GPT-4解释的新变慢方式
 发布于2024-10-30 阅读(0)
发布于2024-10-30 阅读(0)
扫一扫,手机访问
GPT-4,自其发布以来被视为全球最强大的语言模型之一,却也不幸经历了一系列的信任危机。
如果我们将今年早些时候的"间歇式降智"事件与OpenAI对GPT-4架构的重新设计联系起来,那么最近有关GPT-4变得"懒惰"的传闻就更加有趣了。有人测试发现,只要告诉GPT-4"现在是寒假",它就会变得懒洋洋的,仿佛进入了冬眠状态。
要解决模型在新任务上的零样本性能变差的问题,我们可以采取以下方法: 1. 数据增强:通过对现有数据进行扩充和变换,来增加模型的泛化能力。例如,可以通过旋转、缩放、平移等方式改变图像数据,或者通过合成新的数据样本。 2. 迁移学习:利用已经在其他任务上训练好的模型,将其参数和知识迁移到新任务上。这样可以利用已有的知识和经验,提
最近,来自加州大学圣克鲁斯分校的研究人员在一篇论文中发布了一项新的发现,可能能够解释GPT-4性能下降的深层原因。

「我们发现,在训练数据创建日期之前发布的数据集上,LLM 的表现出奇地好于之后发布的数据集。」
它们在「见过的」任务上表现出色,而在新任务上则表现糟糕。这意味着,LLM 只是基于近似检索的模仿智能方法,主要是记忆东西,而没有任何程度的理解。
说白了,就是 LLM 的泛化能力「没有说的那么强」—— 基础不扎实,实战总有出纰漏的时候。
造成这种结果的一大原因是「任务污染」,这是数据污染的其中一种形式。我们以前熟知的数据污染是测试数据污染,即在预训练数据中包含测试数据示例和标签。而「任务污染」是在预训练数据中加入任务训练示例,使零样本或少样本方法中的评估不再真实有效。
研究者在论文中首次对数据污染问题进行了系统分析:

论文链接:https://arxiv.org/pdf/2312.16337.pdf
看完论文,有人「悲观」地表示:
这是所有不具备持续学习能力的机器学习(ML)模型的命运,即 ML 模型权重在训练后会被冻结,但输入分布会不断变化,如果模型不能持续适应这种变化,就会慢慢退化。
这意味着,随着编程语言的不断更新,基于 LLM 的编码工具也会退化。这就是为什么你不必过分依赖这种脆弱工具的原因之一。
不断重新训练这些模型的成本很高,迟早有人会放弃这些低效的方法。
目前还没有任何 ML 模型能够可靠地持续适应不断变化的输入分布,而不会对之前的编码任务造成严重干扰或性能损失。
而这正是生物神经网络所擅长的领域之一。由于生物神经网具有强大的泛化能力,学习不同的任务可以进一步提高系统的性能,因为从一项任务中获得的知识有助于改善整个学习过程本身,这就是所谓的「元学习」。
「任务污染」的问题有多严重?我们一起来看下论文内容。
模型和数据集
实验所使用的模型有 12 个(如表 1 所示),其中 5 个是专有的 GPT-3 系列模型,7 个是可免费获取权重的开放模型。
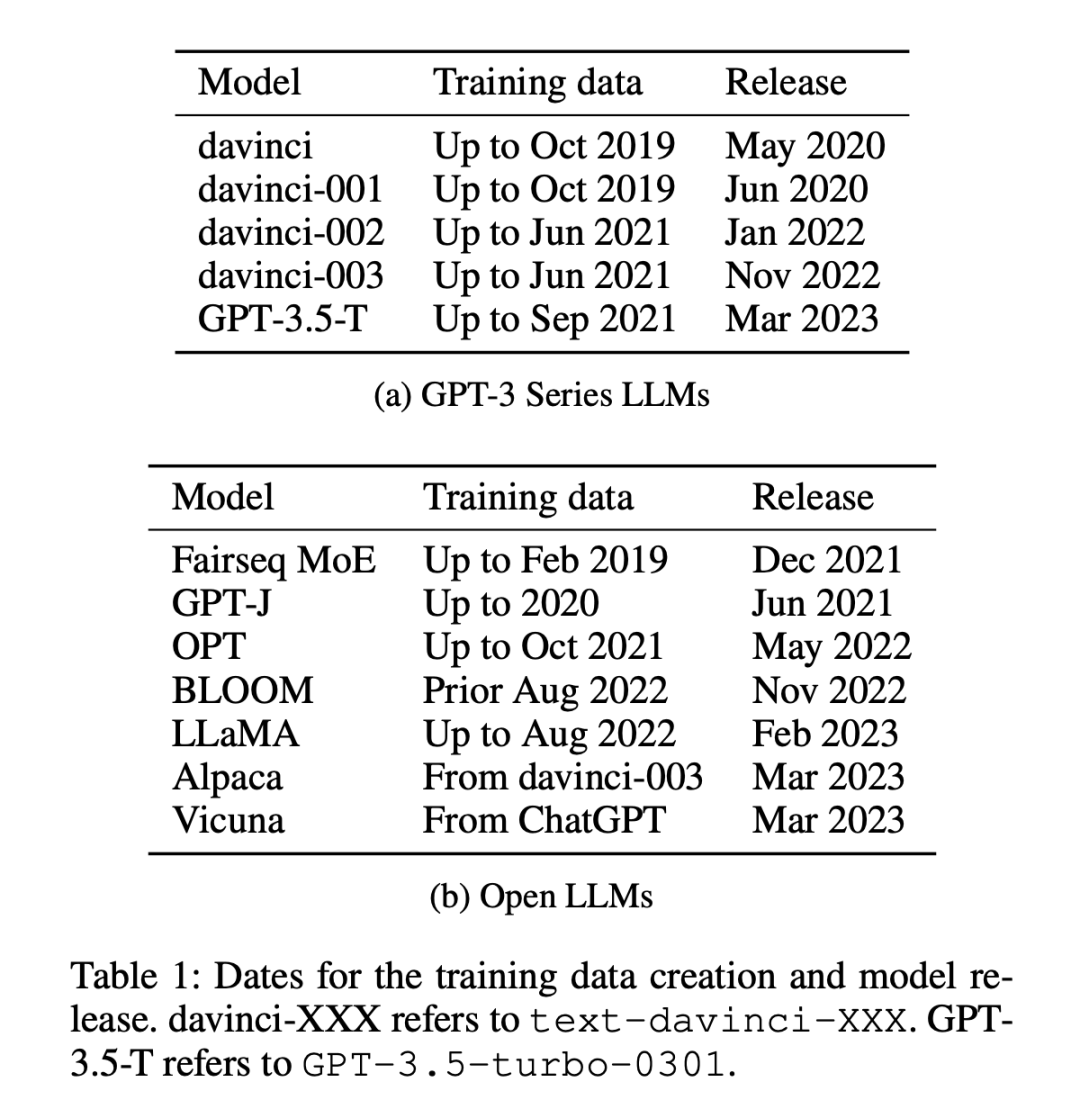
数据集分为两类:2021 年 1 月 1 日之前或之后发布的数据集,研究者使用这种划分方法来分析旧数据集与新数据集之间的零样本或少样本性能差异,并对所有 LLM 采用相同的划分方法。表 1 列出了每个模型训练数据的创建时间,表 2 列出了每个数据集的发布日期。
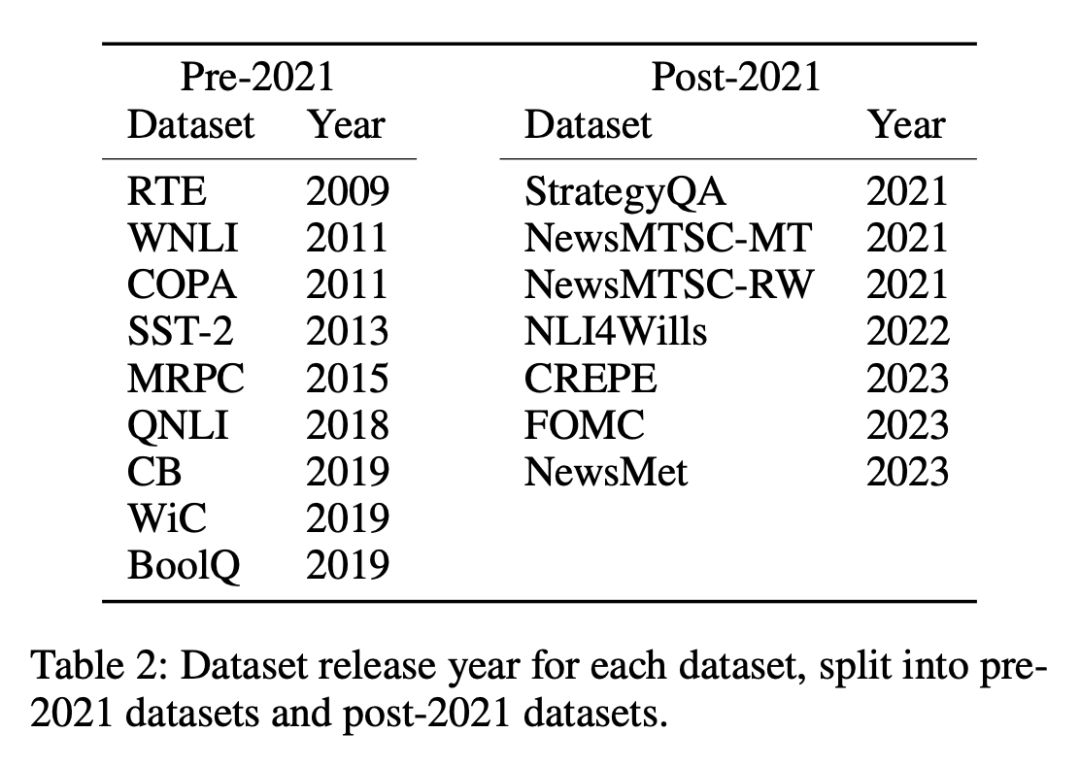
上述做法的考虑是,零样本和少样本评估涉及模型对其在训练期间从未见过或仅见过几次的任务进行预测,其关键前提是模型事先没有接触过要完成的特定任务,从而确保对其学习能力进行公平的评估。然而,受污染的模型会给人一种未接触或仅接触过几次的能力的假象,因为它们在预训练期间已经接受过任务示例的训练。在按时间顺序排列的数据集中,检测这种不一致性会相对容易一些,因为任何重叠或异常都会很明显。
测量方法
研究者采用了四种方法来测量「任务污染」:
- 训练数据检查:在训练数据中搜索任务训练示例。
- 任务示例提取:从现有模型中提取任务示例。只有经过指令调优的模型才能进行提取,这种分析也可用于训练数据或测试数据的提取。注意,为了检测任务污染,提取的任务示例不必与现有的训练数据示例完全匹配。任何演示任务的示例都表明零样本学习和少样本学习可能存在污染。
- 成员推理:此方法仅适用于生成任务。检查输入实例的模型生成内容是否与原始数据集完全相同。如果完全匹配,就可以推断它是 LLM 训练数据中的一员。这与任务示例提取不同,因为生成的输出会被检查是否完全匹配。开放式生成任务的精确匹配强烈表明模型在训练过程中见过这些示例,除非模型「通灵」,知道数据中使用的确切措辞。(注意,这只能用于生成任务。)
- 时序分析:对于在已知时间范围内收集训练数据的模型集,在已知发布日期的数据集上测量其性能,并使用时序证据检查污染证据。
前三种方法精度高,但召回率低。如果能在任务的训练数据中找到数据,那么就能确定模型曾见过示例。但由于数据格式的变化、用于定义任务的关键字的变化以及数据集的大小,使用前三种方法找不到污染证据并不能证明没有污染。
第四种方法,按时间顺序分析的召回率高,但精确度低。如果由于任务污染而导致性能较高,那么按时间顺序分析就有很大机会发现它。但随着时间的推移,其他因素也可能导致性能提高,因此精确度较低。
因此,研究者采用了所有四种方法来检测任务污染,发现了在某些模型和数据集组合中存在任务污染的有力证据。
他们首先对所有测试过的模型和数据集进行时序分析,因为它最有可能发现可能的污染;然后使用训练数据检查和任务示例提取寻找任务污染的进一步证据;接下来观察了 LLM 在无污染任务中的性能,最后使用成员推理攻击进行额外分析。
重点结论如下:
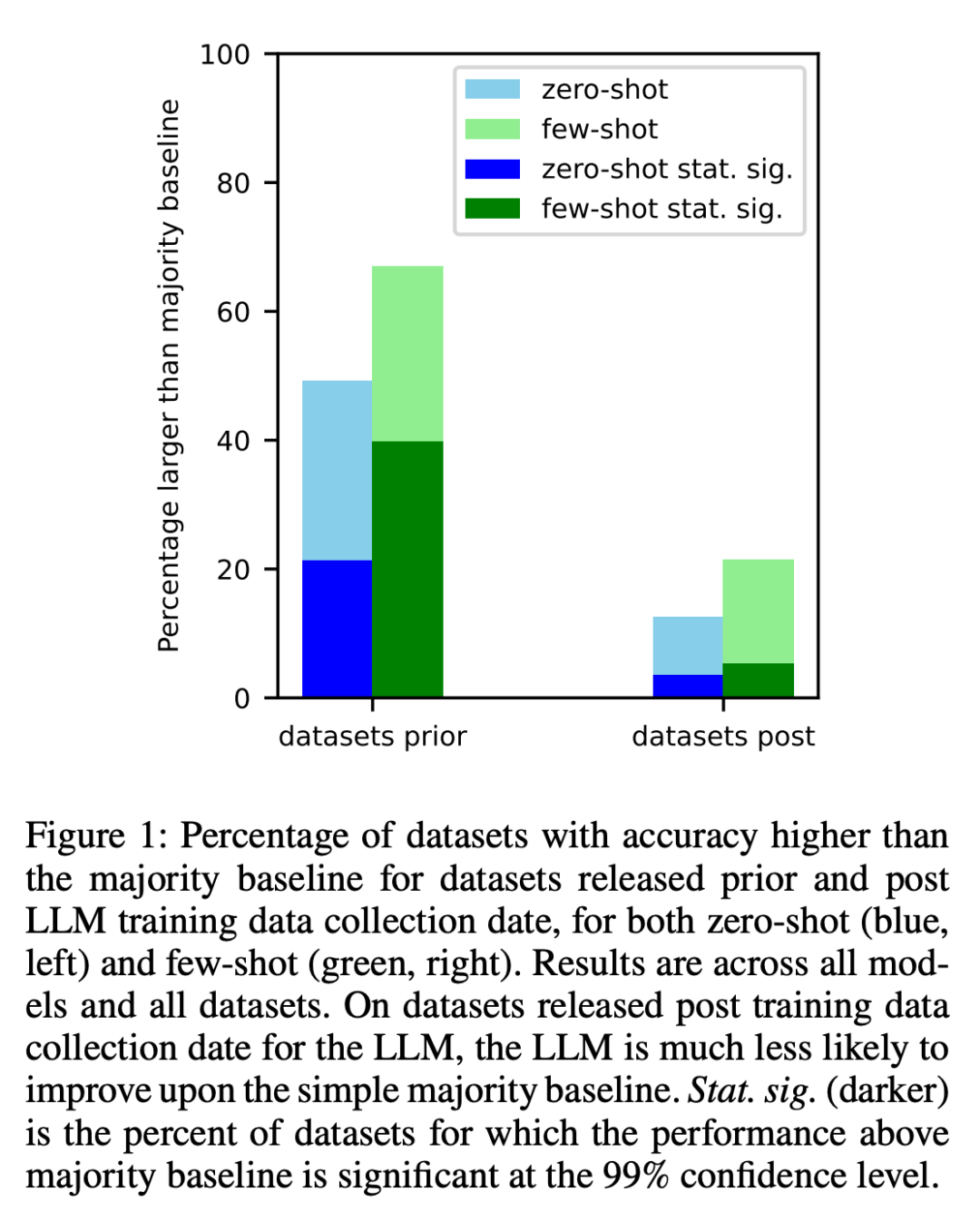
1、研究者对每个模型在其训练数据在互联网上抓取之前创建的数据集和之后创建的数据集进行了分析。结果发现,对于在收集 LLM 训练数据之前创建的数据集,其性能高于大多数基线的几率明显更高(图 1)。
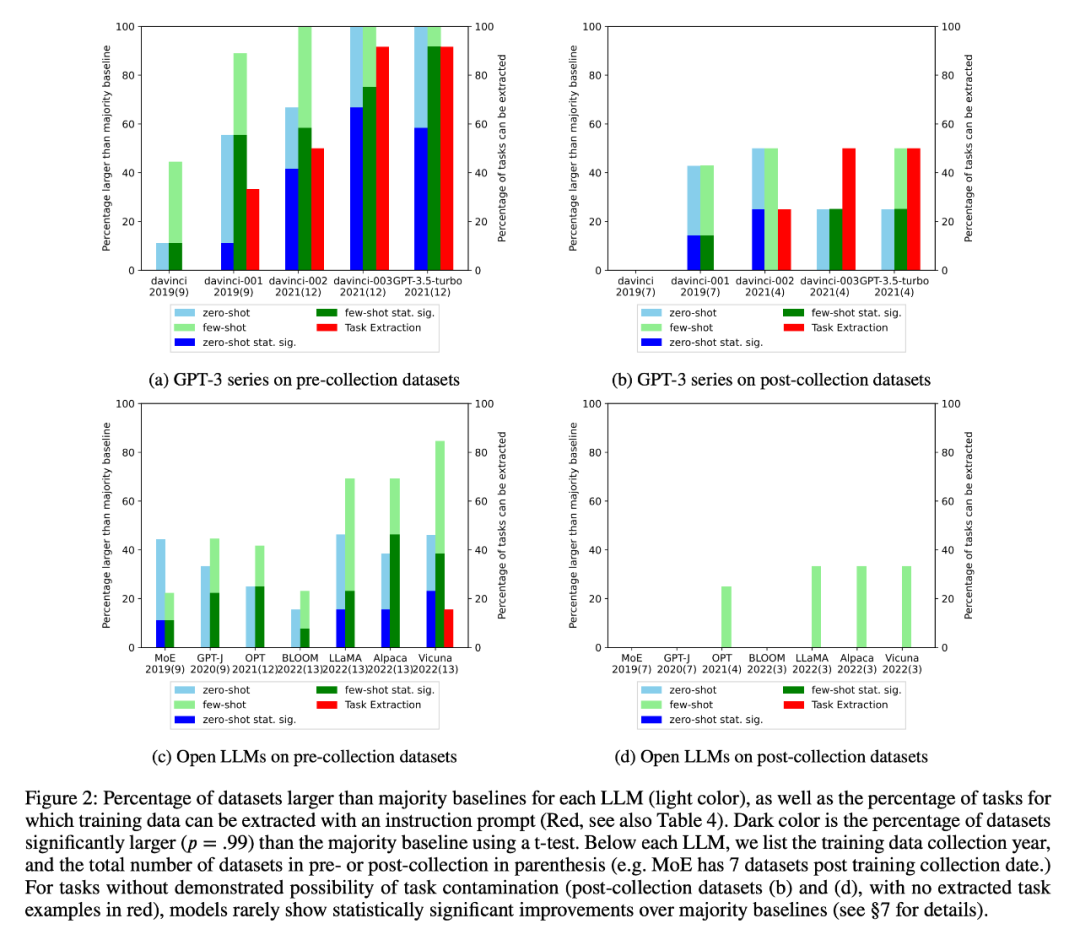
2、研究者进行了训练数据检查和任务示例提取,以查找可能存在的任务污染。结果发现,对于不可能存在任务污染的分类任务,在一系列任务中,模型很少比简单多数基线有统计意义上的显著提高,无论是零样本还是少样本(图 2)。
研究者也检查了 GPT-3 系列和开放 LLM 的平均表现随时间的变化,如图 3:
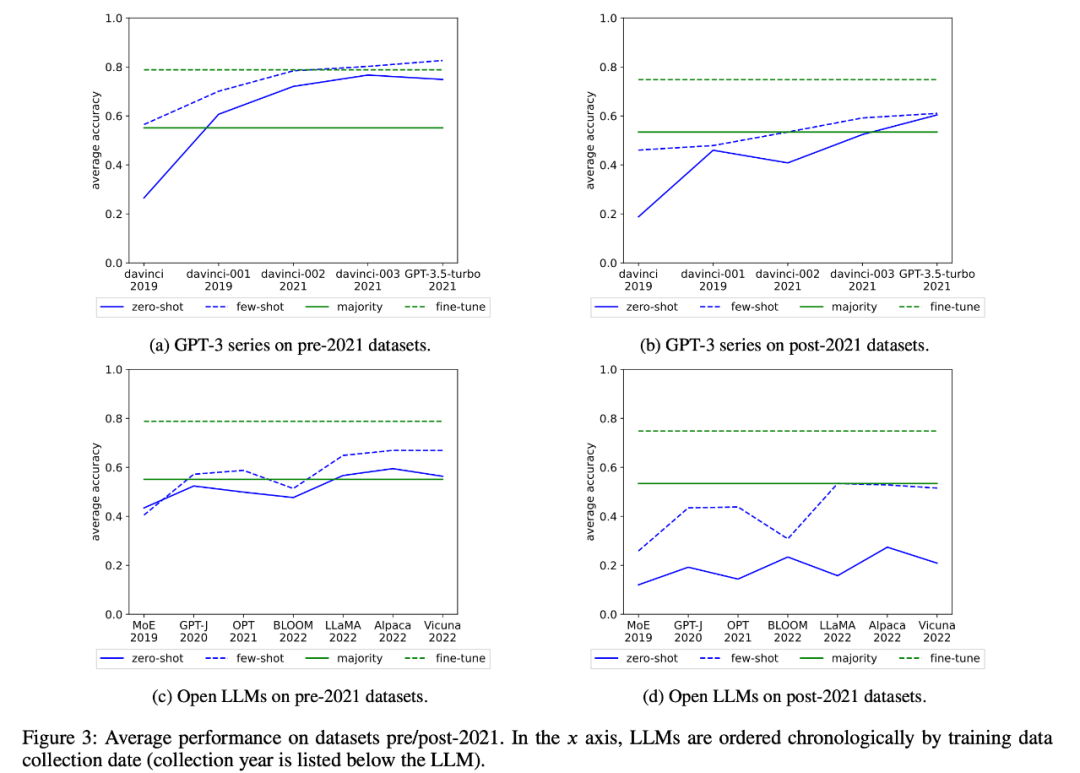
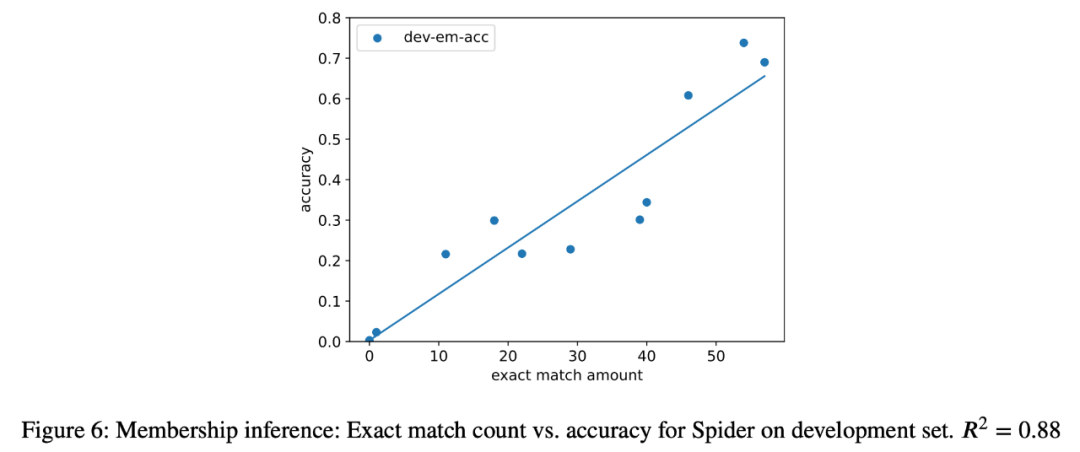
3、作为案例研究,研究者还尝试对分析中的所有模型进行语义解析任务的成员推理攻击,发现在最终任务中,提取实例的数量与模型的准确性之间存在很强的相关性(R=.88)(图 6)。这有力地证明了在这一任务中零样本性能的提高是由于任务污染造成的。
4、研究者还还仔细研究了 GPT-3 系列模型,发现可以从 GPT-3 模型中提取训练示例,而且从 davinci 到 GPT-3.5-turbo 的每个版本中,可提取的训练示例数量都在增加,这与 GPT-3 模型在该任务上零样本性能的提高密切相关(图 2)。这有力地证明了从 davinci 到 GPT-3.5-turbo 的 GPT-3 模型在这些任务上的性能提高是由于任务污染造成的。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 美国发布 UFO 调查报告:未发现外星技术证据,大多数目击事件解释为误解
- 根据美国国防部全域异常解决办公室(AARO)发布的研究报告,经过近80年的调查,他们没有发现任何证据表明存在外星技术。该报告涉及不明飞行物、外星人和外星智慧生物等相关议题。“所有分类级别的所有调查工作都得出一个结论:大多数目击事件都是普通物体和现象,是误认。”作为2023财年国防授权法的一部分,这份长达63页的报告是AARO调查结果的第一卷,涵盖了1945年至2023年10月期间的事件。第二卷报告预计将在今年晚些时候发布,将包括对2023年11月至2024年4月期间所完成研究结果的详细分析。一份报告指出,
- 7分钟前 不明飞行物 0
-
 正版软件
正版软件
- 揭幕 Claude3:揭露 OpenAI 最大弱点
- 企业级SOTA大模型,Anthropic的Claude3释放了哪些信号?作者|宛辰编辑|靖宇作为OpenAIGPT3研发负责人的创业项目,Anthropic被视为最能与OpenAI抗衡的一家创业公司。Anthropic在当地时间周一发布了一组Claude3系列大模型,声称其功能最强大的模型在各种基准测试中都胜过了OpenAI的GPT-4和Google的Gemini1.0Ultra。但是,能处理更复杂的推理任务、更智能、更快响应,这些跻身大模型Top3的综合能力只是Claude3的基本功。Anthropic
- 22分钟前 人工智能 OpenAI 0
-
 正版软件
正版软件
- 育碧游戏《看门狗》将被拍成真人电影
- 根据Deadline的报道,育碧经典游戏《看门狗》将被改编成真人电影。截至目前,电影的具体情节仍然是保密的,采用了原创剧本。虽然情节保密,但已经确认了一些演员的名单。据报道,这部电影将由著名的NewRegencyPictures制作,该公司曾参与制作《刺客信条》和《波西米亚狂想曲》等知名影片。制片人包括亚里夫・米尔坎和娜塔莉・莱曼,以及育碧影视的玛格丽特・博伊金。该片将由法国导演马蒂厄・图里(MathieuTuri)执导,本站查询发现他曾是昆汀《无耻混蛋》、吕克贝松《超体》的助理导演,还执导过好评恐怖片《
- 37分钟前 电影 育碧 看门狗 0
-
 正版软件
正版软件
- 带来时尚革新!戴尔发布支持Tensor Core的Precision 3280 CFF工作站
- 戴尔最近发布了一款名为Precision3280CompactFormFactor(CFF)的全新工作站。这款设备被戴尔称为“全球体积最小的支持TensorCoreGPU的工作站”,其顶配版本支持英伟达(NVIDIA)RTX4000Ada显卡,性能强劲。Precision3280CFF是一款体积小巧的工作站,尺寸为206x178x79毫米,重量仅为2.54千克,便于携带和部署。尽管小巧,但它的性能却非常强大。这款工作站可以配备高达80W的第14代英特尔酷睿处理器,为用户提供出色的计算能力。据小编了解,Pr
- 52分钟前 戴尔 tensor 0
-
 正版软件
正版软件
- 曝光新款比亚迪秦L车型,搭载第五代DM-i混动系统
- 近日,一组未经伪装的比亚迪全新车型秦L的谍照在网络上广泛传播,引起了车迷和消费者的高度关注。根据工信部的申报信息,这款新车即将面世。比亚迪的粉丝社区“迪粉之家”也第一时间分享了这些相关照片,进一步激发了人们对这款新车的好奇心。曝光的谍照显示,秦L车型延续了比亚迪经典的“DragonFace”设计风格。前脸设计中,巨大的进气格栅格外观抢眼,而两侧的C字形导风槽则增添了车辆的动感氛围。车身侧面线条流畅自然,展现出优雅而富有动感的车身曲线。秦L车型在车内设计方面同样充满科技感。配备全液晶仪表盘以及大尺寸中控屏幕
- 1小时前 08:35 比亚迪 秦L 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1830天前
-
 2
2
- Overture设置踏板标记的方法
- 1667天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1657天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1855天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1821天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1817天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1832天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1853天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00