清华文生3D方法在扩散模型下超越SOTA达到监督NeRF
 发布于2024-10-27 阅读(0)
发布于2024-10-27 阅读(0)
扫一扫,手机访问
用文字合成3D图形的AI模型,又有了新的SOTA!
近日,清华大学刘永进教授课题组提出了一种基于扩散模型的文生3D新方式。
无论是不同视角间的一致性,还是与提示词的匹配度,都比此前大幅提升。
 图片
图片
文生3D是3D AIGC的热点研究内容,得到了学术界和工业界的广泛关注。
刘永进教授课题组此次提出的新模型叫做TICD(Text-Image Conditioned Diffusion),在T3Bench数据集上达到了SOTA水平。
目前相关论文已经发布,代码也即将开源。
测评成绩已达SOTA
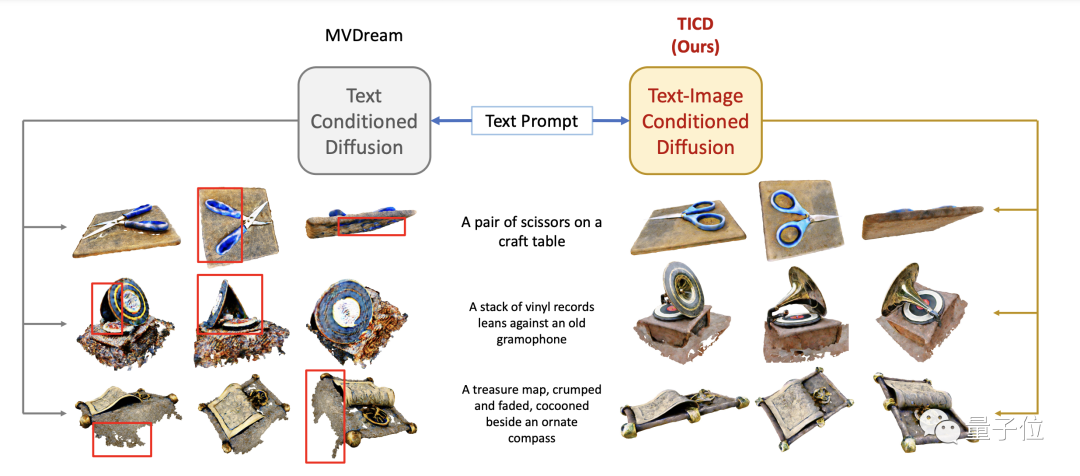
为了评估TICD方法的效果,研究团队首先进行了定性实验,并对比了此前一些较好的方法。
结果显示,用TICD方法生成的3D图形质量更好、图形更清晰,与提示词的匹配程度也更高。
 图片
图片
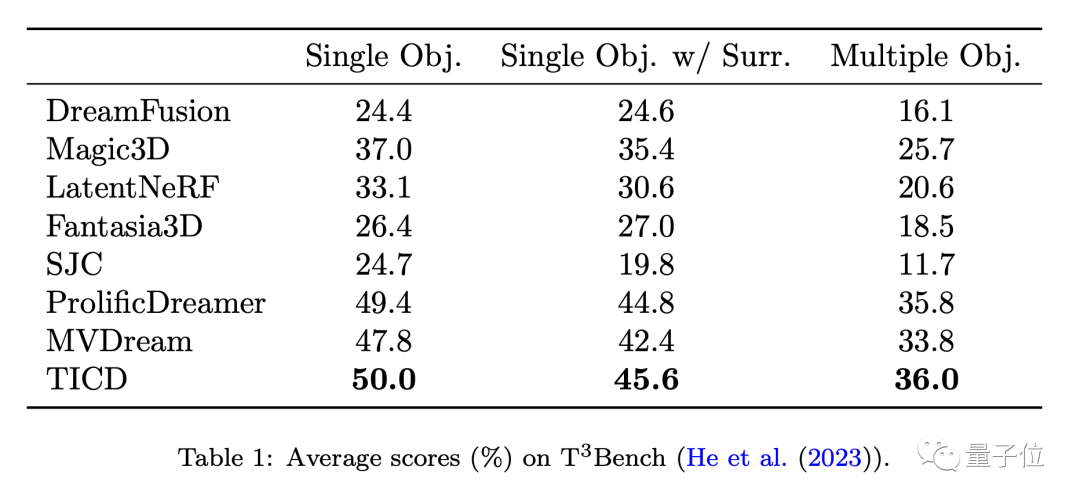
为了进一步评估这些模型的表现,团队在T3Bench数据集上将TICD与这些方法进行了定量测试。
结果显示,TICD在单对象、单对象带背景、多对象这三个提示集上都取得了最好的成绩,证明了它在生成质量和文本对齐性上都具有整体优势。
 图片
图片
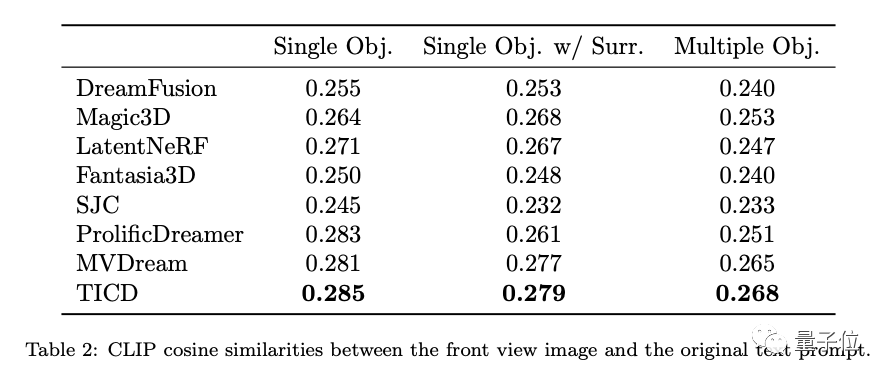
此外,为了进一步评估这些模型的文本对齐性,研究团队还对3D物体渲染得到的图片与原始提示词的CLIP余弦相似度上进行了测试,结果依然是TICD的表现最佳。
那么,TICD方法是如何实现这样的效果的呢?
将多视角一致性先验纳入NeRF监督
目前主流的文本生成3D方法大多使用预训练的2D扩散模型,通过得分蒸馏采样(Score Distillation Sampling, SDS)优化神经辐射场(NeRF)来生成全新的3D模型。
然而,这种预训练扩散模型提供的监督仅限于输入的文本本身,并未约束多视角间的一致性,可能会出现生成几何结构较差等问题。
为了在扩散模型的先验中引入多视角一致性,一些最新的研究通过使用多视角数据对2D扩散模型进行微调,但仍然缺乏细粒度的视角间连续性。
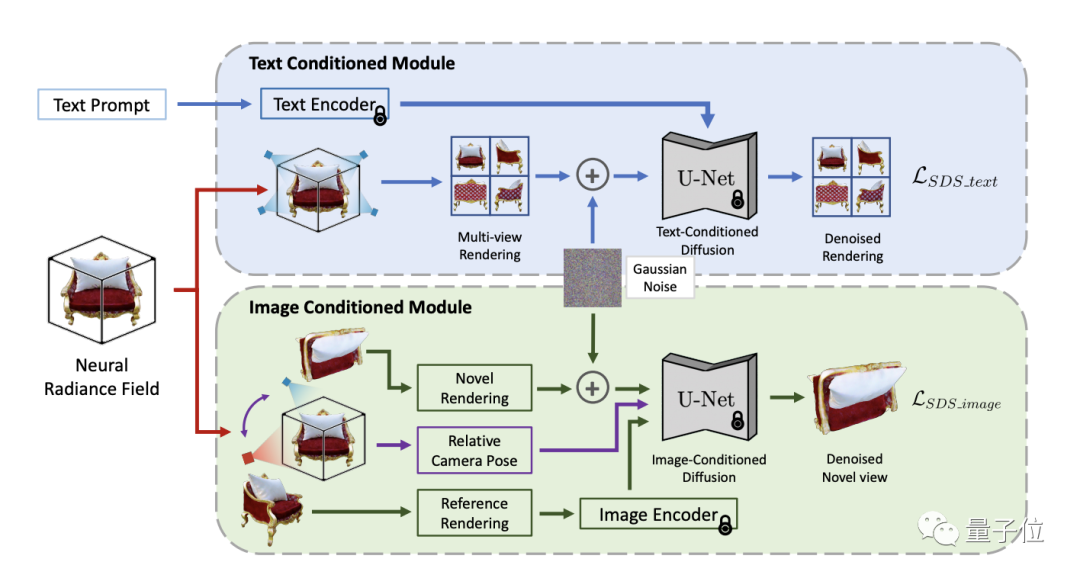
为了解决这一挑战,TICD方法将以文本为条件的和图像为条件的多视角图像纳入NeRF优化的监督信号中,分别保证了3D信息与提示词的对齐和3D物体不同视角间的强一致性,有效提升了生成3D模型的质量。
 图片
图片
工作流程上,TICD首先采样若干组正交的参考相机视角,使用NeRF渲染出对应的参考视图,然后对这些参考视图运用基于文本的条件扩散模型,约束内容与文本的整体一致性。
在此基础上选取若干组参考相机视角,并对于每个视角渲染一个额外新视角下的视图。接着以这两个视图与视角间的位姿关系作为新条件,使用基于图像的条件扩散模型约束不同视角间的细节一致性。
结合两种扩散模型的监督信号,TICD可对NeRF网络的参数进行更新并循环迭代优化,直到获得最终的NeRF模型,并渲染出高质量、几何清晰且与文本一致的3D内容。
此外,TICD方法可以有效消除现有方法面对特定文本输入时可能产生的几何信息消失、错误几何信息过量生成、颜色混淆等问题。
论文地址:https://arxiv.org/abs/2312.11774
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- pyr币是否值得投资
- Pyr币值得投资,但应谨慎。Pyr币是一种低交易费、快速交易的可扩展加密货币,具有交易、质押和治理用例。不过,其波动性、竞争和低采用率也存在风险。在投资前,应考虑风险承受能力、研究和长期投资策略。
- 13分钟前 0
-
 正版软件
正版软件
- TechInsights报告:全球智能手机出货量反弹 市场格局生变
- 5月7日消息显示,根据市场研究机构TechInsights最新发布的报告,2024年第一季度全球智能手机市场呈现出积极的增长态势,出货量同比反弹10%,总量达到2.95亿部。这一数据再次证明了全球智能手机市场的复苏势头,各大厂商也积极调整战略,以应对市场变化。在全球智能手机市场上,三星仍然保持着领先地位,出货量约为6000万部,市场份额达到20%。尽管去年同期出货量微降1%,但三星在北美、中东欧和中东非洲等地区的强劲表现,成功弥补了西欧和亚太地区的波动。其中,三星S24系列智能手机的热销,尤其是Ultra
- 23分钟前 0
-
 正版软件
正版软件
- 比特币减半前的暴跌
- 减半前暴跌是由于获利回吐、不确定性和技术因素造成的,这会导致价格波动性、影响市场情绪并增加交易量。尽管如此,历史数据表明,减半后通常会出现反弹,因为供应减少会长期提振价格。
- 38分钟前 0
-
 正版软件
正版软件
- uni币减半时间
- UniSwap的第一个减半时间为2023年4月30日,届时UNI挖矿奖励将从每区块4UNI减半到每区块2UNI,流通供应的增长速度减慢,可能会影响UNI价格的供需关系和波动。
- 53分钟前 0
-
 正版软件
正版软件
- 火币做空教程
- 在火币交易所进行做空时,投资者卖出资产以受益于预期价格下跌。具体步骤包括:注册火币账户激活永续合约账户选择交易对和杠杆输入价格和数量进行做空管理风险平仓
- 1小时前 02:25 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1899天前
-
 2
2
- Overture设置踏板标记的方法
- 1736天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1725天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1924天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1890天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1886天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1900天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1922天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00