ABBYY FineReader诞生历程
 岛市老八 发布于2020-05-26 阅读(1378)
岛市老八 发布于2020-05-26 阅读(1378)
扫一扫,手机访问
把科学家的OCR原型转变为商业上可行的产品所付出的努力是巨大的,但也很激励人心:在我们将最后“点睛”的部分放FineReader1.0上时,我们已经知道在下一个版本中要做些什么了。由此引发了一个问题:既然已经有了这些伟大的想法,为什么不把它们放进首版本里呢?答案很简单:我们需要尽快发布1.0版本,因为公司的资金一直在消耗,没有1.0版本就永远不会有2.0版本。首版本(的收入)能够让我们负担下一个版本的开发费用,这是一种上上策:在它的帮助下,识别错误将会少很多,在保留原文档格式方面会做得更好,提供了无与伦比的识别精度。

对理想型OCR应用程序的远见促成了我们的开发工作,其中包括两个成为FineReader关键优势的特性:支持所有流行字体和多种语言。
实现多语言支持(有关ABBYY FineReader识别多语言文档的文章,请参考ABBYY FineReader如何识别多语言文档)很简单:很多技术性质的文档都包含多种语言单词,鉴于某些原因,当时所有可用的OCR软件只能识别一种语言,这让很多应用程序都变得不切实际,随着FineReader能够识别多语言文本,使其有了相当大的优势,支持各种语言这一特征一直是ABBYY OCR技术的长处所在。

支持所有流行字体(相关文章请参考解决ABBYY FineReader 12识别字体字符错误的问题)意味着FineReader用户在程序遇到不同字体或大小的文本时无需更改设置,今天,我们已经习惯了OCR软件处理所有字符(除了特殊的字符),但这并不是FineReader首版本问世的理由。那个时候,即便用户处理课本中的常用字体,OCR应用程序都需要用户进行训练,而且这种训练会因输入文本中无关紧要的变化而经常需要重复进行,比如,当不同的字体大小出现在文档中时,或者不同质量的扫描文件发送到程序中时。
FineReader 1.0的发布引发了相当大的兴趣,现有的OCR软件不能满足客户的需求,所以FineReader在正确的时间出现在了正确的地方。首版本我们制作了500个副本,超过100个在出售的首月卖出,按照时间标准来算,这些数字就是一部史诗:甚至Lingvo,曾被认为是成功且流行的产品,罕见地在一个月内销售出超过100个。
产品推荐
-

售后无忧
立即购买>- ABBYY FineReader 14 简体中文【标准版 + Win】
-
¥1058.00
office旗舰店
-

售后无忧
立即购买>- ABBYY FineReader 12 简体中文【专业版 + Mac】
-
¥899.00
office旗舰店
-

售后无忧
立即购买>- ABBYY FineReader 14 简体中文【企业版 + Win】
-
¥1858.00
office旗舰店
-
售后无忧
立即购买>- ABBYY FineReader 12 简体中文【专业版 + Win】
-
¥508.00
office旗舰店
-
 正版软件
正版软件
- 美国如何打击加密货币逃税?一文梳理Oyster Protocol与Bruno Block逃税案
- 2018年10月,加密平台OysterProtocol遭遇了一场严重的危机,其创始人BrunoBlock(真实名字AmirBrunoElmaani)利用智能合约中的漏洞,私自铸造了大量的新OysterPearl(PRL)代币,并在市场上抛售,导致PRL代币价格暴跌。Elmaani随后被指控逃税和欺诈,并于今年10月31日被判处四年监禁。本文将介绍BrunoBlock涉嫌欺诈和逃税案件的案情及背景,并探讨美国政府对其被控逃税罪的法律依据。同时,文章还将分析美国政府和税务局(IRS)对加密货币发行的监管和合规
- 8分钟前 加密货币 美国 0
-
 正版软件
正版软件
- 顺丰旗下丰翼科技推出两款无人机物流产品:“同城送”12 元,“跨城急送”40 元
- 顺丰旗下丰翼科技最近宣布推出两款新的无人机物流产品。在推广期间,“同城即时送”的价格为12元,而“跨城急送”的价格为40元。这意味着顾客可以享受更快捷、便宜的物流服务。据介绍,同城即时送是丰翼无人机推出的面向“同城范围2小时达”的需求,通过“即时响应+无人机运输+上门送达”的运输方式,提供同城高时效运输服务。现支持深圳宝安区、光明区、龙华区范围内互寄,服务范围还在不断拓展中。跨城急送是面向“跨城跨海服务范围4小时达”的需求,通过“即时响应+无人机运输+上门送达”的运输方式,提供高时效城市之间的配送服务。现
- 23分钟前 无人机 顺丰科技 0
-
 正版软件
正版软件
- 一文了解ETHFI币还能买吗
- 当前币安上线的新项目Ether.fi引起了投资者的关注,Ether.fi是以太坊全新的质押协议,本次挖矿采用FDUSD和BNB作为工具,其产出的代币名为ETHFI,它代表着以太坊生态中一种全新的权益证明机制,是社区用于治理协议的关键方面。ETHFI币价格今日行情$6.23≈¥44.76ETHFI是什么币种?Ether.Fi是一个基于太坊上全新的基础设施型质押协议。它允许参与者在代理质押时保留对其密钥的控制,并会自动与Eigenlayer进行再抵押以提高安全性和收益。此外,Eigenla
- 38分钟前 虚拟货币 区块链 比特币 ETHFI币 0
-
 正版软件
正版软件
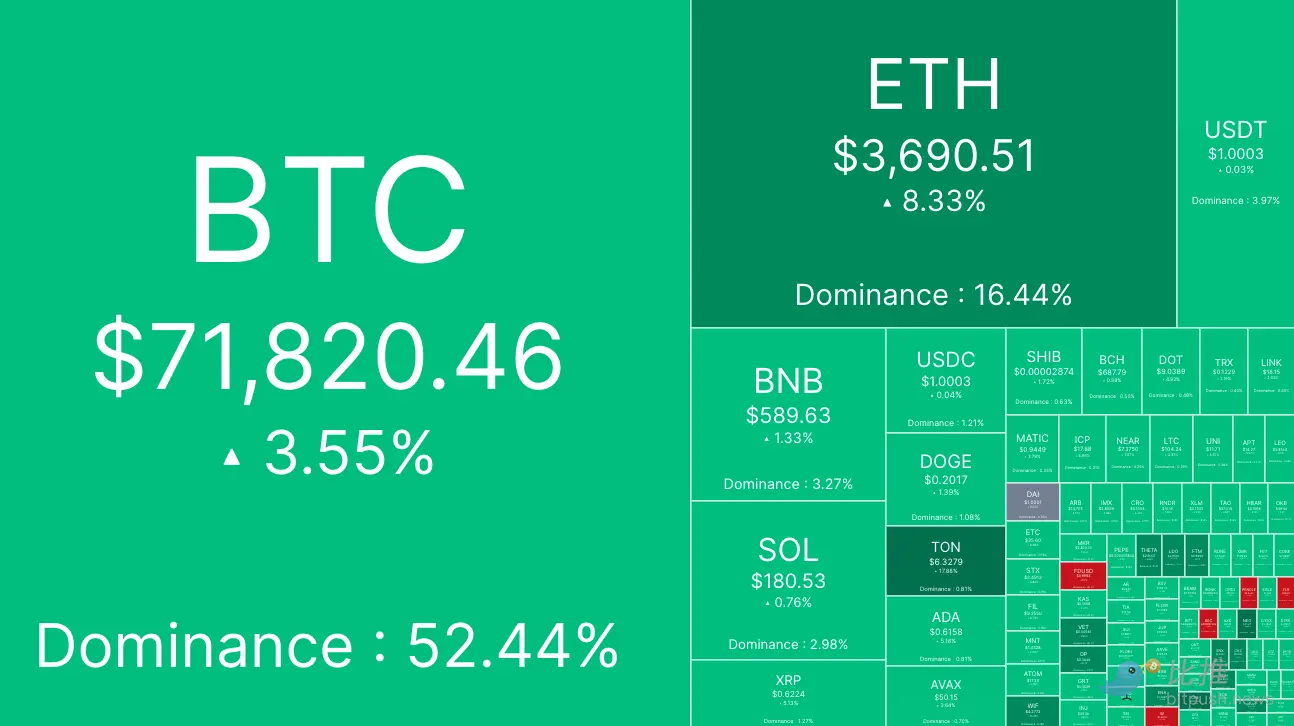
- 牛市补“弹药”进行时,两大稳定币 30 天内增发 100 亿美元
- 作者:MaryLiu,比推BitpushNews随着减半临近,比特币本周开局强劲,在周一早盘交易中飙升至72,000美元以上,距离历史高点73,750美元不到3%。市场数据显示,在周末交易价格接近69,400美元后,比特币多头在周一凌晨开始走高,突破71,000美元的阻力位,在美国东部时间上午8点后不久触及72,780美元的高点。截至发稿时,比特币交易价格为71,845美元,24小时涨幅3.5%。周一上涨的其他代币包括以太坊(上涨8%)、meme币Dogwifhat(上涨18%)和Pepe(上涨10%)。
- 53分钟前 0
-
 正版软件
正版软件
- 以太坊是什么时候开始的 价格是多少
- 以太坊创立于2015年7月30日,初始价格不明确,但预售期间以比特币出售时的价格估计约为:0.311BTC/ETH;0.14USD/ETH。
- 1小时前 21:10 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1866天前
-
 2
2
- Overture设置踏板标记的方法
- 1703天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1693天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1891天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1857天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1853天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1868天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1890天前
-
 9
9
相关推荐
热门关注
-
- ABBYY FineReader 12 简体中文
- ¥508.00-¥1008.00
-
- ABBYY FineReader 12 简体中文
- ¥899.00-¥1199.00
-
- ABBYY FineReader 14 简体中文
- ¥1058.00-¥1299.00
-
- ABBYY FineReader 14 简体中文
- ¥1858.00-¥2415.00