Nat. Mach. Intell.|设计超高效疫苗,普林斯顿团队开发首个解码mRNA序列大模型
 发布于2024-12-27 阅读(0)
发布于2024-12-27 阅读(0)
扫一扫,手机访问
图来自网络
编辑 | ScienceAI
普林斯顿王梦迪团队迎来了一项具有划时代意义的突破。该团队开发了世界首个解码mRNA非翻译区域序列的大模型,用于准确预测mRNA到蛋白质的转录功能,并设计新序列以应用于mRNA疫苗。这一突破有助于加速疫苗开发和设计,提高蛋白质转录的效率和准确性,为治疗和预防疾病提供新的可能性。
该研究论文的题目是「A 5’ UTR Language Model for Decoding Untranslated Regions of mRNA and Function Predictions」,已被《Nature Machine Intelligence》接收。
这篇论文意味着大语言模型可用于预测和设计mRNA疫苗,其中新设计的序列经过实验证实远高于传统疫苗的转录效率。人工智能和语言模型正在领军生物学和制药研究中的传统方法。

论文链接:https://www.nature.com/articles/s42256-024-00823-9
mRNA和mRNA疫苗
2023年诺贝尔生理学或医学奖授予了mRNA技术的两位奠基人—Katalin Karikó和Drew Weissman,表彰他们对mRNA机理研究和疫苗研发的奠基性,以及mRNA疫苗对人类健康的重大贡献。他们的研究不仅深化了我们对mRNA与免疫系统互动方式的理解,而且推动了mRNA疫苗开发的历史性突破。
mRNA,全名信使核糖核酸,是生物体内至关重要的遗传物质。mRNA是单链的碱基序列,从DNA转录而来,其作用是将DNA中的遗传信息转化为蛋白质的合成指令,通过翻译(translation)产生特定的蛋白质。mRNA如何转录?如何调控蛋白质的合成?这些是生物学领域中最重要的问题之一,通过研究mRNA,科学家们希望能解码生命的奥秘。
mRNA分为中间的编码区(coding region) 和两端的非编码区(untranslated region, or UTR)。编码区的碱基序列对应着目标蛋白质的氨基酸序列, 科学家们已经掌握了编码区域和蛋白质的序列对应关系。mRNA最神秘的部分是非编码区,尤其是前端的非编码区(5’ UTR)。原因在于mRNA的非编码区的碱基序列深度参与并调控了编码区序列的转录过程,非编码区碱基序列和细胞里其他分子交互,调控了蛋白质的表达, 合成效率, 以及本身的稳定性等。
因此,在mRNA疫苗设计中,精确设计其非编码区序列,将直接决定mRNA序列在细胞里的翻译效率,最终决定了疫苗的有效性。深入研究mRNA的非编码区是重要的生物学问题,不仅有助于揭示基因表达的复杂机制,而且在疫苗设计和疾病治疗策略的开发中起到了关键作用。
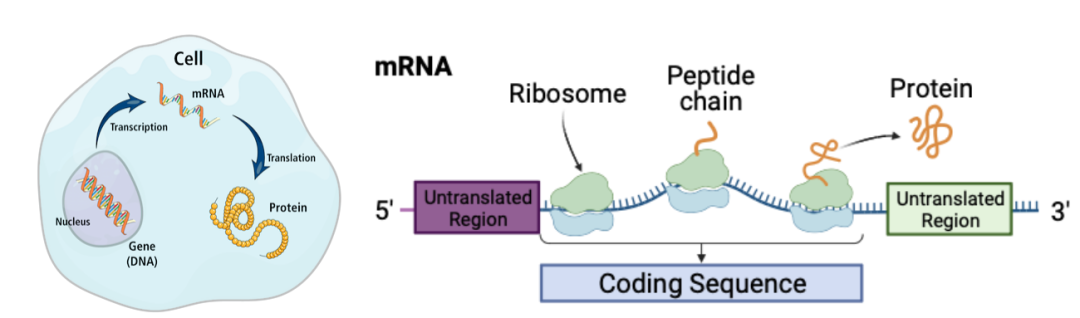
图 1:DNA-mRNA-蛋白质的转录翻译过程,及其mRNA的不同区域。(左图来自网络)
UTR-LM: 多模态mRNA非转录区域语言模型
RNA序列由四种碱基组成,即核苷酸腺嘌呤(A)、鸟嘌呤(G)、胞嘧啶(C)和尿嘧啶(U)组成,就像人类语言由一系列字母构成一样。这些核苷酸按照特定的规则排列,可以传达复杂生物功能的信息。
UTR-LM模型是一个针对mRNA非翻译区域研究而开发的语言模型。它基于transformer架构,通过类似学习自然语言的方式在核苷酸序列上进行自监督学习,并结合了二级结构(SS)和最小自由能(MFE)等多模态数据进行预训练。
为训练该模型,研究团队收集了多个数据库和不同物种的天然mRNA序列:包括Ensembl数据库,涵盖五个物种(人类、大鼠、小鼠、鸡和斑马鱼);Sample等提出的八个合成序列库;以及Cao等早期工作整理的三个内源性人类数据集 (分别来自人类胚胎肾293T细胞、前列腺癌细胞和肌肉组织)。
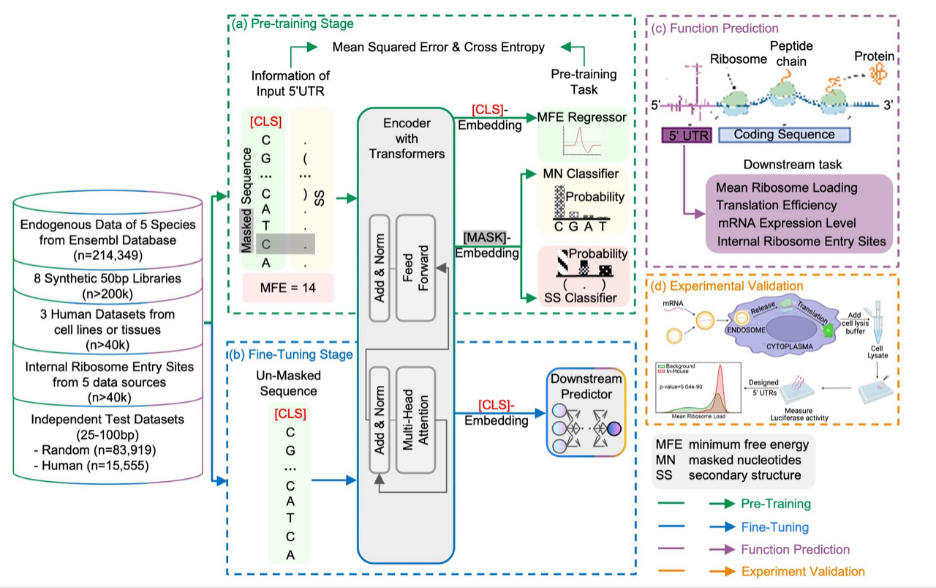
图 2:mRNA非翻译区域语言模型。
在预训练后,研究团队针对多种mRNA翻译功能的预测任务进行了微调。平均核糖体负载量(MRL)、mRNA翻译效率(TE)和表达水平(EL)的预测对生物医学研究极为重要,因为这些指标直接决定了mRNA如何高效地被翻译成蛋白质,影响蛋白质产量和治疗蛋白质的开发。
在这些关键任务上,该mRNA非翻译区语言模型的表现(Spearman R)超过了六种最先进的基准方法,包括RNA-FM和RNABERT两种领先的RNA大语言模型。在平均核糖体负载量的预测上,该模型比Optimus高出高达9%,比FramePool高出高达6%,并且比RNAFM高达42%。对于mRNA翻译效率和表达水平的预测,该模型分别比Cao-RF高出高达5%和8%,而与Optimus相比则高出高达25%和47%。
此外,识别未注释的内部核糖体进入位点(IRES)对于理解和利用mRNA在细胞内非典型翻译启动机制至关重要,这对于开发新型治疗策略和疫苗具有重大意义。在这一挑战性领域,该模型也取得了显著进步,将AUPR从0.37提高到了0.52。这些结果清楚地表明,该模型在这些关键任务上的性能远超现有的先进方法,显示了其在mRNA非翻译区域序列预测领域的先进性。
这些成果突显了mRNA语言模型在生物学研究中的强大潜力。它不仅提升了对mRNA的非转录区域功能的预测精度,而且加深了我们对于mRNA的非转录区域在基因表达和翻译调控中作用的理解。凭借其先进的模型架构和全面的数据训练,mRNA非翻译区语言模型为生物学和医学研究领域提供了一个重要的科研工具,有助于推动这一领域的发展和创新。
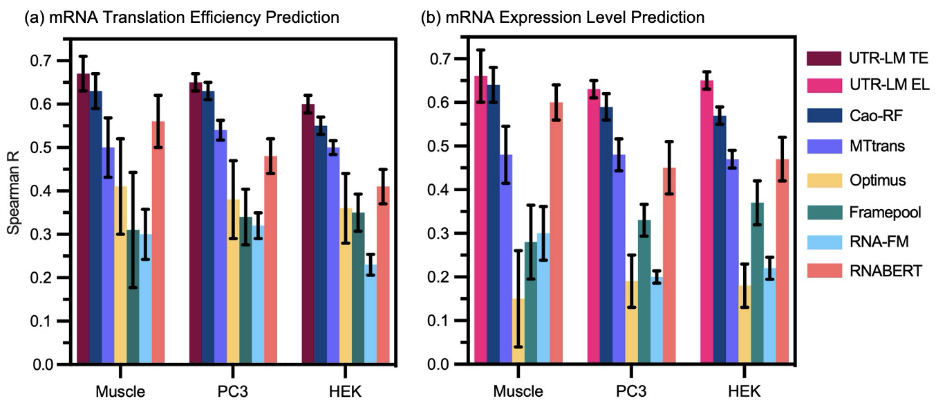
图 3:内源性数据集中mRNA翻译效率和表达水平的预测性能(Spearman R)。数据集包括人类肌肉组织(Muscle)、前列腺癌细胞(PC3)和胚胎肾293T细胞(HEK)。(a) 在翻译效率预测方面,mRNA非翻译区域语言模型的性能最高比Cao-RF高出5%,比Optimus高达27%。(b)在表达水平预测方面,mRNA非翻译区域语言模型的性能最高比Cao-RF高出8%,比Optimus高达47%。配对t检测证明mRNA非翻译区域语言模型在这些任务上显著优于其他基准方法(p < 0.05)。
mRNA语言模型助力设计高效疫苗
在该研究中,研究团队设计了211条自然界中不存在的新mRNA非翻译区域序列,并测试这些新序列用于疫苗的潜力,目的是提高mRNA疫苗的翻译效率、并最大化蛋白质的合成量。
为了验证这些新序列的有效性,团队的合作伙伴RVAC公司采用了mRNA转染和荧光素酶实验。实验中,团队测量了疫苗的相对光单位(RLU)用于评估mRNA的蛋白质产量,从而直观地反映出新的mRNA序列设计对蛋白质合成过程的影响。实验结果十分优异。相较于已经广泛应用的传统mRNA疫苗序列,团队设计的新序列实现了高达32.5%的显著效率提升。
同时,研究团队还测试了该语言模型在新生物实验上的可迁移性。通过zero-shot learning (零样本适应性预测),mRNA UTR语言模型在全新的任务上达到远高于其他方法的预测准确性。展现出了模型的优势和可迁移性。
这些实验结果不仅证实了新型RNA非转录区域序列设计的有效性,而且还彰显了机器学习技术在生物医药领域应用的巨大潜力。该研究给出了提高疫苗和治疗性蛋白质生产效率的新策略,为定制化药物设计和个性化治疗提供了新的途径。

图 4:211个新设计的mRNA非翻译区域的测试结果。(a)与28,246个内源性mRNA非翻译区域相比,新设计的mRNA非翻译区域具有更高的mRNA翻译效率预测值。(b)在湿实验中,该研究对比了前20个设计的mRNA非翻译区域与两种常用基准的翻译效率。(c)mRNA非翻译区域语言模型在预测准确性方面显著超越了现有的基准方法。
前景和结论
这项研究在Twitter上引起了生物学专家的广泛关注和讨论。他们高度评价了这个「mRNA的非转录区域的多物种语言模型」,并特别强调将机器学习应用于生物学数据分析的重要性。
专家们认为,目前生物学领域在这方面的研究还不够充分,而这项工作正好填补了这个空白,为未来的研究提供了新的方向和实验数据。北美和欧洲多个实验室也非常感兴趣向该研究团队发出了合作邀请。
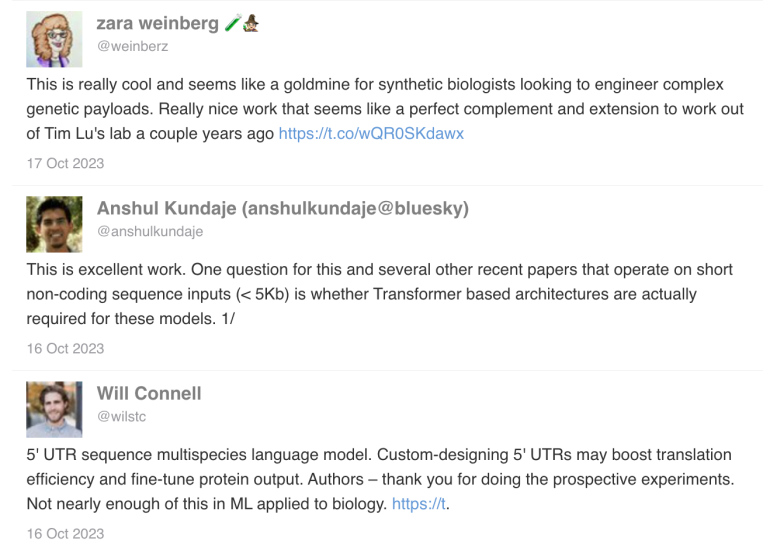
图 5:生物学专家在Twitter上对「mRNA的非转录区域的多物种语言模型」给予积极评价,强调其在生物学研究中的创新应用。
同时,这个研究也吸引了业内公司的注意,biotech知名VC如FlagShip已和研究团队多次深入交流,努力复现这个方法。这项研究突显了AI for science的潜力。
mRNA技术已经在医学界引起了革命,这项针对名RNA的语言模型研究不仅提高了mRNA疫苗设计的效率和准确性,还标志着AI技术对于创新性科学和医学研究的推动、以及保障全球健康安全的巨大潜力。这一技术的广泛应用和更多突破,以推动科学的前进并改善人类健康。
作者简介
王梦迪就职于普林斯顿大学,任统计与机器学习中心、电气与计算机工程系副教授,其研究方向包括强化学习、生成人工智能、AI for Science和机器学习理论。
她于2013年在麻省理工学院获得计算机科学博士学位,曾任DeepMind、高等研究院和Simons理论计算机科学研究所的访问研究科学家。
王梦迪在2016年获得数学优化学会的青年研究者奖、2016年普林斯顿SEAS创新奖、2017年的NSF Career Award职业奖、2017年的谷歌研究奖、2018年的MIT科技评论35岁以下创新奖、2022年的WAIC云帆奖。
因其在在控制系统、机器学习和信息论等交叉学科的杰出贡献,她于2024年获得北美自动控制学会颁发的ACC Donald Eckman奖。她担任ICLR 2023的程序主席(PC)和Neurips、ICML、COLT等国际机器学习的高级区域主席(Senior AC),任Harvard Data Science Review, Operations Research等期刊的Associate Editor。
Jason Zhang曾在wave Life science, 诺华和赛诺菲有十五年工作经验,曾任RVAC首席科学家。
Jason持有化学和免疫学双博士学位,分别在协和医科大学的梁晓天院士和纽约大学的Dan Littman院士的指导下完成,并在耶鲁大学和哈佛大学完全了生物化学博士后研究。
他曾推动了近十个药物开发项目进入临床开发的不同阶段,并曾经成功筹集了超过1亿美元的资金。
在2023年11月,他携手诺贝尔医学奖获奖者Drew Weissman共同成立了Zipcode Bio。
Zipcode Bio定位于RNA技术的前沿,致力于推进下一代的RNA疫苗和疗法的研发。Zipcode Bio重视精准的体内靶向给药、成本效益以及消除对冷链物流的依赖,产品线覆盖了肺纤维化、自身免疫疾病以及癌症等重要领域。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 全球首款!华硕8K Mini LED显示器ProArt Display PA32KCX即将发布
- 华硕公司宣布将参加即将举行的2024年NAB+Show+活动,并预告将推出一款名为ProArtDisplayPA32KCX的显示器。这款显示器被称为全球首款8KMiniLED专业显示器,将为专业用户带来前所未有的视觉体验。这款显示器拥有32英寸的超大屏幕,分辨率高达8K(7680x4320),能够呈现出极为细腻的画面效果。其色彩表现也堪称出色,平均ΔE值小于1,色彩准确度在全球领先。同时,它覆盖了97%的影院级DCI-P3色域,色彩饱和度和度极高,能够还原出更加真实的色彩。ProArtDisplayPA3
- 3分钟前 0
-
 正版软件
正版软件
- 荣耀X50发布日期确定:期待"十年登峰之作"
- 6月27日消息,荣耀宣布其最新手机荣耀X50将于7月5日19:30正式亮相。荣耀X50被称为该系列的"十年登峰之作",预计将带来令人期待的创新体验。据荣耀终端有限公司中国区CMO姜海荣透露,荣耀X50将引入全新的十面抗摔曲面屏技术,旨在挑战抗摔性能的极限。荣耀一直以其超出行业标准的品质测试而闻名,而荣耀X系列更是在按键老化测试和重物软压测试等方面远超行业标准。荣耀X系列的屏幕抗摔测试更是率先定义了严苛的场景,如1米大理石模拟跌落、1米水泥地模拟跌落以及滚筒随机角度跌落等,旨在解决曲面屏易碎的问题。荣耀X5
- 18分钟前 荣耀X 发布日期 十年登峰 0
-
 正版软件
正版软件
- 基于因果推断的推荐系统:回顾和前瞻
- 本次分享的主题为基于因果推断的推荐系统,回顾过去的相关工作,并提出本方向的未来展望。为什么在推荐系统中需要使用因果推断技术?现有的研究工作用因果推断来解决三类问题(参见Gaoetal.的TOIS2023论文CausalInferenceinRecommenderSystems:ASurveyandFutureDirections):首先,在推荐系统中存在各种各样的偏差(BIAS),因果推断是一种有效去除这些偏差的工具。为了解决数据稀缺性和无法准确估计因果效应的问题,推荐系统可能面临挑战。为了解决这一问题,
- 33分钟前 推荐系统 因果推断 推荐模型 0
-
 正版软件
正版软件
- 铭凡V3三合一平板发布:高性能AMD AI引擎引领新潮流
- 3月29日消息,今日,铭凡正式推出了全新的V3三合一平板电脑,被官方赞誉为“高性能AMD+AIWindows三合一平板电脑”。该款设备定价为6999元(32GB+1TB版本),并且首发购买的用户将获赠支架、键盘以及钢化膜。铭凯V3突出于其“高性能AMD+AI”和“三合一”设计。称赞“高性能AMD+AI”,源于设备内置的AMD锐龙78840U处理器,这款处理器集成了AMDRyzenAI引擎,与前代相比,AI算力提升达60%,总体算力高达39亿次。因此,铭凯V3不仅是一款符合微软安全等级的AIWindows三
- 48分钟前 铭凡 0
-
 正版软件
正版软件
- 问界新M5:12小时订单破万,展现强劲市场潜力
- 4月19日消息,最近新M5已经开始接受预订,并在短短的12小时内吸引了超过10000份订单,这种“小定”方式允许定金退还,但其火爆程度已经显现了新车的市场潜力。根据官方最新发布的图片,我们可以看到问界新M5在设计上与M9颇为相似,其增程版本车型采用了封闭式前脸设计,只在下方保留了进气口,整体视觉效果更为简洁、现代,同时也散发出一种未来科技感。M5的更新增加了大都会红和大溪地灰两款外观配色,这两款新配色立即受到了消费者的热烈欢迎,预计将成为新车的主流选择。根据鸿蒙智行APP的信息,问界新M5的配置有所简化,
- 1小时前 23:00 问界 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1843天前
-
 2
2
- Overture设置踏板标记的方法
- 1680天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1670天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1869天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1834天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1830天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1845天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1867天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00