通过对话生成逼真表情与动作,Audio2Photoreal将网络连接变成现实
 发布于2024-10-30 阅读(0)
发布于2024-10-30 阅读(0)
扫一扫,手机访问
当你和朋友隔着冷冰冰的手机屏幕聊天时,你得猜猜对方的语气。当 Ta 发语音时,你的脑海中还能浮现出 Ta 的表情甚至动作。如果能视频通话显然是最好的,但在实际情况下并不能随时拨打视频。
如果你正在与一个远程朋友聊天,不是通过冰冷的屏幕文字,也不是缺乏表情的虚拟形象,而是一个逼真、动态、充满表情的数字化虚拟人。这个虚拟人不仅能够完美地复现你朋友的微笑、眼神,甚至是细微的肢体动作。你会不会感到更加的亲切和温暖呢?真是体现了那一句「我会顺着网线爬过来找你的」。
这不是科幻想象,而是在实际中可以实现的技术了。
面部表情和肢体动作包含的信息量很大,这会极大程度上影响内容表达的意思。比如眼睛一直看着对方说话和眼神基本上没有交流的说话,给人的感觉是截然不同的,这也会影响另一方对沟通内容的理解。我们在交流过程中对这些细微的表情和动作都有着极敏锐的捕捉能力,并用它们来形成对交谈伙伴意图、舒适度或理解程度的高级理解。因此,开发能够捕捉这些微妙之处的高度逼真的对话虚拟人对于互动至关重要。
为此,Meta 与加利福尼亚大学的研究者提出了一种根据两人对话的语音音频生成逼真虚拟人的方法。它可以合成各种高频手势和表情丰富的面部动作,这些动作与语音非常同步。对于身体和手部,他们利用了基于自回归 VQ 的方法和扩散模型的优势。对于面部,他们使用以音频为条件的扩散模型。然后将预测的面部、身体和手部运动渲染为逼真虚拟人。研究者证明了在扩散模型上添加引导姿势条件能够生成比以前的作品更多样化和合理的对话手势。

- 论文地址:https://huggingface.co/papers/2401.01885
- 项目地址:https://people.eecs.berkeley.edu/~evonne_ng/projects/audio2photoreal/
研究者表示,他们是第一个研究如何为人际对话生成逼真面部、身体和手部动作的团队。与之前的研究相比,研究者基于 VQ 和扩散的方法合成了更逼真、更多样的动作。
方法概览
研究者从记录的多视角数据中提取潜在表情代码来表示面部,并用运动骨架中的关节角度来表示身体姿势。如图 3 所示,本文系统由两个生成模型组成,在输入二人对话音频的情况下,生成表情代码和身体姿势序列。然后,表情代码和身体姿势序列可以使用神经虚拟人渲染器逐帧渲染,该渲染器可以从给定的相机视图中生成带有面部、身体和手部的完整纹理头像。
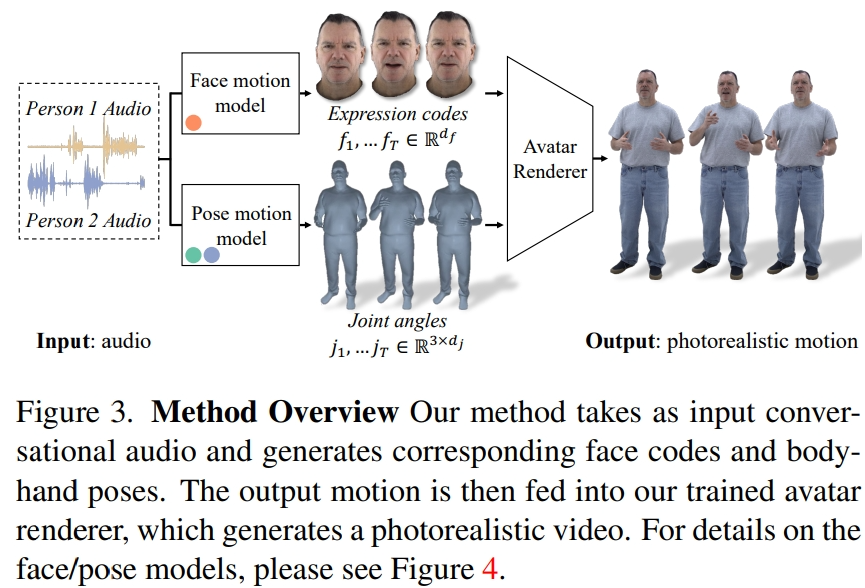
需要注意的是,身体和脸部的动态变化非常不同。首先,面部与输入音频的相关性很强,尤其是嘴唇的运动,而身体与语音的相关性较弱。这就导致在给定的语音输入中,肢体手势有着更加复杂的多样性。其次,由于在两个不同的空间中表示面部和身体,因此它们各自遵循不同的时间动态。因此,研究者用两个独立的运动模型来模拟面部和身体。这样,脸部模型就可以「主攻」与语音一致的脸部细节,而身体模型则可以更加专注于生成多样但合理的身体运动。
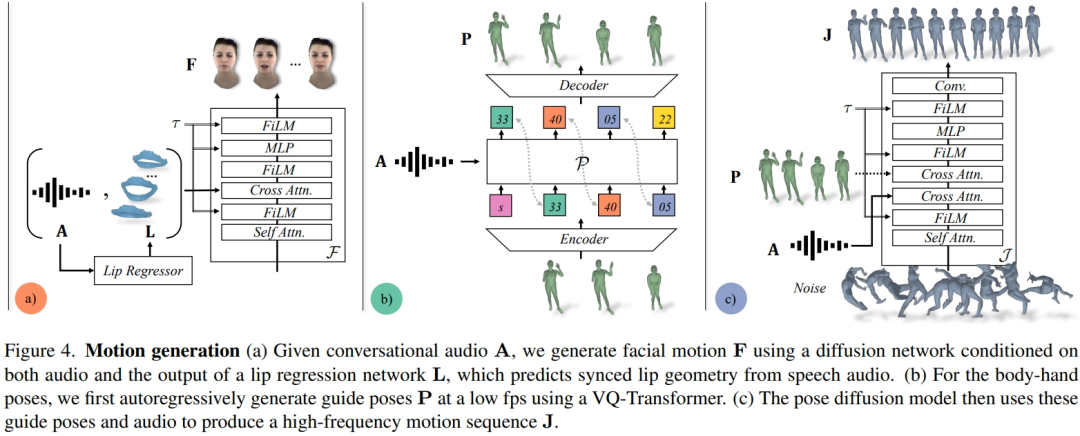
面部运动模型是一个扩散模型,以输入音频和由预先训练的唇部回归器生成的唇部顶点为条件(图 4a)。对于肢体运动模型,研究者发现仅以音频为条件的纯扩散模型产生的运动缺乏多样性,而且在在时间序列上显得不够协调。但是,当研究者以不同的引导姿势为条件时,质量就会提高。因此,他们将身体运动模型分为两部分:首先,自回归音频条件变换器预测 1fp 时的粗略引导姿势(图 4b),然后扩散模型利用这些粗略引导姿势来填充细粒度和高频运动(图 4c)。关于方法设置的更多细节请参阅原文。
实验及结果
研究者根据真实数据定量评估了 Audio2Photoreal 有效生成逼真对话动作的能力。同时,还进行了感知评估,以证实定量结果,并衡量 Audio2Photoreal 在给定的对话环境中生成手势的恰当性。实验结果表明,当手势呈现在逼真的虚拟化身上而不是 3D 网格上时,评估者对微妙手势的感知更敏锐。
研究者将本文方法与 KNN、SHOW、LDA 这三种基线方法根据训练集中的随机运动序列进行了生成结果对比。并进行了消融实验,测试了没有音频或指导姿势的条件下、没有引导姿势但基于音频的条件下、没有音频但基于引导姿势的条件下 Audio2Photoreal 每个组件的有效性。
定量结果
表 1 显示,与之前的研究相比,本文方法在生成多样性最高的运动时,FD 分数最低。虽然随机具有与 GT 相匹配的良好多样性,但随机片段与相应的对话动态并不匹配,导致 FD_g 较高。
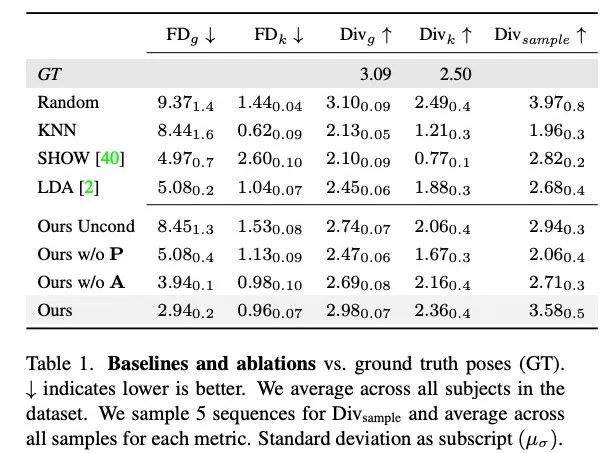
图 5 展示了本文方法所生成的引导姿势的多样性。通过基于 VQ 的变换器 P 采样,可以在相同音频输入的条件下生成风格迥异的姿势。

如图 6 所示,扩散模型会学习生成动态动作,其中的动作会与对话音频更加匹配。

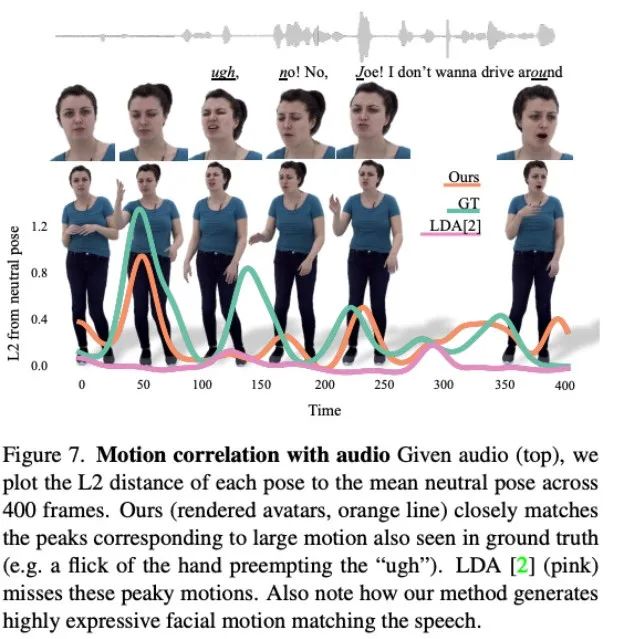
图 7 表现了 LDA 生成的运动缺乏活力,动作也较少。相比之下,本文方法合成的运动变化与实际情况更为吻合。
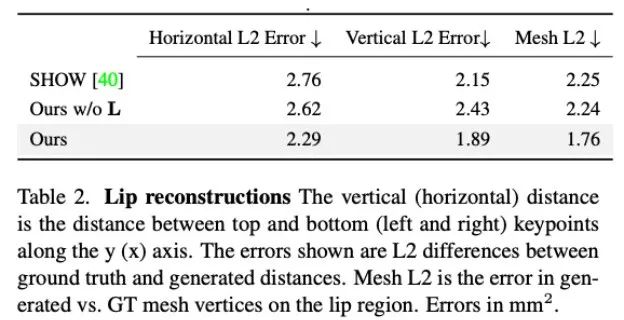
此外,研究者还分析了本文方法在生成嘴唇运动方面的准确度。如表 2 中的统计所示,Audio2Photoreal 显著优于基线方法 SHOW,以及在消融实验中移除预训练的嘴唇回归器后的表现。这一设计改善了说话时嘴形的同步问题,有效避免了不说话时口部出现随机张开和闭合的动作,使得模型能够实现更出色的的嘴唇动作重建,同时降低了面部网格顶点(网格 L2)的误差。
定性评估
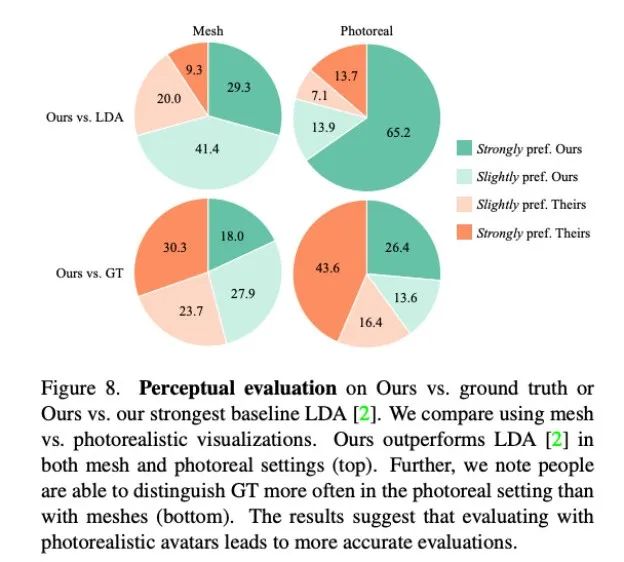
由于对话中手势的连贯性难以被量化,研究者采用了定性方法做评估。他们在 MTurk 进行了两组 A/B 测试。具体来说,他们请测评人员观看本文方法与基线方法的生成结果或本文方法与真实情景的视频对,请他们评估哪个视频中的运动看起来更合理。
如图 8 所示,本文方法显著优于此前的基线方法 LDA,大约有 70% 的测评人员在网格和真实度方面更青睐 Audio2Photoreal。
如图 8 顶部图表所示,和 LDA 相比,评估人员对本文方法的评价从「略微更喜欢」转变为「强烈喜欢」。和真实情况相比,也呈现同样的评价。不过,在逼真程度方面,评估人员还是更认可真实情况,而不是 Audio2Photoreal。
更多技术细节,请阅读原论文。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 比特币杠杆穿仓我用还钱吗
- 比特币杠杆穿仓是否需要还钱取决于具体情况:有平仓机制的平台:穿仓前未平仓需还钱;触发平仓机制及时平仓则不需要还钱。无平仓机制的平台:无论是否触发止损,均需还钱。其他影响因素还包括资金来源、平台赔偿政策和法律法规。
- 5天前 0
-
 正版软件
正版软件
- RWA赛道代币ONDO、CFG大涨!贝莱德拟推出代币化基金BUIDL!
- 资产管理巨头贝莱德(BlackRock)成功推出了比特币现货ETF—IBIT,目前该基金持有的比特币价值已超过150亿美元,仅次于GBTC。去年11月,该公司也申请推出以太坊现货ETF,但目前已经两次推迟。贝莱德与Securitize合作推出代币化基金最近,贝莱德再次向美国证券交易委员会(SEC)提交了表格D文件,计划与美国数字资产代币化公司Securitize合作,推出BlackRockUSDInstitutionalDigitalLiquidity(贝莱德美元机构数字流动性)基金。这一举动
- 5天前 虚拟货币 区块链 比特币 代币 0
-
 正版软件
正版软件
- 比特币杠杆怎么计算
- 比特币杠杆计算什么是比特币杠杆?比特币杠杆是指借贷资金来提高交易规模的一种交易策略。杠杆交易允许交易者以超过其账户可用资金的金额进行交易,从而放大潜在利润和亏损。杠杆计算公式比特币杠杆的计算公式如下:杠杆率=交易金额/借贷金额交易金额:杠杆交易的总价值。借贷金额:从交易所借用的金额。例如:假设一个交易者以50,000美元的杠杆率进行交易,借贷金额为10,000美元,则其交易金额为:交易金额=50,000美元x10,000美元=500,000美元这意味着交易者以超过其可用资金50倍的金额进行交易。影响杠杆计
- 5天前 0
-
 正版软件
正版软件
- 比特币钱包的地址是什么
- 比特币钱包地址是比特币网络中独特的标识符,用于接收和发送比特币。地址格式介于26到35个字符之间,以数字1或3开头。有两种主要类型的地址:P2PKH(最常见)和P2SH(更复杂)。地址通过使用公钥和私钥,并应用哈希函数而生成。比特币地址设计得很安全,但需要保护私钥以确保资金安全。
- 5天前 0
-
 正版软件
正版软件
- 比特币挖矿公司在减半前将设备运往海外
- 随着即将到来的比特币(BTC)减半事件的预期,美国数千台过时的比特币挖矿机正在准备运往海外。据彭博社报道,加密货币挖矿行业的批发商SunnySideDigital正在将约6,000台较旧的比特币挖矿机运往其位于科罗拉多斯普林斯的仓库。该公司计划翻新并转售这些机器给海外买家,特别是在能源成本较低的地区。根据SunnySideDigital首席执行官TarasKulyk的说法,这一决定是对减半事件的必然反应。购买者正在寻找能够降低电力成本的地方。由于这些国家拥有有利的能源成本,如埃塞俄比亚、坦桑尼亚、巴拉圭和
- 5天前 设备 比特币挖矿 海外运营 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1853天前
-
 2
2
- Overture设置踏板标记的方法
- 1690天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1680天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1878天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1844天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1840天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1855天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1876天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00