LLM超长上下文查询-性能评估实战
 发布于2024-12-28 阅读(0)
发布于2024-12-28 阅读(0)
扫一扫,手机访问
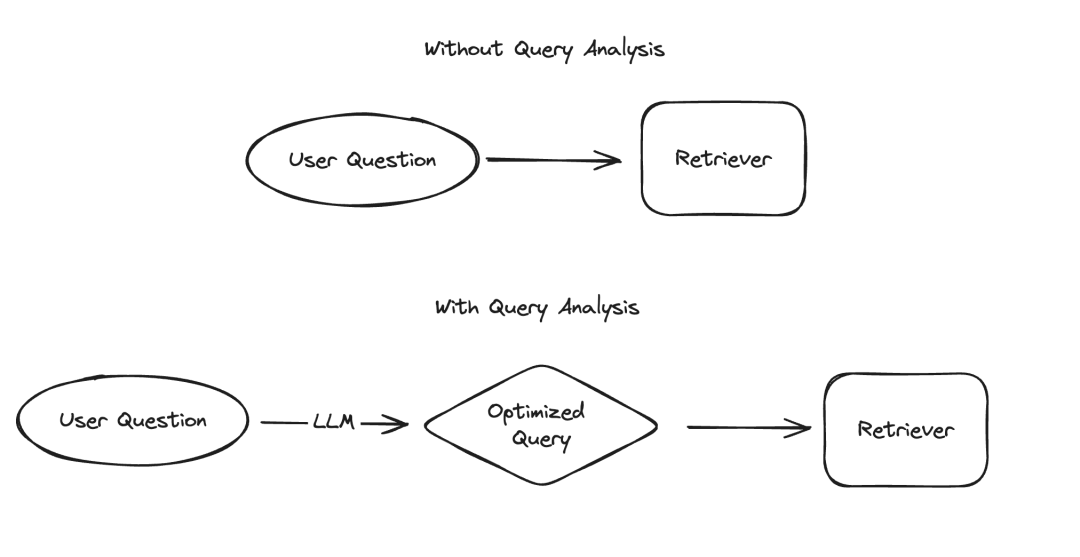
在大型语言模型(LLM)的应用中,有几个场景需要以结构化的方式呈现数据,其中信息提取和查询分析是两个典型的例子。我们最近通过更新的文档和一个专门的代码仓库强调了信息提取的重要性。对于查询分析,我们同样更新了相关文档。在这些场景中,数据字段可能包括字符串、布尔值、整数等多种类型。而在这些类型中,处理高基数的分类值(即枚举类型)是最具挑战性的。
 图片
图片
所谓的“高基数分组值”,指的是那些必须从有限的选项中选择的值,这些值不能随意指定,而必须来自一个预定义的集合。在这种集合中,有时会存在有效值数量非常庞大的情况,我们称之为“高基数数值”。处理这类数值之所以困难,是因为LLM本身并不知道这些可行的值是什么。因此,我们需要向LLM提供关于这些可行值的信息。即使忽略了只有少数几个可行值的情况,我们仍然可以在提示中明确列出这些可能的值来解决这个问题。然而,由于可能值非常多,问题就变得复杂了。
随着可能值数量的增加,LLM选择值的难度也随之增加。一方面,如果可能的值太多,它们可能无法适应LLM的上下文窗口。另一方面,即使所有可能的值都能适应上下文,将它们全部包含在内会导致处理速度变慢、成本增加,以及LLM在处理大量上下文时的推理能力下降。 `随着可能值数量的增加,LLM选择值的难度也随之增加。一方面,如果可能的值太多,它们可能无法适应LLM的上下文窗口。另一方面,即使所有可能的值都能适应上下文,将它们全部包含在内会导致处理速度变慢、成本增加,以及LLM在处理大量上下文时的推理能力下降。` (Note: The original text appears to be URL encoded. I have corrected the encoding and provided the rewritten text.)
最近,我们对查询分析进行了深入研究,并在修订相关文档时特别增加了一个关于如何处理高基数数值的页面。在这篇博客中,我们将深入探讨几种实验性方法,并提供它们的性能基准测试结果。
结果的概览可以在LangSmithhttps://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev中查看。接下来,我们将详细介绍:
 图片
图片
数据集概览
详细的数据集可以在这里查看https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev。
为了模拟这一问题,我们假设了一个场景:我们要查找某位作者关于外星人的书籍。在这个场景中,作家字段是一个高基数分类变量——可能的值有很多,但它们应该是特定的有效作家名称。 为了测试这一点,我们创建了一个包含作者姓名和常用别名的数据集。例如,“Harry Chase”可能是“Harrison Chase”的别名。我们希望智能系统能够处理这种别名。 在这个数据集中,我们生成了一个包含作家姓名和别名列表的数据集。注意,10,000个随机姓名不算太多——对于企业级系统来说,可能需要面对数百万级别的基数。
利用这个数据集,我们提出了这样的问题:“Harry Chase关于外星人的书有哪些?”我们的查询分析系统应该能够将这个问题解析为结构化格式,包含两个字段:主题和作者。在这个例子中,预期的输出应该是{“topic”: “aliens”,“author”: “Harrison Chase”}。我们期望系统能够识别出没有名为Harry Chase的作者,但Harrison Chase可能是用户想要表达的意思。
通过这种设置,我们可以针对我们创建的别名数据集进行测试,检查它们是否能够正确映射到真实姓名。同时,我们还会记录查询的延迟和成本。这种查询分析系统通常用于搜索,因此我们非常关心这两个指标。出于这个原因,我们也限制了所有方法只能进行一次LLM调用。我们可能会在未来的文章中对使用多次LLM调用的方法进行基准测试。
接下来,我们将介绍几种不同的方法及其性能表现。
 图片
图片
完整的结果可以在LangSmith中查看,复现这些结果的代码可以在这里找到。
基线测试
首先,我们对LLM进行了基线测试,即在不提供任何有效姓名信息的情况下,直接要求LLM进行查询分析。结果不出所料,没有一个问题得到了正确回答。这是因为我们故意构建了一个需要通过别名查询作者的数据集。
上下文填充法
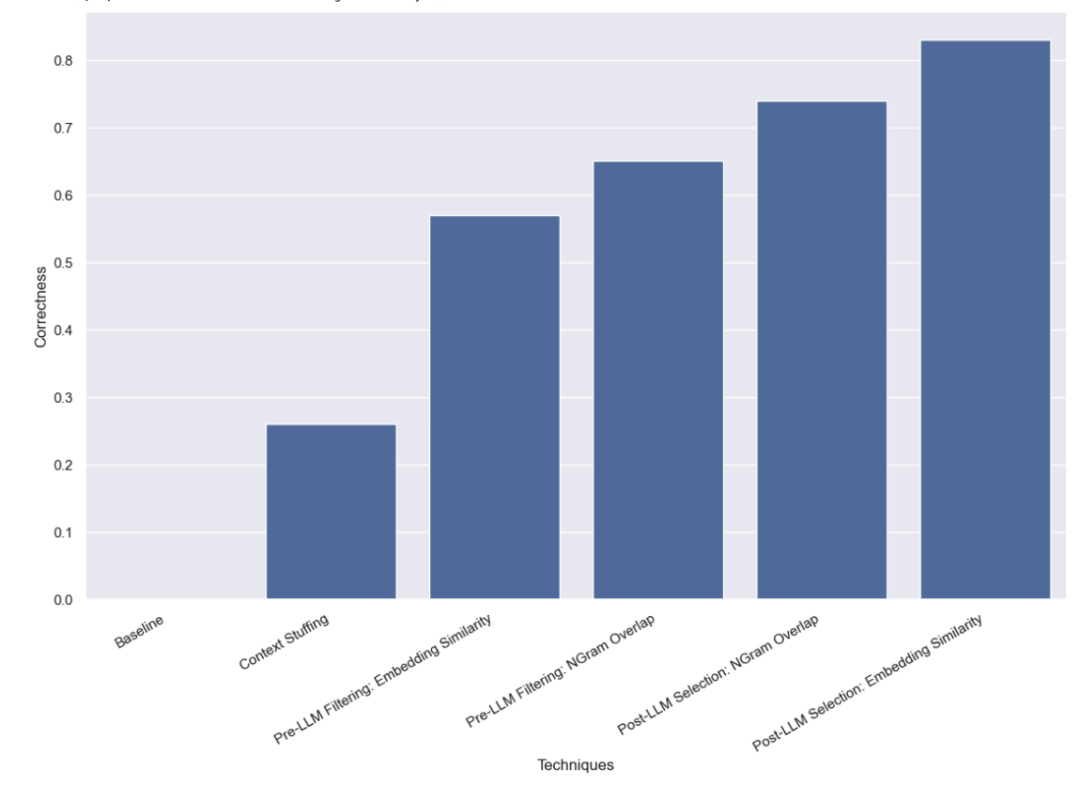
在这种方法中,我们将所有10,000个合法的作者姓名都放入了提示中,并要求LLM在进行查询分析时记住这些是合法的作者姓名。一些模型(如GPT-3.5)由于上下文窗口的限制,根本无法执行这个任务。对于其他具有更长上下文窗口的模型,它们在准确选择正确姓名方面也遇到了困难。GPT-4只在26%的案例中选择了正确的姓名。它最常见的错误是提取了姓名但没有进行校正。这种方法不仅速度慢,成本也高,平均需要5秒钟才能完成,总成本为8.44美元。
LLM前过滤法
我们接下来测试的方法是在将可能的值列表传递给LLM之前进行过滤。这样做的好处是只传递可能姓名的子集给LLM,这样LLM需要考虑的姓名就少得多,希望能够让它更快、更便宜、更准确地完成查询分析。但这也增加了一个新的潜在失败模式——如果初步过滤出错怎么办?
基于嵌入的过滤法
我们最初使用的过滤方法是嵌入法,并选择了与查询最相似的10个姓名。需要注意的是,我们是将整个查询与姓名进行比较,这并不是一个理想的比较方式!
我们发现,使用这种方法,GPT-3.5能够正确处理57%的案例。这种方法比以前的方法快得多,也便宜得多,平均只需要0.76秒就能完成,总成本仅为0.002美元。
基于NGram相似性的过滤法
我们使用的第二种过滤方法是对所有有效姓名的3-gram字符序列进行TF-IDF向量化,并使用向量化的有效姓名与向量化的用户输入之间的余弦相似度来选择最相关的10个有效姓名添加到模型提示中。同样需要注意的是,我们是将整个查询与姓名进行比较,这并不是一个理想的比较方式!
我们发现,使用这种方法,GPT-3.5能够正确处理65%的案例。这种方法同样比以前的方法快得多,也便宜得多,平均只需要0.57秒就能完成,总成本仅为0.002美元。
LLM后选择法
我们最后测试的方法是在LLM完成初步查询分析后,尝试纠正任何错误。我们首先对用户输入进行了查询分析,没有在提示中提供任何关于有效作者姓名的信息。这与我们最初进行的基线测试相同。然后,我们进行了一个后续步骤,取作者字段中的姓名,找到最相似的有效姓名。
基于嵌入相似性的选择法
首先,我们使用嵌入法进行了相似性检查。
我们发现,使用这种方法,GPT-3.5能够正确处理83%的案例。这种方法比以前的方法快得多,也便宜得多,平均只需要0.66秒就能完成,总成本仅为0.001美元。
基于NGram相似性的选择法
最后,我们尝试使用3-gram向量化器进行相似性检查。
我们发现,使用这种方法,GPT-3.5能够正确处理74%的案例。这种方法同样比以前的方法快得多,也便宜得多,平均只需要0.48秒就能完成,总成本仅为0.001美元。
结论
我们对处理高基数分类值的查询分析方法进行了多种基准测试。我们限制了自己只能进行一次LLM调用,这是为了模拟现实世界中的延迟限制。我们发现,使用LLM后基于嵌入相似性的选择方法表现最佳。
还有其他方法值得进一步测试。特别是,在LLM调用之前或之后寻找最相似的分类值有许多不同的方法。此外,本数据集中的类别基数并不像许多企业系统所面临的那样高。这个数据集大约有10,000个值,而许多现实世界中的系统可能需要处理的是数百万级别的基数。因此,对更高基数的数据进行基准测试将是非常有价值的。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- usdt怎么购买狗狗币
- 要使用USDT购买狗狗币,需先注册并验证加密货币交易所账户,然后存入USDT,选择交易对USDT/DOGE,下市价委托,输入购买金额,并确认交易即可。交易完成,狗狗币将存入交易所钱包。如何使用USDT购买狗狗币步骤1:注册并验证加密货币交易所账户选择一家信誉良好的加密货币交易所,如Binance或Coinbase。注册一个账户并完成身份验证流程。步骤2:存入USDT将USDT从您的钱包或其他交易所存入您的交易所账户。可以使用银行电汇、信用卡或借记卡等多种方式存入USDT。步骤3:选择交易对找到交易对USD
- 5分钟前 0
-
 正版软件
正版软件
- MakerDAO创始人:DeFi前端在欧洲可能需注册 持牌照才能营运
- 欧盟具有里程碑意义的加密资产市场法《MiCA》将于2024年6月正式生效,这将使欧盟成为世界上第一个拥有量身定制、全面加密货币法规的司法管辖区,不过MiCA可能涉及对DeFi的监管,正引发加密货币产业的疑虑。Cointelegraph上周报导,欧盟可能将通过MiCA法规,要求DeFi应用应取得牌照,根据MiCA规定,欧洲委员会被要求在今年12月30日前准备一份报告,评估DeFi市场、针对DeFi特别监管的可行性,欧盟目前尚未做出任何决定。DeFi前端将需获牌照?而Makerdao共同创办人RuneChri
- 20分钟前 元宇宙 Web3.0 Arbitrum 比特币爆仓 中币/ZB网 0
-
 正版软件
正版软件
- 币安在法律挫折后成立首个董事会
- 在全球交易量最大的加密货币交易所,通过首次成立董事会,在重塑其运营方面迈出了重要一步。这一举措是在该交易所去年对美国有关反洗钱(AML)和制裁违规的指控之后进行的。币安公布首届董事会成员根据彭博社的报道,董事会由七名成员组成,由巴巴多斯前驻联合国大使GabrielAbed担任主席。币安首席执行官ChangpengZhao和首席运营官TedLin也是董事会成员之一,另外三名公司高管分别是HeinaChen、JinkaiHe和LilaiWang。币安的监管首席执行官RichardTeng也是董事会成员之一。两
- 30分钟前 币安 董事会 0
-
 正版软件
正版软件
- 香港意博金融(VSFG)申请比特币现货ETF!目标最快5月挂牌上市
- 根据外媒报道,香港资产管理公司「意博金融(VSFG)」已提交比特币现货ETF申请,计划在今年5月挂牌上市。据ETF投资和产品集团主管陈裕楷(BrianChan)指出,“如果一切顺利的话”,预计这档ETF将能够在今年5月推出,“但为了安全起见,我们也会把时间范围延长到6月”。陈裕楷补充说:监管程序通常很难给出确切的日期,但我们正与证监会积极讨论。我们已迅速针对他们的初步反馈展开行动,并正处于密切合作状态。香港证监会(SFC)在12月份发布公告表示,已准备好接受加密货币现货ETF等基金的申请。中国大陆资产管理
- 45分钟前 比特币减半 比特币汇率 比特币暴跌 比特币支付 区块链金融 0
-
 正版软件
正版软件
- 比亚迪闪耀泰国曼谷国际车展,全品牌车型悉数登场
- 3月29日消息,比亚迪官方宣布,在近日盛大开幕的泰国第45届曼谷国际车展上,该品牌首次在海外全面展示了其全系车型。这一重要举措不仅彰显了比亚迪对泰国乃至整个东盟市场的深切关注和长期布局,更向全球消费者展现了其在新能源汽车领域的卓越实力和创新成果。数据小编了解到,比亚迪在此次车展上大放异彩,不仅发布了备受期待的2024年版BYDATTO3(国内对应车型为元PLUS)长续航版,还宣布了腾势D9车型的盲订活动。同时,多款全新车型也同步亮相,包括首款右舵宋MaxEV、BYDSEALION(海狮07)、BYDSEA
- 1小时前 02:10 比亚迪 0













