ABBYY PDF Transformer+图像处理的方法教程
 岛市老八 发布于2020-04-27 阅读(1349)
岛市老八 发布于2020-04-27 阅读(1349)
扫一扫,手机访问
ABBYY PDF Transformer+如何进行图像处理?ABBYY PDF Transformer+ 这款Ocr图文识别软件提供多种图像处理选项,可提高源图像的质量,便于准确地识别光学字符。我们扫描纸质文档或从图像文件创建 PDF 时,务必选择合适的图像处理选项。而在ABBYY PDF Transformer+中包含下列图像处理选项。

ABBYY PDF Transformer+图像处理的内容一览
识别文本 — 选择此选项会将文本层放在图像下方,生成的可搜索 PDF 文档看起来与原件完全相同。您将能够复制并标记 PDF 文档中的文本。
纠正失真的文本行、文档倾斜以及其他缺陷 — 选择此选项将导致程序在图像上运行多个图像增强例程。
视乎输入图像的类型,ABBYY PDF Transformer+ 将选择合适的图像增强机制,比如,歪斜纠正、梯形失真纠正或图像分辨率调整。
·图像增强可能需要一段时间。
纠正页面方向 — 选择此选项将导致程序在扫描仪上检测页面方向。
为了实现合适的识别效果,页面应有标准方向,即,水平线条和字母应向上。
拆分对开页 — 选择此选项将导致以下问题:将书籍或杂志的任何两页拆分为两个独立的图像。
当您扫描书籍时,扫描的图像将通常包含两个相反的页面。为了获得合适的识别效果,程序将图像拆分为两个,为每个书籍页面创建一个独立的 PDF 页面。 此功能对中文和日文文本不起作用。
使用混合光栅内容 (MRC) 压缩 — 选择此选项将应用 MRC 压缩算法,这将大大减小文件大小,保留图像的视觉质量。
注意:确保选择合适的文本识别语言。
产品推荐
-

售后无忧
立即购买>- ABBYY FineReader 14 简体中文【标准版 + Win】
-
¥1058.00
office旗舰店
-

售后无忧
立即购买>- ABBYY FineReader 12 简体中文【专业版 + Mac】
-
¥899.00
office旗舰店
-

售后无忧
立即购买>- ABBYY FineReader 14 简体中文【企业版 + Win】
-
¥1858.00
office旗舰店
-
售后无忧
立即购买>- ABBYY FineReader 12 简体中文【专业版 + Win】
-
¥508.00
office旗舰店
-
 正版软件
正版软件
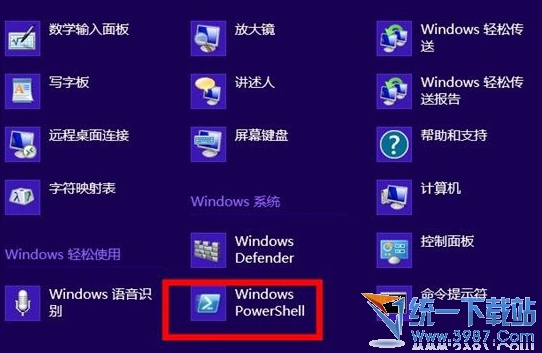
- win8磁贴无法启动的原因及解决方法
- win8磁贴打不开是怎么回事???解??1、右键开始按钮,选择“命令提示符(管理员)”;2、在2113命令提示符窗口输入命令:cd/d%LocalAppData%\Microsoft\Windows\,回车执行;3、不要关闭当前窗口,接着在任务5261栏空白处鼠标右键,选择“任4102务管理器”,找到Windows资源管理器,右键选择“结束任务”;4、这时桌面图标都消失,回到命令提示符窗口,输入delappsfolder.menu.itemdata-ms,回车执行;5、继续输入delappsfolder.
- 7分钟前 0
-
 正版软件
正版软件
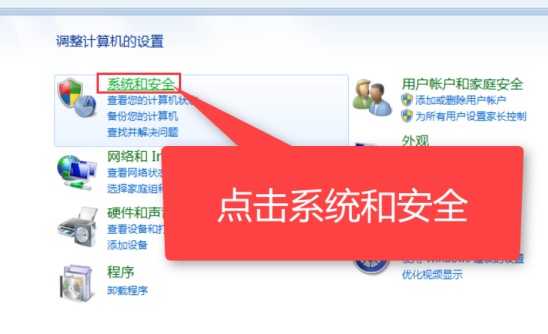
- 详细教程:如何重置Windows 7系统
- 在我们日常使用电脑时,各种误操作或者病毒导致电脑崩溃出各种问题时不可避免的,这时如果我们还能进入电脑系统的话,系统还原就是一个不错的解决方法了,他可以帮我们把电脑还原到以前最好的工作状态,免去重新装机麻烦,也会保护我们的数据不丢失。win7系统怎么还原:1、进入win7系统,打开“控制面板”,然后点击“系统和安全”。2、在系统和安全窗口中找到备份和还原,点击下面的“从备份还原文件”。3、在新窗口中点击“打开系统还原”按钮。4、选择推荐的还原的选项,然后继续“下一步”。5、系统就会开始还原了,等待就可以了。
- 22分钟前 系统还原 备份文件 恢复默认 0
-
 正版软件
正版软件
- 元素数据设置错误导致win10家庭版出错
- 现在我们的电脑使用越来越平凡了,但是也常常会遭遇一些小小的困扰。例如,有很多用户他们在打开电脑后,系统属性窗口总会不经意间跳出,"由于启动计算机时出现了页面文件配置问题"。win10家庭版设置元素数据时出现错误1、首先我们先用鼠标右键点击桌面上的我的电脑,在弹出的菜单中我们选择属性。2、随后进入属性页面以后,我们直接点击左侧的高级系统设置。3、我们在系统属性的窗口中,再次点击高级选项中的性能设置按钮。4、进入性能设置的界面以后,我们切换至高级选项,点击虚拟内存下面的更改按钮。5、我们在虚拟内存的窗口中,随
- 37分钟前 win10 设置错误 0
-
 正版软件
正版软件
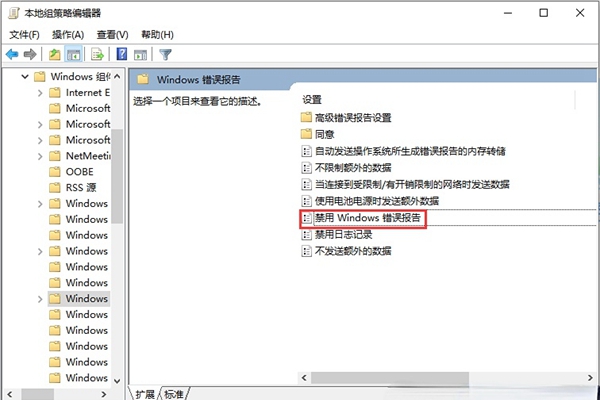
- 如何禁用win10自动更新
- win10系统有着自动更新最新版本的功能,这是非常便利的一件事情用户们不必自己来进行更新一切都会自动的完成,但是由于电脑中装载了各种程序有时候会因为win10系统的自动更新而无法使用这就让人非常的苦恼了,今天小编为大家带来的就是如何禁用Windows自动更新设置图文教程。win10关闭自动更新方法方法一:1、首先我们鼠标点击左下角的搜索窗输入“gpedit.msc"然后回车打开组策略2、顺序打开左侧菜单“计算机配置”、“管理模板”、“Windows组件”、“Windows更新”,右键点击“配置自动更新”,
- 52分钟前 win 关闭 自动更新 0
-
 正版软件
正版软件
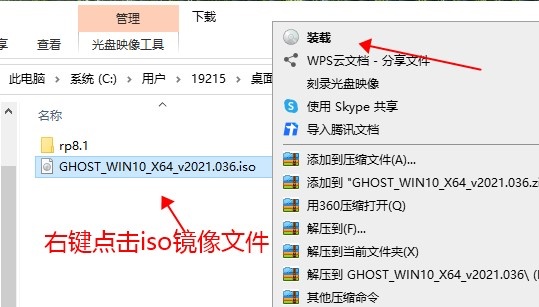
- 安装win10系统iso文件的下载和安装指南
- 我们在使用安装了win10操作系统电脑的时候,如果想要重装我们的操作系统,那么对于下载好win10系统iso文件后怎么安装这个问题,小编觉得我们可以在下载完后根据自己电脑的情况选择系统安装的方式,如果电脑无法开机可以使用U盘安装,可以开机也可以使用直接安装的方式。详细内容就来看下小编是怎么说的吧~下载好win10系统iso文件后怎么安装方法一:1、首先我们需要下载一个win10iso文件。2、如果我们是要重装系统的话,就在系统中装载该文件。3、然后允许其中的一键安装程序,如图所示。4、最后点击“立即安装到
- 1小时前 20:54 教程 安装 下载 0
最新发布
-
 1
1
- KeyShot支持的文件格式一览
- 1674天前
-
 2
2
- 优动漫PAINT试用版和完整版区别介绍
- 1714天前
-
 3
3
- CDR高版本转换为低版本
- 1859天前
-
 4
4
- 优动漫导入ps图层的方法教程
- 1713天前
-
 5
5
- ZBrush雕刻衣服以及调整方法教程
- 1710天前
-
 6
6
- 修改Xshell默认存储路径的方法教程
- 1725天前
-
 7
7
- Overture设置一个音轨两个声部的操作教程
- 1703天前
-
 8
8
- PhotoZoom Pro功能和系统要求简介
- 1879天前
-
 9
9
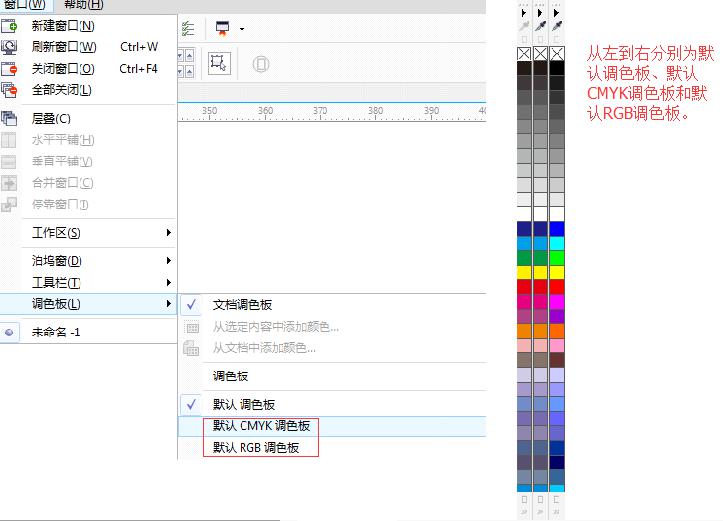
- CorelDRAW添加移动和关闭调色板操作方法
- 1752天前
相关推荐
热门关注
-
- ABBYY FineReader 12 简体中文
- ¥508.00-¥1008.00
-
- ABBYY FineReader 12 简体中文
- ¥899.00-¥1199.00
-
- ABBYY FineReader 14 简体中文
- ¥1058.00-¥1299.00
-
- ABBYY FineReader 14 简体中文
- ¥1858.00-¥2415.00