OCR文字识别对PDF文档处理的重要性
 Ari 发布于2020-05-06 阅读(1902)
Ari 发布于2020-05-06 阅读(1902)
扫一扫,手机访问
OCR文字识别为何对PDF文档处理那么重要?你曾遇到过PDF难题吗?比如,无法选择文本进行复制,或者搜索PDF文档中已有的单词时,却搜索不到任何结果,原因很简单,只要有正确的工具,问题就能轻松解决。下面跟着正软小编来看看吧。
OCR文字识别对PDF文档处理的重要性
为什么PDF文档表现有所不同?
PDF文档根据文件创建的方式,可分为三种不同的类型,文件最初的创建方式规定了PDF内容(文本、图像、表格)能否访问,或是否“锁定”在页面图像中。
想要理解PDF的结构,应该按照图层来理解。上面一层只是一张图片,如果你想访问文本,则需要有第二图层,即文本层,位于图片层下面,被隐藏了。
“真正”或数字创建的PDF文档
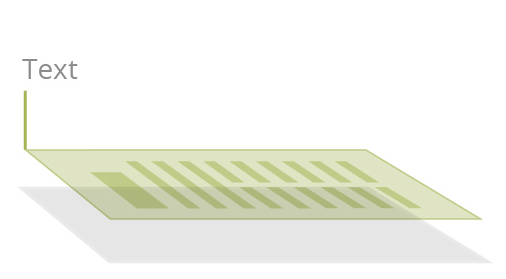
使用软件Microsoft Word、Excel,或者通过软件应用程序(虚拟打印机)中的“打印”功能创建,由文本和图像组成。可搜索,内容可访问,以便注释和重复使用。
“仅图像”或扫描的PDF文档
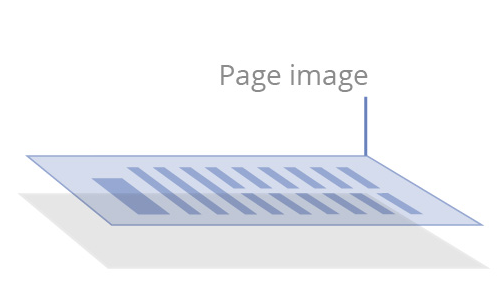
由一体化设备和办公室扫描仪上的扫描纸质文档创建,或者转换jpg或tiff图像为PDF时创建。
仅包含扫描的或者拍摄的页面图像,底下不带有文本层,内容“锁定”在快照图像中。不可进行搜索,内容不可访问。
可搜索的扫描PDF文档
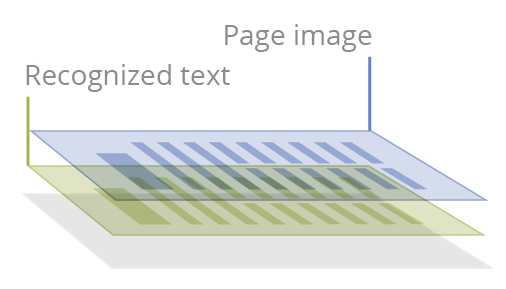
文本层被添加到图像层,通常放在下面,可进行搜索,内容可访问,可进行注释和重复使用。可能会出现一些限制,比如图片元素和图像。
什么是OCR?它和处理PDF文档有何关联?
很多扫描仪都可以创建PDF文档,但也仅限于创建图像或文档快照,不过就是一堆黑白或彩色的点,称为光栅图像,无其他数据。要想从扫描文档或“仅图像”PDF文档中提取并利用数据,需要OCR文字识别软件,比如ABBYY FineReader,或者PDF工具,如ABBYY PDF Transformer+。
光学字符识别或者文本识别可以解锁“困”在扫描/拍摄的文档图像上的信息,OCR软件可以通过翻译字符图像“读取”文档里的内容,让转换文档内容和布局为可搜索和可编辑的格式成为可能。
OCR对你处理PDF的日常工作有何影响呢?
现在你知道了:每次想要选取PDF文档里的内容时都会失败,要么就是无法搜索文档里的关键词,几乎就是在处理扫描的“仅图像”PDF文档。
有了OCR,使用ABBYY FineReader,就可以将扫描的“仅图像”PDF文档转换为包含可选择和可搜索文本的PDF文档,实现轻松管理、复制和索引内容,以及全文本搜索。
处理PDF文档变得更加简单和更有效率
•可以处理扫描的纸质文档和“仅图像”PDF文档,就跟处理数字创建的PDF文档一样;
•可以更加快速地从文档中找到并访问信息,再也不用在纸堆里翻箱倒海了;
•可以重复使用文档里的信息,无需手动重新输入;
•和同时协作的时候,可以选择文本进行强调、评论和添加注释;
•可以使用“搜索和编辑”功能编辑文档中出现的机密信息。
产品推荐
-

售后无忧
立即购买>- ABBYY FineReader 14 简体中文【标准版 + Win】
-
¥1058.00
office旗舰店
-

售后无忧
立即购买>- ABBYY FineReader 12 简体中文【专业版 + Mac】
-
¥899.00
office旗舰店
-

售后无忧
立即购买>- ABBYY FineReader 14 简体中文【企业版 + Win】
-
¥1858.00
office旗舰店
-
售后无忧
立即购买>- ABBYY FineReader 12 简体中文【专业版 + Win】
-
¥508.00
office旗舰店
-
 正版软件
正版软件
- 打印机无法完成打印任务
- 很多小伙伴打印文档的时候,文档发送到打印机后,打印机没有动静,查看到打印机还是亮着灯,但打印机竟然一些反应都没有,电脑上也没有像以前一个文档发送成功或开始打印等等一些类似的提示了。这就表示打印机脱机不工作了。点击有脚下图标可以看见打印机状态,该怎么解决呢?下面一起来看看吧。打印机发送任务不打印的解决方法1、首先打开电脑的“控制面板”。2、点击“硬件与声音”选项,选择最上方的“设备与打印机”。3、右键选择一个打印机,点击“属性”选项。4、查看输出端口是否勾选,然后点击"高级"选项,查看是否“设置使用时间”。
- 9分钟前 打印机 打印任务 不打印 0
-
 正版软件
正版软件
- 无法关闭Win10飞行模式的解决方法
- 我们有的时候会发现系统莫名其妙开启了飞行模式,但是自己无法关闭,结果就没法上网了。这时候我们可以在服务中启动相关服务,然后重启电脑就可以了,下面就一起来看一下具体的操作方法吧。win10关闭飞行模式点不动解决方法1、首先使用快捷键“win+r”打开运行。2、输入“services.msc”,按下“确定”3、然后找到“windowseventlog”,双击打开4、将启动类型设置为“自动”5、最后点击“确定”并重启电脑就可以关闭飞行模式了。
- 24分钟前 性能问题 驱动更新 Win 关闭飞行模式 解决方法 快捷键功能 0
-
 正版软件
正版软件
- 介绍如何快速更新win10系统的详细步骤
- win10系统给很多用户带来了便利,但是有些钉子户不愿意升级因为他们不清楚更新win10麻不麻烦,今天就给你们带来了更新win10系统是否麻烦详情介绍,快来看看吧。更新win10系统麻烦吗:答:更新win10系统不麻烦。只需要根据提示进行点击操作即可,没有任何专业难题。更新win10系统方法:1、首先直接进入微软官网升级,无需等待推送即可升级。进入官网>>2、进入官网进行购买升级是最安全也是成功率最高的。3、在更新的时候先将第三方杀毒软件和管理软件进行关闭或者删除,随后再升级。4、点击“立即升
- 39分钟前 驱动程序 被广泛用于个人电脑 以提升系统的稳定性 0
-
 正版软件
正版软件
- 如何创建适合个人需求的CAD模板
- 一、对于如何新建适合个人需求的CAD模板,下面提供详细回答:在CAD中,创建适合个人需求的模板可以有效提高工作效率,以下是具体的步骤:1.打开CAD软件:启动CAD软件,进入绘图界面。2.绘制基础图层:根据个人或项目的需求,绘制基础图层。可以包括标准的图框、标题栏、公司标志等。3.设置图层属性:对绘制的基础图层进行图层属性设置,包括线型、颜色、线宽等。确保符合自己或公司的绘图标准。4.添加标注和文字样式:添加标准的文字样式和标注样式。设置文字的字体、大小、颜色等属性,确保一致性。5.保存为模板文件:选择“
- 54分钟前 0
-
 正版软件
正版软件
- 本地硬盘怎么安装原版win10系统
- 如果我们电脑使用的是win10操作系统,想要对自己的电脑进行系统重装的话,如果是使用本地硬盘安装原版win10系统的话,相信还有很多小伙伴不知道应该怎么进行操作。那么小编觉得其实我们可以在自己的硬盘中进行直接安装。也可以使用移动硬盘进行安装即可。本地硬盘怎么安装原版win10系统1、首先下载系统之后将其进行解压。2、然后打开文件夹中的“setup”程序。3、之后点击下一步。4、接受安装声明和许可条款。5、等到准备就绪了就可以开始安装了。6、最后就可以进行安装了,好了之后会重启几次不用担心,等待它自己好就行
- 1小时前 21:40 win 硬盘 安装 0
最新发布
-
 1
1
- KeyShot支持的文件格式一览
- 1684天前
-
 2
2
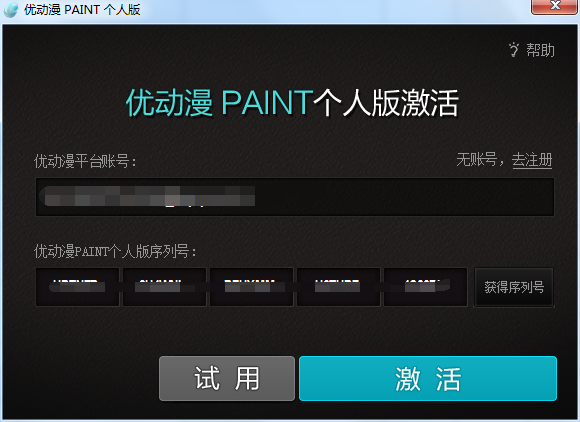
- 优动漫PAINT试用版和完整版区别介绍
- 1724天前
-
 3
3
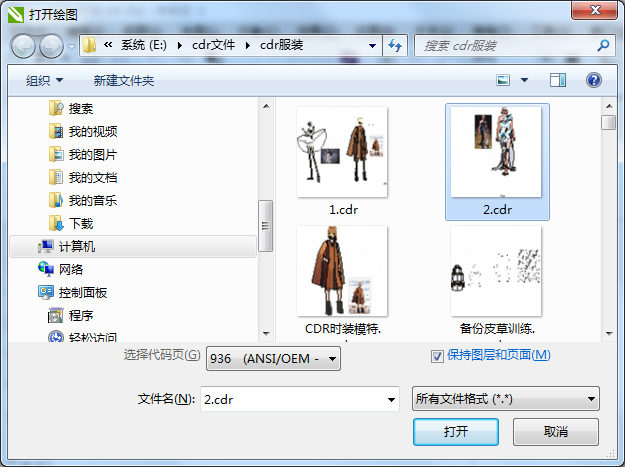
- CDR高版本转换为低版本
- 1869天前
-
 4
4
- 优动漫导入ps图层的方法教程
- 1724天前
-
 5
5
- ZBrush雕刻衣服以及调整方法教程
- 1720天前
-
 6
6
- 修改Xshell默认存储路径的方法教程
- 1735天前
-
 7
7
- Overture设置一个音轨两个声部的操作教程
- 1713天前
-
 8
8
- PhotoZoom Pro功能和系统要求简介
- 1889天前
-
 9
9
- CorelDRAW添加移动和关闭调色板操作方法
- 1762天前
相关推荐
热门关注
-

- ABBYY FineReader 12 简体中文
- ¥508.00-¥1008.00
-
- ABBYY FineReader 12 简体中文
- ¥899.00-¥1199.00
-

- ABBYY FineReader 14 简体中文
- ¥1058.00-¥1299.00
-

- ABBYY FineReader 14 简体中文
- ¥1858.00-¥2415.00