微软最新研究探索LLM修剪和知识恢复的LoRAShear技术
 发布于2023-11-13 阅读(0)
发布于2023-11-13 阅读(0)
扫一扫,手机访问
LoRAShear是微软为优化语言模型模型(llm)和保存知识而开发的一种新方法。它可以进行结构性修剪,减少计算需求并提高效率。

LHSPG技术(Lora Half-Space Projected Gradient)支持渐进式结构化剪枝和动态知识恢复。可以通过依赖图分析和稀疏度优化应用于各种LLM
LoRAPrune将LoRA与迭代结构化修剪相结合,以实现参数的高效微调。即使在LLAMA v1上进行了大量修剪,其性能仍能保持相当水平
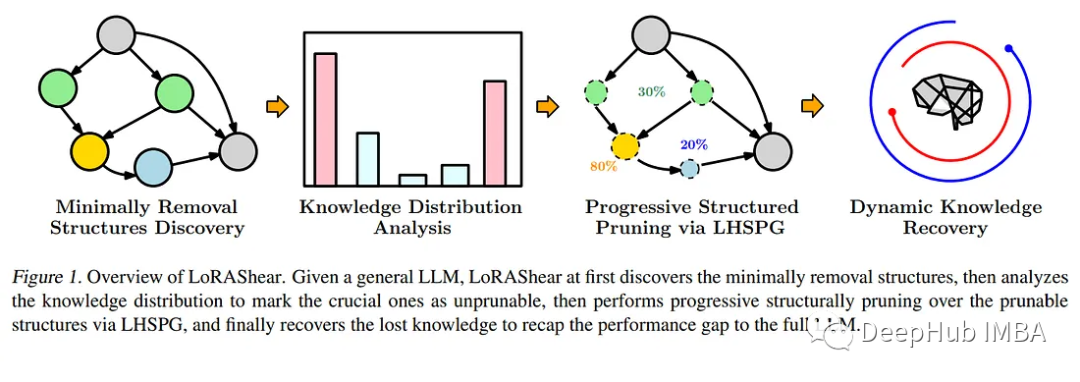
在不断发展的人工智能领域,语言模型模型(llm)已经成为处理大量文本数据、快速检索相关信息和增强知识可访问性的关键工具。它们的深远影响跨越了各个领域,从增强搜索引擎和问答系统到启用数据分析,研究人员、专业人员和知识寻求者都从中获益。
目前最大的问题是,LLM需要不断更新知识以满足信息的动态性要求。一般情况下,开发人员会使用特定于领域的数据对预训练模型进行微调,以保持其最新状态,并向模型灌输最新的见解。定期更新对于组织和研究人员来说是至关重要的,以确保LLM与不断变化的信息景观保持同步。然而,微调的成本很高且周期长
为了应对这一迫切需要,微软的研究人员推出了一种开创性的方法——LoRAShear。这种创新的方法不仅简化了llm,而且促进了结构知识的恢复。结构修剪的核心是去除或减少神经网络架构中的特定组件,优化效率、紧凑性和计算需求。
微软的LoRAShear使用了LHSPG技术,以支持渐进式结构化修剪。这种方法可以在LoRA模块之间无缝传递知识,并且还集成了动态知识恢复阶段。微调过程类似于预训练和指导微调,以确保LLM保持更新和相关性
重新写成:利用依赖图分析,LoRAShear可以扩展到一般的llm,尤其是在LoRA模块的支持范围内。该方法使用原始LLM和LoRA模块创建依赖关系图,并引入了一种结构化稀疏性优化算法,该算法利用LoRA模块的信息来增强权重更新过程中的知识保存
在论文中,还提到了一种称为LoRAPrune的集成技术,它将LoRA与迭代结构化修剪相结合,以实现参数的高效微调和直接硬件加速。这种节省内存的方法完全依赖于LoRA的权重和梯度来进行修剪标准。具体的过程包括构建一个跟踪图,确定需要压缩的节点组,划分可训练的变量,并最终将它们返回给LLM
论文通过在开源LLAMAv1上的实现,证明了LoRAShear的有效性。值得注意的是,修剪了20%的LLAMAv1只有1%的性能损失,而修剪了50%的模型在评估基准上保留了82%的性能。
LoRAShear代表了人工智能领域的重大进步。它不仅简化了LLM的使用方式,使其更有效率,而且确保了关键知识的保存。它可以使人工智能驱动的应用程序能够在优化计算资源的同时,与不断发展的信息环境保持同步。随着组织越来越依赖人工智能进行数据处理和知识检索,像LoRAShear这样的解决方案将在市场上发挥关键作用,提供效率和知识弹性。
论文地址:https://arxiv.org/abs/2310.18356
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 解析决策树模型及其与过拟合问题的关系
- 决策树是一种监督机器学习模型,利用带有标记的输入和目标数据进行训练。它通过树状结构表示决策过程,根据前几组标签/节点的回答来进行决策。决策树的优点在于它模仿人类思维的逻辑流程,使结果和过程更易于理解和解释。与线性模型不同,决策树能够处理变量之间的非线性关系。主要用于解决分类问题,通过模型对对象进行分类或分类。此外,在机器学习中,决策树也可用于解决回归问题。决策树的结构决策树通过递归分区构建,树的根位于顶部。根节点包含所有训练数据。从根节点开始,每个节点可以分裂为左右子节点。叶节点是没有进一步分裂的末端节点
- 4分钟前 人工智能 机器学习 0
-
 正版软件
正版软件
- 自监督学习框架与监督学习、无监督学习之间的关联
- 自监督学习(SSL)是一种无需人工输入数据标记的监督学习形式。它通过独立分析数据、标记和分类信息的模型来获得结果,而无需任何人工干预。这种方法可以减少人工标注的工作量,提高训练效率,并且在大规模数据集上表现出色。SSL是一种有前景的学习方法,可以在各种领域中应用,如计算机视觉和自然语言处理。自监督学习是一种利用未标记数据来生成监督信号的无监督学习方式。简单来说,它通过生成高置信度的数据标签来训练模型,然后在下一次迭代中使用这些标签。在每次迭代中,基于数据标签的基本事实都会发生变化。这种方法可以有效地利用未
- 19分钟前 机器学习 0
-
 正版软件
正版软件
- 即将上市的三星Galaxy Ring指环:AI健康监测成突出特点
- 三星在今日举办的GalaxyS24系列发布会上,向全球消费者展示了他们的最新智能穿戴产品——GalaxyRing智能指环。这款创新产品的亮相为整个科技盛宴增添了一抹亮色。在发布会即将结束之际,三星通过一段精彩的预告片向公众展示了GalaxyRing的迷人魅力。这款智能指环的设计独特,它像一枚时尚的戒指,轻松佩戴在手指上。指环内侧集成了多个先进传感器,结合AI技术,为用户提供全方位的健康追踪服务。然而,预告片并未透露GalaxyRing的售价和上市时间等更多细节。用户期待能尽快了解这款智能指环的详细信息,以
- 34分钟前 三星 0
-
 正版软件
正版软件
- 华硕灵耀14 2024亮相:搭载首款酷睿Ultra的超轻薄本体验
- 华硕灵耀系列轻薄本在市场上以其独特的个性脱颖而出,包括时尚的外观、轻薄的机身、出色的续航等特性吸引了大众的广泛关注。2023年12月15日,英特尔重磅推出了全新的酷睿Ultra处理器,Intel4工艺、3DFoveros封装技术、人工智能NPU、锐炫核显……一系列全新的特性激发出大众对酷睿Ultra处理器的强烈期待。紧跟英特尔脚步,华硕在第一时间推出了首发酷睿Ultra处理器的AI超轻薄本——华硕灵耀142024,那么这款搭载全新处理器的轻薄本有着怎样的表现呢?产品参数操作系统:Windows11Home
- 49分钟前 0
-
 正版软件
正版软件
- 机器学习的自动化(AutoML)
- 自动机器学习(AutoML)是机器学习领域的变革者。它能够自动选择和优化算法,让训练机器学习模型的过程更加简单高效。即使没有机器学习经验,借助AutoML,也能轻松训练出性能优秀的模型。AutoML提供了一种可解释的AI方法,以增强模型的可解释性。这样,数据科学家能够深入了解模型的预测过程。特别是在医疗保健、金融和自治系统领域,这非常有用。它能够帮助识别数据中的偏差,并防止错误的预测。AutoML利用机器学习来解决现实世界的问题,包括算法选择、超参数优化和特征工程等任务。以下是一些常用的方法:神经架构搜索
- 1小时前 13:35 机器学习 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1800天前
-
 2
2
- Overture设置踏板标记的方法
- 1637天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1627天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1825天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1791天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1787天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1802天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1823天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00