PillarNEst:如何进一步优化基于Pillar的3D目标检测性能?
 发布于2024-10-24 阅读(0)
发布于2024-10-24 阅读(0)
扫一扫,手机访问
写在前面 && 笔者的个人理解
在自动驾驶领域,一辆自动驾驶汽车通常配备多种传感器,例如激光雷达传感器用于采集点云数据,相机传感器用于采集图像数据等。由于激光雷达传感器能够更准确地获取待检测物体的几何和位置信息,因此基于点云的感知算法模型得以迅速迭代和发展。目前,基于点云的感知算法主要分为以下两大类
- 一类是基于Voxel-based的感知算法,如经典的SECOND、VoxelNet等算法。Voxel-based的算法模型首先会将输入的点云数据转换成3D的体素结构表示,然后利用3D的卷积算法模型实现后续的特征提取,将提取后的3D特征送入到后续的模块当中。
- 另外一类是基于Pillar-based的感知算法,如经典的PointPillar、PillaNext、PillarNet等算法。Pillar-based的算法模型并不依赖3D的卷积网络来获取点云特征,而是直接将点云数据构建成柱状的数据从而实现更快的检测速度,方便后续的上车部署等任务。
尽管目前广泛采用基于Pillar的算法模型,因为其部署方便、精度高,但是目前这些模型主要使用随机初始化的方法对2D卷积神经网络进行初始化。这导致很多在ImageNet上预训练的2D主干网络并没有被有效利用,造成资源浪费。另外,目前来看,基于点云的感知算法模型尺寸放大并没有导致精度上升的现象。而在2D检测任务中,预训练的主干网络和更大尺寸的主干网络在大规模数据集上都展现出更好的优势
所以,今天解析的这篇论文就是要探索2D主干网络的规模大小和预训练对于Pillar-based的3D目标检测器的性能影响。
以下是论文的arxiv链接:https://arxiv.org/pdf/2311.17770.pdf
PillarNeSt的算法解析
首先,让我们来介绍PillarNeSt算法模型的整体框架结构,如下图所示
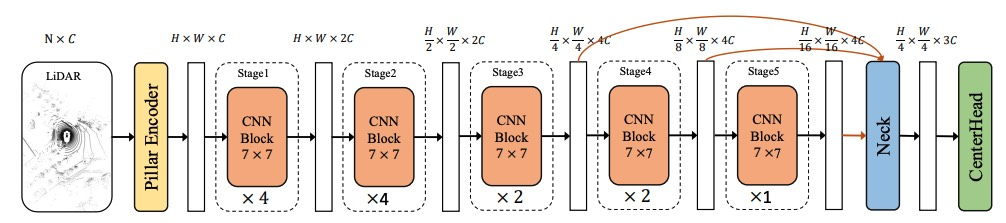 PillarNeSt算法模型的网络框图
PillarNeSt算法模型的网络框图
通过观察上图可知,PillarNeSt采用了点云感知算法中经典的架构模型(CenterPoint-Pillars)作为基线模型。然而,为了构建一个更强大的基线模型,论文作者对原有的PointPillars算法进行了修改。为了使读者更清楚地了解每个部分的修改位置,首先简单列举了CenterPoint-Pillars算法模型的几个基础模块
- 点云的伪图像表示:利用Pillar Encoder模块完成原始输入到模型中的点云数据向伪图像格式的表示
- 2D的主干网络完成伪图像的特征提取
- 利用Neck模块融合2D主干网络提取出来的多尺度特征图
- 利用3D检测头(CenerHead)输出最终的3D检测结果
- 根据损失函数计算损失loss,利用反向传播代码更新网络的参数值
接下来,我们将根据前面提到的每个基础模块,逐步进行修改和增强,最终构建出PillarNeSt算法模型
Pillar Encoder
在CenterPoint-Pillars算法模型的原始版本中,Pillar Encoder模块首先使用多层感知机结构提取点云数据的特征,然后采用Max Pooling层提取Pillar特征。然而,在本文中,作者认为只使用Max Pooling层会导致信息的丧失。基于此,作者在原有的Max Pooling层基础上添加了一个Mean Pooling层,以获取更多有用的信息。此外,作者还引入了每个点相对于几何中心高度的偏移量作为模块的输入,以补偿在Z轴上的信息丢失
“
在这篇论文中,我们同时使用最大池化和平均池化来保留更多的信息。此外,我们还引入了点的高度偏移,相对于几何中心的输入,以补偿在z轴上的信息损失
“
2D Backbone的重新设计
- 采用更大尺寸的卷积核
论文的作者提出,在2D图像领域中,通过增加网络模型的层数或者是深度,模型的有效感受野大小并没有得到有效的增加。而针对Pillar-based的算法模型也需要对伪图像点云数据进行特征提取。受到最近几篇Large-Kernel工作的启发,作者认为通过使用更大的卷积核可以使模型的有效感受野(ERF)增加,从而增加基于点云的感知算法的检测性能。同时,论文的作者为了平衡好模型速度和精度二者之间的关系,在本文中,采用了卷积核大小为7x7的深度可分离卷积层。
一些最近的研究认为,通过使用更大的卷积核可以有效地实现较大的有效感受野。此外,更大的感受野有助于提高点云检测器的能力
- 在第一层移除下采样操作
论文的作者考虑到图像当中有很多像素的信息都是存在冗余的,而常见的2D主干网络通常都会包括步长为2的卷积层对提取的图像特征进行下采样操作,从而降低后续卷积操作的运算成本。
但是对于点云信息而言却有所不同,由于原始的点云数据是稀疏而且是不规则的,而且包含了物体非常丰富的几何和结构信息。但是如果过早的应用下采样层就会导致点云中关键信息的损失。论文的作者基于这些考虑,在新设计的算法模型当中,删除了在第一个层存在的下采样层,从而保证了输入到后续层的分辨率,保存了输入数据的有效信息。
我们的骨干网络设计去除了干扰因素,并避免在第一阶段块中进行下采样。这个战略选择确保了输入特征的原始分辨率的保持
- 模型早期添加更多的block
作者指出,针对2D图像领域而言,通常都会在网络模型的后面几层堆叠更多的block来提取更抽象的语义特征,从而获取更加丰富的语义表达。但是考虑到点云数据是不规则同时也是稀疏的特点,这就意味着应该在模型的早期堆叠更多的block来完全提取出点云中包含的数据信息。作者也在论文中提到,通过实验结果也可以得出类似的结论,与在主干网络的后期堆叠block相比,在主干网络的前几层堆叠block可以获得更高的检测结果收益。
我们的大量实验表明,在早期阶段增加块的数量比在后期阶段增加更多块的效果更好
- 更深层次的层
论文的作者通过对点云的场景进行分析认为,不同物体的尺寸大小变化是非常巨大的。在针对Pillar-based的算法中而言,当Pillar的的尺寸设置为0.2m时,8倍的下采样后最大可感知范围为1.6m。然而,现实场景中的许多对象超过了有限的可感知范围。这意味着8倍下采样后的特征点不能完全感知大物体的整个物体。
基于此,作者采用了一种简单易行的方法来缓解这个问题,在主干网络第四层的输出基础上,额外再添加一层并标记为第五层。第五层模块包含的模块数量可以根据模型的规模进行扩展。
we adopt a simple way and add one more stage (named stage-5) on top of stage-4, which contains only one or two ConNeXt blocks. The block number of stage-5 can be scaled up based on the model size. The output of added stage-5 is served as one of the multi-scale inputs of the neck network.
主干网络缩放
在本文中,论文的一个重要目标是设计出一组可调整的网络结构模型,以在参数量和精度之间取得平衡。作者提出了一系列2D主干网络,从PillarNeSt-Tiny到PillarNeSt-Large,以满足不同参数量和精度的需求。下图展示了不同尺度的网络模型配置
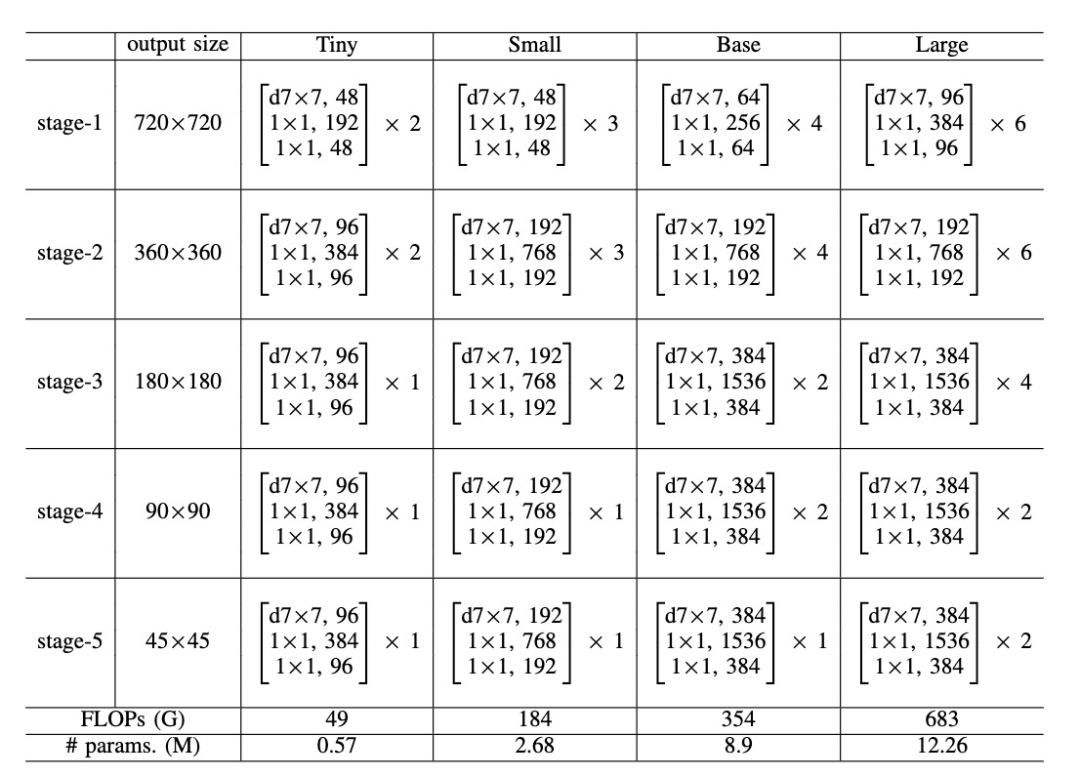 不同PillarNeSt模型的参数配置情况
不同PillarNeSt模型的参数配置情况
通过上图可以看出,不同版本的模型共用相似的模型结构。每个模型包括五层结构,上文已经提到过的第一层去掉了降采样层,对于剩余的其他层都会进行降采样的操作
在论文中,还为不同规模的主干网络模型提供了更加简便的表示方法,如下图所示

对于不同的PillarNeSt模型,进行通道数和block数的统计
主干网络预训练
为了达到作者的另一个目标,即利用在ImageNet上预训练的2D主干网络的优势,同时论文中的主干网络是基于ConvNeXt进行修改的,因此无法直接将原有的在ImageNet上预训练的ConvNeXt迁移到新设计的网络结构上。为此,论文采用了两种参数初始化方法,分别是基于stage view和micro view的初始化方法
- stage view
直接简单地从预训练的ConvNeXt模型中复制权重,用于用于Stage1-4,而添加的最后层(Stage-5)进行随机的初始化。对于Stage1-4,如果块数小于ConvNeXt的块数,我们只根据块标识复制相应块的参数 - micro view
从预训练的ConvNeXt模型的前Cin个通道复制训练好的参数,而对于剩余的通道则采用随机初始化的方式赋值参数
实验部分
在nuScenes和Argoverse2数据集上对PillarNeSt算法模型进行了有效性测试。首先,我们展示了在nuScenes数据集上的结果
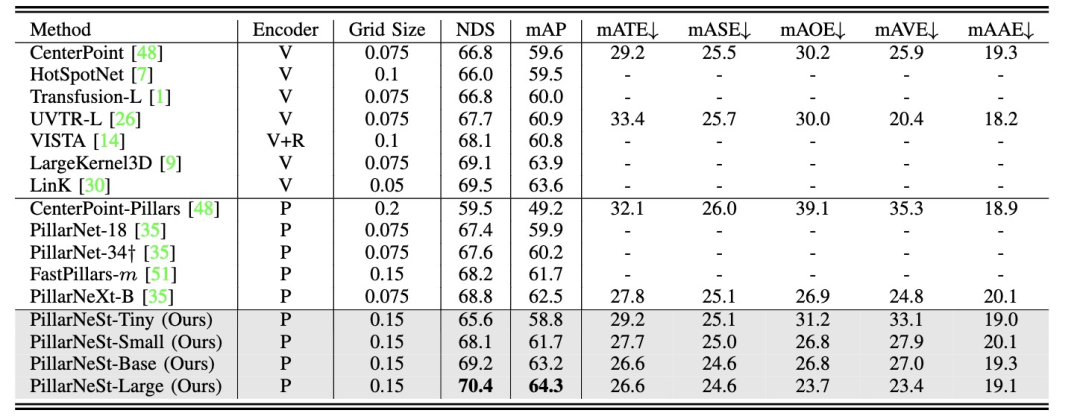
根据实验结果显示,PillarNeSt-Large算法模型在最大参数量下实现了64.3的mAP,相比其他基于点云的感知算法模型,取得了显著的优势
在Argoverse2数据集中,PillarNeSt的性能表现依然出色,除了在nuScenes数据集上的对比结果之外

从表格结果可以看出,PillarNeSt-Base算法模型在mAP和CDS指标上表现出最优的检测性能,明显优于其他基于点云的感知算法模型
通过上述实验结果表格,清楚地展示了该方法成功实现了一组可扩展的网络结构。根据具体情况,可以选择不同参数量的算法模型以获得不同的精度效果。针对论文中提出的预训练问题,同样提供了下图所示的实验结果
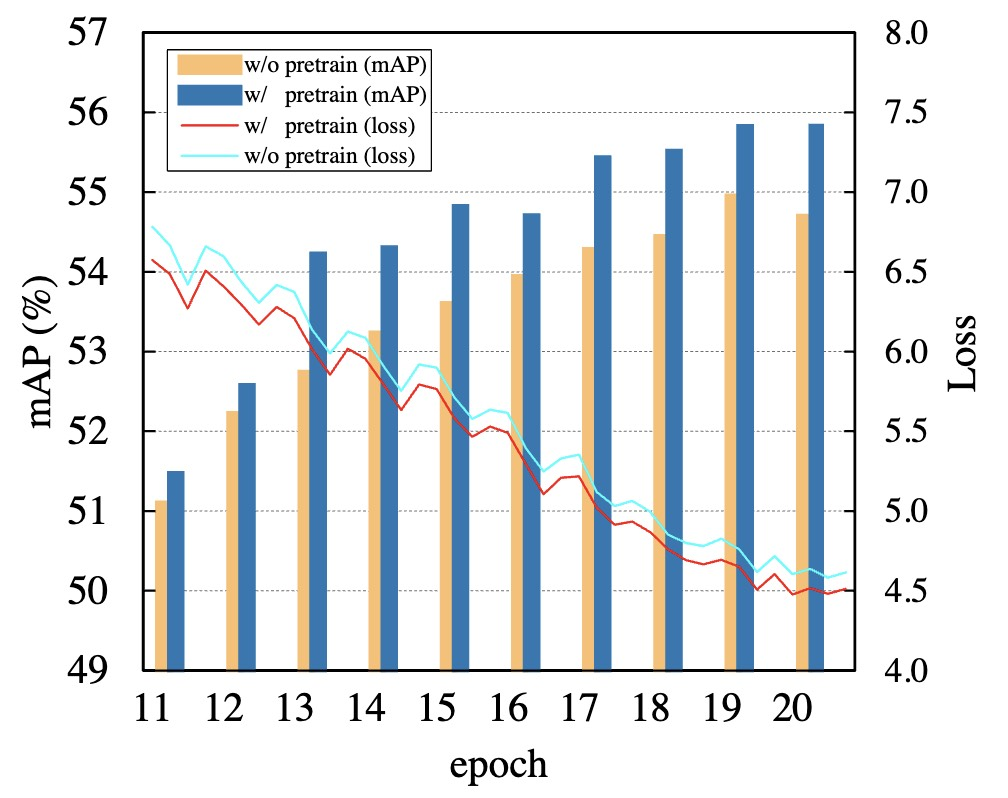
实验结果已经很好地证明了,论文中设计的网络结构继承了来自ImageNet上预训练得到的知识信息,无论是mAP还是训练损失,加载了预训练模型的效果都优于不采用预训练模型的效果
总结
目前,尽管基于点云的感知算法已经取得了很大的进步,但是针对Pillar-base算法模型中的2D主干网络依旧采用随机初始化的方式,没有使用到来自ImageNet预训练的网络模型,同时基于点云的算法模型也没得到不同尺度规模带来的优势
PillarNeSt是一个很好的解决方案,可以解决上述提到的两个问题。希望这篇解析能对大家有所帮助

原文链接:https://mp.weixin.qq.com/s/NJoAOyTuk9INQRJtJKz__g
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 复旦大学成立蘑菇车联自动驾驶人工智能研究中心
- 12月20日,据DoNews消息,12月19日在上海举行的上海市“脑与类脑智能基础转化应用研究”科技重大专项2023年度总结会上,复旦大学-蘑菇车联“自动驾驶人工智能校企联合研究中心”正式揭牌。揭牌仪式上,复旦大学校长、中国科学院院士金力以及蘑菇车联创始人兼首席执行官朱磊出席并见证了这一重要时刻赵健,上海市科学技术委员会总工程师,科学技术部原副部长、国际半导体照明联盟主席,季华实验室理事长兼主任曹健林,中国科学院院士、复旦大学原校长许宁生,中国科学院院士、复旦大学副校长张人禾,复旦大学类脑智能科学与技术研
- 6分钟前 自动驾驶 人工智能研究 大学-蘑菇车 0
-
 正版软件
正版软件
- 苹果培训员工在介绍 Vision Pro 头显时建议避免使用“VR”单词
- IT之家12月20日消息,消息源BradLynch近日发布推文,表示苹果在VisionPro头显的岗前培训中,禁止员工使用“VR”词汇。他在推文中表示,苹果明确要求其员工,在向用户展示和宣传过程中,不得使用“VR”这个单词,而是重点强调“神奇”(magical)和“新”(new)印象。在他与网友的互动中,他透露苹果公司只禁止使用虚拟现实(VR)这个词,而不禁止使用增强现实(AR)和扩展现实(XR)。然而,在岗前培训中几乎没有提到混合现实(MR)据IT之家此前援引彭博社马克·古尔曼报道,苹果邀请了部分零售店
- 16分钟前 0
-
 正版软件
正版软件
- OPPO Find X7系列采用索尼LYT-900感光技术,提供超高感光度和纯净图像,领先行业标准
- OPPO今日宣布了旗舰手机OPPOFindX7的重大更新:该手机将率先搭载索尼最新LYT-900传感器。这项突破性技术引领了手机摄影的新时代,也标志着OPPO在高端智能手机市场的重要成就索尼LYT-900传感器是被誉为“镜皇”的新一代传感器,特别引人注目的地方是它超大的一英寸传感器尺寸。这一进步不仅意味着更先进的制造工艺,还代表着它在感光能力、图像纯净度和动态范围方面都有显著提升。在智能手机摄影领域,这样的技术进步具有革命性意义,预示着未来手机摄影的新可能性根据我的了解,这款传感器有着5000万像素的高分
- 31分钟前 OPPO 0
-
 正版软件
正版软件
- 阿里巴巴CEO吴泳铭兼任淘天集团首席执行官,戴珊加入资产管理公司作为合作伙伴
- 阿里巴巴集团在12月20日宣布,阿里巴巴集团的CEO兼淘天集团的董事长吴泳铭将同时担任淘天集团的CEO一职自此,吴泳铭将同时担任阿里巴巴集团、淘天集团和阿里云智能集团三项CEO职务,确保集团聚焦核心战略电商和云,形成统一调度指挥和高压强的持续投入。▲图源阿里巴巴官网淘天集团原CEO戴珊将协助筹建阿里巴巴集团资产管理公司,这是阿里巴巴变革之后新的业务职能。本站从阿里巴巴官网获悉,吴泳铭自2023年9月起担任阿里巴巴首席执行官及董事。吴泳铭是阿里巴巴的创始人之一及阿里巴巴合伙人。他自2023年5月起出任淘天集
- 46分钟前 阿里 阿里巴巴 吴泳铭 淘天集团 0
-
 正版软件
正版软件
- 500+米冰道上,再度测试玄武钢化昆仑玻璃的超强耐久性
- 刚刚从冰岛火山回来的华为MateX5折叠屏手机,又要“搞事”了。就在12月30日,有媒体分享了一则“华为MateX5典藏版挑战500+米超长冰滑道”的视频,视频里,为了验证华为MateX5典藏版和华为Mate60RS非凡大师超可靠的玄武钢化昆仑玻璃,媒体前往长春,将手机从500+米长的滑道上滑下,结果当然也是意料之内的——两款手机成功挑战了500+米超长冰滑道,屏幕依旧完好无损。华为MateX5典藏版此前成功挑战了“上刀山”和“下火海”,所以这次的“500+米超长冰滑道”并不是第一次的“搞事”华为Mate
- 1小时前 05:25 华为Mate X5 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1779天前
-
 2
2
- Overture设置踏板标记的方法
- 1616天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1606天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1804天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1770天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1766天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1781天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1802天前
-
 9
9
相关推荐
- 复旦大学成立蘑菇车联自动驾驶人工智能研究中心
- 苹果培训员工在介绍 Vision Pro 头显时建议避免使用“VR”单词
- OPPO Find X7系列采用索尼LYT-900感光技术,提供超高感光度和纯净图像,领先行业标准
- 阿里巴巴CEO吴泳铭兼任淘天集团首席执行官,戴珊加入资产管理公司作为合作伙伴
- 500+米冰道上,再度测试玄武钢化昆仑玻璃的超强耐久性
- 发布了iOS 17.2.1正式版:修复了重要错误并提升了电池续航能力
- 奇瑞i CAR 03四驱长续航版:卓越性能与超值性价比,预售价18.58万元
- 全球首发:OPPO Find X7系列搭载索尼LYT-900影像传感器的强大功能
- PillarNEst:如何进一步优化基于Pillar的3D目标检测性能?
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00