使用Java连接Redis的方法
 发布于2023-04-28 阅读(0)
发布于2023-04-28 阅读(0)
扫一扫,手机访问
一、Java连接池连接(管道,lua)
加入如下依赖
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version></dependency>
1、Test
public class Test {public static void main(String[] args) {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(20);jedisPoolConfig.setMaxIdle(10);jedisPoolConfig.setMinIdle(5);// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.157.6", 6379, 3000, null);Jedis jedis = null;try {// 从redis连接池里拿出一个连接执行命令jedis = jedisPool.getResource();System.out.println(jedis.set("single", "zhuge"));System.out.println(jedis.get("single"));// 管道示例// 管道的命令执行方式:cat redis.txt | redis‐cli ‐h 127.0.0.1 ‐a password ‐ p 6379 ‐‐pipePipeline pl = jedis.pipelined();for (int i = 0; i < 10; i++) {pl.incr("pipelineKey");pl.set("zhuge" + i, "zhuge");}List<Object> results = pl.syncAndReturnAll();System.out.println(results);// lua脚本模拟一个商品减库存的原子操作// lua脚本命令执行方式:redis‐cli ‐‐eval /tmp/test.lua , 10jedis.set("product_count_10016", "15"); // 初始化商品10016的库存String script = " local count = redis.call('get', KEYS[1]) " +" local a = tonumber(count) "+" local b = tonumber(ARGV[1]) " +" if a >= b then " +" redis.call('set', KEYS[1], count‐b) "+" return 1 " +" end " +" return 0 ";System.out.println("script:"+script);Object obj = jedis.eval(script, Arrays.asList("product_count_10016"), Arrays.asList("10"));System.out.println(obj);} catch (Exception e) {e.printStackTrace();} finally {// 注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedis != null)jedis.close();}}}2、管道(Pipeline)
客户端可以一次性发送多个请求而不用等待服务器的响应,待所有命令都发送完后再一次性读取服务的响应,这样可以极大的降低多条命令执行的网络传输开销,管道执行多条命令的网络开销实际上只相当于一次命令执行的网络开销。需要注意到是用pipeline方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。pipeline中发送的每个command都会被server立即执行,如果执行失败,将会在此后的响应中得到信息;也就是pipeline并不是表达“所有command都一起成功”的语义,管道中前面命令失败,后面命令不会有影响,继续执行。
例子参考如上。
3、Redis Lua脚本
Redis在2.6推出了脚本功能,允许开发者使用Lua语言编写脚本传到Redis中执行。使用脚本的好处如下:
1、减少网络开销
本来5次网络请求的操作,可以用一个请求完成,原先5次请求的逻辑放在redis服务器上完成。使用脚本,减少了网络往返时延。这点跟管道类似。
2、原子操作
Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。管道不是原子的,不过redis的批量操作命令(类似mset)是原子的。
3、替代redis的事务功能
redis自带的事务功能很鸡肋,报错不支持回滚,而redis的lua脚本几乎现了常规的事务功能,支持报错回滚操作,官方推荐如果要使用redis的事务功能可以用redis lua替代。
官网文档上有这样一段话:
A Redis script is transactional by definition, so everything you can do with a Redis transaction, you can also do with a script,and usually the script will be both simpler and faster.
从Redis2.6.0版本开始,通过内置的Lua解释器,可以使用EVAL命令对Lua脚本进行求值。EVAL命令的格
式如下:
EVAL script numkeys key [key ...] arg [arg ...]
script参数是一段Lua脚本程序,它会被运行在Redis服务器上下文中,这段脚本不必(也不应该)定义为一
个Lua函数。numkeys参数用于指定键名参数的个数。键名参数 key [key …] 从EVAL的第三个参数开始算
起,表示在脚本中所用到的那些Redis键(key),这些键名参数可以在 Lua中通过全局变量KEYS数组,用1
为基址的形式访问( KEYS[1] , KEYS[2] ,以此类推)。在命令的最后,那些不是键名参数的附加参数 arg [arg …] ,可以在Lua中通过全局变量ARGV数组访问,访问的形式和KEYS变量类似( ARGV[1] 、 ARGV[2] ,诸如此类)。例如
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second2 1) "key1"3 2) "key2"4 3) "first"5 4) "second"其中 “return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}” 是被求值的Lua脚本,数字2指定了键名参数的数
量, key1和key2是键名参数,分别使用 KEYS[1] 和 KEYS[2] 访问,而最后的 first 和 second 则是附加
参数,可以通过 ARGV[1] 和 ARGV[2] 访问它们。在 Lua 脚本中,可以使用redis.call()函数来执行Redis命令
例子参考如上。
注意,不要在Lua脚本中出现死循环和耗时的运算,否则redis会阻塞,将不接受其他的命令, 所以使用
时要注意不能出现死循环、耗时的运算。redis是单进程、单线程执行脚本。管道不会阻塞redis。
二、哨兵的Jedis连接代码
public class Test2 {public static void main(String[] args) {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(20);jedisPoolConfig.setMaxIdle(10);jedisPoolConfig.setMinIdle(5);String masterName = "mymaster";Set<String> sentinels = new HashSet<String>();sentinels.add(new HostAndPort("192.168.157.6",26379).toString());sentinels.add(new HostAndPort("192.168.157.6",26380).toString());sentinels.add(new HostAndPort("192.168.157.6",26381).toString());// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数JedisSentinelPool jedisSentinelPool = new JedisSentinelPool(masterName, sentinels, jedisPoolConfig, 3000, null);Jedis jedis = null;try {// 从redis连接池里拿出一个连接执行命令jedis = jedisSentinelPool.getResource();while(true) {Thread.sleep(1000);try {System.out.println(jedis.set("single", "zhuge"));System.out.println(jedis.get("single"));} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}}} catch (Exception e) {e.printStackTrace();} finally {// 注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedis != null)jedis.close();}}}三、哨兵的Spring Boot整合Redis连接
1、引入相关依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring‐boot‐starter‐data‐redis</artifactId></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons‐pool2</artifactId></dependency>
2、springboot项目核心配置
server:port: 8080spring:redis:database: 0timeout: 3000sentinel: #哨兵模式master: mymaster #主服务器所在集群名称nodes: 192.168.0.60:26379,192.168.0.60:26380,192.168.0.60:26381lettuce:pool:max‐idle: 50min‐idle: 10max‐active: 100max‐wait: 1000
3、访问代码
@RestControllerpublic class IndexController {private static final Logger logger = LoggerFactory.getLogger(IndexController.class);@Autowiredprivate StringRedisTemplate stringRedisTemplate;/*** 测试节点挂了哨兵重新选举新的master节点,客户端是否能动态感知到* 新的master选举出来后,哨兵会把消息发布出去,客户端实际上是实现了一个消息监听机制,* 当哨兵把新master的消息发布出去,客户端会立马感知到新master的信息,从而动态切换访问的masterip* @throws InterruptedException*/@RequestMapping("/test_sentinel")public void testSentinel() throws InterruptedException {int i = 1;while (true){try {stringRedisTemplate.opsForValue().set("zhuge"+i, i+"");System.out.println("设置key:"+ "zhuge" + i);i++;Thread.sleep(1000);}catch (Exception e){logger.error("错误:", e);}}}}4、StringRedisTemplate与RedisTemplate
spring 封装了 RedisTemplate 对象来进行对redis的各种操作,它支持所有的 redis 原生的 api。在
RedisTemplate中提供了几个常用的接口方法的使用,分别是:
private ValueOperations<K, V> valueOps;private HashOperations<K, V> hashOps;private ListOperations<K, V> listOps;private SetOperations<K, V> setOps;private ZSetOperations<K, V> zSetOps;
RedisTemplate中定义了对5种数据结构操作
redisTemplate.opsForValue();//操作字符串redisTemplate.opsForHash();//操作hashredisTemplate.opsForList();//操作listredisTemplate.opsForSet();//操作setredisTemplate.opsForZSet();//操作有序set
StringRedisTemplate继承自RedisTemplate,也一样拥有上面这些操作。
StringRedisTemplate默认采用的是String的序列化策略,保存的key和value都是采用此策略序列化保存
的。RedisTemplate默认采用的是JDK的序列化策略,保存的key和value都是采用此策略序列化保存的。
也就是若是用RedisTemplate保存的内容,你在控制台打开看到会是很多编码后的字符,比较难理解。
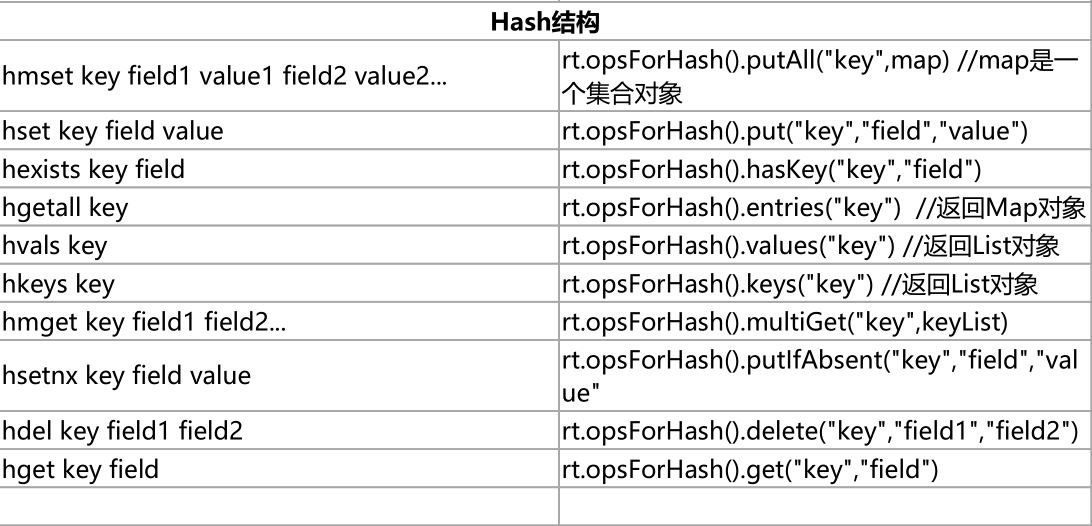
Redis客户端命令对应的RedisTemplate中的方法列表: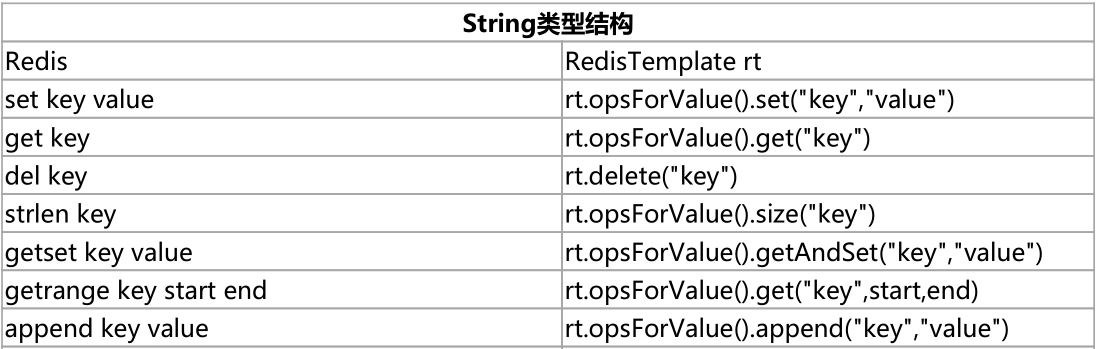


四、集群的Jedis连接代码
public class Test3 {public static void main(String[] args) throws IOException {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(20);jedisPoolConfig.setMaxIdle(10);jedisPoolConfig.setMinIdle(5);Set<HostAndPort> jedisClusterNode = new HashSet<HostAndPort>();jedisClusterNode.add(new HostAndPort("192.168.0.61", 8001));jedisClusterNode.add(new HostAndPort("192.168.0.62", 8002));jedisClusterNode.add(new HostAndPort("192.168.0.63", 8003));jedisClusterNode.add(new HostAndPort("192.168.0.61", 8004));jedisClusterNode.add(new HostAndPort("192.168.0.62", 8005));jedisClusterNode.add(new HostAndPort("192.168.0.63", 8006));// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数JedisCluster jedisCluster = new JedisCluster(jedisClusterNode, 6000, 5000, 10, "zhuge", jedisPoolConfig);try {while(true) {Thread.sleep(1000);try {System.out.println(jedisCluster.set("single", "zhuge"));System.out.println(jedisCluster.get("single"));} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}}} catch (Exception e) {e.printStackTrace();} finally {// 注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedisCluster != null)jedisCluster.close();}}}五、集群模式Springboot整合redis
其实集群模式跟哨兵模式很类似,只不过配置文件修改一下即可
server:port: 8080spring:redis:database: 0timeout: 3000password: zhugecluster:nodes:192.168.0.61:8001,192.168.0.62:8002,192.168.0.63:8003lettuce:pool:# 连接池中的最大空闲连接max‐idle: 50# 连接池中最小空闲连接min‐idle: 10max‐active: 100# 连接池阻塞等待时间(负值表示没有限制)max‐wait: 1000
只不过 sentinel换成了 cluster,然后API什么的都是一样的。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 探究Java线程同步和互斥的奥秘:揭示并发编程的精髓
- 深入剖析Java线程同步与互斥:掌握并发编程的精髓在现代计算机科学中,并发编程是至关重要的组成部分。为了协调多个线程之间的交互并确保代码的正确执行,需要对共享数据进行同步和互斥。Java作为一门流行的编程语言,提供了丰富的同步机制来管理线程之间的访问。本文将深入剖析Java线程同步与互斥,揭开并发编程的奥秘。一、Java线程同步基础同步是指多个线程对共享数据进行访问时,必须按照一定的顺序进行,以避免出现数据不一致的情况。Java提供了多种同步机制,包括:同步方法:通过在方法前加上synchronized关
- 9分钟前 多线程 并发 同步 volatile 互斥锁 原子操作 0
-
正版软件
- 最有效的方法学习Golang中的错误处理
- 错误处理在编程中是一个非常重要的主题。在Golang中,错误处理的方式与其他编程语言有所不同,因此需要掌握一些最佳实践来优化代码的可读性和可维护性。1.返回错误值而不是抛出异常与其他一些语言不同,Golang鼓励使用返回值来表示错误,而不是通过抛出异常来处理错误。这种方式使得代码更加清晰和可控。下面是一个示例:funcdivide(x,yint)(
- 14分钟前 实践 Golang 错误处理 0
-
正版软件
- 深入解析volatile关键字
- volatile关键字详解在多线程编程中,我们经常会遇到共享变量的读写问题。由于各个线程有自己的缓存,当一个线程对共享变量进行写操作时,其他线程无法立即看到这个写操作的结果,这就导致了数据不一致的问题。为了解决这个问题,Java提供了一个volatile关键字。volatile关键字用于修饰共享变量,它具有两个主要的特性:可见性:当一个线程对volatile
- 29分钟前 详解 关键字 0
-
 正版软件
正版软件
- 解答常见问题:Python 字典的疑难解决
- 1.如何在字典中添加键值对?在字典中添加键值对,可以使用以下两种方法:#方法一:使用方括号my_dict["key"]="value"#方法二:使用update()方法my_dict.update({"key":"value"})2.如何在字典中查找键?在字典中查找键,可以使用以下两种方法:#方法一:使用in运算符if"key"inmy_dict:print("Keyexists")else:print("Keydoesnotexist")#方法二:使用get()方法value=my_dict.get("
- 44分钟前 Python 数据类型 运算符 字典 键值对 0
-
正版软件
- 在SQL中如何使用WHERE语句
- SQL中WHERE的用法,需要具体代码示例SQL(StructuredQueryLanguage)是一种用于管理关系数据库管理系统(RDBMS)的标准化语言。在SQL中,WHERE子句用于过滤SELECT语句返回的数据。通过WHERE子句,我们可以根据特定的条件选择需要的数据行。WHERE子句的一般语法如下:SELECTcolumn1,column2
- 59分钟前 where子句 where条件 SQL过滤 0
最新发布
-
 1
1
-
 2
2
-
3
- Vue组件中如何处理图片预览和缩放问题
- 436天前
-
 4
4
-
 5
5
-
 6
6
- Python实战教程:批量转换多种音乐格式
- 607天前
-
7
- WebSocket协议的优势与劣势分析
- 438天前
-
8
- java动态代理实例代码分析
- 608天前
-
 9
9
- java io文件操作删除文件或文件夹的方法
- 605天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00