大规模模型在星际争霸中的技艺到底有多高?研究人员和汪军团队的最新发布
 发布于2024-10-31 阅读(0)
发布于2024-10-31 阅读(0)
扫一扫,手机访问


在星际争霸 II 的战场上,进行有效决策意味着需要及时处理大量复杂的信息,进行合理的战略分析与长期规划,最终制定宏观战略决策。这让团队面临着巨大的挑战。原有的 CoT (Chain of Thought) 及其改进方法,在 TextStarCraft II 环境中遭遇了三个主要问题:无法完全理解复杂的游戏信息,难以分析战局的走向,以及不足以提出有用的策略建议。
为了应对这些挑战,我们的团队提出了一种创新的方法,称为「Chain of Summarization」。这种方法由两个核心组成部分组成:单帧总结和多帧总结。 在单帧总结中,我们侧重于将观测到的游戏信息进行压缩和提取,将其转化为简洁而富含语义的结构化数据,以便于LLM(Language Model)的理解和分析。 而多帧总结则受到计算机硬件缓存机制和强化学习中跳帧技术的启发。它通过同时处理多步观测信息,弥补了快节奏的游戏和LLM推理速度之间的差异,从而提高了LLM在复杂环境中的理解和决策能力。这种方法能够帮助LLM更好地适应游戏的节奏,并更准确地进行推理和决策。
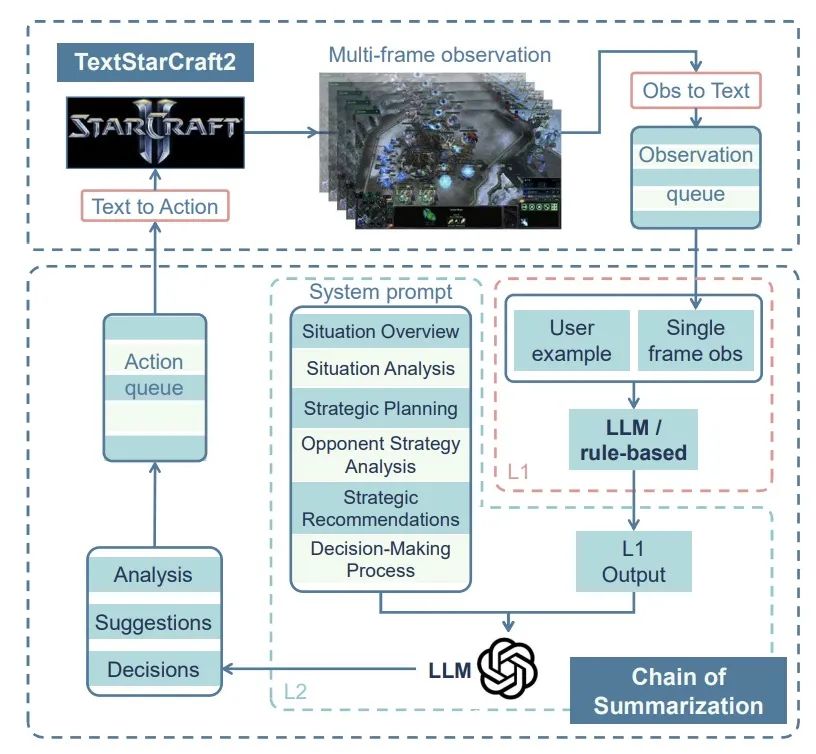 图1:Chain of Summarization 框架。
图1:Chain of Summarization 框架。
Complex Prompt System:构建智慧的桥梁
为了帮助 LLM 在实时战略决策中更加高效,我们的团队设计了一个复杂的提示词系统。这个系统包括四个主要部分:游戏状态总结、状态分析、策略建议和最终决策。通过这个系统,我们可以迅速总结当前的游戏状态,对状态进行深入分析,给出相应的策略建议,并最终做出决策。这套系统的设计旨在提供有价值的信息,帮助 LLM 在实时战略中做出明智的选择。
通过这种方法,模型能够全面理解游戏的当前状态,分析双方的策略,并给出具有战略深度的建议,最终做出多步的合理决策。这不仅大大提高了LLM的实时决策和长期规划能力,还显著提高了决策的可解释性。在后续的实验中,LLM代理展现了前所未有的智能水平。


 2. 加速研发科技
2. 加速研发科技  3. 前期侦察
3. 前期侦察  4. 加速生产工人
4. 加速生产工人  5. 防御与反击
5. 防御与反击  6. 侦测单位侦察
6. 侦测单位侦察 
为了进一步了解LLM在玩星际争霸II中表现出色的原因,研究团队提出了一个假设:这些LLM在预训练阶段可能已经学习到了与星际争霸II相关的知识。
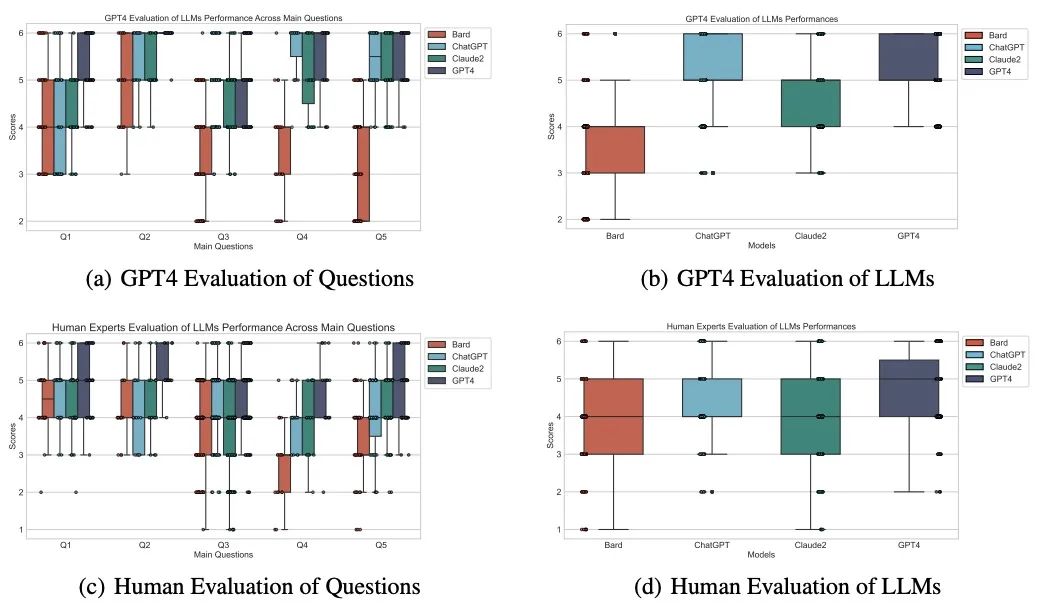
为了验证这个假设,研究团队设计了一系列问题,涵盖了星际争霸 II 的基础知识、种族机制、典型战术、标准开局以及战术应对等方面。这些问题的答案由一组人类专家(包括大师和宗师级选手)和GPT-4进行双盲评分,以评估不同模型对星际争霸 II 知识的掌握程度。
根据实验结果显示的图表,我们可以观察到一个有趣的现象:这些模型在不同程度上对星际争霸 II 的相关知识有一定的掌握,其中 GPT-4 在理解和回答这些问题方面表现尤为出色。这个发现不仅验证了我们团队的假设,也为我们对于 LLM agent 在复杂现实场景中的应用提供了新的视角。
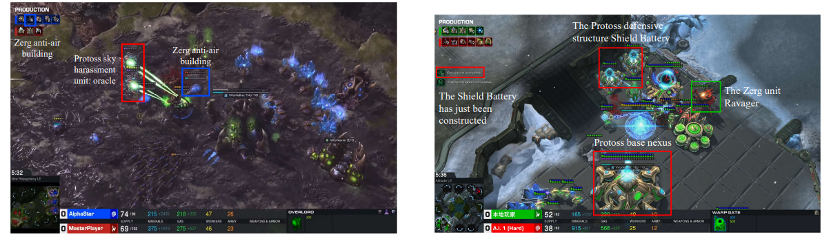
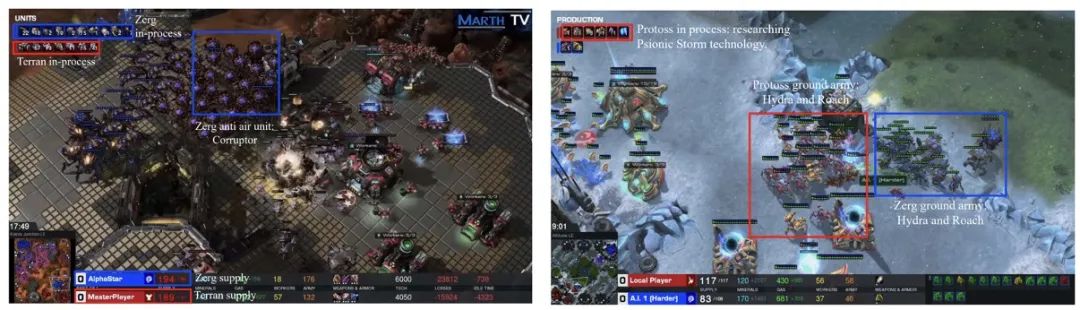
LLM(Language Model)代理是一种基于人工智能技术的语言模型代理,它具有广阔的潜力和应用前景。未来,LLM代理有望在许多领域发挥重要作用。 首先,LLM代理可以应用于自然语言处理领域。它可以用于机器翻译、语音识别、情感分析等任务,
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 强震导致日本多家半导体工厂停产检修,初步评估认为影响可控
- 本站1月3日消息,集邦咨询近日发布报告,称本次日本强震导致当地多家半导体工厂停产,不过初步排查结果显示机台并未受到严重灾损,研判影响可控。关于晶圆厂方面,新潟县的信越化学工业(Shin-Etsu)和环球晶圆(GlobalWafers)目前正进行停机检查。在矽晶圆(RawWafer)制程中,长晶(CrystalGrowth)对地震摇晃最为敏感。然而,幸运的是,信越公司的长晶厂区主要位于福岛地区,因此受到本次地震的影响相对有限。位于石川县西南部的Toshiba加贺(Kaga)工厂是一家半导体厂。该工厂拥有一座
- 2分钟前 晶圆 0
-
 正版软件
正版软件
- 甲子光年:AI加速追赶,演进之道
- 随着人工智能等应用需求不断增长,推广先进存储技术势在必行人工智能的发展日新月异,其中的算力和算法也在快速迭代。相比之下,数据的进展相对缓慢,出现了短板效应。特别是在大型模型不断涌现、数据处理需求持续增长的现阶段,数据存储成为了拖累的显著因素,迫切需要先进存储技术的引入赛迪最新发布的《中国先进存力发展研究报告》(下称“报告”)指出,目前中国存力发展存在一定“被忽视”现象,预计到2025年,将有超过420EB的巨大存力缺口亟待补充。与此同时,以曙光存储为代表的一线厂商在持续发力“先进存力”,为存力赛道的进阶探
- 17分钟前 AI大步向前 0
-
 正版软件
正版软件
- 2023年第三季度晶圆代工报告:台积电继续领跑市场,其份额占比达到59%,三星紧随其后,占比为13%
- 市场调查机构CounterpointResearch最近发布了多张信息图,总结了2023年第3季度全球半导体、晶圆代工份额和智能手机应用处理器(AP)份额的情况2023年第3季度晶圆代工收入份额晶圆代工公司收入份额2023年第三季度,全球晶圆代工行业的市场份额呈现出明显的等级。台积电通过提升N3的产能和智能手机的补货需求,以令人印象深刻的59%的市场份额占据了主导地位三星代工排在第二位,占据了13%的市场份额。联电、GlobalFoundries和中芯国际的市场份额相近,各自占据了约6%的份额台积电的显著
- 32分钟前 台积电 半导体 三星 代工 晶圆 0
-
 正版软件
正版软件
- TinyBERT模型解析——压缩BERT模型的精髓
- 译者|朱先忠为了帮助尚未通关的玩家,下面是一些解谜技巧,希望对大家有所帮助。简介近年来,大型语言模型的发展突飞猛进。BERT成为最受欢迎和最有效的模型之一,可以高精度地解决各种自然语言处理(NLP)任务。继BERT模型之后,一组其他的模型也先后出现并各自展示出优秀的性能。不难看到一个明显趋势是,随着时间的推移,大型语言模型(LLM)往往会因其训练的参数和数据数量呈指数级增加而变得更加复杂。深度学习研究表明,这种技术通常会带来更好的运行结果。然而,遗憾的是,尽管机器学习世界已经克服了不少关于大型语言模型相关
- 47分钟前 BERT 0
-
 正版软件
正版软件
- 青云科技和燧原科技合作,推动 AI 异构算力的创新!
- 青云科技与燧原科技达成战略合作,共同创新算力异构资源池的灵活调度,构建支持场景落地的AI算力生态。这一合作将为AI应用的快速落地和算力的普惠提供强大的驱动力。人工智能迅猛发展,推动数字经济进入新阶段。青云科技凭借多年数字化技术积累和运营经验,全面布局AI算力。基于中国企业的应用需求和新兴场景,与国内优秀软硬件厂商合作,打造开放共赢的生态系统,为AI产业创新提供支持。人工智能技术的进步正进入一个全新的阶段,AIGC内容生成类模型正在改变互联网商业模式,推动数字经济的新突破。随着计算任务的多样化和复杂化,异构
- 1小时前 08:20 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1786天前
-
 2
2
- Overture设置踏板标记的方法
- 1623天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1613天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1811天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1777天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1773天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1788天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1809天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00