谷歌DeepMind:大规模机器人重构揭秘具体化智能的未来
 发布于2024-10-31 阅读(0)
发布于2024-10-31 阅读(0)
扫一扫,手机访问
过去一年中,连连取得突破的大模型正在重塑机器人研究领域。
随着最先进的大模型成为机器人的"大脑",机器人的进化速度超乎想象。
7 月,谷歌 DeepMind 宣布推出 RT-2:全球第一个控制机器人的视觉 - 语言 - 动作(VLA)模型。
只需要向对话一样下达命令,它就能在一堆图片中辨认出霉霉,送给她一罐「快乐水」。

甚至能主动思考,完成了从「选择灭绝的动物」到抓取桌子上的塑料恐龙这种多阶段推理的飞跃。

在 RT-2 之后,谷歌 DeepMind 又提出了 Q-Transformer,机器人界也有了自己的 Transformer 。Q-Transformer 使得机器人突破了对高质量的演示数据的依赖,更擅长依靠自主「思考」来积累经验。
RT-2 发布仅两个月,又迎来了机器人的 ImageNet 时刻。谷歌 DeepMind 联合其他机构推出了 Open X-Embodiment 数据集,改变了以往需要针对每个任务、机器人具体定制模型的方法,将各种机器人学的知识结合起来,创造出了一种训练通用机器人的新思路。
可以想象一下,只需向你的机器人小助理发出简单的要求,比如「打扫房子」或「做一顿美味健康的饭菜」,它们就可以完成这些任务。对于人类来说,这些工作可能很简单,但对于机器人来说,需要它们对世界有深度理解,这并非易事。
基于在机器人 Transformer 领域深耕多年的研究基础, 近期,谷歌宣布了一系列机器人研究进展:AutoRT、SARA-RT 和 RT-Trajectory,它们能够帮助机器人更快地做出决策,更好地理解它们身处于怎样的环境,更好地指导自己完成任务。
谷歌相信随着 AutoRT、SARA-RT 和 RT-Trajectory 等研究成果的推出,能为现实的世界机器人的数据收集、速度和泛化能力带来增益。
接下来,让我们回顾一下这几项重要研究。
AutoRT:利用大型模型更好地训练机器人
AutoRT 结合了大型基础模型(如大型语言模型(LLM)或视觉语言模型(VLM))和机器人控制模型(RT-1 或 RT-2),创建了一个可以在新环境中部署机器人用以收集训练数据的系统。AutoRT 可以同时指导多个配备了视频摄像机和末端执行器的机器人,在各种各样环境中执行多样化的任务。
具体来说,每个机器人将根据 AutoRT,使用视觉语言模型(VLM)来「看看四周」,了解其环境和视线内的物体。接下来,大型语言模型会为其提出一系列创造性任务,例如「将零食放在桌子上」,并扮演决策者的角色,为机器人选择需要执行的任务。
研究人员在现实世界中对 AutoRT 进行了长达七个月的广泛评估。实验证明,AutoRT 系统能够同时安全地协调多达 20 个机器人,最多时共能协调 52 个机器人。通过指导机器人在各种办公楼内执行各种任务,研究人员收集了涵盖 77,000 个机器人试验,6,650 个独特任务的多样化数据集。
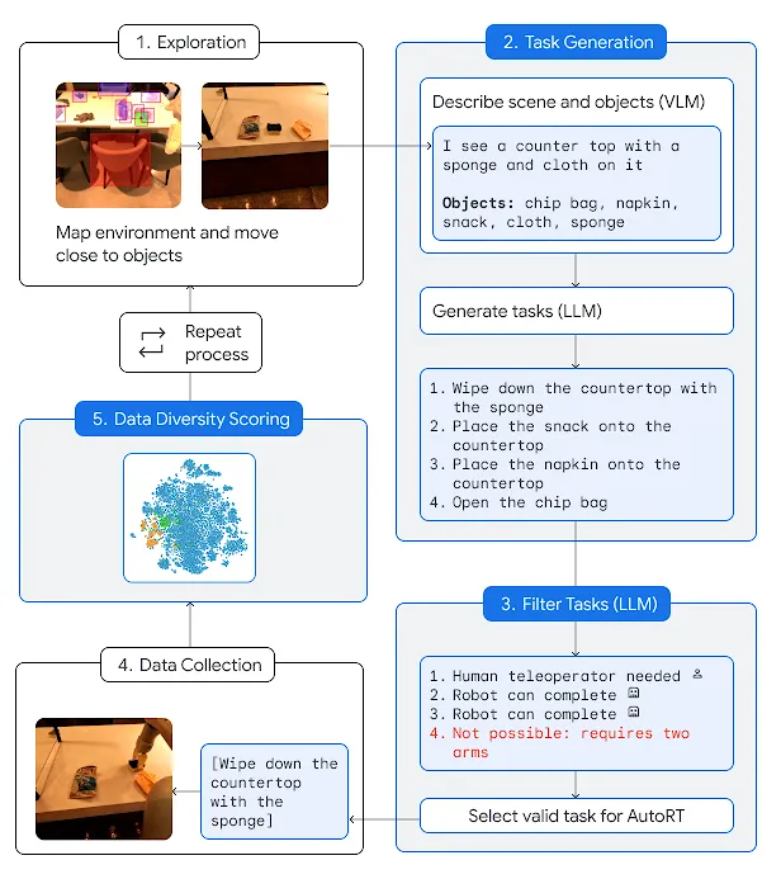
上图呈现了 AutoRT 系统的运作过程:(1)自主轮式机器人找到了一个有多个物体的位置。(2)VLM 向 LLM 描述场景和物体。(3)LLM 为机器人提出各种操作任务,并决定哪些任务机器人可以独立完成,哪些任务需要人类远程控制,哪些任务不可能完成,然后做出选择。(4)机器人尝试选择要做的任务,收集实验数据,并对数据的多样性和新鲜度进行评分。机器人将不断重复这个过程。
AutoRT 具有利用大型基础模型的潜力,这对于机器人理解实际应用中的人类指令至关重要。通过收集更全面的实验训练数据和更多样化的数据,AutoRT 能够扩展机器人的学习能力,为现实世界的机器人训练带来提升。
在机器人融入我们的日常生活之前,需要保证它们的安全性,这要求研究者做到负责任地开发,并对机器人的安全性进行深度研究。
虽然 AutoRT 现在只是一个数据收集系统,但可以将其视为现实世界中自主机器人的早期阶段。它具有安全护栏,其中一项是一套以安全为重点的提示词,它能够在机器人执行基于 LLM 的决策时提供需要遵守的基本规则。
这些规则部分受到艾萨克・阿西莫夫的机器人三定律的启发,其中最重要的是机器人「不得伤害人类」。安全规则还要求机器人不得尝试涉及人类、动物、尖锐物体或电器的任务。
仅在提示词方面下功夫,也无法完全保证机器人实际应用中的安全问题。因此,AutoRT 系统还包含实用安全措施层这一机器人技术的经典设计。例如,协作机器人的程序被设定为如果其关节上的力超过给定阈值,则自动停止,并且所有自主控制的机器人都能够通过物理停用开关被限制在人类监督员的视线范围内。
SARA-RT:让机器人 Transformer(RT)变得更快、更精简
另一项成果 SARA-RT,可将机器人 Transformer(RT)模型转换为更高效的版本。
谷歌团队开发的 RT 神经网络架构已被用于最新的机器人控制系统,包括 RT-2 模型。最好的 SARA-RT-2 模型在获得简短的图像历史记录后,比 RT-2 模型的精确度高 10.6%,速度快 14%。谷歌表示,这是首个在不降低质量的情况下提高计算能力的可扩展注意力机制。
虽然 Transformer 功能强大,但它们可能会受到计算需求的限制,从而减慢决策速度。Transformer 主要依赖于二次复杂度的注意力模块。这意味着,如果 RT 模型的输入增加一倍(例如,为机器人提供更多或更高分辨率的传感器),处理该输入所需的计算资源就会增加四倍,从而导致决策速度减慢。
SARA-RT 采用了一种新颖的模型微调方法(称为「向上训练」)来提高模型的效率。向上训练将二次复杂性转换为单纯的线性复杂性,从而大幅降低了计算要求。这种转换不仅能提高原始模型的速度,还能保持其质量。
谷歌希望许多研究人员和从业人员能将这一实用系统应用于机器人技术及其他领域。由于 SARA 提供了加快 Transformer 速度的通用方法,无需进行计算成本高昂的预训练,因此这种方法具有大规模推广 Transformer 技术的潜力。SARA-RT 不需要任何额外的代码,因为可以使用各种开源的线性变体。
当 SARA-RT 应用于拥有数十亿个参数的 SOTA RT-2 模型,它能在各种机器人任务中实现更快的决策和更好的性能:

用于操纵任务的 SARA-RT-2 模型。机器人的动作以图像和文本指令为条件。
凭借其坚实的理论基础,SARA-RT 可应用于各种 Transformer 模型。例如,将 SARA-RT 应用于点云 Transformer(用于处理来自机器人深度摄像头的空间数据),其速度能够提高一倍以上。
RT-Trajectory:帮助机器人泛化
人类可以直观地理解、学会如何擦桌子,但机器人需要许多可能的方式将指令转化为实际的物理动作。
传统上,对机械臂的训练依赖于将抽象的自然语言(擦桌子)映射到具体的动作(关闭抓手、向左移动、向右移动),这使得模型很难推广到新任务中。与此相反,RT - 轨迹模型通过解释具体的机器人动作(如视频或草图中的动作),使 RT 模型能够理解 「如何完成」任务。
RT-Trajectory 模型能自动添加视觉轮廓,描述训练视频中的机器人动作。RT-Trajectory 将训练数据集中的每段视频与机器人手臂执行任务时抓手的 2D 轨迹草图叠加在一起。这些轨迹以 RGB 图像的形式,为模型学习机器人控制策略提供了低层次、实用的视觉提示。
在对训练数据中未见的 41 项任务进行测试时,由 RT-Trajectory 控制的机械臂的性能比现有的 SOTA RT 模型高出一倍多:任务成功率达到 63%,而 RT-2 的成功率仅为 29%。
该系统的用途十分广泛,RT-Trajectory 还可以通过观看人类对所需任务的演示来创建轨迹,甚至可以接受手绘草图。而且,它还能随时适应不同的机器人平台。
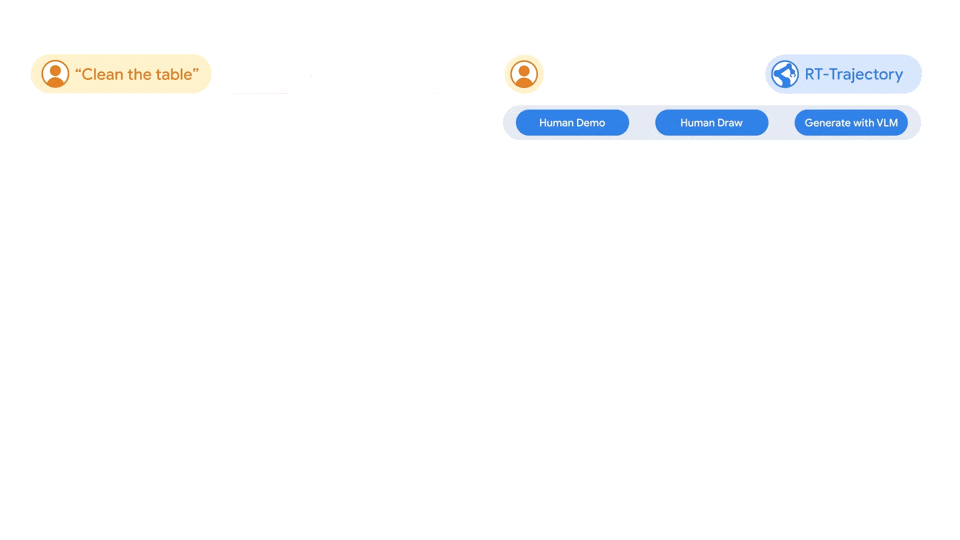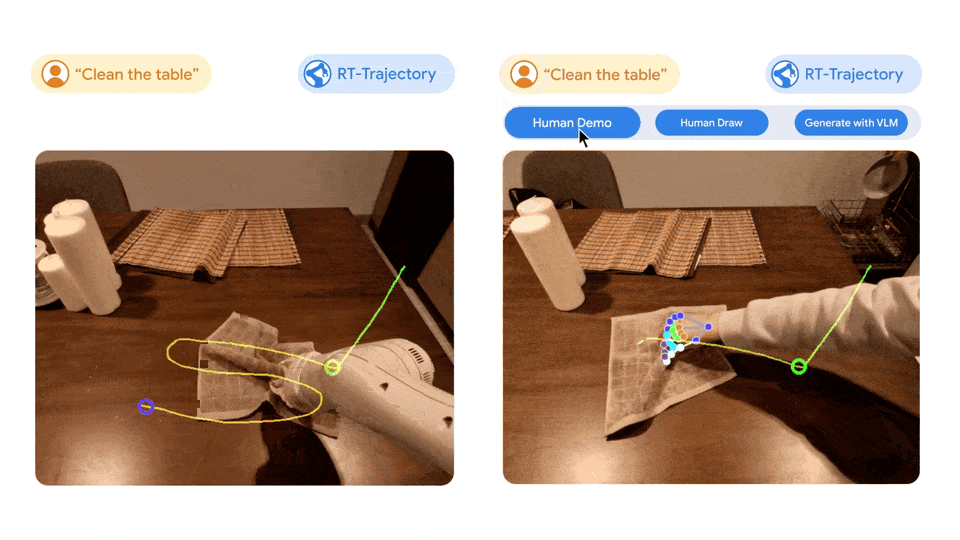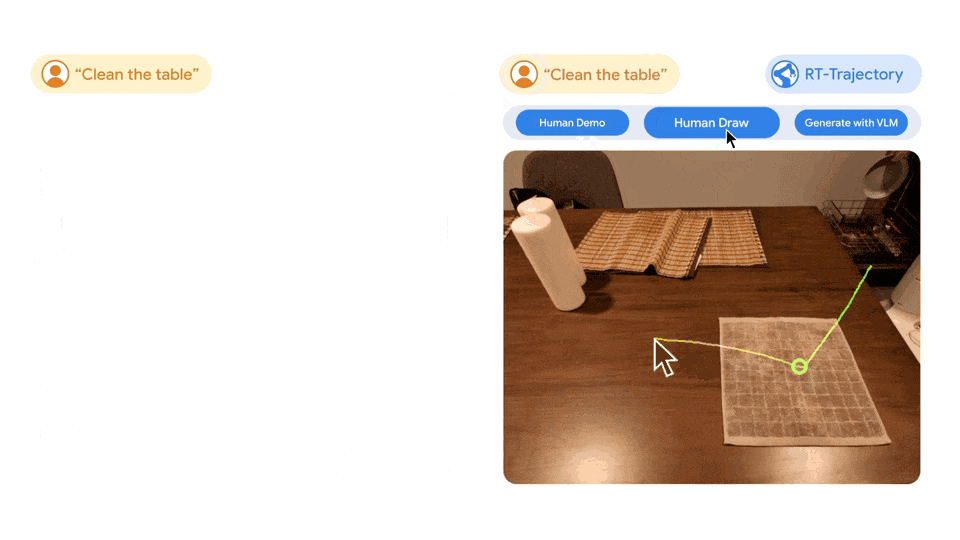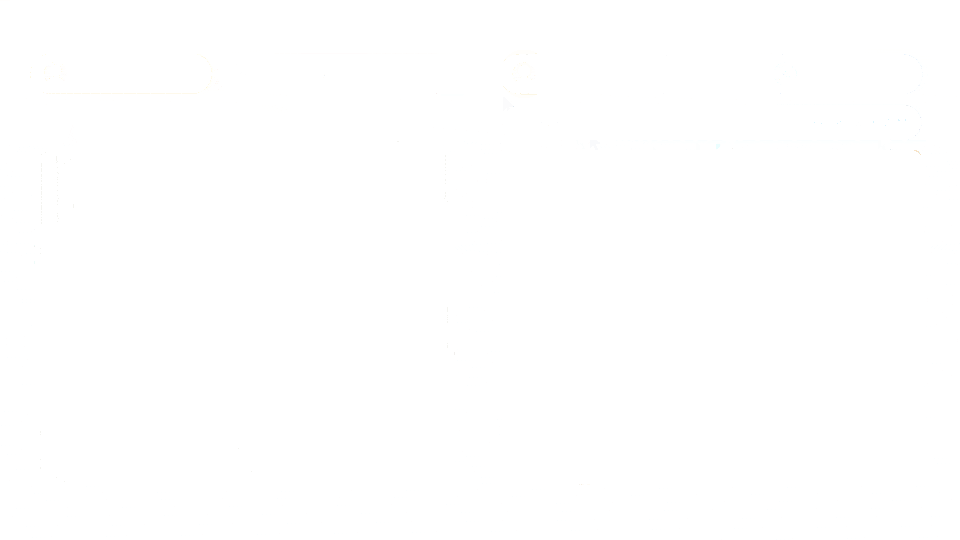 左图:只使用自然语言数据集训练的 RT 模型控制的机器人,在执行擦桌子这一新任务时受挫,而由 RT 轨迹模型控制的机器人,在经过 2D 轨迹增强的相同数据集训练后,成功规划并执行了擦拭轨迹。右图:训练有素的 RT 轨迹模型在接到新任务(擦桌子)后,可以在人类的协助下或利用视觉语言模型自行以多种方式创建 2D 轨迹。
左图:只使用自然语言数据集训练的 RT 模型控制的机器人,在执行擦桌子这一新任务时受挫,而由 RT 轨迹模型控制的机器人,在经过 2D 轨迹增强的相同数据集训练后,成功规划并执行了擦拭轨迹。右图:训练有素的 RT 轨迹模型在接到新任务(擦桌子)后,可以在人类的协助下或利用视觉语言模型自行以多种方式创建 2D 轨迹。
RT 轨迹利用了丰富的机器人运动信息,这些信息存在于所有机器人数据集中,但目前尚未得到充分利用。RT-Trajectory 不仅代表着在制造面向新任务高效准确移动的机器人的道路上又迈进了一步,而且还能从现有数据集中发掘知识。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Steam 改进策略:支持发布更多的 AI 游戏并提升内容审核力度
- IT之家1月10日消息,Valve的数字游戏分发平台Steam近日发布公告,宣布对相关政策进行微调,以支持更多使用AI技术的游戏。划分使用AI技术的游戏当开发者向Steam提交游戏时,需要填写新的内容调查表格。最新的调查表格中包含了一个全新的部分,即AI内容披露。在这一部分,开发者需要详细描述他们在游戏开发和运行过程中如何应用AI技术。这个新的要求旨在增加透明度,让玩家了解游戏中的AI功能和其对游戏体验的影响。开发者应该清楚地解释他们使用AI的目的以及它在游戏中的具体应用。这样一来,玩家就能更好地理解游戏
- 4分钟前 0
-
 正版软件
正版软件
- 《Talk Changsha》第十期《长沙智造:工业AI未来可期》即将呈现!
- 看见长沙连通世界SeeingChangshaLinkingtheWorld湖南首档全英文国际经贸访谈节目《TalkChangsha》第十期即将呈现!ThetenthissueofthefirstEnglish-languagebusinesstalkshowfromHunanChina-TalkChangsha-iscomingsoon!湖南广播电视台国际频道将于1月10日播出由中国国际贸易促进委员会长沙支会和中国国际商会长沙商会联合摄制的湖南首档全英文国际经贸访谈节目《TalkChangsha》第十期。
- 9分钟前 0
-
 正版软件
正版软件
- 小米集团任命首位女性独立非执行董事-蔡金青
- 小米集团今日发布公告,宣布蔡金青将担任独立非执行董事、董事会提名委员会及企业管治委员会成员,该任命将于2024年1月8日生效。同时,唐伟章因计划投入更多时间于其他事务,已辞去独立非执行董事、董事会提名委员会主席及企业管治委员会成员的职位。蔡金青女士自2018年起担任开云集团大中华区总裁。她是一位备受赞誉的商界女性,曾荣获多项荣誉,包括被福布斯中国评选为“杰出商界女性100强”,财富中文网评选为“中国最具影响力的商界女性”,以及预计在2023年入选《财富》中国最具影响力的商界女性榜单。这些殊荣充分证明了她在
- 24分钟前 小米集团 0
-
 正版软件
正版软件
- 中国首艘大型邮轮“爱达・魔都号”成功首航
- 本站1月7日消息,今日,国产首艘大型邮轮“爱达・魔都号”顺利完成首航,3000余名来自16个国家和地区的乘客完成了7天6晚前往韩国济州与日本福冈、长崎等地的品质之旅。参考本站此前报道,“爱达・魔都号”于1月1日正式从上海吴淞口国际邮轮港出发,执航上海至东北亚经典旅游目的地的国际邮轮航线。“爱达・魔都号”首航售价4930元/人起,共7天6晚,航线为上海-济州(西归浦)-长崎-福冈-上海。据介绍,“爱达・魔都号”总吨位13.55万吨,长323.6米,宽37.2米,最大高度72.2米,全船共有15层甲板,房舱2
- 39分钟前 旅行 邮轮 0
-
 正版软件
正版软件
- 智能宠物追踪器 Minitailz:照顾猫狗健康与监测实时位置的AI技术亮相
- Invoxia公司在CES2024中发布了一款名为Minitailz的智能宠物追踪器,这款设备是专为猫狗设计的AI可穿戴设备。售价为99美元(约合709元人民币),此外,用户还需要每月支付8.3美元(约合59元人民币)的订阅费才能使用相关服务。(来源:IT之家)据悉,Minitailz追踪器内置了一体式GPS和健康追踪器,可以准确识别宠物的步行、跑步、抓挠、吃喝、吠叫和休息等行为方式。此外,它还能结合宠物的呼吸频率和心脏体征,通过AI技术测量宠物的健康情况,并提醒主人可能存在的健康问题。这款追踪器为主人提
- 54分钟前 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1786天前
-
 2
2
- Overture设置踏板标记的方法
- 1623天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1613天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1811天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1777天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1773天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1788天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1809天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00