Champ首发开源:人体视频生成新SOTA,5天斩获1k星,demo可玩
 发布于2024-12-28 阅读(0)
发布于2024-12-28 阅读(0)
扫一扫,手机访问
一张照片 + 一段视频,就能让照片活起来!
近日,由阿里、复旦大学、南京大学联合发布的可控人体视觉生成工作Champ火爆全网。该模型仅开源5天GitHub即收获1k星,在Twitter更是“火出圈”,吸引了大量博主二创,浏览量总量达到300K。
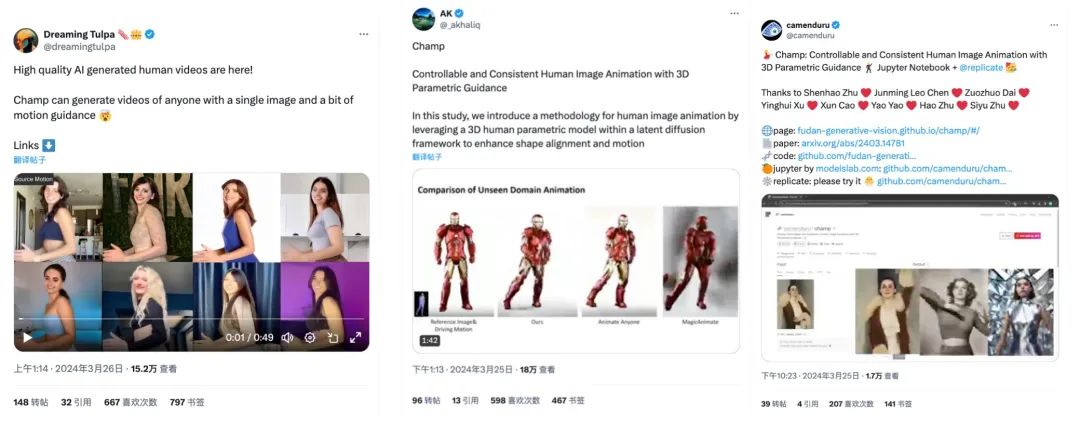
目前 Champ 已经开源推理代码与权重,用户可以直接从 Github 上下载使用。官方 Hugging Face 的 Demo 已经上线,封装的 Champ-ComfyUI 也正在同步推进中。GitHub 主页显示团队将会在近期开源训练代码及数据集,感兴趣的小伙伴可以持续关注项目动态。
项目主页:https://fudan-generative-vision.github.io/champ/
论文链接:https://arxiv.org/abs/2403.14781
Github 链接:https://github.com/fudan-generative-vision/champ
Hugging Face 链接:https://huggingface.co/fudan-generative-ai/champ
Champ 在现实世界人像上的视频效果,能够让不同的人像“复制”相同的动作,从左上角的角度的动作视频为输入。
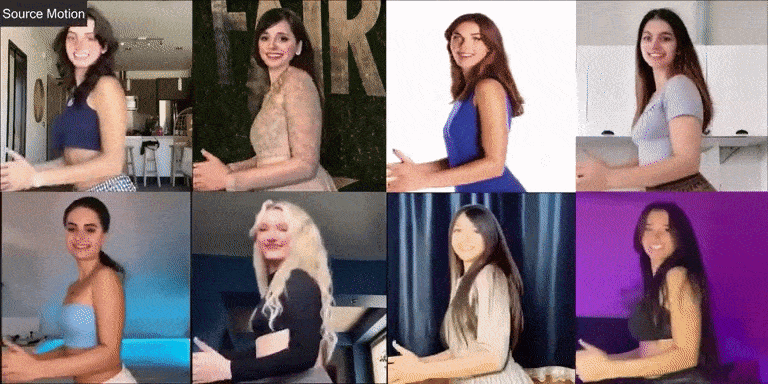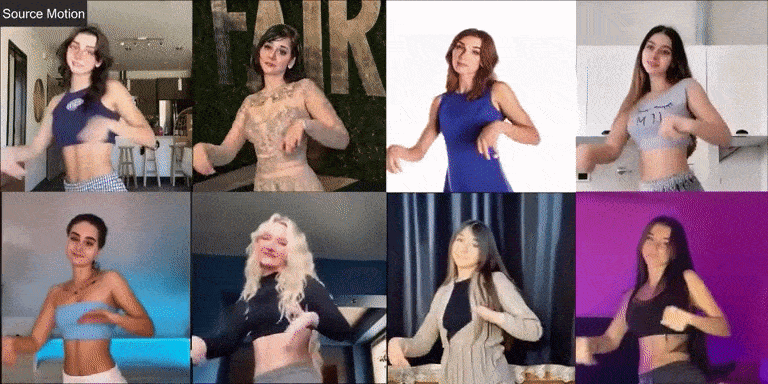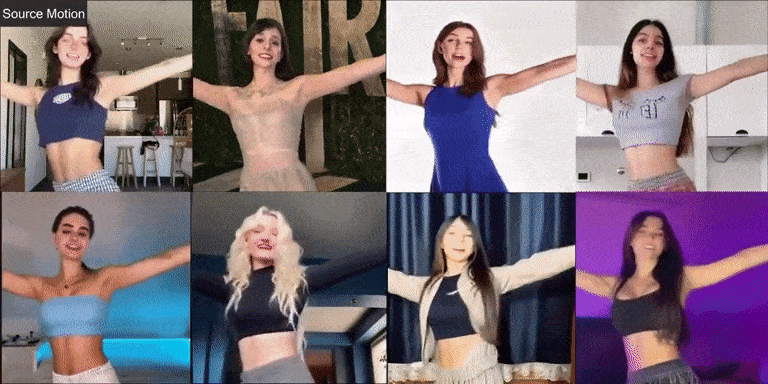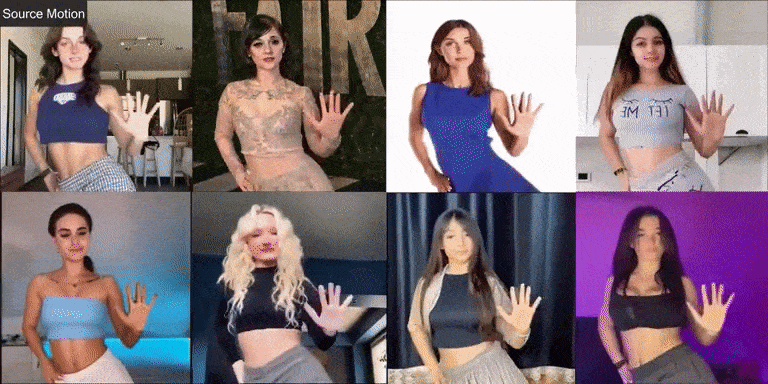
虽然 Champ 仅用真实的人体视频训练,但它在不同类型的图像上展现了强大的泛化能力:

黑白照片,油画,水彩画等效果拔群,在不同文生图模型生成的真实感图像,虚拟人物也不在话下:

技术概览
Champ 利用先进的人体网格恢复模型,从输入的人体视频中提取出对应的参数化三维人体网格模型 SMPL 序列(Skinned Multi-Person Linear Model),进一步从中渲染出对应的深度图,法线图,人体姿态与人体语义图,作为对应的运动控制条件去指导视频生成,将动作迁移到输入的参考人像上,能够显著地提升人体运动视频的质量,以及几何和外观一致性。
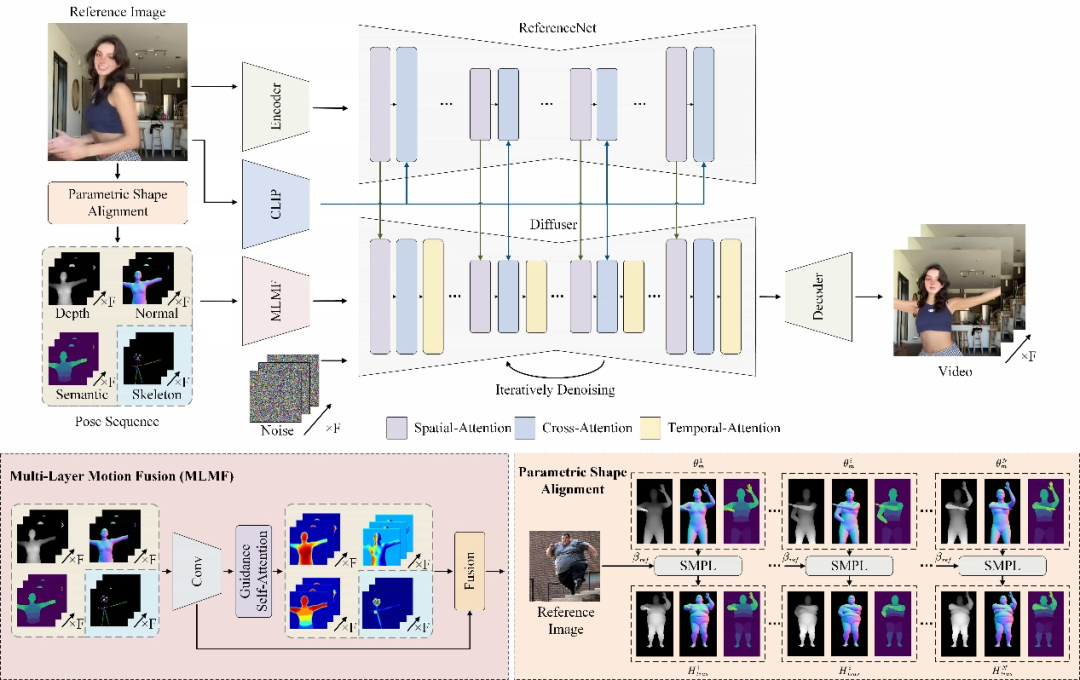
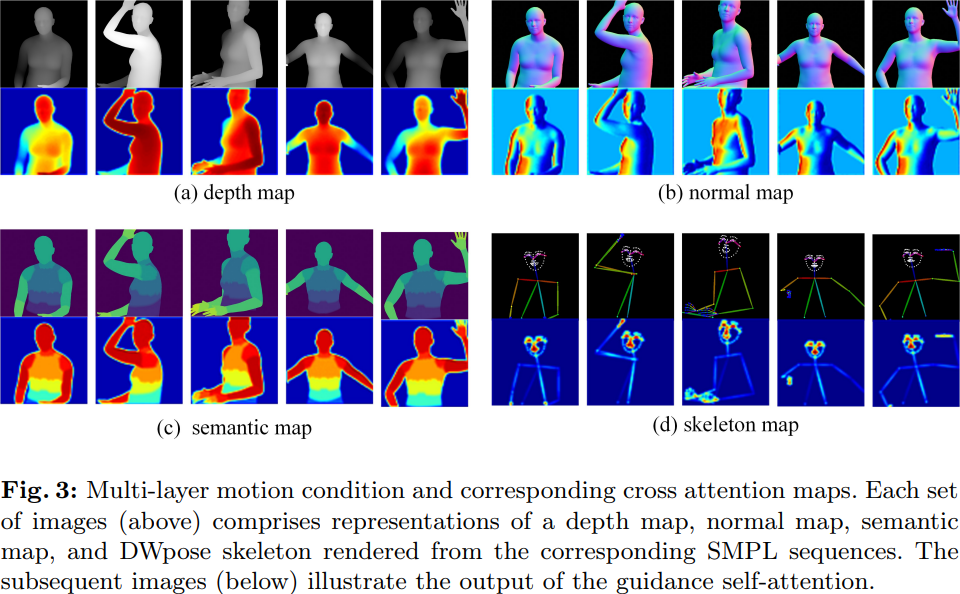
针对不同的运动条件,Champ 采用了一个多层运动融合模块(MLMF),利用自注意力机制充分融合不同条件之间的特性,实现更为精细化的运动控制。下图中展示了该模块不同条件的注意力可视化结果:深度图关注人物形态的几何轮廓信息,法线图指示了人体的朝向,语义图控制人体不同的部分的外观对应关系,而人体姿态骨架则仅关注于人脸与手部的关键点细节。
另一方面,Champ 发现并解决了人体视频生成中一直被忽略的体型迁移的问题。此前的工作或是基于人体骨骼模型,或是基于输入的视频得到的其他几何信息来驱动人像的运动,但这些方法都无法将运动与人体体型解耦,导致生成的结果无法与参考图像的人体体型匹配。
例如,给定一个大胖作为参考图像得到的如下图 7 所示的对比结果:

可以看到,Animate Anyone 与 MagicAnimate 的生成结果中,大胖的大肚子被抹平,甚至骨架也有一些缩水。而 Champ 利用 SMPL 中体型参数,来将其与驱动视频的 SMPL 序列进行参数化的体型对齐,从而在体型,动作上都取得了最佳的一致性(图中 with PST)。
实验结果
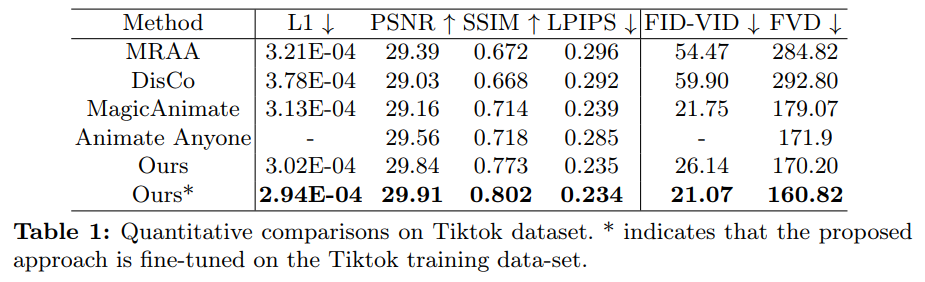
如下表 4 所示,与其他的 SOTA 工作相比,Champ 具有更好的运动控制以及更少的伪影:

同时,Champ 还展现了其优越的泛化性能与外观匹配上的稳定性:


更多技术细节以及实验结果请参阅 Champ 原论文与代码,也可在 HuggingFace 或下载官方源码动手体验。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 华为 WATCH 4 Pro 太空探索上市!致敬先驱设计,实力上太空
- 在4月8日,华为推出了WATCH4Pro,这款智能手表拥有太空探索正式开启预售。这是华为首款金刚钛智能手表,也是全球首款搭载ICCEUWB无感车钥匙的穿戴产品。拉瓦尔喷管(火箭发动机的核心组件)的设计精髓源自华为太空表汲取人类探索宇宙之源——拉瓦尔喷管(火箭发动机的核心组件)。该设计精髓在外观、材质、功能等方面均实现了卓越的进化,是太空科技美学的生动诠释者。在体验上,更是在华为WATCH4系列的基础上,升级一键微体检2.0、无感智能迎宾、TruSeen™5.5+高精度体征监测技术、健康趋势分析、高血糖风险
- 7分钟前 华为太空表 0
-
 正版软件
正版软件
- 小米揭示SU7顶棚SOS紧急呼叫功能的细节
- 4月21日消息,小米官方在最新公布的问答中,对SU7顶棚上的SOS按键功能给出了详尽的阐释。这是一个紧急呼叫功能的ASOS(自动车辆辨识系统)。一旦车辆出现人员伤害或者其他任何紧急情况,车主可以选择手动启动,或者在特定情况下车辆辨识会自动触发这一功能,以便向呼叫中心发送求助信息并请求紧急救援。但需要明确的是,SOS功能专为应对紧急情况设计,并不等同于常规的售后服务热线。经过小编了解,车主只需按下SOS按键并保持2至10秒,随后松开,即可激活SOS功能。此时,车辆的各种状态信息,如位置、时间和车辆相关数据,
- 22分钟前 小米 0
-
 正版软件
正版软件
- 水浒传、三国、西厢记 IP 动画电影备案立项:《江湖豪客传》《三国的星空》《新西厢记》
- 国家电影局今日发布消息,宣布2024年2月下旬全国电影剧本(梗概)备案、立项公示,其中出现多部传统文化IP改编的动画电影。其中,光线影业备案了《江湖豪客传》和《新西厢记》,分别根据《水浒传》和《西厢记》改编。《江湖豪客传》由倪圣雄编剧,本站附剧情梗概:禁军教头林冲因得罪高俅,被流放他乡,在一处风雪之夜于山神庙手刃追杀自己的仇人陈谦,踏上逃亡之路,并结识史进、刘唐、鲁智深等一干好汉,最终实现报国护民的理想。《新西厢记》由郑靖仪编剧,剧情梗概如下:张生在寺院偶遇相国千金崔莺莺,两人一见钟情,私定终身。在侍女红
- 37分钟前 动画电影 三国 水浒传 西厢记 0
-
 正版软件
正版软件
- GPT Store都开不下去,这家国产平台怎么敢走这条路的??
- 注意看,这个男人把超1000种大模型接入,让你可插拔无缝切换使用。最近还上线了可视化的AI工作流:给你一个直观的拖放界面,拖拖、拉拉、拽拽,就能在无限画布上编排自己个儿的Workflow。正所谓兵贵神速,量子位听说,这个AIWorkflow上线不到48小时,就已经有用户配出了100多个节点的个人工作流。不卖关子,今天要聊的就是LLMOps公司Dify,及其CEO张路宇。张路宇也是Dify的创始人。投身创业前,有11年的互联网从业经验。搞产品设计,懂项目管理,也对SaaS有点自己的独到见解。后来他还在腾讯云
- 52分钟前 AI 大模型 0
-
 正版软件
正版软件
- Meson Network闲置宽带挣钱?新瓶装旧酒罢了
- 利用闲置宽带赚钱这个概念并不新鲜,很多人都听说过。早在2017年,这个概念就在币圈引起了轰动,当时玩客云就是其中比较出名的项目。当然,玩客云在今年已经宣布停止运营了!可以说,坚持了将近七年,真的不容易。毕竟很多韭菜项目只能存活七周,而玩客云竟然能坚持近7年才关闭,这说明团队还是有一定的实力和决心!可是为什么坚持近七年却要停止运营呢?共享宽带这一概念在实践中遇到了技术上的困难,经过时间的验证发现其并不可行。因此,我们不得不做出停止运营的决定,以便及时止损。用七年时间来验证一个技术,可以说玩客云的项目团队真的
- 1小时前 21:10 构建系统 Meson 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1844天前
-
 2
2
- Overture设置踏板标记的方法
- 1681天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1671天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1869天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1835天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1831天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1846天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1868天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00