千亿级超大规模向量数据库正加速AI进化
 发布于2023-11-24 阅读(0)
发布于2023-11-24 阅读(0)
扫一扫,手机访问
在大型模型展开“诸神之战”时,出现了一个致命的问题,让那些尝试的用户无法忍受。很多大型模型都存在一个普遍的问题,即“一本正经地胡说八道”,这就是我们常说的“AI幻觉”。那么,如何让大型模型变得更准确、更聪明,而不是胡言乱语呢?除了模型框架、数据和算法之外,还有一个关键的应用,那就是向量数据库!

数据中枢背后
关于向量数据库与大模型的关系以及其重要性,有多种不同的解读。一个比较形象的说法是,如果将大模型比喻为一个容易遗忘的大脑,那么向量数据库就相当于其中的“海马体”,主要负责存储和定向记忆等功能。从解剖学的角度来看,如果将一个人的海马区切除,该人将失去长时记忆的能力,并无法感知声音、光线、味觉等信息
说白了,大模型之所以有幻觉,根本原因是大模型的向量数据库不够强大,导致大模型只能从既定的数据中查找答案,推理的结果常常泛泛而谈,或者胡诌,极度影响体验。所以,大模型聪明与否,要看向量数据库是否给力,这也是腾讯云为什么发力向量数据库,构建AGI“数据中枢”的根本原因。
有人可能会想:我在数据中台层面提升数据调度能力,传统关系型数据库也可以支持呀?但现实情况是,企业在搭建和使用大模型时,首先需要把海量数据安全、高效地接入大模型,在诸多复杂数据中,适合关系型数据库的结构化数据仅有20%,其余80%都是文本、图像、视频、音频等非结构化的数据。而向量数据库可以把复杂的非结构化数据处理成多维逻辑的坐标值,与大模型进行连接,数据处理的效率要比传统数据库提升10倍。
同时,向量数据库也可以作为外部知识库给大模型输送最新、最准确、最全面的信息,高效应对实时问答,并且让大模型拥有长期记忆,避免聊天时的断片。如此一来,向量数据库与大模型是最 佳搭档的说法,就比较容易理解了。
专业向量数据库VS传统数据库向量插件
事实上,把向量数据库作为大模型背后的主要赛道,领先企业已经走在创新征程中了。初步统计,致力于向量数据库的厂商已经有50多家。而从具体的技术路线来看,主要分两大类:一类是专业的向量原生数据库,从诞生开始就为向量设计,可以做向量数据结构的存储、解锁、查询;另一类是传统数据库上加了一个向量插件,使其能够支持向量的检索。
对比分析,两种方式各有应用场景,比如:企业刚开始时候,数据量不大,不想引入新数据库,那就可以选择传统数据库+向量插件的方式。但如果企业数据量较大,想构建更聪明的大模型,对性能和未来发展有更高要求,那选择像腾讯云这样专业的向量数据库产品,显然会更适合。
在向量数据库的应用角度来看,还存在着更多的潜力。目前,许多企业正在使用向量数据库来解决大型模型的虚幻感以及知识增强等方面的弱点。然而,未来的发展不仅局限于这些能力,还可以在图像查询方面有更出色的表现。例如,可以对手机中的照片进行查询,类似于图像搜索引擎,这实际上也是一种向量查询
专业向量数据库并不能取代传统数据库,尤其是在大型场景下。传统关系型数据库和向量数据库可以相互协同发展、相互补充。向量数据库通过向量化数据来满足传统关系型数据库难以处理的大规模数据、低时延高并发检索、模糊匹配等领域的需求。向量数据库只支持新的数据类型,并不存储原始数据,而传统数据库支持数值、字符串、时间等传统数据类型。传统数据库支持的数据规模相对较小,最多只能支撑1亿条数据,而向量数据库可以支撑大规模的数据,底线是千亿条数据。传统数据库的查询方式为精确查找,要么符合条件,要么不符合;而向量数据库则是近似查找,查询结构和输入条件要尽可能相似,对计算能力要求也更高。上层应用程序可以使用统一的API方式,更适合于大规模人工智能应用程序的部署和使用
智能进化
大模型并不是从零开始,向量数据库也不是。那么,向量数据库到底是怎么发展起来的?腾讯云数据库团队曾经有过深刻的思考!
腾讯云数据库副总经理罗云认为,大模型的本质不应该是一个无限大的存储体,而是一个带有智算能力的平台,将之前只有编程语言才能触达的底层计算能力,用自然语言去调度,这应该是一个令人兴奋的奇点。兴奋之余再次冷静思考,人类在完成数字化改造过程中,除了计算平台,还有其他的可能性吗?到底什么才是AGI时代的技术内核?总结发现,底层数据的智能化流通才是撬动数据中枢的金钥匙!
如今,当企业有了通用的智能计算能力后,底层的数据可以快速流动起来,我们可以把文件存在文件系统,我们可以调用关系型数据库里面的表格数据、非关系型里面的KV数据,所有数据都可以通过智能化的方式流通和联动。但要想让数据和人类对话,光有计算平台还不够,还要有一个智能数据平台,可以用自然语言把数据取出来,然后交给大模型去计算,而要达成这样的目的,向量数据库就成为一个重要的枢纽。
既然向量数据库如此重要,我们应该如何通过智能化升级,在传统数据库经验基础上与数据平台对话呢?这正是腾讯云数据库的特长!在腾讯云向量数据库技术峰会上,腾讯云宣布与第三方机构合作完成了一项测试,证明腾讯云向量数据库可以支持千亿级别规模的数据,并且显著提高了每秒查询率,达到了500万的峰值能力
目前,腾讯云向量数据库已经有大量用户,包括百川智能、好未来、销售易等公司。最近,他们和百川一起做了个 AGI 启航计划,赠送向量数据库实例及 Baichuan2 大模型 400 万的 Tokens。
通过Embedding、向量索引、分布式系统架构、硬件加速等核心技术,腾讯云向量数据库可以有效解决文本、图像、视频,包括生物制药、风控、音频、多模态等广阔场景的特定问题。比如:利用Embedding技术将高维度的数据(例如文字、 图片、 音频)映射到低维度空间 ,即把图片、声音和文字转化为向量来表示,将这些向量存储起来就构成向量数据库,实现Embedding过程的方法包括神经网络、 LSH(局部敏感哈希算法)等。
腾讯从2019年开始致力于提升向量数据库的能力,引领企业业务迈向AGI时代。至今,腾讯云已经为40多家内部客户提供服务,每天支持的向量数据检索次数超过了1600亿次。同时,腾讯云还为1000家外部客户提供服务,增长速度可谓惊人
放眼未来,AGI正在加速进化,这中间有惊喜,也有挑战。腾讯云数据库将一如既往,不断探索,引领创新。“Road to AGI,Together on the Path”——这句话完美地概括了腾讯云技术团队的当前状态!
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 哀悼!55岁商汤科技创始人汤晓鸥突然离世,他撑起中国计算机视觉研究半壁江山
- 沉痛悼念!商汤科技创始人汤晓鸥教授于2023年12月15日晚上11点45分因病不治去世,享年55岁中国人工智能界再次失去了一位领军人物,这让人感到天妒英才。在两年前,孙剑博士意外辞世后,如今又有一位领军人物离世计算机视觉的开拓者汤晓鸥教授被毫不夸张地称为中国计算机视觉领域的先驱和探索者2014年6月,汤晓鸥实验室发布的DeepID算法,开启了人脸识别技术广泛应用的时代,自此我国在该领域迅速取得世界领先地位汤教授提出的人脸识别技术,是世界上第一个超过人眼识别能力的计算机算法。他还是自然语言处理领域的重要研究
- 30分钟前 人工智能 科技 0
-
 正版软件
正版软件
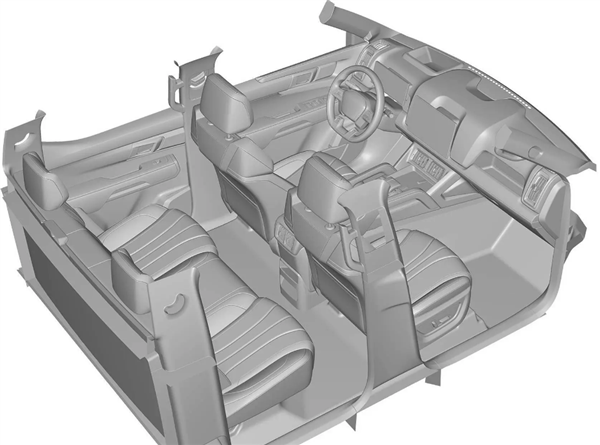
- 比亚迪皮卡内饰专利图曝光,设计独具特色
- 12月17日消息,近日,比亚迪皮卡内饰的专利图曝光,这款越野皮卡内部设计风格鲜明,充满变化。比亚迪皮卡的内饰设计似乎受到了方程豹的灵感,呈现出独特的风格。车内配置非常丰富,包括全液晶仪表、大型悬浮式中控屏幕和HUD抬头显示系统。中控屏幕采用了凸起的设计,而副驾驶座前方的储物格还进一步增加了车内的储物空间比亚迪皮卡在中央扶手位置采用了方程豹式的档把和机械按键设计,这不仅增加了内饰的豪华感,还使车内功能更加方便实用此前已有比亚迪皮卡车型的内饰谍照曝光,与此次专利图相似度很高。另外,该车空调出风口也采用了竖排设
- 8小时前 10:20 比亚迪 内饰设计 皮卡 0
-
 正版软件
正版软件
- 魅族21银河定制版亮相,炫彩后盖设计引领时尚潮流
- 12月17日消息,近日,吉利汽车举办了盛大的用户大会,地点选在了广东。会上,除了备受瞩目的银河E8预售活动,魅族21吉利银河定制版手机也首次向公众展示,吸引了大量关注。这次大会不仅是吉利汽车的展示平台,也成为了科技与汽车融合的一个重要示例。在这次大会上,魅族21吉利银河定制版手机的亮相特别引人注目。通过公布的照片可以看出,这款手机采用了独特的拼接设计风格,右侧显著的是吉利银河的标志性色块,而在右下角则巧妙地融合了魅族和吉利银河的双Logo。这种设计不仅展现了吉利银河的品牌特色,也彰显了魅族在设计上的创新和
- 昨天 10-16 10:15 魅族 定制版 拼色设计 0
-
 正版软件
正版软件
- 联想ThinkPad X1 2024 二合一笔记本明年三月上市
- 根据联想海外网站的最新消息,2024年3月将会有ThinkPadX1二合一Gen9笔记本盛大上市。这款备受期待的二合一笔记本的起售价预计为2639美元,约合人民币18790元左右在硬件参数方面,联想ThinkPadX12024二合一笔记本将配备强大的酷睿Ultra系列处理器,并提供高达64GBLPDDR5X内存和2TBSSD的可选配置。它的屏幕尺寸为14英寸,用户还可以选择升级到2.8K分辨率、支持120Hz刷新率的OLED触控屏。这款笔记本的设计也非常出色,它的厚度仅为15.49毫米,重量仅有1.32千
- 前天 10-15 10:10 0
-
 正版软件
正版软件
- 极狐阿尔法 T5 12 月 27 日正式上市,交付即刻
- 12月17日消息,据最新消息,极狐汽车即将推出其最新款电动汽车——极狐阿尔法T5。这款备受期待的新车将于12月27日正式登陆市场,并计划在上市当天开始交付。极狐阿尔法T5自11月30日起已开启预售,预售价格区间设置在15.58万至20.38万元之间。这款车型采用了先进的800V高压电力系统,官方宣称其充电速度极快,仅需10分钟即可充电260公里。此外,该车型提供两种续航里程选项,分别为520公里和660公里,满足不同用户的需求。T5车型的车身尺寸为4690mm长、1936mm宽和1650mm高,轴距为28
- 3天前 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1772天前
-
 2
2
- Overture设置踏板标记的方法
- 1609天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1599天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1797天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1763天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1759天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1774天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1795天前
-
 9
9
相关推荐
- 哀悼!55岁商汤科技创始人汤晓鸥突然离世,他撑起中国计算机视觉研究半壁江山
- 比亚迪皮卡内饰专利图曝光,设计独具特色
- 魅族21银河定制版亮相,炫彩后盖设计引领时尚潮流
- 联想ThinkPad X1 2024 二合一笔记本明年三月上市
- 极狐阿尔法 T5 12 月 27 日正式上市,交付即刻
- 新一代宏碁非凡Go笔记本即将发布,搭载Acer Sense应用的AI功能更加丰富
- Mistral与微软合作为"小语言模型"带来革命,Mistral中杯代码能力超越GPT-4,成本降低2/3
- 极氪高速NZP服务覆盖范围扩展至无锡、苏州、常州、南京、镇江地区
- 《人工智能全域变革图景展望:跃迁点来临(2023)》:高质量数据愈发稀缺
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00