直接扩展到无限长,谷歌Infini-Transformer终结上下文长度之争
 发布于2024-12-27 阅读(0)
发布于2024-12-27 阅读(0)
扫一扫,手机访问
不知 Gemini 1.5 Pro 是否用到了这项技术。
谷歌又放大招了,发布下一代 Transformer 模型 Infini-Transformer。
引入了一种实用且强大的注意力机制 Infini-attention—— 具有长期压缩内存和局部因果注意力,可用于有效地建模长期和短期上下文依赖关系; Infini-attention 对标准缩放点积注意力( standard scaled dot-product attention)进行了最小的改变,并通过设计支持即插即用的持续预训练和长上下文自适应; 该方法使 Transformer LLM 能够通过流的方式处理极长的输入,在有限的内存和计算资源下扩展到无限长的上下文。

论文链接:https://arxiv.org/pdf/2404.07143.pdf 论文标题:Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
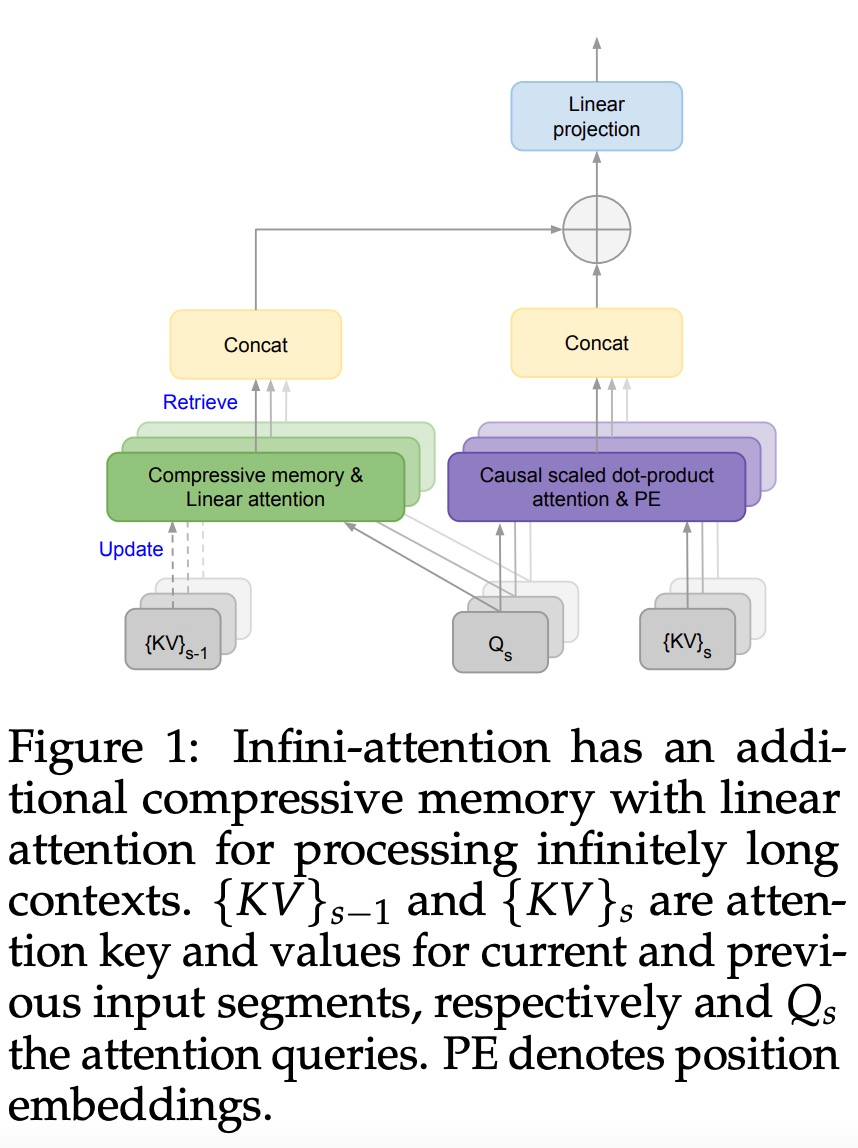
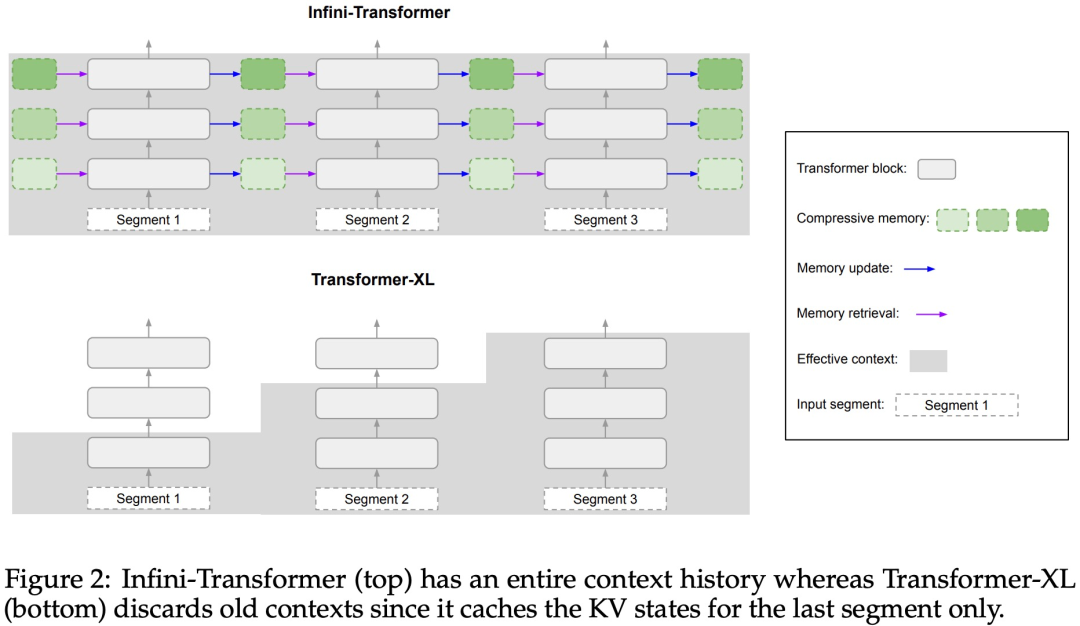



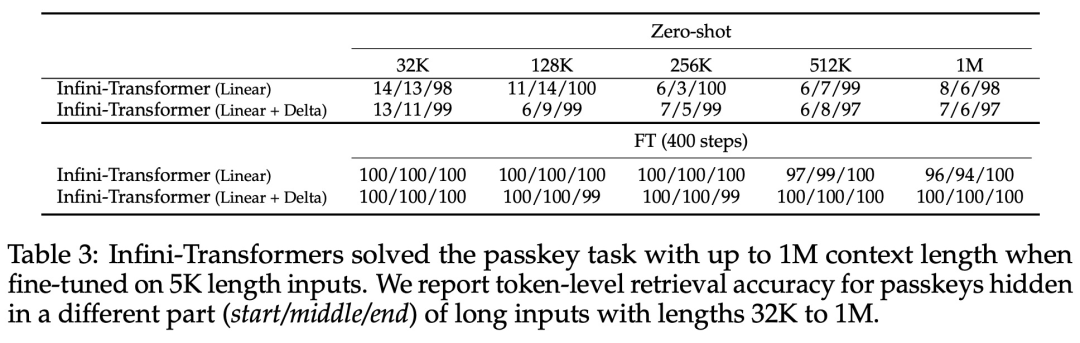
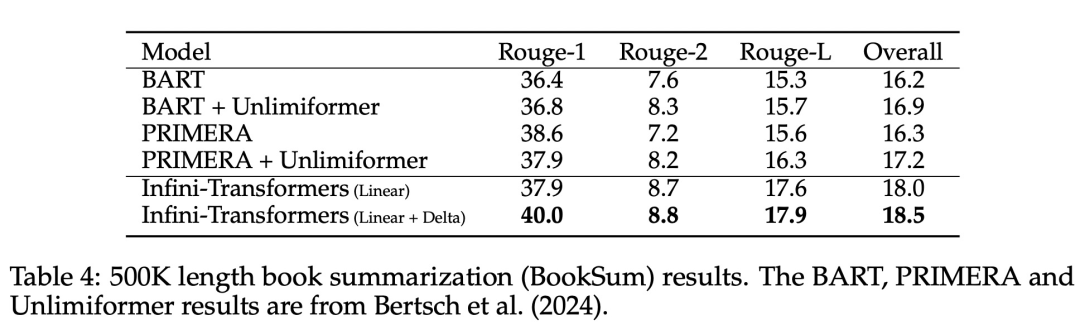

本文转载于:https://www.jiqizhixin.com/articles/2024-04-12-8 如有侵犯,请联系admin@zhengruan.com删除
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 十个推荐开源免费文本标注工具
- 文本标注工作是将标签或标记与文本中特定内容相对应的工作。其主要目的是为文本提供额外的信息,以便进行更深入的分析和处理,尤其是在人工智能领域。文本标注对于人工智能应用中的监督机器学习任务至关重要。用于训练AI模型,有助更准确地理解自然语言文本信息,提高文本分类、情感分析和语言翻译等任务的性能。通过文本标注,我们可以教AI模型识别文本中的实体、理解上下文,并在出现新的类似数据时做出准确的预测。本文主要推荐一些较好的开源文本标注工具。1.LabelStudiohttps://github.com/HumanSi
- 10分钟前 AI 开源 文本标注 0
-
 正版软件
正版软件
- 全球AI顶会NeurlPS开始收高中生论文了
- 卷高考之后的下一步,卷论文?培养AI人才,要从娃娃抓起,这句话似乎越来越不像开玩笑了。本周五,顶级学术会议NeurIPS开设高中生论文Track的消息引爆了人工智能社区。消息援引自大会组织方的一项新公告。请注意,这不是workshop,是主会议:我们诚邀高中生提交与机器学习社会影响相关的研究论文,将在NeurIPS+2024上展示他们的项目。组委会将选择部分决赛入围者以虚拟方式展示他们的项目,并在NeurIPS主页上重点展示他们的作品。此外,最多五个获奖项目的主要作者将受邀参加在温哥华举行的NeurIPS
- 20分钟前 产业 0
-
 正版软件
正版软件
- Redmi迭代新机曝光:支持90W快充,搭载骁龙8s Gen 3,海外版命名POCO F6
- 3月26日消息,小米旗下有一款全新机型近日正式通过了国家3C质量认证,该机型型号为24069RA21C,由西安比亚迪电子工厂负责代工生产。这款新机在充电技术方面迎来了重大升级,支持高达90W的有线快充,这一功率在当前的手机市场中无疑属于领先水平,将为用户带来更快速、更便捷的充电体验。随着消息的进一步传出,数码博主们纷纷对这款新机进行了深入剖析。据他们透露,这款新机实际上是Redmi品牌的新系列产品,可以看作是RedmiNote12Turbo的升级版或者迭代机型。不仅如此,该机还将荣幸地成为首批搭载全新骁龙
- 30分钟前 小米 0
-
 正版软件
正版软件
- 小鹏G6黑武士版明日亮相,黑色涂装彰显个性
- 2022年4月10日消息,小鹏汽车今日正式公布了小鹏G6黑武士版的官方图片,这款备受瞩目的新车将于明日正式亮相。作为现有小鹏G6车型的全新演绎,黑武士版在设计中注入了更多运动元素,通过一系列黑色涂装的细节处理,使得整车更具运动气息和战斗感。小鹏G6黑武士版在外观设计上与普通版并无太大差异,但在内饰方面进行了更多运动元素的注入,通过一系列黑色涂装的细节处理,使得整车更具运动气息和战斗感。车辆采用了全新的运动座椅,并通过黑色涂装的细节点缀,进一步提升了座椅的视觉效在外观方面,小鹏G6黑武士版依旧基于现款小鹏G
- 45分钟前 0
-
 正版软件
正版软件
- 以假乱真,天工音乐大模型带来颠覆式AI体验
- 昨日,昆仑万维AI音乐生成大模型“天工SkyMusic”开启了免费邀测活动。诚邀媒体、行业专家以及感兴趣的音乐从业者们共同体验SOTA的音乐大模型产品。该产品能够让用户产生身临其境的体验,同时共同体验人声情感表达。邀测开始后,广大用户对“天工SkyMusic”AI音乐生成大模型的期望很高。工作人员在极短时间内收到了数十万份测试申请,其中包括众多专业的音乐创作人、媒体及行业专家。同时,还有大量测试申请源源不断地发至后台。在申请中,包括众多专业的音乐创作人、媒体及行业专家,还有大量的测试申请需要被源源不断地筛
- 59分钟前 产业 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1844天前
-
 2
2
- Overture设置踏板标记的方法
- 1681天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1670天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1869天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1834天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1831天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1845天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1867天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00