DeepMind终结大模型幻觉?标注事实比人类靠谱、还便宜20倍,全开源
 发布于2024-12-28 阅读(0)
发布于2024-12-28 阅读(0)
扫一扫,手机访问
大模型的幻觉终于要终结了?
今日,社交媒体平台Reddit上的一则帖子引起网友热议。帖子讨论的是谷歌DeepMind昨日提交的一篇论文《Long-form factuality in large language models(大语言模型的长篇事实性)》,文中提出的方法和结果让人得出大语言模型幻觉不再是问题了。

我们知道,大语言模型在响应开放式主题的fact-seeking(事实寻求)提问时,通常会生成包含事实错误的内容。DeepMind 针对这一现象进行了一些探索性研究。
为了对一个模型在开放域的长篇事实性进行基准测试,研究者使用 GPT-4 生成 LongFact,它是一个包含38个主题、数千个问题的提示集。然后他们提出使用搜索增强事实评估器(SAFE)来将 LLM 智能体用作长篇事实性的自动评估器。SAFE 的目的是提高事实可信度评估器的准确性。
关于SAFE,使用LLM可以更准确地解释每个实例的准确性。这里多步推理过程包括将搜索查询发送到Google搜索并确定搜索结果是否支持某个实例。

论文地址:https://arxiv.org/pdf/2403.18802.pdf
GitHub 地址:https://github.com/google-deepmind/long-form-factuality
此外,研究者提出将 F1 分数(F1@K)扩展为长篇实践性的聚合指标。他们平衡了响应中支持的实际的百分比(精度)和所提供事实相对于代表用户首选响应长度的超参数的百分比(召回率)。
实证结果表明,LLM 智能体可以实现超越人类的评级性能。在一组约 16k 个单独的事实上,SAFE 在 72% 的情况下与人类注释者一致,并且在 100 个分歧案例的随机子集上,SAFE 的赢率为 76%。同时,SAFE 的成本比人类注释者便宜 20 倍以上。
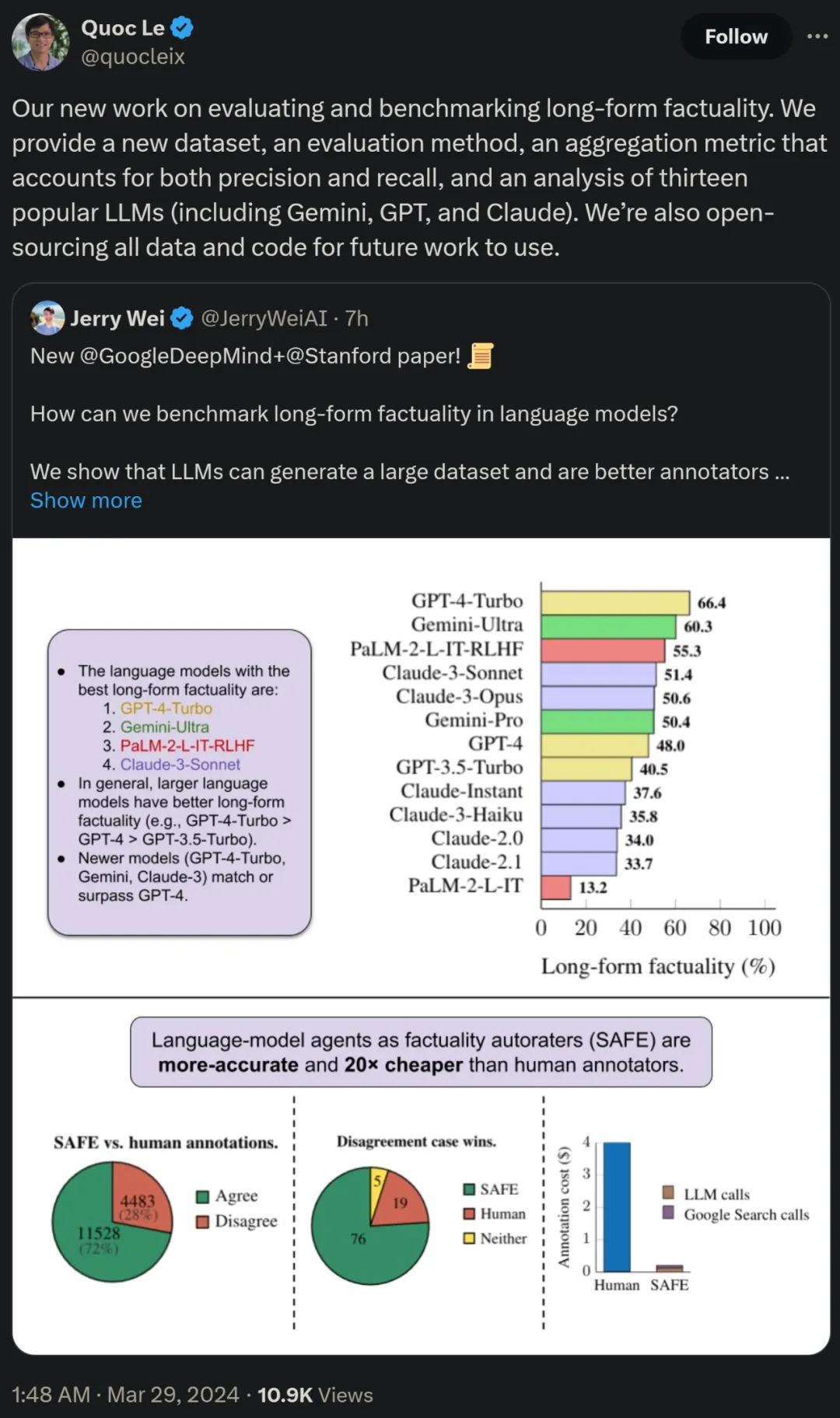
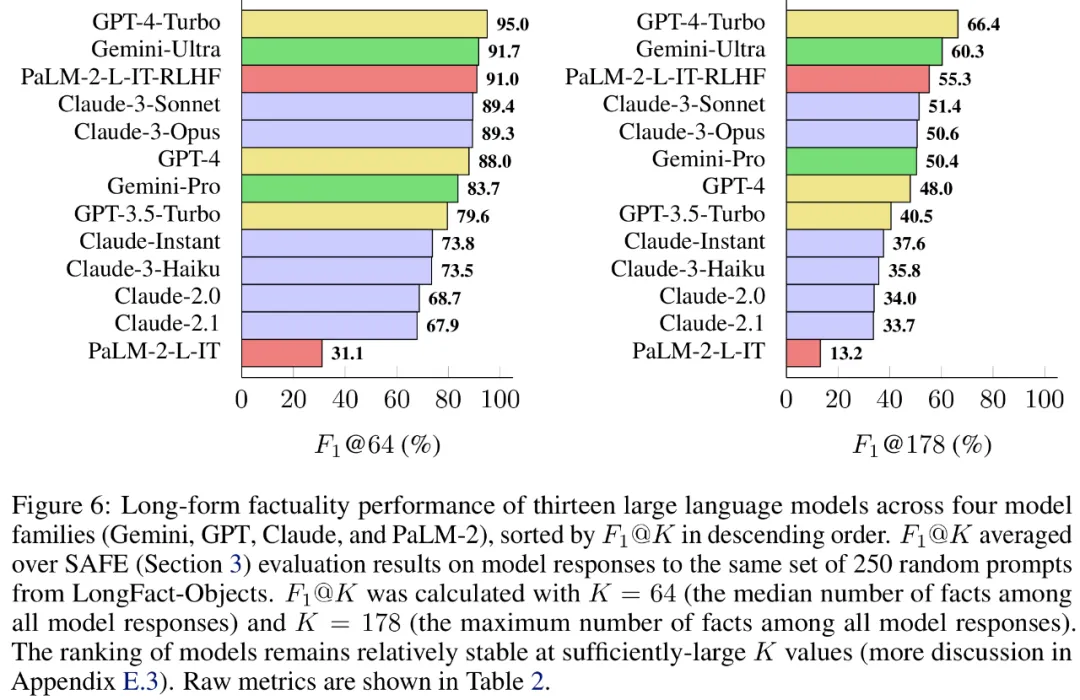
研究者还使用 LongFact,对四个大模型系列(Gemini、GPT、Claude 和 PaLM-2)的 13 种流行的语言模型进行了基准测试,结果发现较大的语言模型通常可以实现更好的长篇事实性。
论文作者之一、谷歌研究科学家 Quoc V. Le 表示,这篇对长篇事实性进行评估和基准测试的新工作提出了一个新数据集、 一种新评估方法以及一种兼顾精度和召回率的聚合指标。同时所有数据和代码将开源以供未来工作使用。
方法概览
LONGFACT:使用 LLM 生成长篇事实性的多主题基准
首先来看使用 GPT-4 生成的 LongFact 提示集,包含了 2280 个事实寻求提示,这些提示要求跨 38 个手动选择主题的长篇响应。研究者表示,LongFact 是第一个用于评估各个领域长篇事实性的提示集。
LongFact 包含两个任务:LongFact-Concepts 和 LongFact-Objects,根据问题是否询问概念或对象来区分。研究者为每个主题生成 30 个独特的提示,每个任务各有 1140 个提示。

SAFE:LLM 智能体作为事实性自动评分者
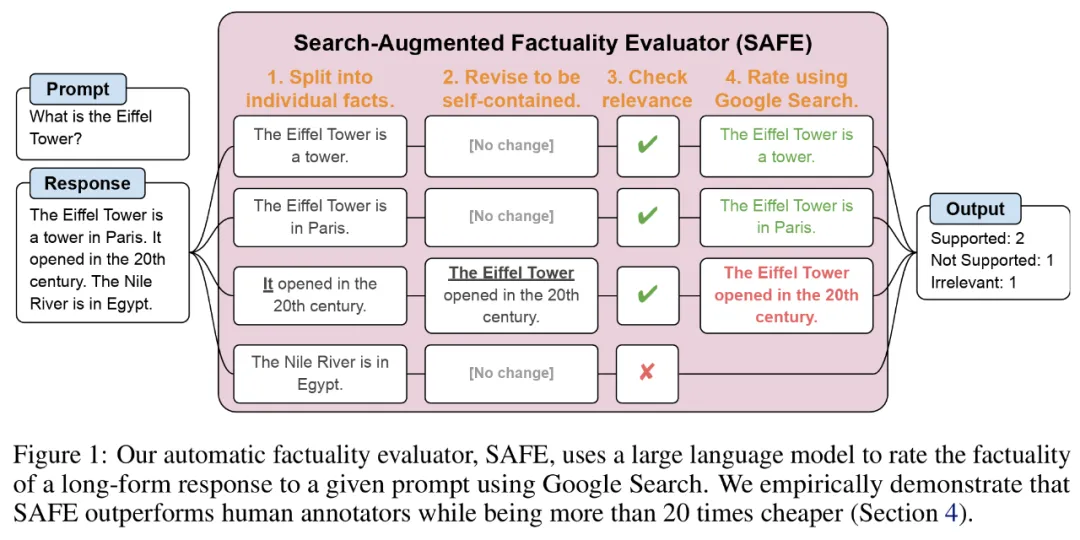
研究者提出了搜索增强事实评估器(SAFE),它的运行原理如下所示:
a)将长篇的响应拆分为单独的独立事实;
b)确定每个单独的事实是否与回答上下文中的提示相关;
c) 对于每个相关事实,在多步过程中迭代地发出 Google 搜索查询,并推理搜索结果是否支持该事实。
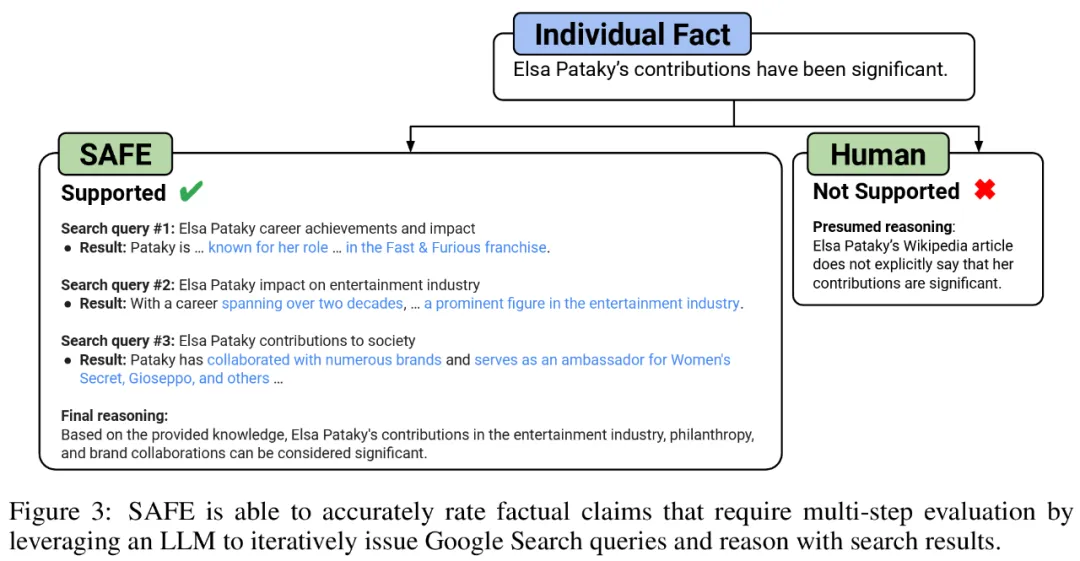
他们认为 SAFE 的关键创新在于使用语言模型作为智能体,来生成多步 Google 搜索查询,并仔细推理搜索结果是否支持事实。下图 3 为推理链示例。
为了将长篇响应拆分为单独的独立事实,研究者首先提示语言模型将长篇响应中的每个句子拆分为单独的事实,然后通过指示模型将模糊引用(如代词)替换为它们在响应上下文中引用的正确实体,将每个单独的事实修改为独立的。
为了对每个独立的事实进行评分,他们使用语言模型来推理该事实是否与在响应上下文中回答的提示相关,接着使用多步方法将每个剩余的相关事实评级为「支持」或「不支持」。具体如下图 1 所示。
在每个步骤中,模型都会根据要评分的事实和之前获得的搜索结果来生成搜索查询。经过一定数量的步骤后,模型执行推理以确定搜索结果是否支持该事实,如上图 3 所示。在对所有事实进行评级后,SAFE 针对给定提示 - 响应对的输出指标为 「支持」事实的数量、「不相关」事实的数量以及「不支持」事实的数量。
实验结果
LLM 智能体成为比人类更好的事实注释者
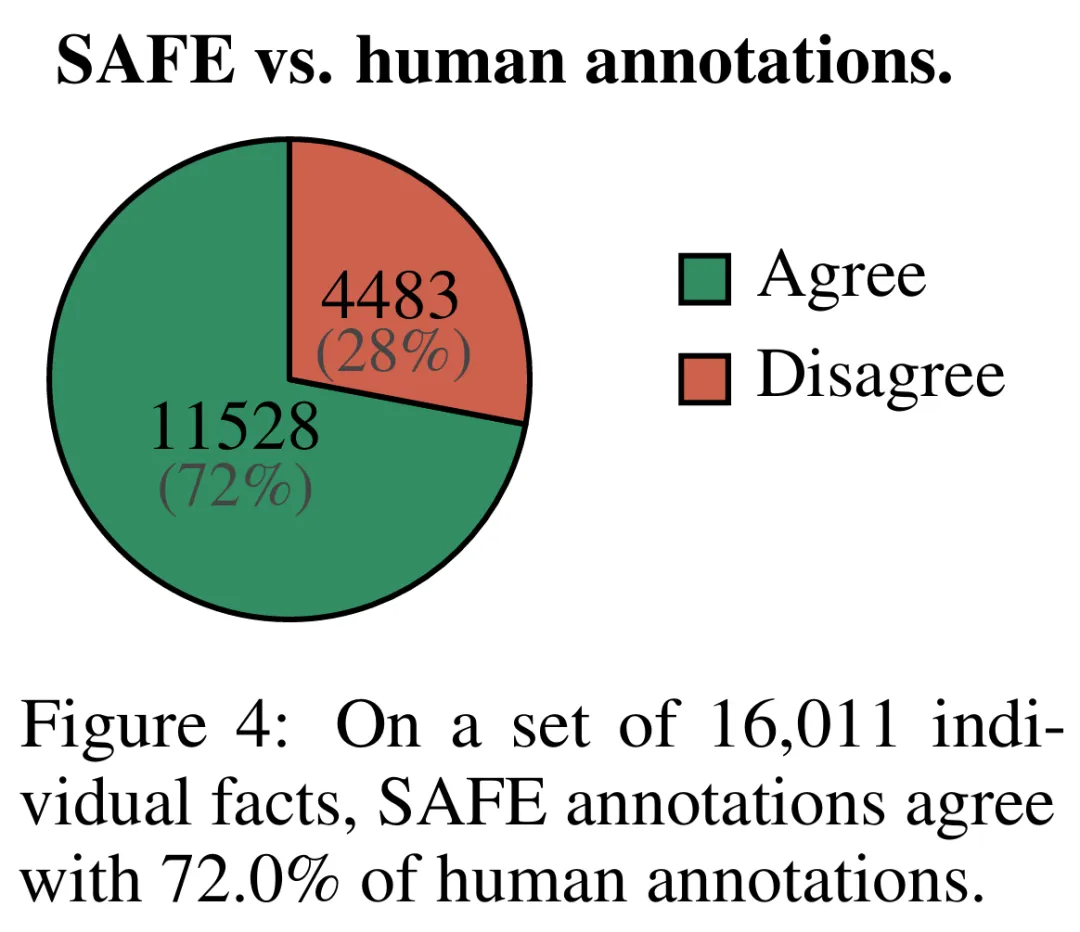
为了定量评估使用 SAFE 获得注释的质量,研究者使用了众包人类注释。这些数据包含 496 个提示 - 响应对,其中响应被手动拆分为单独的事实(总共 16011 个单独的事实),并且每个单独的事实都被手动标记为支持、不相关或不支持。
他们直接比较每个事实的 SAFE 注释和人类注释,结果发现 SAFE 在 72.0% 的单独事实上与人类一致,如下图 4 所示。这表明 SAFE 在大多数单独事实上都达到了人类水平的表现。然后检查随机采访的 100 个单独事实的子集,其中 SAFE 的注释与人类评分者的注释不一致。
研究者手动重新注释每个事实(允许访问 Google 搜索,而不仅仅是维基百科,以获得更全面的注释),并使用这些标签作为基本事实。他们发现,在这些分歧案例中,SAFE 注释的正确率为 76%,而人工注释的正确率仅为 19%,这代表 SAFE 的胜率是 4 比 1。具体如下图 5 所示。
这里,两种注释方案的价格非常值得关注。使用人工注释对单个模型响应进行评级的成本为 4 美元,而使用 GPT-3.5-Turbo 和 Serper API 的 SAFE 仅为 0.19 美元。

Gemini、GPT、Claude 和 PaLM-2 系列基准测试
最后,研究者在 LongFact 上对下表 1 中四个模型系列(Gemini、GPT、Claude 和 PaLM-2)的 13 个大语言模型进行了广泛的基准测试。
具体来讲,他们利用了 LongFact-Objects 中 250 个提示组成的相同随机子集来评估每个模型,然后使用 SAFE 获取每个模型响应的原始评估指标,并利用 F1@K 指标进行聚合。

结果发现,一般而言,较大的语言模型可以实现更好的长篇事实性。如下图 6 和下表 2 所示,GPT-4-Turbo 优于 GPT-4,GPT-4 优于 GPT-3.5-Turbo,Gemini-Ultra 优于 Gemini-Pro,PaLM-2-L-IT-RLHF 优于 PaLM- 2-L-IT。
更多技术细节和实验结果请参阅原论文。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 水浒传、三国、西厢记 IP 动画电影备案立项:《江湖豪客传》《三国的星空》《新西厢记》
- 国家电影局今日发布消息,宣布2024年2月下旬全国电影剧本(梗概)备案、立项公示,其中出现多部传统文化IP改编的动画电影。其中,光线影业备案了《江湖豪客传》和《新西厢记》,分别根据《水浒传》和《西厢记》改编。《江湖豪客传》由倪圣雄编剧,本站附剧情梗概:禁军教头林冲因得罪高俅,被流放他乡,在一处风雪之夜于山神庙手刃追杀自己的仇人陈谦,踏上逃亡之路,并结识史进、刘唐、鲁智深等一干好汉,最终实现报国护民的理想。《新西厢记》由郑靖仪编剧,剧情梗概如下:张生在寺院偶遇相国千金崔莺莺,两人一见钟情,私定终身。在侍女红
- 3分钟前 动画电影 三国 水浒传 西厢记 0
-
 正版软件
正版软件
- GPT Store都开不下去,这家国产平台怎么敢走这条路的??
- 注意看,这个男人把超1000种大模型接入,让你可插拔无缝切换使用。最近还上线了可视化的AI工作流:给你一个直观的拖放界面,拖拖、拉拉、拽拽,就能在无限画布上编排自己个儿的Workflow。正所谓兵贵神速,量子位听说,这个AIWorkflow上线不到48小时,就已经有用户配出了100多个节点的个人工作流。不卖关子,今天要聊的就是LLMOps公司Dify,及其CEO张路宇。张路宇也是Dify的创始人。投身创业前,有11年的互联网从业经验。搞产品设计,懂项目管理,也对SaaS有点自己的独到见解。后来他还在腾讯云
- 18分钟前 AI 大模型 0
-
 正版软件
正版软件
- Meson Network闲置宽带挣钱?新瓶装旧酒罢了
- 利用闲置宽带赚钱这个概念并不新鲜,很多人都听说过。早在2017年,这个概念就在币圈引起了轰动,当时玩客云就是其中比较出名的项目。当然,玩客云在今年已经宣布停止运营了!可以说,坚持了将近七年,真的不容易。毕竟很多韭菜项目只能存活七周,而玩客云竟然能坚持近7年才关闭,这说明团队还是有一定的实力和决心!可是为什么坚持近七年却要停止运营呢?共享宽带这一概念在实践中遇到了技术上的困难,经过时间的验证发现其并不可行。因此,我们不得不做出停止运营的决定,以便及时止损。用七年时间来验证一个技术,可以说玩客云的项目团队真的
- 33分钟前 构建系统 Meson 0
-
 正版软件
正版软件
- 联想与京东签署全新战略合作协议,三年销售目标 1200 亿
- 本站4月7日消息,今日,联想与京东在联想总部签署全新战略合作协议。根据协议,双方将在AI营销、智能供应链、AI服务以及AI技术融合等方面深化合作,明确了未来三年联想在京东全渠道销售1200亿元的目标,同时将互为首个AIPC先锋伙伴,共建AI终端产业生态,加速AIPC等AI设备落地。联想集团执行副总裁兼中国区总裁刘军表示:京东是联想最紧密的战略伙伴之一,双方合作广泛而深远,建立了深厚的友谊。作为领先的AI解决方案和服务提供商,联想已开启面向AI的新10年,致力于推动AI普惠千家万户、千行万业。此次战略合作是
- 48分钟前 联想 京东 0
-
 正版软件
正版软件
- 微软国行Xbox无线手柄丛林风暴特别版即将亮相
- 近期消息,微软Xbox官方宣布,备受期待的全新Xbox无线手柄林风暴特别版将于4月15日正式登陆中国市场。这款特别版手柄将在微软官方商城、微软京东自营官方旗舰店、微软天猫官方旗舰店以及微软授权经销商、Xbox零售合作伙伴等大渠道同步上市,为广大游戏爱好者带来全新的游戏体验。丛林风暴特别版手柄作为风暴系列的新成员,继幻境风暴、风暴蓝特别版之后再次为玩家们带来了耳目一新的配色选择。该手柄的特色在于其独特的菱纹橡胶握把设计,不仅提升了握感的舒适度,更在视觉上呈现出与众不同的风格。这种手柄的特色不仅体现了握挡的舒
- 1小时前 20:40 0













