ABBYY PDF Transformer+的后台识别过程一览
 岛市老八 发布于2020-04-27 阅读(1653)
岛市老八 发布于2020-04-27 阅读(1653)
扫一扫,手机访问
ABBYY PDF Transformer+的后台怎么识别的?ABBYY PDF Transformer+可让您从不包含文本层的PDF文档中搜索或复制文本和图片,如扫描文档和从图像文件创建的文档。这可能归功于后台运行的识别过程。本文就讲述了ABBYY PDF Transformer+的后台识别过程。
ABBYY PDF Transformer+的后台识别详解
后台识别在默认情况下运行即启用。当您打开无文本层的 PDF 文档时,它自动启动。
但是这里要知道的是,后台识别过程无法在单核处理器的计算机上运行。
后台识别过程不会改变 PDF 文档的类型,因此,如果您保存了仅图像文档并使用另一应用程序将其打开,您将无法再搜索它或复制其内容。
要使 PDF 文档可搜索,您需要对其添加文本层。
如果搜索或复制功能不能正常运行,请查看是否已正确指定文档语言。参见ABBYY PDF Transformer+改善转换结果之识别语言以获取更多信息。
您可通过在首项对话框中清除在没有文本层的光栅文档中启用复制和全文搜索复选框,随时禁用后台识别过程。

产品推荐
-

售后无忧
立即购买>- ABBYY FineReader 14 简体中文【标准版 + Win】
-
¥1058.00
office旗舰店
-

售后无忧
立即购买>- ABBYY FineReader 12 简体中文【专业版 + Mac】
-
¥899.00
office旗舰店
-

售后无忧
立即购买>- ABBYY FineReader 14 简体中文【企业版 + Win】
-
¥1858.00
office旗舰店
-
售后无忧
立即购买>- ABBYY FineReader 12 简体中文【专业版 + Win】
-
¥508.00
office旗舰店
-
 正版软件
正版软件
- 如何跳过创建账户步骤在Win10 1903安装过程中
- 有的小伙伴不想在创建账户的时候填写信息,想要跳过这个过程,那么对于这个问题小编觉得我们可以在传建一个新账户的时候选择不方便使用微软邮箱登录,然后在进行接下来一系列的操作即可。win101903安装怎么跳过创建账户一、在登录Microsoft账户这一界面,点击“创建一个新账户”。二、在注册Outlook邮箱这一界面,点击下方的“不使用Microsoft账户登录”。三、然后就会跳到本地账户创建界面,在账户这一界面输入用户名和密码(可选),点击“完成”即可使用本地账户登录完成Win10的安装。如此一来,就可以跳
- 4分钟前 跳过账户创建 0
-
 正版软件
正版软件
- edge浏览器xp能否使用详情
- 有许多怀旧的小伙伴还在使用xp系统,但是又想使用edge浏览器却又不知道xp是否可以适配而很是苦恼,下面就为大家带来了详细的介绍,一起来看看吧。edge浏览器xp能用吗:答:不能使用。浏览器所用的内核版本需要的系统支持组件而XP系统是不包含的,所以没法使用。edge浏览器的主要特色:1、Edge浏览器可以让用户在网页上手写和做标记,而且这些内容都是可以分享给朋友的。2、阅读列表可以让用户保存喜欢的文章,在方便的时候进行阅读。3、阅读模式可以为用户提供干净、无干扰的屏幕布局环境。4、内置数字助理Cortan
- 9分钟前 Edge浏览器 XP系统 详情 0
-
 正版软件
正版软件
- 完整的Windows 10系统安装指南
- 我们在使用win10操作系统的时候,如果遇到了系统故障无法正常启动电脑或者是影响正常使用的话,我们可以尝试重装操作系统。那么对于深度安装win10系统怎么安装,小编觉得我们可以先准备好自己需要的操作系统,在下载一个u启动来进行安装的操作。具体步骤就来看下小编是怎么做的吧~深度安装win10系统安装教程win10系统下载链接:1、深度技术系统win10安装方法:PE安装法(1)制作一个启动U盘,可用u启动制作软件制作启动U盘。开机进入bios界面设置U盘为第一启动顺序,或者敲击键盘相应按键进入快捷启动菜单,
- 24分钟前 教程 win 深度安装 0
-
 正版软件
正版软件
- Win10远程桌面设置步骤详解
- 在使用w10的远程桌面功能的时候。还需要去设置允许外部设备连接你的电脑,同时还要添加相关的用户才行,那么这个设置需要到哪里去进行设置呢,快来看看详细的教程吧~win10远程桌面怎么设置:1、桌面上,鼠标右键“此电脑”,然后选择属性。2、在最左边,选择“远程设置”进入。3、进入窗口中,将此两项允许都勾上,然后点击下方的“选择用户”。4、然后在弹出的窗口中点击添加,再次弹出窗口后,点击高级。5、进入高级选项后,我们点击此项“立即查找”。6、然后选择我们的用户就行了。
- 39分钟前 Win远程桌面设置 Win远程桌面教程 设置Win远程桌面 0
-
 正版软件
正版软件
- win10和win7在内存占用方面的详细比较测试
- 我们在分别使用过win7和win10系统之后,一定有想过win10比win7占内存大吗,为了让大家可以更加安心的去使用系统,下面就带来了详细的介绍一起来看看吧。win10比win7占内存大吗:答:win10相对于win7来说,内存占用要比win7稍微高出一些,但是没有明显差别。主要是因为win10系统较win7来说增加了许多新的功能,但是win10相对win7来说更加流畅。win7在兼容方面较好,因为其发布时间较久,所以更加稳定,而win10还需要一段时间的提升。官方配置要求:与Windows7持平进行W
- 54分钟前 系统性能 内存占用量 资源消耗比较 0
最新发布
-
 1
1
- KeyShot支持的文件格式一览
- 1619天前
-
 2
2
- 优动漫PAINT试用版和完整版区别介绍
- 1659天前
-
 3
3
- CDR高版本转换为低版本
- 1804天前
-
 4
4
- 优动漫导入ps图层的方法教程
- 1658天前
-
 5
5
- ZBrush雕刻衣服以及调整方法教程
- 1655天前
-
 6
6
- 修改Xshell默认存储路径的方法教程
- 1670天前
-
 7
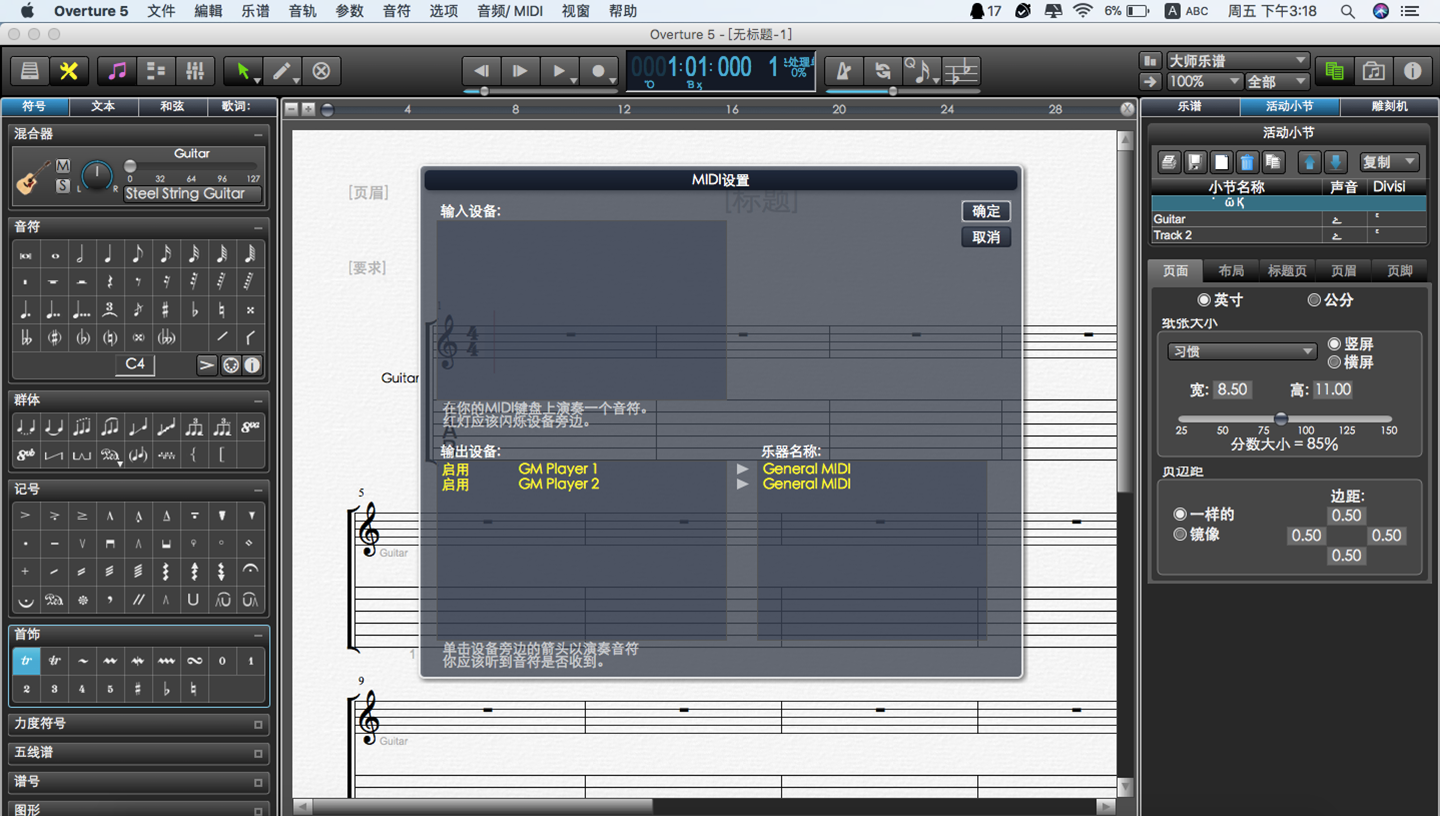
7
- Overture设置一个音轨两个声部的操作教程
- 1648天前
-
 8
8
- PhotoZoom Pro功能和系统要求简介
- 1824天前
-
 9
9
- 优动漫平行尺的调整操作方法
- 1656天前
相关推荐
热门关注
-
- ABBYY FineReader 12 简体中文
- ¥508.00-¥1008.00
-
- ABBYY FineReader 12 简体中文
- ¥899.00-¥1199.00
-
- ABBYY FineReader 14 简体中文
- ¥1058.00-¥1299.00
-
- ABBYY FineReader 14 简体中文
- ¥1858.00-¥2415.00