Java中KMP算法怎么实现
 发布于2023-04-28 阅读(0)
发布于2023-04-28 阅读(0)
扫一扫,手机访问
图解
kmp算法跟之前讲的bm算法思想有一定的相似性。之前提到过,bm算法中有个好后缀的概念,而在kmp中有个好前缀的概念,什么是好前缀,我们先来看下面这个例子。
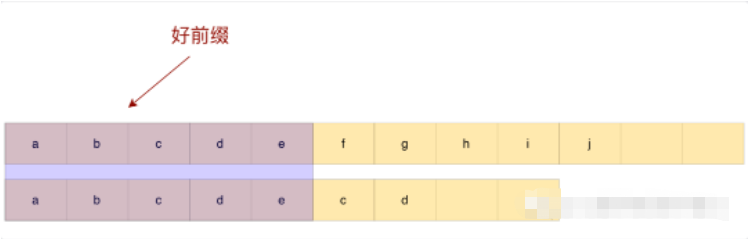
观察上面这个例子,已经匹配的abcde称为好前缀,a与之后的bcde都不匹配,所以没有必要再比一次,直接滑动到e之后即可。
那如果好前缀中有互相匹配的字符呢?
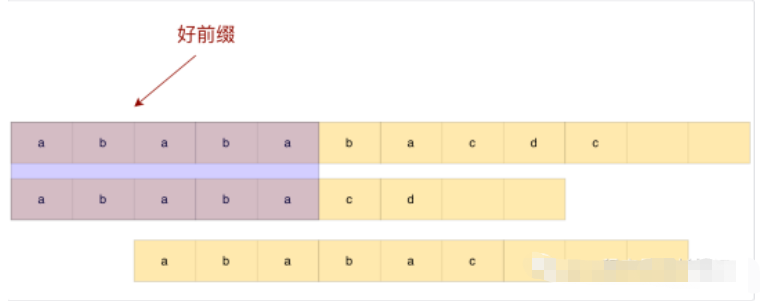
观察上面这个例子,这个时候如果我们直接滑到好前缀之后,则会过度滑动,错失匹配子串。那我们如何根据好前缀来进行合理滑动?
其实就是看当前的好前缀的前缀和后缀是否有匹配的,找到最长匹配长度,直接滑动。鉴于不止一次找最长匹配长度,我们完全可以先初始化一个数组,保存在当前好前缀情况下,最长匹配长度是多少,这时候我们的next数组就出来了。
我们定义一个next数组,表示在当前好前缀下,好前缀的前缀和后缀的最长匹配子串长度,这个最长匹配长度表示这个子串之前已经匹配过匹配了,不需要再次进行匹配,直接从子串的下一个字符开始匹配。

我们是否每次算next[i]时都需要每一个字符进行匹配,是否可以根据next[i - 1]进行推导以便减少不必要的比较。
带着这个思路我们来看看下面的步骤:
假设next[i - 1] = k - 1;
如果modelStr[k] = modelStr[i] 则next[i]=k

如果modelStr[k] != modelStr[i],我们是否可以直接认定next[i] = next[i - 1]?

通过上面这个例子,我们可以很清晰的看到,next[i]!=next[i-1],那当modelStr[k]!=modelStr[i]时候,我们已知next[0],next[1]…next[i-1],如何推倒出next[i]呢?
假设modelStr[x…i]是前缀后缀能匹配的最长后缀子串,那么最长匹配前缀子串为modelStr[0…i-x]

我们在求这个最长匹配串的时候,他的前面的次长匹配串(不包含当前i的),也就是modelStr[x…i-1]在之前应该是已经求解出来了的,因此我们只需要找到这个某一个已经求解的匹配串,假设前缀子串为modelStr[0…i-x-1],后缀子串为modelStr[x…i-1],且modelStr[i-x] == modelStr[i],这个前缀后缀子串即为次前缀子串,加上当前字符即为最长匹配前缀后缀子串。
代码实现
首先在kmp算法中最主要的next数组,这个数组标志着截止到当前下标的最长前缀后缀匹配子串字符个数,kmp算法里面,如果某个前缀是好前缀,即与模式串前缀匹配,我们就可以利用一定的技巧不止向前滑动一个字符,具体看前面的讲解。我们提前不知道哪些是好前缀,并且匹配过程不止一次,因此我们在最开始调用一个初始化方法,初始化next数组。
1.如果上一个字符的最长前缀子串的下一个字符==当前字符,上一个字符的最长前缀子串直接加上当前字符即可
2.如果不等于,需要找到之前存在的最长前缀子串的下一个字符等于当前子串的,然后设置当前字符子串的最长前缀后缀子串
int[] next ;
/**
* 初始化next数组
* @param modelStr
*/
public void init(char[] modelStr) {
//首先计算next数组
//遍历modelStr,遍历到的字符与之前字符组成一个串
next = new int[modelStr.length];
int start = 0;
while (start < modelStr.length) {
next[start] = this.recursion(start, modelStr);
++ start;
}
}
/**
*
* @param i 当前遍历到的字符
* @return
*/
private int recursion(int i, char[] modelStr) {
//next记录的是个数,不是下标
if (0 == i) {
return 0;
}
int last = next[i -1];
//没有匹配的,直接判断第一个是否匹配
if (0 == last) {
if (modelStr[last] == modelStr[i]) {
return 1;
}
return 0;
}
//如果last不为0,有值,可以作为最长匹配的前缀
if (modelStr[last] == modelStr[i]) {
return next[i - 1] + 1;
}
//当next[i-1]对应的子串的下一个值与modelStr不匹配时,需要找到当前要找的最长匹配子串的次长子串
//依据就是次长子串对应的子串的下一个字符==modelStr[i];
int tempIndex = i;
while (tempIndex > 0) {
last = next[tempIndex - 1];
//找到第一个下一个字符是当前字符的匹配子串
if (modelStr[last] == modelStr[i]) {
return last + 1;
}
-- tempIndex;
}
return 0;
}然后开始利用next数组进行匹配,从第一个字符开始匹配进行匹配,找到第一个不匹配的字符,这时候之前的都是匹配的,接下来先判断是否已经是完全匹配,是直接返回,不是,判断是否第一个就不匹配,是直接往后面匹配。如果有好前缀,这时候就利用到了next数组,通过next数组知道当前可以从哪个开始匹配,之前的都不用进行匹配。
public int kmp(char[] mainStr, char[] modelStr) {
//开始进行匹配
int i = 0, j = 0;
while (i + modelStr.length <= mainStr.length) {
while (j < modelStr.length) {
//找到第一个不匹配的位置
if (modelStr[j] != mainStr[i]) {
break;
}
++ i;
++ j;
}
if (j == modelStr.length) {
//证明完全匹配
return i - j;
}
//走到这里找到的是第一个不匹配的位置
if (j == 0) {
++ i;
continue;
}
//从好前缀后一个匹配
j = next[j - 1];
}
return -1;
} 产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Spring Boot测试框架揭秘:保障代码质量的必备利器
- 二、SpringBoot测试框架的功能springBoot测试框架提供了许多功能,其中包括:测试注解:SpringBoot测试框架提供了许多测试注解,这些注解可以帮助开发人员轻松地配置和运行测试。例如,@SpringBootTest注解可以帮助开发人员快速启动SpringBoot应用程序,并将其注入到测试上下文中。实用程序:SpringBoot测试框架还提供了一些实用程序,这些实用程序可以帮助开发人员轻松地测试他们的应用程序。例如,Mockmvc类可以帮助开发人员模拟Http请求,并验证应用程序的响应。测
- 8分钟前 单元测试 测试框架 集成测试 端到端测试 0
-
 正版软件
正版软件
- 制胜关键:PHP 跨站请求伪造(CSRF)的防茅策略
- CSRF攻击可以造成多种危害,包括:窃取敏感信息:攻击者可以通过CSRF攻击窃取受害者的登录凭证、信用卡信息、电子邮件地址等敏感信息。破坏网站数据:攻击者可以通过CSRF攻击修改或删除网站的数据,从而导致网站无法正常运行。传播恶意软件:攻击者可以通过CSRF攻击在受害者的计算机上安装恶意软件,从而控制受害者的计算机。CSRF攻击防范措施为了防范CSRF攻击,网站管理员和开发人员可以采取多种措施,包括:使用CSRF令牌:CSRF令牌是一种随机生成的唯一字符串,网站在生成每个表单时都会在表单中嵌入一个CSRF
- 13分钟前 0
-
 正版软件
正版软件
- 提前防范风险:PHP 跨站请求伪造(CSRF)的前瞻性防范策略
- 常见的CSRF攻击类型1.表单提交CSRF攻击这种攻击类型是通过欺骗受害者点击伪造的链接或按钮,导致受害者的浏览器向攻击者的网站发送POST请求,从而执行攻击者预期的操作。2.GET请求CSRF攻击GET请求CSRF攻击通过欺骗受害者点击伪造的链接或图像,导致受害者的浏览器向攻击者的网站发送GET请求,从而执行攻击者预期的操作。3.JSON请求CSRF攻击JSON请求CSRF攻击通过欺骗受害者点击伪造的链接或按钮,导致受害者的浏览器向攻击者的网站发送jsON请求,从而执行攻击者预期的操作。4.AJAX请求
- 28分钟前 0
-
 正版软件
正版软件
- PHP 跨站请求伪造(CSRF)的防范策略
- 一、跨站请求伪造(CSRF)简介跨站请求伪造(CSRF)是一种常见的WEB安全漏洞,它允许攻击者在未经授权的情况下以受害者的身份执行恶意操作。CSRF攻击通常通过诱使用户点击恶意链接或打开恶意网站来发起,攻击者利用用户的信任,促使受害者在不知不觉中访问攻击者的服务器,并携带受害者的身份验证信息,向受害者的Web应用程序发送攻击者精心构造的请求。攻击者可以利用这些请求来执行各种恶意操作,例如修改或删除敏感数据、进行欺诈交易、发送垃圾邮件等。二、跨站请求伪造(CSRF)的危害CSRF攻击的危害是巨大的,它可能
- 43分钟前 PHP csrf Web 安全 验证机制 安全防范措施 随机数令牌 0
-
 正版软件
正版软件
- 提升 Java JNDI 性能的方法:优化 Java JNDI 的效率和性能
- 1.使用连接池连接池是优化JavaJNDI性能的有效方法之一。连接池通过预先创建和维护一定数量的数据库连接,以便应用程序随时使用,从而减少了创建新连接的开销。//创建连接池ConnectionPoolpool=newConnectionPool();//获取连接Connectionconnection=pool.getConnection();//使用连接...//释放连接connection.close();2.使用缓存缓存是另一种优化JavaJNDI性能的有效方法。缓存通过将经常使用的数据存储在内存中
- 58分钟前 0
最新发布
-
 1
1
-
 2
2
-
3
- Vue组件中如何处理图片预览和缩放问题
- 438天前
-
 4
4
-
 5
5
-
 6
6
- Python实战教程:批量转换多种音乐格式
- 609天前
-
7
- WebSocket协议的优势与劣势分析
- 440天前
-
8
- java动态代理实例代码分析
- 610天前
-
 9
9
- java io文件操作删除文件或文件夹的方法
- 607天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00