亿美元。虽然工业自动化解决方案各不相同,但它们都依赖于共同的支持技术。随着工业行业采用数据驱动的操作,对先进技术的需求也在增加。这些技术最大限度地发挥了工业自动化系统的潜力和投资回报。哪些技术和趋势将塑造工业自动化系统的未来?该领域的参与者如何利用它们来提供更强大的产品?软件可编程逻辑控制器PLC(可编程逻辑控制器)在过去几年一直
- 58分钟前 人工智能 网络安全 0
-
 正版软件
正版软件
- nuScenes最新SOTA | SparseAD:稀疏查询助力高效端到端自动驾驶!
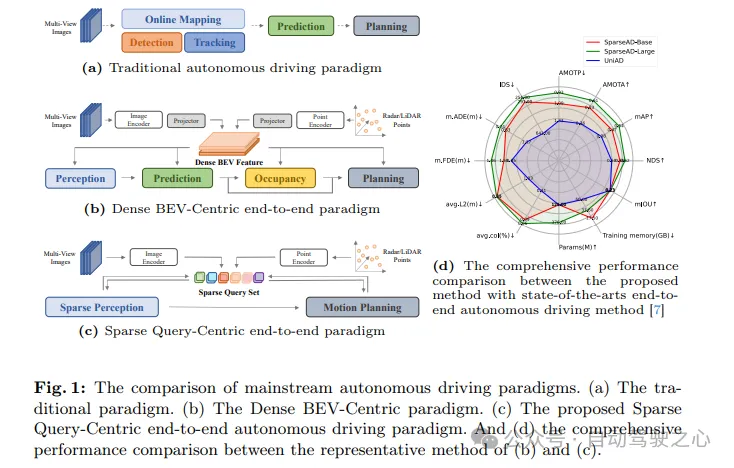
- 写在前面&出发点端到端的范式使用统一的框架在自动驾驶系统中实现多任务。尽管这种范式具有简单性和清晰性,但端到端的自动驾驶方法在子任务上的性能仍然远远落后于单任务方法。同时,先前端到端方法中广泛使用的密集鸟瞰图(BEV)特征使得扩展到更多模态或任务变得困难。这里提出了一种稀疏查找为中心的端到端自动驾驶范式(SparseAD),其中稀疏查找完全代表整个驾驶场景,包括空间、时间和任务,无需任何密集的BEV表示。具体来说,设计了一个统一的稀疏架构,用于包括检测、跟踪和在线地图绘制在内的任务感知。此外,重新
- 1小时前 16:10 自动驾驶 端到端 0













