深度学习架构的超级英雄——BatchNorm2d
 发布于2024-12-28 阅读(0)
发布于2024-12-28 阅读(0)
扫一扫,手机访问

想了解更多AIGC的内容,请访问:
51CTO AI.x社区
https://www.51cto.com/aigc/
本文旨在探究2D批处理规范化在深度学习架构中的关键作用,通过简单的例子来解释该技术的内部工作原理。重点在于微调细节,而非改变原内容的主旨。

由作者本人创建的图像
深度学习(DL)已经改变了卷积神经网络(CNN)和生成式人工智能(Gen AI)发展的游戏规则。这种深度学习模型可以从多维空间数据(如图像)中提取复杂的模式和特征,并进行预测。输入数据中的模式越复杂,模型的结构就越复杂。这也意味着输入的数据模式越复杂,模型的架构就越复杂。因此,输入数据中的模式越复杂,模型的训练和预测就越困难。
有许多方法可以加快模型训练速度并提高模型推理性能。通过将二维(2D)数据集转换为超级英像素,可以展示如何将2D集成到DL框架中,从而实现更快的收敛和更好的推理。
了解一下BN2D
BN2D是一种批量应用于多维空间输入(如图像)的归一化技术,以归一化它们的维度(通道)值,从而使这些批次的维度工具具有0的平均值和1的方差。
合并BN2D组件的主要目的是防止来自网络内先前层的输入数据中跨维度或通道的内部协变量偏移。当维度数据的分布由于在训练周期(epoch)对网络参数进行的更新而改变时,会发生跨维度的内部协变量偏移。例如,卷积层中的N个过滤器产生N维激活作为输出。该层维护其过滤器的权重和偏差参数,这些参数随着每个训练周期而逐渐更新。
作为这些更新的结果,来自一个过滤器的激活可以具有与来自相同卷积层的另一过滤器的激活明显不同的分布。这种分布上的差异表明,来自一个过滤器的激活与来自另一过滤器的激活在很大程度上不同。当将这种尺度大不相同的维度数据输入到网络中的下一层时,该层的可学习性受到阻碍,因为与尺度较小的维度相比,尺度较大的维度的权重在梯度下降期间需要更大的更新。
另一个可能的后果是,尺度较小的权重梯度可能消失,而尺度较大的权重梯度则可能爆炸式增长。当网络遇到这种学习障碍时,梯度下降将在更大的尺度上振荡,严重阻碍学习收敛和训练稳定性。BN2D通过将维度数据标准化为平均值为0、标准偏差为1的标准尺度,有效地缓解了这一现象,并促进了训练过程中更快的收敛,减少了实现最佳性能所需的训练周期(epoch)数量。因此,通过简化网络的训练阶段,该技术确保网络可以专注于学习更复杂和抽象的特征,从而从输入数据中提取更丰富的表示。
在标准实际应用中,BN2D实例插入卷积层后面,但插入到激活层(如ReLU)前,如图1中的示例DL网络所示:

图1:一个深度CNN的示例(图片由作者本人创建)
BN2D内部工作原理
图2中显示了一批简单的多维空间数据的示例(如仅使用了3个通道的图像),以说明BN2D技术的内部工作原理。
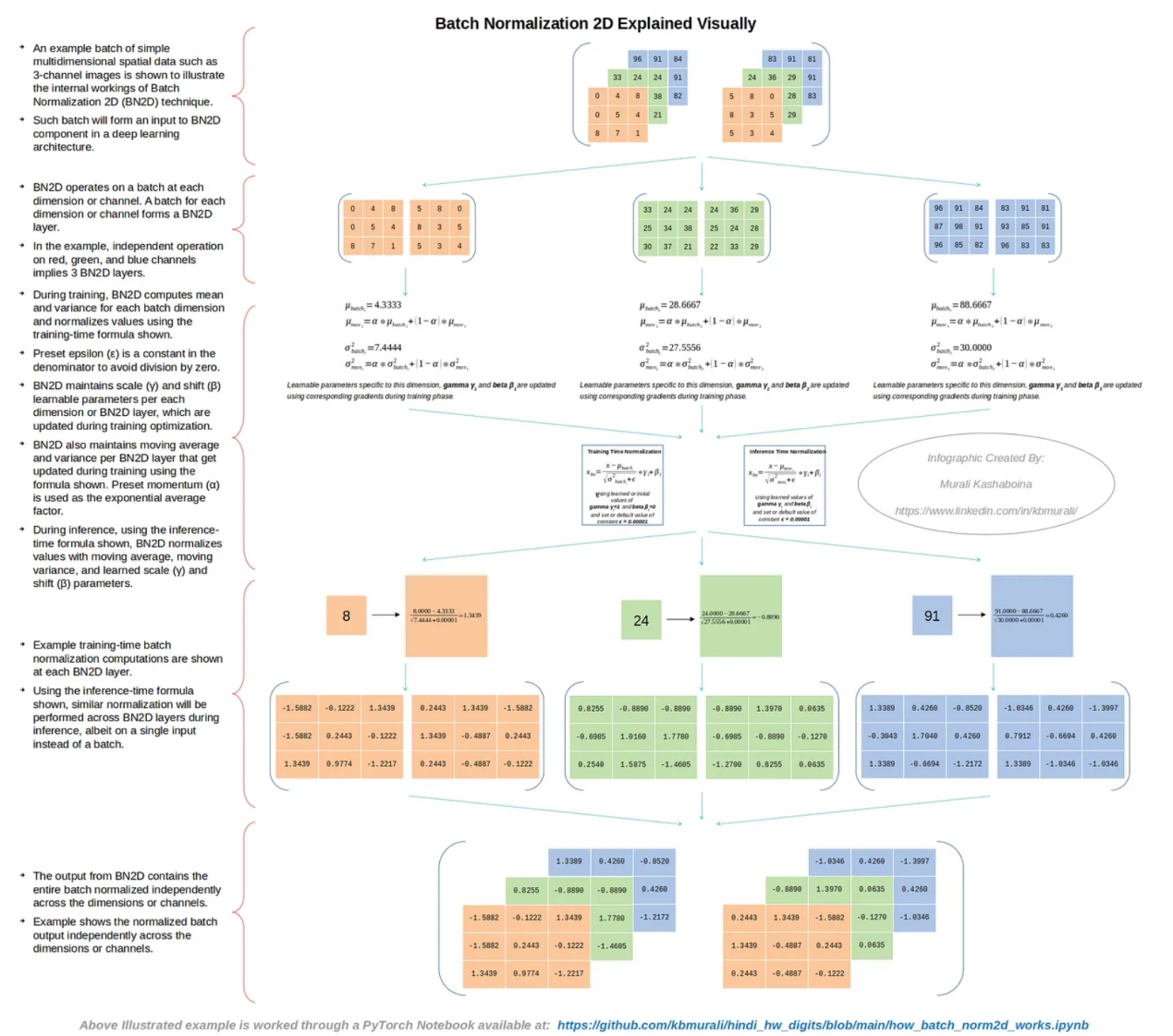
图2:BN2D的内部工作原理(作者本人创建的图像)
如图2所示,BN2D的功能是在每个维度或通道处理一个批次。如果输入批次具有N个维度或通道,则BN2D实例将具有N个BN2D层。在示例情况下,红色、绿色和蓝色通道的单独处理意味着对应的BN2D实例具有3个BN2D层。

图3:BN2D使用的公式(作者本人创建的图像)
在训练过程中,BN2D计算每个批次维度的平均值和方差,并使用图3所示的训练时间公式对值进行归一化,如图2所示。预设的ε是分母中的一个常数,以避免出现被零除的错误。BN2D实例维护每个维度或BN2D层的可学习参数——比例(γ)和偏移(β),这些参数在训练优化期间更新。BN2D实例还维护每个BN2D层的移动平均值和方差,如图2所示,它们在训练过程中使用图3所示的公式进行更新。预设动量(α)用作指数平均因子。
在推理过程中,使用如图3所示的推理时间公式,BN2D实例使用特定维度的移动平均值、移动方差以及学习的比例(γ)和偏移(β)参数对每个维度的值进行归一化。图2中显示了批量输入中每个维度的训练时间批量归一化计算示例。图2中的示例还说明了BN2D实例的输出,该实例包含跨维度或通道独立规范化的整个批次。用于完成图2所示示例的PyTorch Jupyter笔记本文件可在以下GitHub存储库中找到:https://github.com/kbmurali/hindi_hw_digits/blob/main/how_batch_norm2d_works.ipynb。
使用BN2D
为了检查在DL网络架构中结合BN2D实例的预期性能改进,我们使用一个简单的(类似玩具的)图像数据集来构建具有和不具有BN2D的相对比较简单的DL网络,来实现所属类别的预测。以下是使用BN2D预期带来的几个关键DL模型性能改进方面:
改进的泛化:BN2D引入的归一化有望提高DL模型的泛化能力。在该示例中,当在网络中引入BN2D层时,预计会提高推理时间分类精度。
更快的收敛:引入BN2D层有望促进训练过程中更快的收敛,减少实现最佳性能所需的训练周期数量。在该示例中,在引入BN2D层之后的早期训练周期开始,预计训练损失会降低。
更平滑的梯度下降:由于BN2D将维度数据标准化为标准尺度,平均值为0,标准偏差为1,因此有望将梯度下降在较大规模维度上振荡的可能性降至最低,梯度下降有望顺利进行。
示例数据集
Kaggle在地址https://www.kaggle.com/datasets/suvooo/hindi-character-recognition/data处发布的印地语手写数字(0-9)数据(GNU许可证)将用于训练和测试包含和不包含BN2D的卷积DL模型。读者可参考本文顶部的横幅图片,了解印地语数字是如何书写的。DL模型网络是使用PyTorch DL模块构建而成的。选择手写的印地语数字而不是英语数字是基于与后者相比的复杂性。印地语数字的边缘检测比英语更具挑战性,因为印地语数字中的曲线多于直线。此外,根据一个人的写作风格,同一个数字可能会有更多的变化。
而且,我还开发了一个实用的Python函数,以便对数字数据的访问更符合PyTorch数据集/数据加载器的操作,如下面的代码片段所示。训练数据集有17000个样本,而测试数据集有3000个。请注意,在将图像加载为PyTorch张量时应用了PyTorch灰度转换器。另外,我还专门开发了一个名为“ml_utils.py”的实用程序模块,用于打包使用基于PyTorch张量的操作运行控制训练周期、训练和测试深度学习模型的函数。其中,训练和测试函数还能够捕获模型度量指标,以帮助评估模型的性能。Python笔记本文件和实用程序模块均可以在作者的公共GitHub存储库中访问,其链接如下:
https://github.com/kbmurali/hindi_hw_digits。
import torchimport torch.nn as nnfrom torch.utils.data import *import torchvisionfrom torchvision import transformsfrom sklearn.metrics import accuracy_scoreimport matplotlib.pyplot as pltimport seaborn as snsfrom ml_utils import *from hindi.datasets import Digitsset_seed( 5842 )batch_size = 32img_transformer = transforms.Compose([transforms.Grayscale(),transforms.ToTensor()])train_dataset = Digits( "./data", train=True, transform=img_transformer, download=True )test_dataset = Digits( "./data", train=False, transform=img_transformer, download=True )train_loader = DataLoader( train_dataset, batch_size=batch_size, shuffle=True )test_loader = DataLoader( test_dataset, batch_size=batch_size )
DL模型示例
第一个DL模型将包括具有16个过滤器的三个卷积层,每个过滤器的核大小为3,填充为1,以便产生“相同”的卷积。每个卷积的激活函数是修正线性单元(ReLU)。池大小为2的最大池化层被放置在完全连接层之前,导致产生一个输出10个类别的softmax层。该模型的网络架构如图4所示。下面的代码片段显示了相应的PyTorch模型定义。
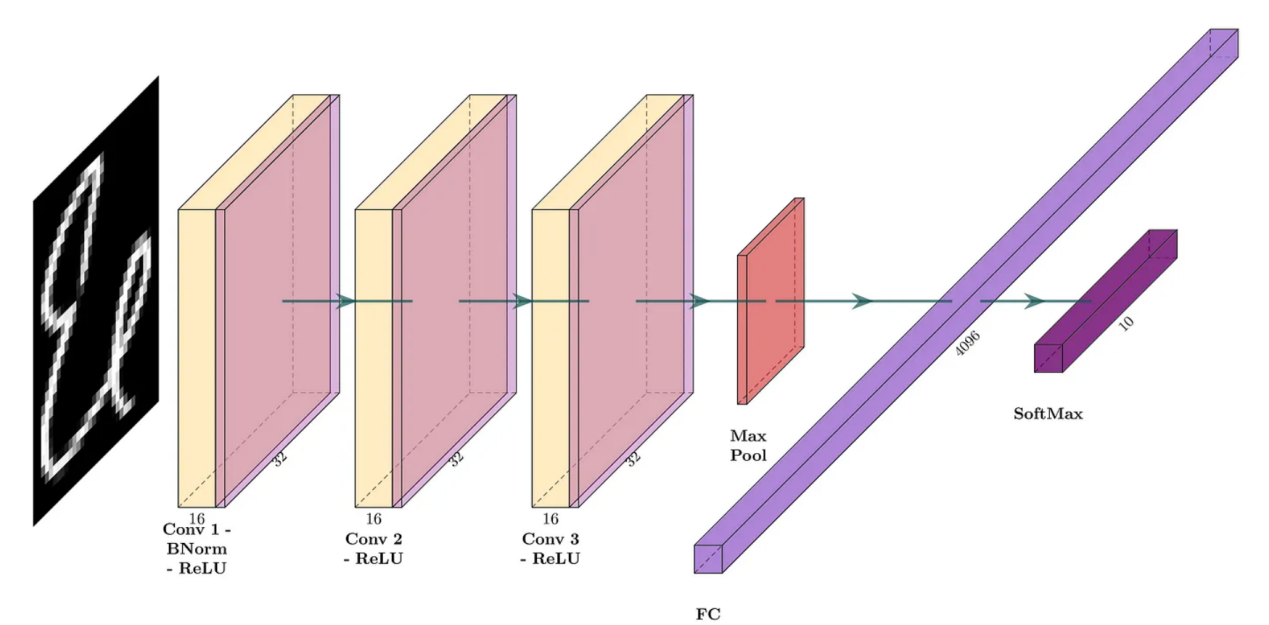
图4:没有BN2D的卷积网络(图片由作者本人创建)
device = torch.device( 'cuda' if torch.cuda.is_available() else 'cpu' )loss_func = nn.CrossEntropyLoss()input_channels = 1classes = 10filters = 16kernel_size = 3padding = kernel_size//2pool_size = 2original_pixels_per_channel = 32*32three_convs_model = nn.Sequential(nn.Conv2d( input_channels, filters, kernel_size, padding=padding ), # 1x32x32 => 16x32x32nn.ReLU(inplace=True), #16x32x32 => 16x32x32nn.Conv2d(filters, filters, kernel_size, padding=padding ), # 16x32x32 => 16x32x32nn.ReLU(inplace=True), #16x32x32 => 16x32x32nn.Conv2d(filters, filters, kernel_size, padding=padding ), # 16x32x32 => 16x32x32nn.ReLU(inplace=True), #16x32x32 => 16x32x32nn.MaxPool2d(pool_size), # 16x32x32 => 16x16x16nn.Flatten(), # 16x16x16 => 4096nn.Linear( 4096, classes) # 1024 => 10)
第二个DL模型与第一个DL模型共享相似的结构,但在卷积之后和激活之前引入了BN2D实例。该模型的网络架构如图5所示。下面的代码片段显示了相应的PyTorch模型定义。
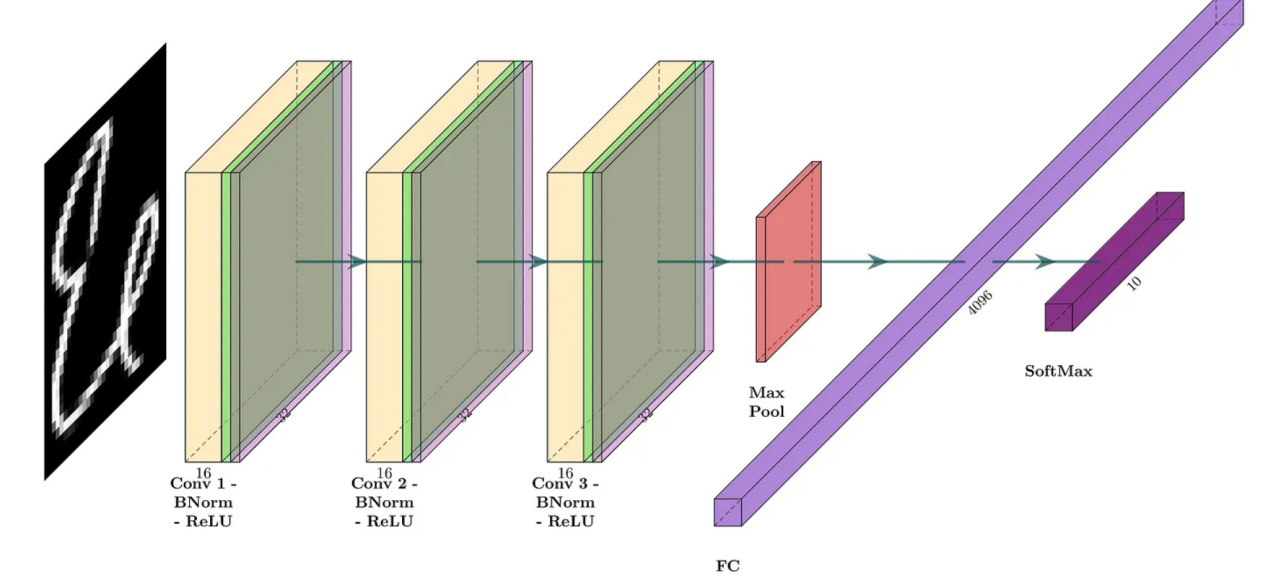
图5:带BN2D的卷积网络(图片由作者本人创建)
three_convs_wth_bn_model = nn.Sequential(nn.Conv2d( input_channels, filters, kernel_size, padding=padding ), # 1x32x32 => 16x32x32nn.BatchNorm2d( filters ), #16x32x32 => 16x32x32nn.ReLU(inplace=True), #16x32x32 => 16x32x32nn.Conv2d(filters, filters, kernel_size, padding=padding ), # 16x32x32 => 16x32x32nn.BatchNorm2d( filters ), #16x32x32 => 16x32x32nn.ReLU(inplace=True), #16x32x32 => 16x32x32nn.Conv2d(filters, filters, kernel_size, padding=padding ), # 16x32x32 => 16x32x32nn.BatchNorm2d( filters ), #16x32x32 => 16x32x32nn.ReLU(inplace=True), #16x32x32 => 16x32x32nn.MaxPool2d(pool_size), # 16x32x32 => 16x16x16nn.Flatten(), # 16x16x16 => 4096nn.Linear( 4096, classes) # 4096 => 10)
我们使用以下代码片段中所示的实用函数,以便在示例印地语数字数据集上训练两个DL模型。注意,代码中捕获了来自最后卷积层中过滤器的两个维度/通道的两个样本权重,以便可视化展示训练损失的梯度下降信息。
three_convs_model_results_df = train_model( three_convs_model,loss_func, train_loader, test_loader=test_loader, score_funcs={'accuracy': accuracy_score}, device=device, epochs=30,capture_conv_sample_weights=True, conv_index=4, wx_flt_index=3, wx_ch_index=4, wx_ro_index=1, wx_index=0,wy_flt_index=3,wy_ch_index=8, wy_ro_index=1, wy_index=0)three_convs_wth_bn_model_results_df = train_model( three_convs_wth_bn_model,loss_func, train_loader, test_loader=test_loader, score_funcs={'accuracy': accuracy_score}, device=device, epochs=30,capture_conv_sample_weights=True, conv_index=6, wx_flt_index=3, wx_ch_index=4, wx_ro_index=1, wx_index=0,wy_flt_index=3,wy_ch_index=8, wy_ro_index=1, wy_index=0)发现之1:提高了测试精度
通过引入BN2D实例,DL模型的测试精度更好,如图6所示。对于具有BN2D的模型,测试精度随着训练时期的增加而逐渐提高,而对于没有BN2D的模式,测试精度则随着训练周期而振荡。在第30个训练周期结束时,具有BN2D的模型的测试精度为99.1%,而不具有BN2D模型的测试准确率为92.4%。这些结果表明,引入BN2D实例对模型的性能产生了积极影响,显著提高了测试精度。
sns.lineplot( x='epoch', y='test accuracy', data=three_convs_model_results_df, label="Three Convs Without BN2D Model" )sns.lineplot( x='epoch', y='test accuracy', data=three_convs_wth_bn_model_results_df, label="Three Convs Wth BN2D Model" )
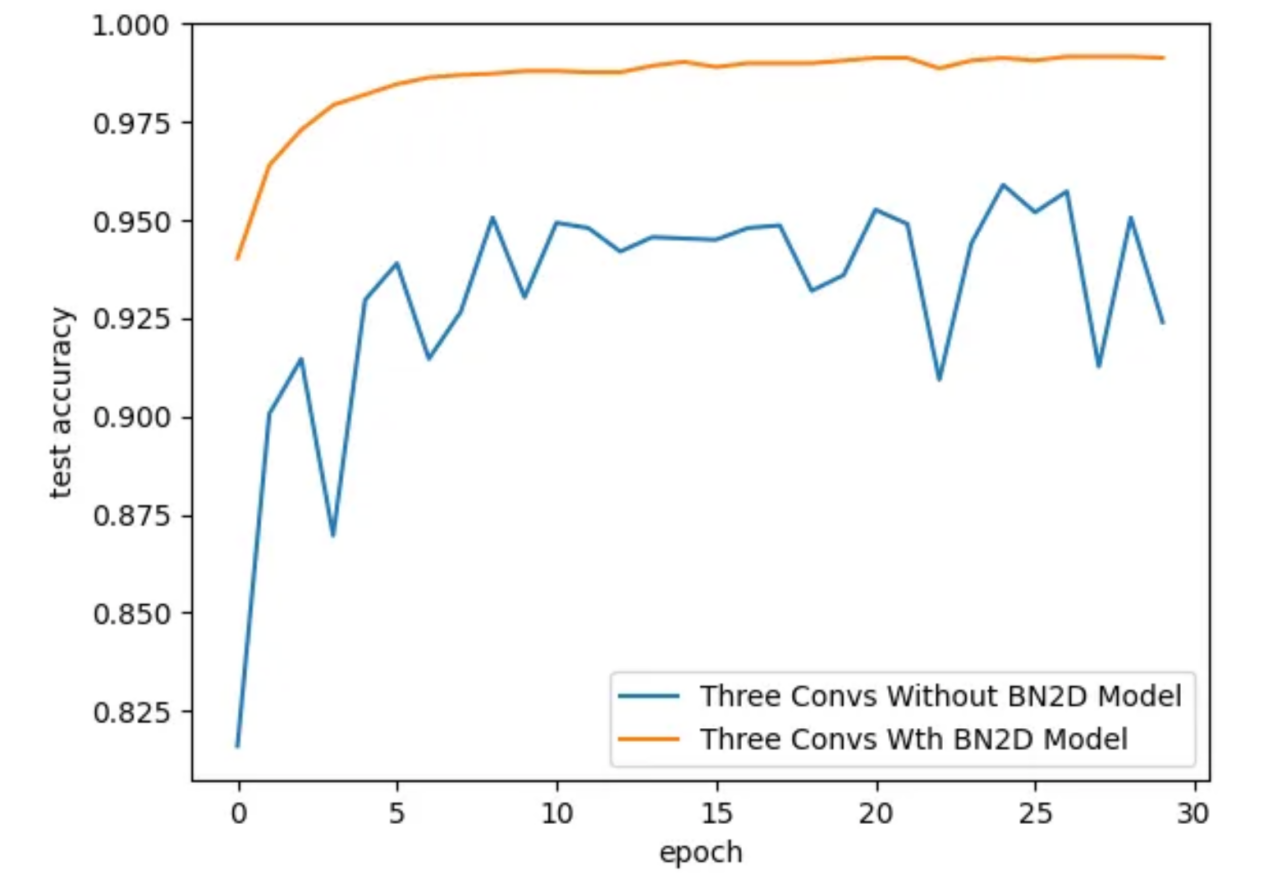
图6:训练周期的测试准确性(图片由作者本人创建)
发现之2:更快的收敛
引入BN2D实例时,DL模型的训练损失要低得多,如图7所示。大约训练到第3个周期时,具有BN2D的模型表现出比没有BN2D的模型更低的训练损失。较低的训练损失表明,BN2D有助于在训练过程中更快地收敛,可能会减少合理收敛的训练周期数量。
sns.lineplot( x='epoch', y='train loss', data=three_convs_model_results_df, label="Three Convs Without BN2D Model" )sns.lineplot( x='epoch', y='train loss', data=three_convs_wth_bn_model_results_df, label="Three Convs Wth BN2D Model" )
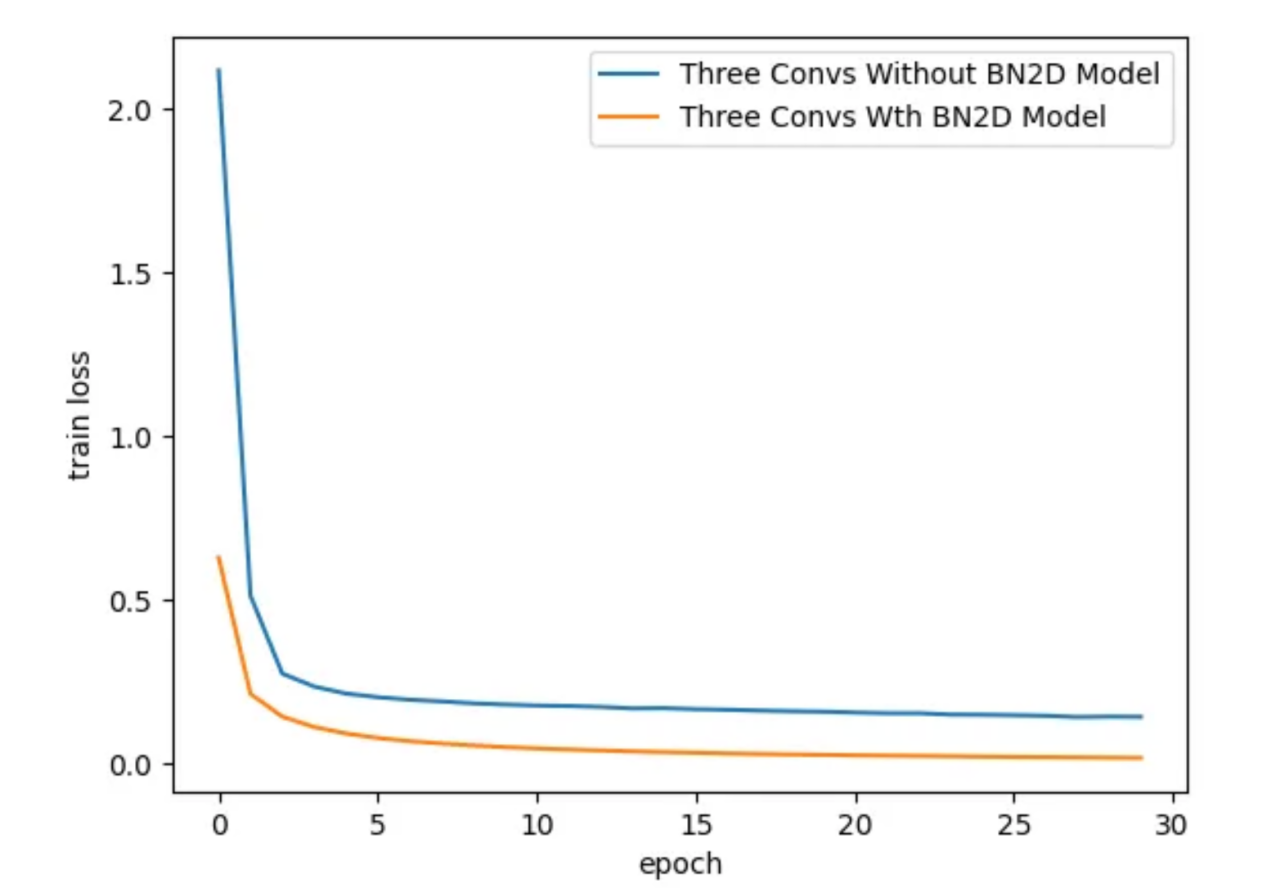
图7:在各个训练周期过程对应的训练损失(图片由作者本人创建)
发现之3:更平滑的梯度下降
如图8所示,从带有BN2D的模型的最后一次卷积中获得的两个样本权重的损失函数显示出比没有BN2D的模型更平滑的梯度下降。没有BN2D的模型的损失函数遵循相当明显的“之”字形的梯度下降。BN2D的更平滑的梯度下降表明,将维度数据标准化为平均值为0、标准偏差为1的标准规模,使得不同维度的权重可能趋于相似的规模,从而减少梯度下降的可能振荡。
fig1 = draw_loss_descent( three_convs_model_results_df, title='Three Convs Model Without BN2D Training Loss' )fig2 = draw_loss_descent( three_convs_wth_bn_model_results_df, title='Three Convs With BN2D Model Training Loss' )
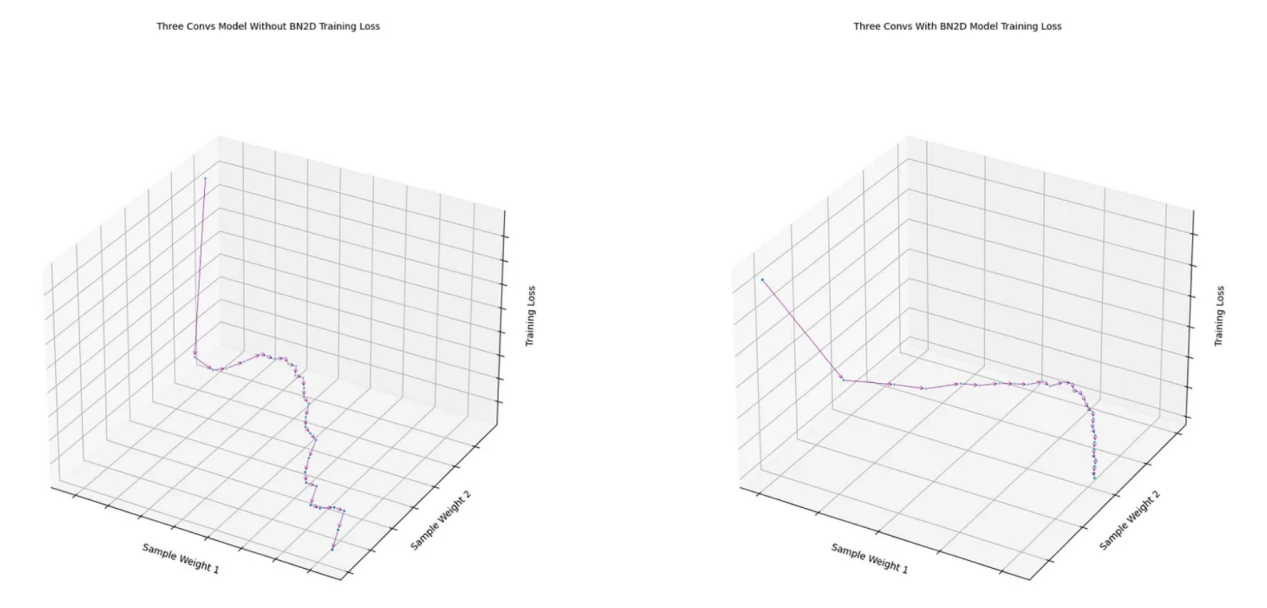
图8:样本权重上的损失函数梯度下降(图片由作者本人创建)
实际注意事项
虽然BN2D的好处是显而易见的,但要真正使用它还需要仔细考量。权重的适当初始化、适当的学习率以及在DL网络中放置BN2D层是最大化其有效性的关键因素。虽然BN2D通常可以防止过度拟合,但在某些情况下,它甚至可能导致过度拟合。例如,如果将BN2D与另一种称为Dropout的技术一起使用,则根据具体配置和数据集,组合可能会对过度拟合产生不同的影响。同样,在小批量的情况下,批量平均值和方差可能不能很好地代表整个数据集的统计数据,这可能会导致有噪声的归一化,这在防止过度拟合方面可能没有那么有效。
结论
本文旨在展示在深度学习网络中使用BN2D的背后逻辑。文中使用类玩具图像数据的示例卷积模型仅用于展示在DL网络架构中结合BN2D实例情况下的预期结果的性能改进。最后的结论是,跨空间和通道维度的BN2D归一化带来了训练稳定性、更快的收敛性和增强的泛化能力,最终有助于深度学习模型的成功。希望这篇文章有助于您很好地理解BN2D的工作原理及其背后的实现逻辑。在开发更复杂的DL模型时,我相信这种理解和直觉感受会助您一臂之力。
参考资料
1.“印地语字符识别”,解决分类梵文的问题。地址:https://www.kaggle.com/datasets/suvooo/hindi-character-recognition/data?source=post_page-----b4eb869e8b60--------------------------------。
2.“BatchNorm2d-PyTorch 2.1文档”,读者可加入PyTorch开发者社区,贡献、学习并回答您的问题。地址:https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html?source=post_page-----b4eb869e8b60--------------------------------。
3.“为什么在特征中使用2D批量归一化和在分类器中使用1D?”,讨论BatchNorm2d和BatchNorm1d之间有什么区别?为什么在特征中使用BatchNorm2d而BatchNorm1d是……地址:https://discuss.pytorch.org/t/why-2d-batch-normalisation-is-used-in-features-and-1d-in-classifiers/88360/3?source=post_page-----b4eb869e8b60--------------------------------。
4.“Keras文档:BatchNormalization层”,Keras文档有关内容,地址:https://keras.io/api/layers/normalization_layers/batch_normalization/?source=post_page-----b4eb869e8b60--------------------------------。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Exploring the Superhero Role of 2D Batch Normalization in Deep Learning Architectures,作者:Murali Kashaboina
链接:https://towardsdatascience.com/exploring-the-superhero-role-of-2d-batch-normalization-in-deep-learning-architectures-b4eb869e8b60。
想了解更多AIGC的内容,请访问:
51CTO AI.x社区
https://www.51cto.com/aigc/
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- MakerDAO创始人:DeFi前端在欧洲可能需注册 持牌照才能营运
- 欧盟具有里程碑意义的加密资产市场法《MiCA》将于2024年6月正式生效,这将使欧盟成为世界上第一个拥有量身定制、全面加密货币法规的司法管辖区,不过MiCA可能涉及对DeFi的监管,正引发加密货币产业的疑虑。Cointelegraph上周报导,欧盟可能将通过MiCA法规,要求DeFi应用应取得牌照,根据MiCA规定,欧洲委员会被要求在今年12月30日前准备一份报告,评估DeFi市场、针对DeFi特别监管的可行性,欧盟目前尚未做出任何决定。DeFi前端将需获牌照?而Makerdao共同创办人RuneChri
- 11分钟前 元宇宙 Web3.0 Arbitrum 比特币爆仓 中币/ZB网 0
-
 正版软件
正版软件
- 币安在法律挫折后成立首个董事会
- 在全球交易量最大的加密货币交易所,通过首次成立董事会,在重塑其运营方面迈出了重要一步。这一举措是在该交易所去年对美国有关反洗钱(AML)和制裁违规的指控之后进行的。币安公布首届董事会成员根据彭博社的报道,董事会由七名成员组成,由巴巴多斯前驻联合国大使GabrielAbed担任主席。币安首席执行官ChangpengZhao和首席运营官TedLin也是董事会成员之一,另外三名公司高管分别是HeinaChen、JinkaiHe和LilaiWang。币安的监管首席执行官RichardTeng也是董事会成员之一。两
- 16分钟前 币安 董事会 0
-
 正版软件
正版软件
- 香港意博金融(VSFG)申请比特币现货ETF!目标最快5月挂牌上市
- 根据外媒报道,香港资产管理公司「意博金融(VSFG)」已提交比特币现货ETF申请,计划在今年5月挂牌上市。据ETF投资和产品集团主管陈裕楷(BrianChan)指出,“如果一切顺利的话”,预计这档ETF将能够在今年5月推出,“但为了安全起见,我们也会把时间范围延长到6月”。陈裕楷补充说:监管程序通常很难给出确切的日期,但我们正与证监会积极讨论。我们已迅速针对他们的初步反馈展开行动,并正处于密切合作状态。香港证监会(SFC)在12月份发布公告表示,已准备好接受加密货币现货ETF等基金的申请。中国大陆资产管理
- 31分钟前 比特币减半 比特币汇率 比特币暴跌 比特币支付 区块链金融 0
-
 正版软件
正版软件
- 比亚迪闪耀泰国曼谷国际车展,全品牌车型悉数登场
- 3月29日消息,比亚迪官方宣布,在近日盛大开幕的泰国第45届曼谷国际车展上,该品牌首次在海外全面展示了其全系车型。这一重要举措不仅彰显了比亚迪对泰国乃至整个东盟市场的深切关注和长期布局,更向全球消费者展现了其在新能源汽车领域的卓越实力和创新成果。数据小编了解到,比亚迪在此次车展上大放异彩,不仅发布了备受期待的2024年版BYDATTO3(国内对应车型为元PLUS)长续航版,还宣布了腾势D9车型的盲订活动。同时,多款全新车型也同步亮相,包括首款右舵宋MaxEV、BYDSEALION(海狮07)、BYDSEA
- 46分钟前 比亚迪 0
-
 正版软件
正版软件
- 如何查看门罗币交易量?
- 可以通过选择交易所、行情网站或区块浏览器查看门罗币交易量,选择合适的平台后搜索门罗币交易对即可获得交易量数据。不同平台提供的交易量数据可能略有差异,且交易量会随着时间动态变化。如何查看门罗币交易量?门罗币(XMR)是一种注重隐私的加密货币,其交易量是衡量其市场活动和受欢迎程度的重要指标。查看门罗币交易量的方法如下:选择一个平台交易所:币安、火币、OKX等主流交易所都提供门罗币交易量查询功能。行情网站:CoinMarketCap、CoinGecko等行情网站也提供门罗币交易量查询功能。区块浏览器:Moner
- 1小时前 01:55 0













