携手合拼:羊驼的结合,登顶HuggingFace
 发布于2024-10-30 阅读(0)
发布于2024-10-30 阅读(0)
扫一扫,手机访问
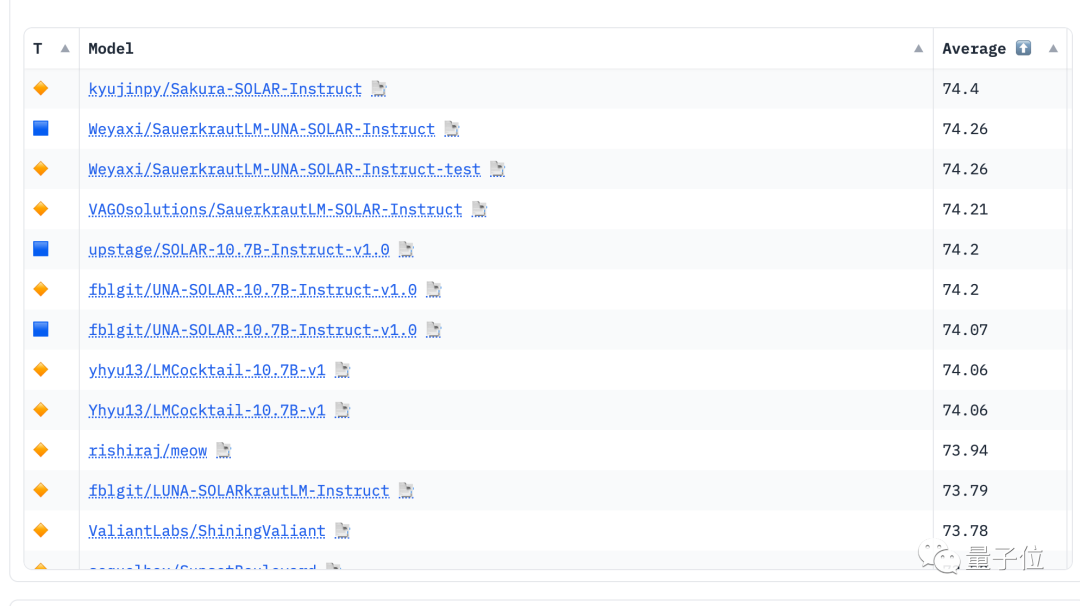
HuggingFace开源大模型排行榜,又被屠榜了。
前排被清一色的SOLAR 10.7B微调版本占据,把几周之前的各种Mixtral 8x7B微调版本挤了下去。
SOLAR大模型什么来头?
相关论文刚刚上传到ArXiv,来自韩国公司Upstage AI,使用了新的大模型扩展方法depth up-scaling(DUS)。

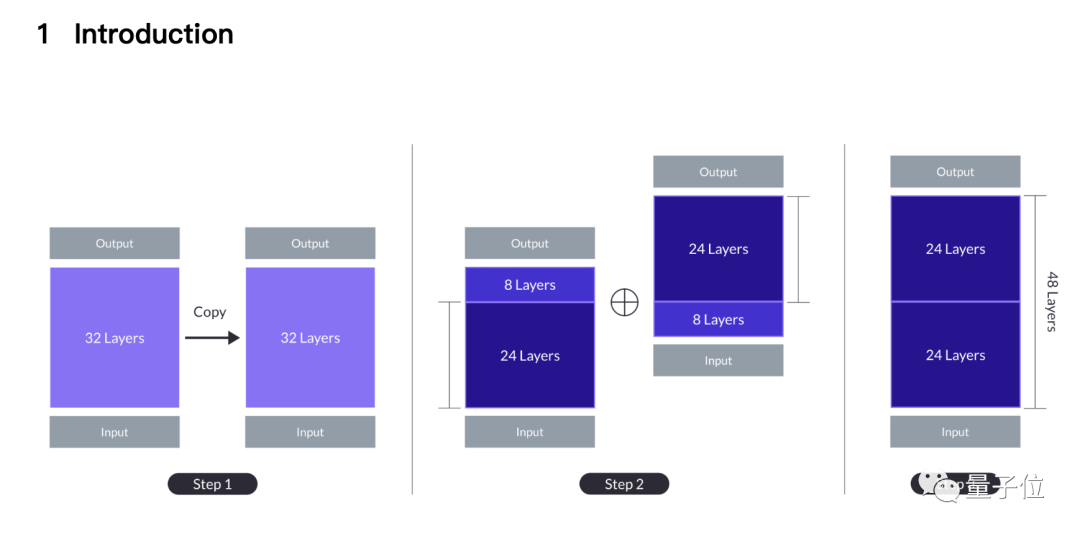
简单来说就是两只7B羊驼掐头去尾,一只砍掉前8层,一只砍掉后8层。
剩下两个24层缝合在一起,第一个模型的第24层与第二个模型的第9层拼接,最后变成新的48层10.7B大模型。
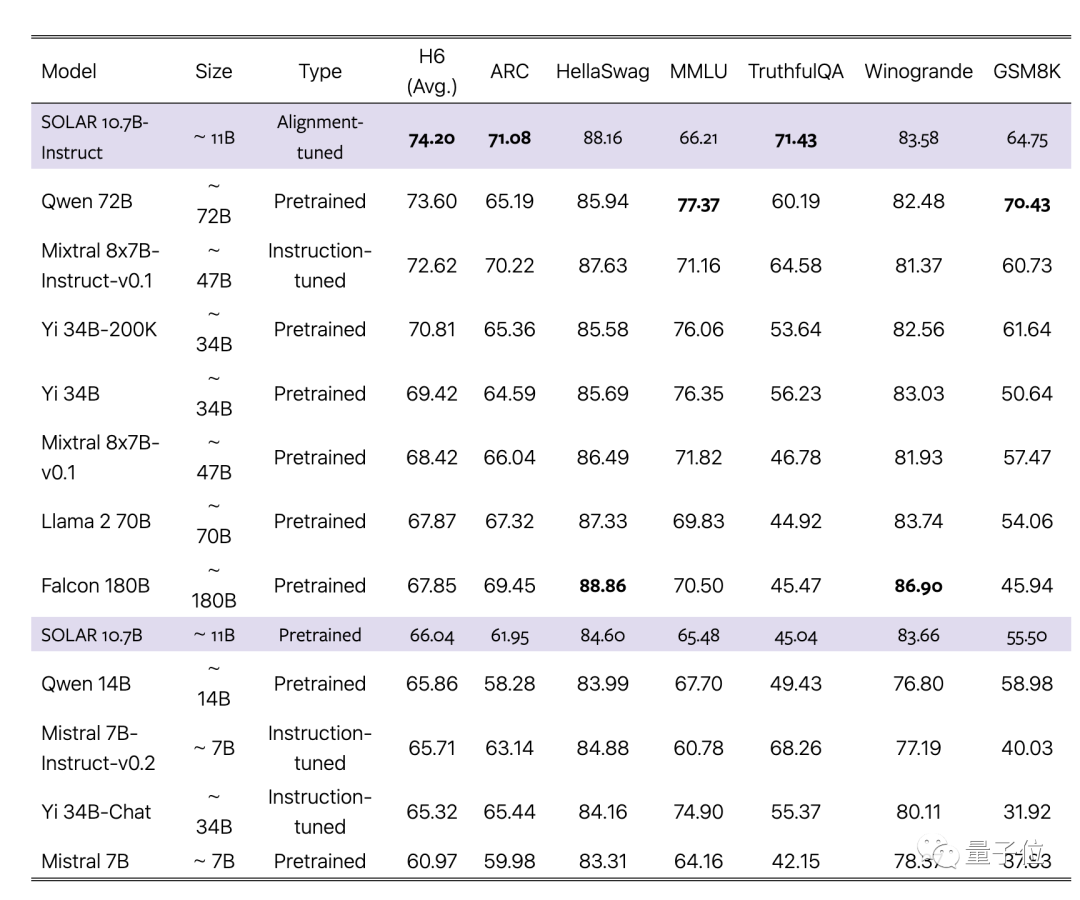
论文声称新方法超过传统扩展方法如MoE,而且可以与沿用基础大模型完全相同的基础设施。
不需要门控网络等附加模块,针对MoE优化训练框架了,也不需要自定义CUDA内核来快速推理,可以无缝集成到现有方法中,同时保持高效。
团队选择7B规模最强的单体大模型Mistral 7B作为底材,用新方法拼接起来,再超越原版以及MoE版。
同时,经过对齐的Instruct版本也超越对应的MoE Instruct版本。
将缝合进行到底
为什么是这种拼接方式,论文中介绍来自一种直觉。
从最简单的扩展方式开始,也就是把32层的基础大模型重复两次,变成64层。
这样做的好处是不存在异质性,所有层都来自基础大模型,但第32层和第33层(与第1层相同)的接缝处有较大的“层距离”(layer distance)。
之前有研究表明,Transformer不同层做不同的事,如越深的层擅长处理越抽象的概念。
团队认为层距离过大可能妨碍模型有效利用预训练权重的能力。
一个潜在的解决方案是牺牲中间层,从而减少接缝处的差异,DUS方法就从这里诞生。
根据性能与模型尺寸的权衡,团队选择从每个模型中删除8层,接缝处从32层连第1层,变成了24层连第9层。
简单拼接后的模型,性能一开始还是会低于原版基础模型,但经过继续预训练可以迅速恢复。
在指令微调阶段,除了使用开源数据集,还制作了数学强化数据集,对齐阶段使用DPO。
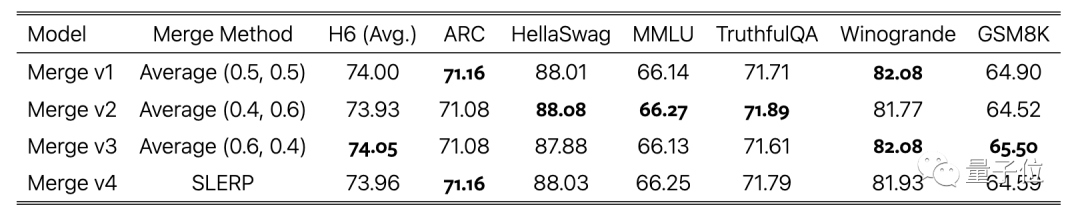
最后一步,把使用不同数据集训练的模型版本加权平均,也是把缝合进行到底了。
有网友质疑测试数据泄露的可能性。

团队也考虑到这一点,在论文附录中专门报告了数据污染测试结果,显示出低水平。

最后,SOLAR 10.7B基础模型和微调模型都以Apache 2.0协议开源。
试用过的网友反馈,从JSON格式数据中提取数据表现不错。

论文地址:https://arxiv.org/abs/2312.15166
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
正版软件
- 一汽丰田2023年汽车产量超过80万,新能源车型销量大幅增长
- 12月31日消息,与往常不同,多家车企选择在年末“提前交卷”,公布了他们的产销战报。岚图汽车昨天公布了12月部分车型的销量,而一汽丰田今天则揭晓了他们在2023年的汽车产量成绩。这一举动引起了广泛关注,让人们对整个汽车行业的发展趋势产生了更大的兴趣。根据一汽丰田的数据显示,他们在今年成功生产了802,666台汽车。其中,混合动力车型的增长率达到了27%,而新能源车型的增幅更是高达187%。这一数据显示一汽丰田在新能源汽车领域取得了显著进展。然而,据路透社和日本时事通信社的报道,丰田汽车此前曾公布将停止在中
- 12分钟前 0
-
 正版软件
正版软件
- 《EXTERMINATOR》Steam页面上线 机器人定制战斗
- 《EXTERMINATOR》Steam页面上线机器人定制战斗SamanSpades开发并发行了一款名为《EXTERMINATOR》的机器人定制对战新游戏,该游戏的Steam页面已经上线,预计于2024年3月正式推出。不过需要注意的是,该游戏暂时不支持中文《EXTERMINATOR》是由个人独立游戏开发者SamanSpades耗时两年多打造的机器人定制战斗游戏,游戏的对战舞台是华丽光怪的沙盒空间,目前总计有10个类型各异的特色任务,想要通关每隔任务至少需要40分钟的时间。玩家可以逐步通关解锁新任务,获得更好
- 17分钟前 0
-
 正版软件
正版软件
- AndesGPT加持!Find X7带来强大AI表现
- 从2022年底开始,人工智能(AI)迅速蔓延全球,成为全球关注的焦点之一。作为智能产品,手机也需要变得更加智慧。因此,手机厂商们也积极努力不懈地提升手机的AI能力。1月8日,OPPO隆重推出了FindX7系列,这一高端旗舰系列不仅在性能、影像、屏幕等方面取得了巨大突破,而且其AI能力的显著增强也成为了手机界的一大亮点。我们之前已经得知,FindX7系列将推出行业首个在端侧部署的70亿参数大模型。通过"端云协同"架构,该系列能够实现本地与云端协同运作,从而为FindX7系列带来全新的智能能力。OPPO的安第
- 32分钟前 0
-
正版软件
- 东城区成立人工智能产业联盟,推进智能化生态系统的建设
- 47分钟前 0
-
 正版软件
正版软件
- 预计2024年推出的革命性AR眼镜原型“Orion”的Meta
- 12月24日消息,meta,一家在社交媒体界有着巨大影响力的科技企业,现正将其雄厚的期望寄托于增强现实(AR)眼镜,一种被认为是下一代计算平台的技术。近期,meta的技术主管安德鲁・博斯沃思(AndrewBosworth)在一次采访中透露,该公司有望在2024年推出一款代号为“Orion”的先进AR眼镜原型。长期以来,meta在AR技术上的投入丝毫不亚于其他领域,他们投入了巨额资金,达数十亿美元,旨在打造一款能与iPhone相媲美的革命性产品。尽管去年他们宣布终止Orion眼镜的大规模生产计划,转而将这款
- 1小时前 12:35 Meta 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1785天前
-
 2
2
- Overture设置踏板标记的方法
- 1622天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1612天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1810天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1776天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1772天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1787天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1808天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00