谷歌揭秘大模型不会数 r 原因:嵌入维度是关键,不止分词器问题
 发布于2025-01-12 阅读(0)
发布于2025-01-12 阅读(0)
扫一扫,手机访问
大模型做奥赛题游刃有余,简单的数数却屡屡翻车的原因找到了。
谷歌的一项新研究,发现大模型不会数数的原因,并不是简单的 tokenizer 所致,而是没有足够的空间来存储用于计数的向量。

数出一段话中某个单词出现的次数,这样简单的任务可以难倒许多大模型,GPT-4o、Claude 3.5 也无法幸免。
如果再进一步,想要找到出现频率最高的一个词,更是难如登天,即便能蒙对给出的具体数量也是错的。

有人认为是词汇的 token 化导致了大模型看到的 " 词 " 和我们的看法不一致,但论文表明,实际情况并不是这么简单。
想数清单词,嵌入维度要够大
Transformer 的计数能力与其嵌入维度 d 和词汇量 m(指词汇表中词的数量,非序列长度)的关系密切相关。
详细的原因,就涉及到了 Transformer 统计词频时的机制。
Transformer 通过一种特殊的嵌入方式,利用嵌入空间的线性结构,巧妙地将计数问题转化为了向量加法。
具体说是将每个词映射到一个独特的正交向量上,在这种表示下,词频可以通过对这些正交向量求和来简单地计算。
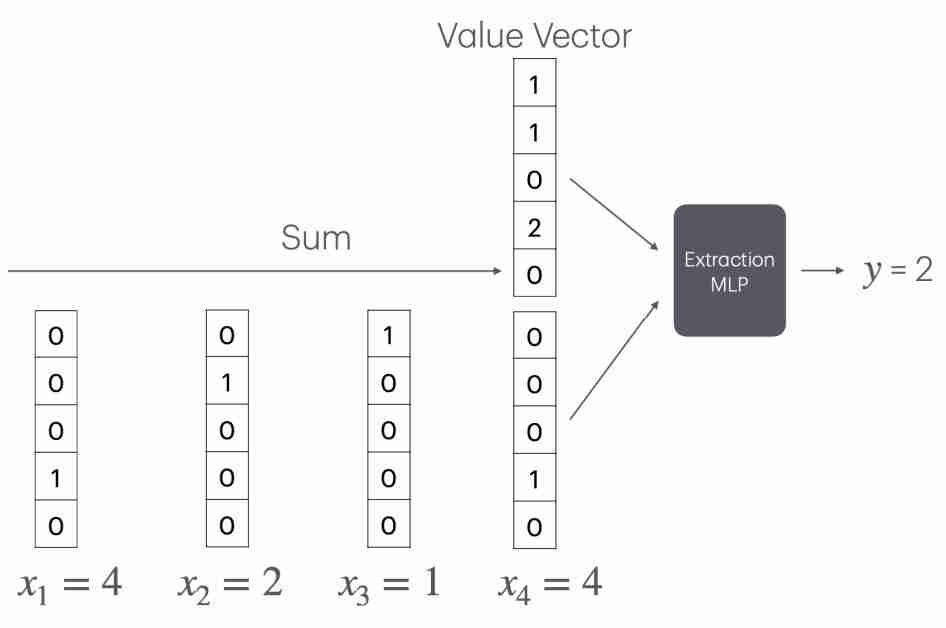
然而,这种机制的局限性在于,它要求词汇表中的每个词都有一个独立的正交向量表示,因此嵌入维度必须大于词汇量。
嵌入维度不足时,词向量就无法保持正交性,词频的线性叠加也就无法实现了。
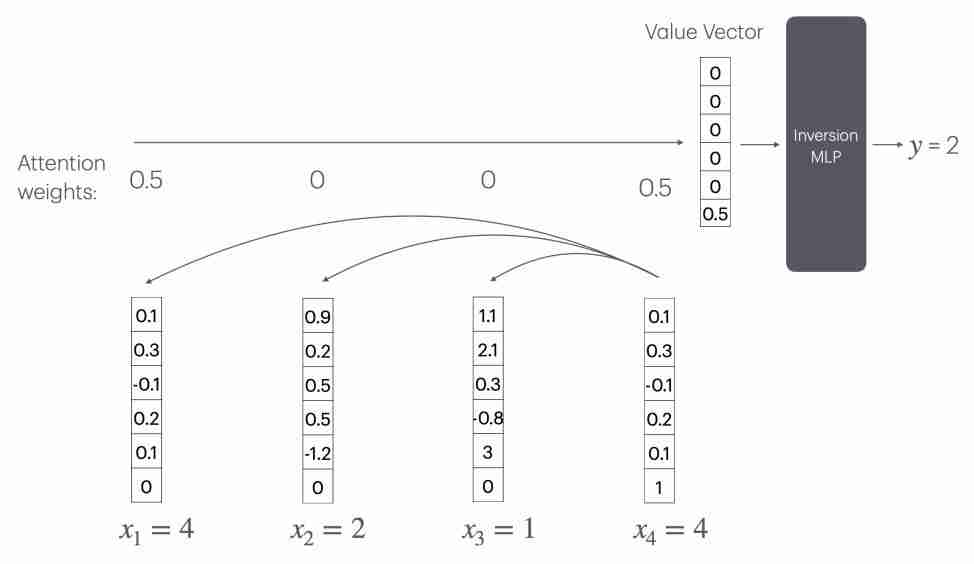
此时 Transformer 要实现计数,可以通过注意力机制(CountAttend)来实现,但需要一个随序列长度 n 线性增长的大型 " 逆转 MLP" 层。
具体来说,模型首先通过注意力赋予被查询词较大的权重,再利用位置编码将注意力权重提取到值向量的最后一个元素,这个元素实际记录了被查询词的出现频率的倒数。
这意味着,模型需要一个大小为 O ( n ) 的 MLP 层来计算 1/x 函数(x 为某个词出现的次数)。
但进一步分析表明,任何常数层 ReLU 网络都无法在 o ( n ) 的神经元数量下逼近 1/x 函数。
因此,对于固定规模的 Transformer,这种方案无法推广到任意长度的序列。当序列长度超出训练集长度时,模型的计数能力会急剧恶化。
长度非主要因素,词汇表中数量是关键
为了验证这一结论,作者一共进行了两个实验。
第一个实验,是在一个从头开始训练的 Transformer 模型上进行的,具体有关参数如下:
使用一个由两个 Transformer 层、四个注意力头组成的标准模型;
嵌入维度 d 的取值范围为 8 到 128;
对每个固定的 d,词汇量 m 从 5 到 150 变化,分别测试 20 个不同的值;
模型使用 Adam 优化器从零开始训练,批量大小为 16,学习率为 10^-4,训练 10 万步。
训练和评测数据通过随机采样生成。首先从大小为 m 的词汇表中均匀采样 n 个词,构成一个长度为 n 的序列。
序列长度 n 设置为 n=10m,平均每个词出现的次数固定为 10 次,一共使用了 1600 个样本进行测试。
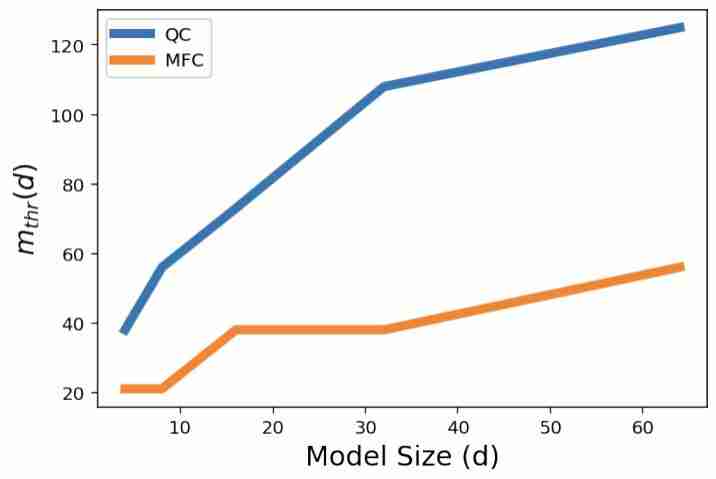
作者发现,随着词汇量的增加,模型的计数准确率呈阶梯状下降,临界点恰好出现在词汇量超过嵌入维度的时刻。
为了进一步量化模型的计数能力,作者定义了一个指标 m_thr,表示模型的计数准确率下降到 80% 时的临界词汇量。
直观地说,m_thr 反映了在给定嵌入维度下,模型可以 " 承受 " 的最大词汇量,m_thr 越大说明模型的计数能力越强。
结果显示,对于计数(QC)和找出最高频词(MFC)的任务,m_thr 都随嵌入维度 d 的增大而近似线性增长。
第二个实验则是在预训练的 Gemini 1.5 模型上开展,在这个实验中,作者更关注词汇量对计数能力的影响。
他们设计了一系列计数任务,每个任务使用不同大小的词汇表,并把每个词在序列中出现的平均次数固定。
这意味着,在实验组当中,词汇量越大,序列长度也就越长。
作为对照,作者还设置了一个 "Binary Baseline",词汇表中只有固定为两个词,但序列长度与主实验组相同。
这样一来,就可以判断出带来模型计数误差的究竟是词汇量还是序列长度。
实验结果显示,随着词汇量的增加,Gemini 1.5 在计数任务上的平均绝对误差显著上升,而 "Binary Baseline" 的误差要低得多。
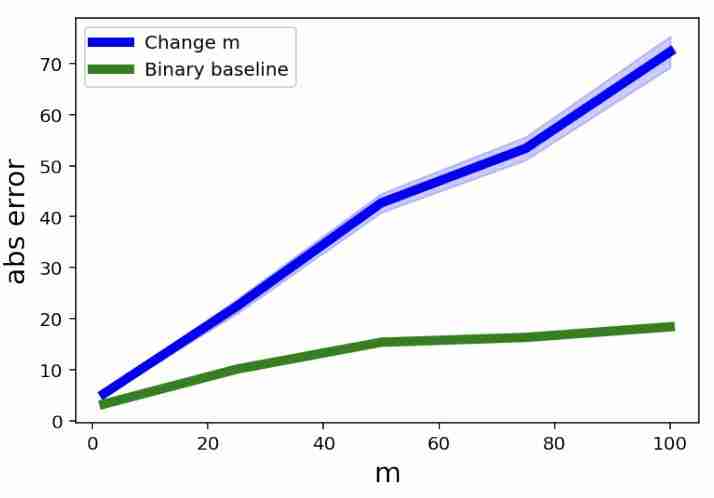
这表明,词汇量的增加,而非序列长度的增长,是导致大模型计数能力下降的主要原因。
不过作者也表示,虽然这项研究一定程度上划定了大模型计数能力的上下界,但这些界限还不够紧致,距离理想的结果还有一定差距。
同时,作者也没有探究增加 Transformer 的层数是否会改变这一结论,需要未来开发新的技术工具才能进一步验证。
论文地址:
https://arxiv.org/abs/2407.15160
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 大疆发布掌上 Vlog 无人机DJI Neo,售价1299元起
- DJI大疆今日正式发布DJINeo掌上Vlog无人机。DJINeo仅135克,是DJI迄今最轻、最小的无人机,无需遥控器,掌上起降即可轻松拍出主角大片,让你放手去飞,将美景与好友尽收画中,以多变视角向世界展现精彩自我。零门槛掌上起降,你也能飞DJINeo携带便携、操作便捷。135克超轻重量,无需遥控器,只需按下机身顶部模式按键,选好拍摄模式后,便可从掌上轻盈起飞,自动运镜完成创作,再来个掌上降落,佳作轻易到手。同时,DJINeo搭载AI智能算法,能跟随取景框中的对象,带来智能跟拍玩法,让你成为画面焦点。无
- 8分钟前 硬件资讯 智能生活 Hi科技 5G IOT 消费电子 人工智能AI 手机数码 新能源汽车 自动驾驶汽车 智能家居 电脑影音 DJINeo 0
-
 正版软件
正版软件
- 华为 nova Flip 可折叠 120 万次!折叠屏的极限在哪里?
- 8月6日,华为novaFlip与广大消费者正式见面,作为全新一代小折叠屏手机,novaFlip凭借潮美外观、鸿蒙AI趣玩、智慧体验以及业界领先的人像自拍、悬停影像玩法等,成为了一款与年轻人气质高度吻合的潮流新品。不过,要说华为novaFlip哪一点最吸引人,还是它可经受120万次折叠测试后,依旧保持功能完整的强大耐用性。华为novaFlip对于很多用户而言,花大几千买折叠屏手机,想要用得久无可厚非。当下折叠屏相较过于有了长足进步,这一点从折叠次数的变化上就能看出,此前主流折叠屏产品的折叠次数大致在20万到
- 23分钟前 华为 Nova 折叠 flip 折叠屏 华为nova 水滴铰链 0
-
 正版软件
正版软件
- 迈从G75Pro和G75的实际区别介绍
- 迈从G75Pro和G75顾名思义是同一款产品的两个版本,G75Pro和G75最大的区别在于轴体,G75的轴体为青轴与酒红轴,G75Pro轴体为白菜豆腐轴与抹茶拿铁轴,其次是电池容量的区别,G75PRO电池多4000毫安,详细区别如下。迈从G75Pro和G75的实际区别介绍迈从G75Pro键盘价格:199至249元键盘外观颜色:暮光白/清屿蓝、晶石黑/冰岛蓝、暮光白/清屿蓝/青岚白键盘轴体:白菜豆腐轴V2、抹茶拿铁轴V2键帽高度:原厂键帽工艺:双色PBT、PBT侧刻、双色PBT连接方式:Type-C有线、2
- 38分钟前 0
-
 正版软件
正版软件
- 华硕 ROG 幻影硬盘盒白色版开售:10 Gbps 速率、插针开盖设计,389 元
- 本站9月10日消息,华硕ROG幻影硬盘盒白色版现已在京东现货开售,该硬盘盒主打“传输速率达10Gbps”,到手价389元。外观方面,这款ROG幻影硬盘盒壳外壳为铝合金材质,设计灵感号称来源未来的辐射装甲概念,采用铝合金材质与激光雕刻技术,在兼具外观设计的同时将SSD产生的热量带出外壳,帮助内部SSD进行冷却。ROG幻影硬盘盒主控为ASM2362;采用USB-C3.1Gen2接口,传输速率达10Gbps;支持2230、2242、2260、2280规格SSD;采用插针开盖设计与旋钮安装、无需使用螺丝刀。本站附
- 53分钟前 华硕 rog 硬盘盒 0
-
 正版软件
正版软件
- 只有一根内存条插哪个槽
- 新组装电脑内存条插哪个位置1、电脑内存条一般安装在电脑主板的内存插槽上。位置在:使用提示:内存超过4G,一般就要换64位系统,32位系统支持最大使用4G内存,超过就会浪费。2、电脑内存条在主板上面,对台式机来说,内存条垂直主板放置。每台笔记本电脑的型号不同,内存安放位置也不一样,笔记本内存条基本上都放置在笔记本底部或者键盘下面。3、电脑主机的内存条在CPU的旁边,是主板上最长的插槽,有两个插槽的,也有四个插槽的,用哪个都可以。拔掉内存条时,一定要先将两头的白色卡扣打开,然后就可以轻松拔掉。4、打开电脑后盖
- 1小时前 07:29 0