使用矢量化替代循环的Python编程技巧
 发布于2023-04-30 阅读(0)
发布于2023-04-30 阅读(0)
扫一扫,手机访问
所有编程语言都离不开循环。因此,默认情况下,只要有重复操作,我们就会开始执行循环。但是当我们处理大量迭代(数百万/十亿行)时,使用循环是一种犯罪。您可能会被困几个小时,后来才意识到它行不通。这就是在 python 中实现矢量化变得非常关键的地方。
什么是矢量化?
矢量化是在数据集上实现 (NumPy) 数组操作的技术。在后台,它将操作一次性应用于数组或系列的所有元素(不同于一次操作一行的“for”循环)。
接下来我们使用一些用例来演示什么是矢量化。
求数字之和
##使用循环
import time
start = time.time()
# iterative sum
total = 0
# iterating through 1.5 Million numbers
for item in range(0, 1500000):
total = total + item
print('sum is:' + str(total))
end = time.time()
print(end - start)
#1124999250000
#0.14 Seconds## 使用矢量化 import numpy as np start = time.time() # vectorized sum - using numpy for vectorization # np.arange create the sequence of numbers from 0 to 1499999 print(np.sum(np.arange(1500000))) end = time.time() print(end - start) ##1124999250000 ##0.008 Seconds
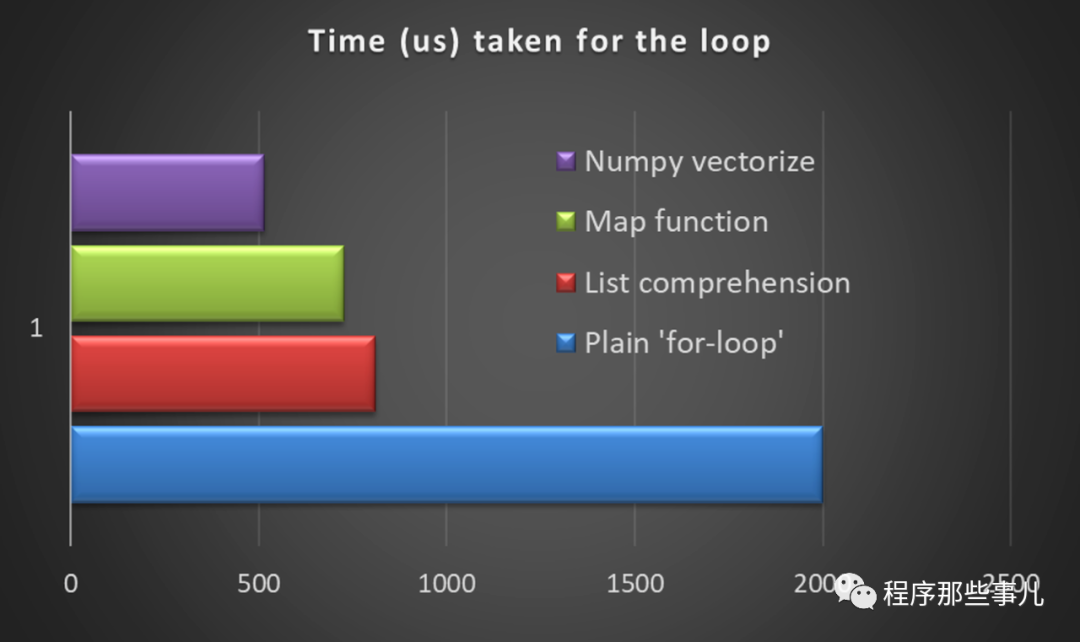
与使用范围函数的迭代相比,矢量化的执行时间减少了约 18 倍。在使用 Pandas DataFrame 时,这种差异将变得更加显著。
数学运算
在数据科学中,在使用 Pandas DataFrame 时,开发人员使用循环通过数学运算创建新的派生列。
在下面的示例中,我们可以看到对于此类用例,用矢量化替换循环是多么容易。
DataFrame 是行和列形式的表格数据。
我们创建一个具有 500 万行和 4 列的 pandas DataFrame,其中填充了 0 到 50 之间的随机值。
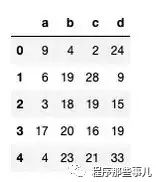
import numpy as np import pandas as pd df = pd.DataFrame(np.random.randint( 0 , 50 , size=( 5000000 , 4 )), columns=( 'a' , 'b' , 'c' , 'd ' )) df.shape # (5000000, 5) df.head()
创建一个新列“ratio”来查找列“d”和“c”的比率。
## 循环遍历 import time start = time.time() # 使用 iterrows 遍历 DataFrame for idx, row in df.iterrows(): # 创建一个新列 df.at[idx, 'ratio' ] = 100 * (row[ "d" ] / row[ "c" ]) end = time.time() print (end - start) ### 109 秒
## 使用矢量化 start = time.time() df[ "ratio" ] = 100 * (df[ "d" ] / df[ "c" ]) end = time.time() print (end - start) ### 0.12 秒
我们可以看到 DataFrame 的显著改进,与Python 中的循环相比,矢量化操作所花费的时间几乎快 1000 倍。
If-else 语句
我们实现了很多需要我们使用“If-else”类型逻辑的操作。我们可以轻松地将这些逻辑替换为 python 中的矢量化操作。
让我们看下面的例子来更好地理解它(我们将使用我们在用例 2 中创建的 DataFrame):
想象一下,我们要根据现有列“a”上的某些条件创建一个新列“e”
## 使用循环 import time start = time.time() # 使用 iterrows 遍历 DataFrame for idx, row in df.iterrows(): if row.a == 0 : df.at[idx, 'e' ] = row.d elif ( row.a <= 25 ) & (row.a > 0 ): df.at[idx, 'e' ] = (row.b)-(row.c) else : df.at[idx, 'e' ] = row.b + row.c end = time.time() print (end - start) ### 耗时:166 秒
## 矢量化 start = time.time() df[ 'e' ] = df[ 'b' ] + df[ 'c' ] df.loc[df[ 'a' ] <= 25 , 'e' ] = df [ 'b' ] -df[ 'c' ] df.loc[df[ 'a' ]== 0 , 'e' ] = df[ 'd' ]end = time.time() 打印(结束 - 开始) ## 0.29007707595825195 秒
与使用 if-else 语句的 python 循环相比,向量化操作所花费的时间快 600 倍。
解决机器学习/深度学习网络
深度学习要求我们解决多个复杂的方程式,而且需要解决数百万和数十亿行的问题。在 Python 中运行循环来求解这些方程式非常慢,矢量化是最佳解决方案。
例如,计算以下多元线性回归方程中数百万行的 y 值:
我们可以用矢量化代替循环。
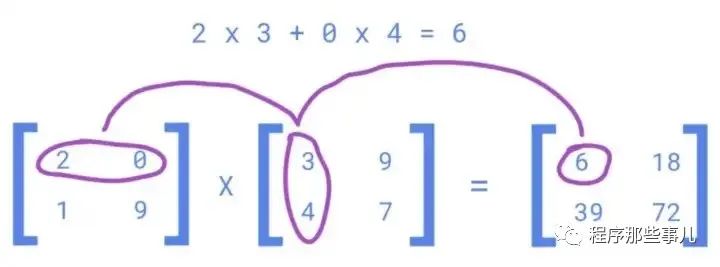
m1、m2、m3……的值是通过使用与 x1、x2、x3……对应的数百万个值求解上述等式来确定的
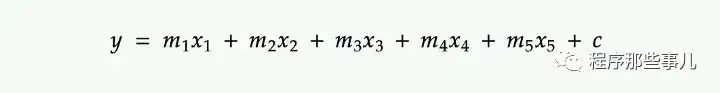

import numpy as np # 设置 m 的初始值 m = np.random.rand( 1 , 5 ) # 500 万行的输入值 x = np.random.rand( 5000000 , 5 )
## 使用循环
import numpy as np
m = np.random.rand(1,5)
x = np.random.rand(5000000,5)
total = 0
tic = time.process_time()
for i in range(0,5000000):
total = 0
for j in range(0,5):
total = total + x[i][j]*m[0][j]
zer[i] = total
toc = time.process_time()
print ("Computation time = "+ str ((toc - tic)) + "seconds" )
####计算时间 = 27.02 秒## 矢量化 tic = time.process_time() #dot product np.dot(x,mT) toc = time.process_time() print ( "计算时间 = " + str ((toc - tic)) + "seconds" ) ####计算时间 = 0.107 秒
np.dot 在后端实现向量化矩阵乘法。与 Python 中的循环相比,它快 165 倍。
结论
python 中的矢量化速度非常快,无论何时我们处理非常大的数据集,都应该优先于循环。

随着时间的推移开始实施它,您将习惯于按照代码的矢量化思路进行思考。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 解密 Java 文件操作:突破文件操作的限制
- 文件操作是Java程序设计中至关重要的一环,因为它允许程序与文件系统交互,存储和检索数据。本文旨在深入揭秘Java文件操作的奥秘,为读者提供全面且深入的理解。文件输入文件输入涉及从文件中读取数据。在Java中,主要使用以下类和方法来实现文件输入:FileInputStream:允许读取原始字节数据。DatainputStream:提供了读取特定数据类型的便利方法(例如int、long和float)。Scanner:一个更高级别的类,用于以一行行的形式读取文本文件。文件输出文件输出涉及将数据写入文件。以下类
- 7分钟前 引言 0
-
 正版软件
正版软件
- 在Java中平衡文件操作的灵活性和效率
- JavaNIO(NewI/O)JavaNIO是SunMicrosystems于Java1.4版本引入的一种新型I/O机制,旨在提供更高的性能和可伸缩性。Nio提供了非阻塞I/O操作,允许应用程序在无需等待I/O操作完成的情况下继续处理其他任务。这种异步处理方式减少了线程开销,提高了并发处理能力。优点:非阻塞I/O,提高并发性高效的内存映射文件访问可定制的缓冲区管理缺点:编程复杂度更高可能造成额外内存开销JavaBIO(BlockingI/O)JavaBIO是传统的文件I/O机制,使用阻塞式I/O操作。当执
- 17分钟前 0
-
 正版软件
正版软件
- 使用PHP绘制一个椭圆
- 这篇文章将为大家详细讲解有关PHP画一个椭圆,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。PHP画椭圆前言php语言提供了丰富的函数库,其中GD库专门用于图像处理,可以在PHP中绘制各种形状,包括椭圆。绘制椭圆1.加载GD库<?php//加载GD库imagettftext($im,12,0,50,50,$color,$font,$text);?>2.创建图像<?php//创建一个新图像$im=imagecreatetruecolor(640,480);
- 32分钟前 PHP编程 GD库 PHP图像处理 后端开发 绘制椭圆 PHP画一个椭圆 线条宽度 椭圆弧 0
-
 正版软件
正版软件
- 探索Java文件操作的最新趋势:数据处理的未来
- 1.大数据处理现代企业处理的数据量不断爆炸式增长,传统的序列文件操作方式已无法满足大规模数据处理的需求。因此,Java引入了大数据处理框架,如hadoop和spark,这些框架提供分布式文件系统和并行计算能力,可以高效地处理TB甚至PB级的数据。2.云计算存储云计算的兴起为文件存储提供了新的选择。Java可以使用云存储api与AmazonS3、GoogleCloudStorage等云存储服务集成,将数据存储在云端,从而降低本地存储成本,提高数据可访问性和可靠性。3.流式数据处理实时数据流分析已成为许多领域
- 47分钟前 0
-
 正版软件
正版软件
- 提升Java文件处理效率和可靠性的最佳实践
- 字节流(InputStream/OutputStream):适用于处理原始二进制数据。字符流(Reader/Writer):适用于处理文本文件。根据数据的类型和操作要求选择合适的流可以提高效率。2.使用缓冲流缓冲流通过在内存中临时存储数据来减少对底层存储设备的I/O操作数量。BufferedInputStream/BufferedOutputStream:针对字节流。BufferedReader/BufferedWriter:针对字符流。3.避免不必要的刷新刷新流会将数据从内存写入底层存储设备。频繁刷新会
- 1小时前 02:10 0
最新发布
-
 1
1
-
 2
2
-
3
- Vue组件中如何处理图片预览和缩放问题
- 491天前
-
 4
4
-
 5
5
-
 6
6
- Python实战教程:批量转换多种音乐格式
- 662天前
-
7
- WebSocket协议的优势与劣势分析
- 493天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 490天前
-
9
- java动态代理实例代码分析
- 663天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00