TinyBERT模型解析——压缩BERT模型的精髓
 发布于2024-10-31 阅读(0)
发布于2024-10-31 阅读(0)
扫一扫,手机访问
译者 | 朱先忠
为了帮助尚未通关的玩家,下面是一些解谜技巧,希望对大家有所帮助。
简介
近年来,大型语言模型的发展突飞猛进。BERT成为最受欢迎和最有效的模型之一,可以高精度地解决各种自然语言处理(NLP)任务。继BERT模型之后,一组其他的模型也先后出现并各自展示出优秀的性能。
不难看到一个明显趋势是,随着时间的推移,大型语言模型(LLM)往往会因其训练的参数和数据数量呈指数级增加而变得更加复杂。深度学习研究表明,这种技术通常会带来更好的运行结果。然而,遗憾的是,尽管机器学习世界已经克服了不少关于大型语言模型相关的问题;但是,可扩展性的问题已经成为有效训练、存储和使用大型语言模型的主要障碍。
考虑到上述问题,人们已经开发出不少的压缩大型语言模型的特殊方法。在这篇文章中,我们将重点讨论转换器蒸馏方法,这种方法诞生了名为TinyBERT的一个迷你版本的BERT模型。此外,我们还将介绍TinyBERT模型的学习过程,以及使TinyBERT模型变得如此强大的几个微妙原因。本文基于TinyBERT的官方论文整理而成。
主要思想
在最近的文章中,我们已经讨论了DistilBERT模型中蒸馏技术的工作原理。简而言之,蒸馏技术的主要思想是:修改损失函数目标,以便使学生模型和教师模型的预测结果相似。在DistilBERT模型中,损失函数比较学生模型和教师模型的输出分布,并兼顾两个模型的输出嵌入(针对相似性损失)。
有关DistilBERT模型的更多的细节,请参考文章《Large Language Models: DistilBERT — Smaller, Faster, Cheaper and Lighter》,地址是:
“https://towardsdatascience.com/distilbert-11c8810d29fc?source=post_page-----1a928ba3082b--------------------------------”。此文的主要内容介绍了BERT模型压缩的秘密,目标是实现师生模型框架效率的最大化。
从表面上看,TinyBERT模型中的蒸馏框架与DistilBERT模型没有太大变化:再次修改了损失函数,目标是使学生模型模仿教师模型。然而,在TinyBERT模型的情况下,它更进了一步:损失函数不仅考虑了师生两个模型产生的结果,还考虑了如何获得预测结果的问题。根据TinyBERT模型论文作者介绍,TinyBERT损失函数由三个部分组成,它们涵盖了师生两个模型的不同方面:
- 嵌入层的输出
- 从转换器层导出的隐藏状态和注意力矩阵
- 预测层输出的logits值
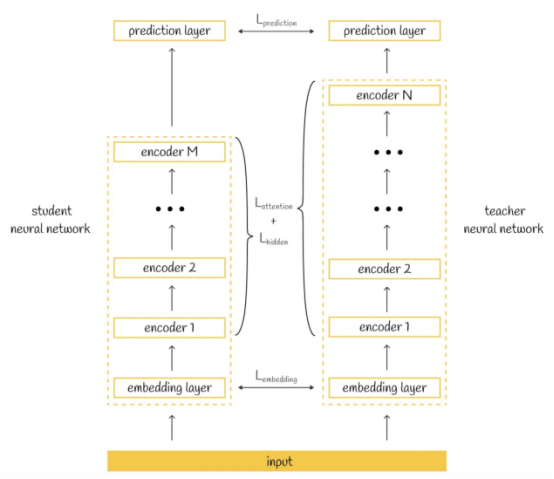 转换器蒸馏损失函数示意图
转换器蒸馏损失函数示意图
那么,比较师生两种模型的隐藏状态有什么意义呢?通过包括隐藏状态和注意力的输出结果,注意力矩阵使得学生模型有可能学习教师模型的隐藏层内容,从而构建与教师模型相似的层。这样,提取的模型不仅可以模仿原始模型的输出,而且模仿其内部行为。
那么,为什么复制教师模型的行为很重要呢?研究人员声称,通过BERT模型学习到的注意力权重有利于捕捉语言结构。因此,它们对另一种模式的蒸馏也给了学生模型更多获得语言知识的机会。
层映射
TinyBERT模型仅代表一种较小的BERT版本,具有较少的编码器层。现在,不妨让我们将BERT模型层数定义为N,将TinyBERT模型层数定义为M。鉴于层数不同,如何计算蒸馏损失值的问题尚不明确。
为此,引入了一个特殊函数n=g(m)来定义哪个BERT模型层n用于将其知识提取到TinyBERT模型中的相应层m。然后,所选择的BERT层用于训练期间的损失值计算。
引入的函数n=g(m)具有两个推理约束:
- g(0)=0。这意味着,BERT模型中的嵌入层被直接映射到TinyBERT模型中的嵌入图层,这是有意义的。
- g(M+1)=N+1。该等式指示,BERT模型中的预测层被映射到TinyBERT模型中的预测层。对于所有其他TinyBERT模型中满足条件1≤m≤m的那些层,需要映射n=g(m)的相应函数值。现在,假设已经定义好了这样的函数。
有关TinyBERT模型设置的问题,将在本文稍后进行研究。
转换器蒸馏
1.嵌入层蒸馏
原始输入在被传递到模型之前,首先被标记化,然后被映射到学习的嵌入层。然后,这些嵌入层被用作模型的第一层。所有可能的嵌入层都可以用矩阵的形式表示。为了比较学生模型和教师模型的嵌入层有多大的不同,可以在他们各自的嵌入矩阵E上使用标准回归度量。例如,转换器蒸馏使用均方误差(MSE)作为回归度量。
由于学生模型和教师模型的嵌入矩阵具有不同的大小,因此不可能通过使用均方误差来明智地比较它们的元素。这就解释了为什么学生模型嵌入矩阵乘以可学习的权重矩阵W,从而导致结果矩阵与教师模型嵌入矩阵具有相同的形状。
 嵌入层蒸馏损失函数。
嵌入层蒸馏损失函数。
由于学生模型和教师模型的嵌入空间是不同的,矩阵W在将学生模型的嵌入空间线性转换为教师模型嵌入空间方面也起着重要作用。
2.转换器层蒸馏
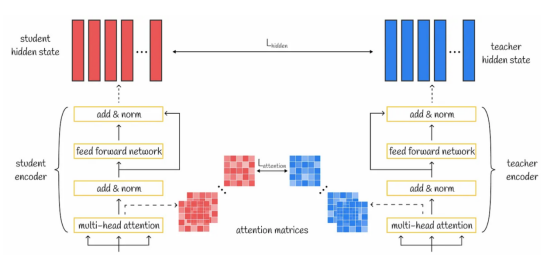 转换器层蒸馏损失函数可视化展示
转换器层蒸馏损失函数可视化展示
2A. 注意力层蒸馏
转换器中的多头注意力机制的核心是生成包含丰富语言知识的多个注意力矩阵。通过转移教师模型的注意力权重,学生模型也可以理解重要的语言概念。为了实现这一思想,使用损失函数来计算学生模型和教师模型注意力权重之间的差异。
在TinyBERT模型中,考虑了所有的注意力层,并且每一层的最终损失值等于所有头部的相应学生模型和教师模型注意力矩阵之间的均方误差值之和。
 注意层蒸馏损失函数计算公式
注意层蒸馏损失函数计算公式
值得注意的是,用于注意力层提取的注意力矩阵A是未归一化的,而不是它们的softmax输出softmax(A)。根据研究人员的说法,这种微妙之处有助于更快地收敛并提高性能。
2B. 隐藏层蒸馏
为了实现获取丰富语言知识的想法,蒸馏操作也被应用到转换器层的输出上。
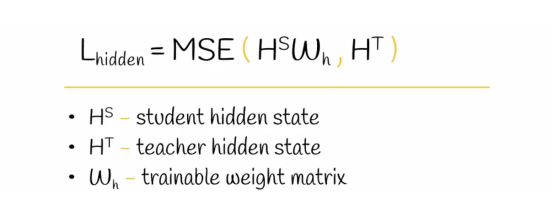 隐藏层蒸馏损失函数计算公式。
隐藏层蒸馏损失函数计算公式。
这里,权重矩阵W起到与上述用于嵌入层蒸馏的权重矩阵相同的作用。
3.预测层蒸馏
最后,为了使学生模型再现教师模型的输出结果,使用了预测层损失函数。它包括计算两个模型预测的logit向量之间的交叉熵。
 预测层蒸馏损失函数计算公式
预测层蒸馏损失函数计算公式
值得注意的是,有些情况下,logits要除以控制输出分布的平滑度的温度参数T。在TinyBERT模型中,温度参数T设置为1。
损失方程
在TinyBERT模型中,根据其类型特征,每一层都有自己的损失函数。考虑到某些层或多或少的重要性作用,将相应的损失值乘以常数a。最终的损失函数等于所有TinyBERT模型层的损失值的加权和。
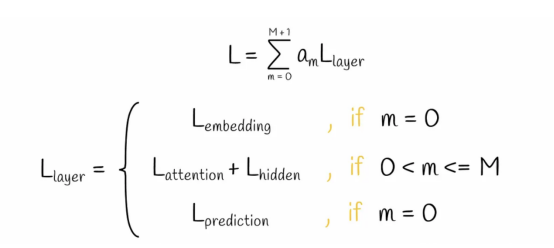 TinyBERT模型中的损失函数计算公式
TinyBERT模型中的损失函数计算公式
大量实验表明,在三种损失分量中,转换器层蒸馏损失对模型性能的影响最大。
模型训练
需要注意的是,大多数自然语言处理模型(包括BERT)开发过程可大致划分为两个阶段:
- 在一个大型数据语料库上对模型进行预训练,以获得语言结构的一般知识。
- 在另一个数据集上对模型进行微调,以解决特定的下游任务。
遵循与此同样的思想,研究人员研发了一个新的框架TinyBERT,它的学习过程也是由类似上面的两个阶段组成的。在这两个训练阶段中,使用转换器蒸馏算法将BERT模型知识转换成TinyBERT模型。
阶段一:普通蒸馏。TinyBERT作为一个教师模型,通过预先训练(无需微调)的BERT模型获得了丰富的语言结构常识。通过使用更少的层和参数,在这个阶段之后,TinyBERT模型的性能通常比BERT模型差一些。
阶段二:特定任务的蒸馏。这一次,微调版的BERT模型扮演了教师模型的角色。为了进一步提高性能,正如研究人员所提出的,在训练数据集上应用了数据增强方法。实验结果表明,经过特定任务的蒸馏操作后,TinyBERT模型在BERT模型方面取得了相当的性能。
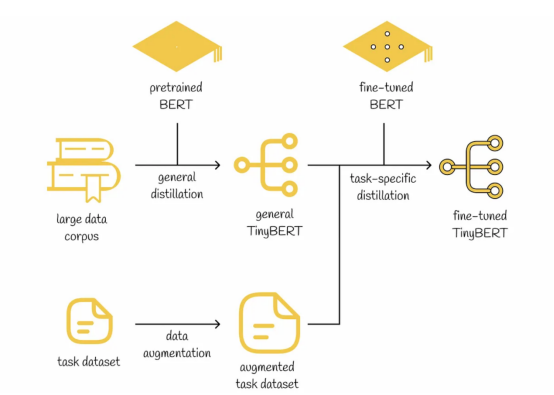 TinyBERT模型训练流程示意图
TinyBERT模型训练流程示意图
数据增强
针对特定任务的蒸馏,引入了一种特殊的数据增强技术。在这种数据增强技术中,首先从给定的数据集中提取序列,然后以下列两种方式之一替换一定百分比的单词:
- 如果某单词被标记为同一个单词,则该单词由BERT模型预测,并且用预测后的结果单词替换序列中的原始单词。
- 如果单词被标记为几个子单词,那么这些子单词将被最相似的GloVe嵌入(全局向量的词嵌入:Global Vectors for Word Representation)所取代。
尽管模型大小显著减小,但是所描述的数据增强机制通过允许TinyBERT学习更多不同的示例,对其性能产生了很大影响。
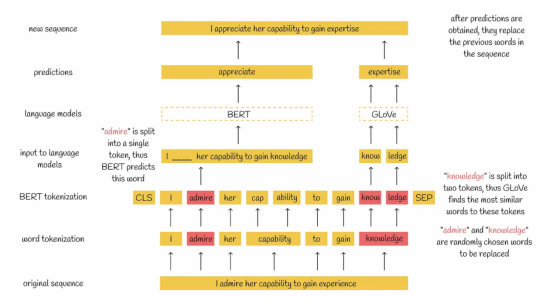 数据增强技术示意图
数据增强技术示意图
模型设置
由于只有14.5M个参数,TinyBERT模型比基础型BERT模型小约7.5倍。它们的详细比较如下图所示:
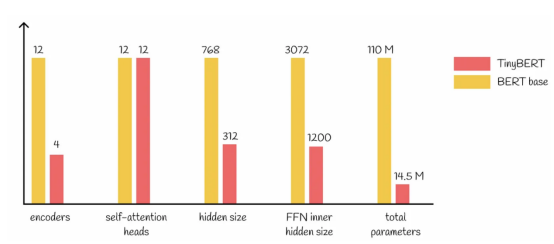 基础BERT模型与TinyBERT模型比较
基础BERT模型与TinyBERT模型比较
对于层映射,论文作者提出了一种统一的策略。根据该策略,层映射函数将每个TinyBERT层映射到按序排序的每三个为一组的BERT层中的第一个:g(m)=3*m。论文作者还研究了其他的策略(如采用所有底部或顶部BERT层),但仅有统一策略显示出最佳实验结果。这个结论似乎是比较合乎逻辑的,因为它允许从不同的抽象层转移知识,使转移的信息更加多样化。
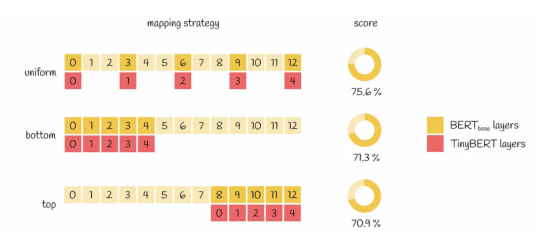 基于不同的层映射策略情况:图中展示了基于GLUE数据集的性能比较结果
基于不同的层映射策略情况:图中展示了基于GLUE数据集的性能比较结果
就训练实现过程方面,TinyBERT模型是在英语维基百科(2500M个单词)上训练的,其大多数超参数与BERT模型库中使用的相同。
结论
转换器蒸馏是自然语言处理中的一项重要措施。考虑到基于转换器的模型是目前机器学习中最强大的模型之一,我们可以通过应用转换器蒸馏来有效地压缩它们来进一步开发利用它们。这方面最伟大的例子之一是TinyBERT模型,它在BERT模型基础上压缩了7.5倍。
尽管参数大幅减少,但实验表明,TinyBERT模型的性能与BERT基础模型基本相当:在GLUE基准数据集上的测试结果表明,TinyBERT模型获得77.0%的得分,与得分为79.5%的BERT模型相距并不远。显然,这是一个惊人的成就!最后,其他的一些流行的压缩技术,如量化或修剪等,都可以应用于TinyBERT模型压缩算法,从而使此模型体积变得更小。
除非另有说明,否则本文中所有图片均由作者本人提供。
参考资料
- TinyBERT: Distilling BERT for Natural Language Understanding:https://arxiv.org/pdf/1909.10351.pdf。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Large Language Models: TinyBERT — Distilling BERT for NLP,作者:Vyacheslav Efimov
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 揭秘拉斐尔名画的真相:不完全由大师创作
- 据最新消息,一项人工智能神经网络的研究在拉斐尔的一幅名画中发现了一处异常之处。在这幅画中,竟然出现了一个面孔,而这个面孔并非出自拉斐尔本人之手。这一发现引起了广泛的关注和讨论。这幅画被称为《玫瑰圣母(MadonnadellaRosa)》,多年来一直存在争议,学者们对于这幅画是否是拉斐尔的原作一直争论不休。尽管判断一件艺术品的来源需要综合各种证据,但一种基于人工智能算法的新的分析方法支持了那些认为这幅画至少有一部分是由另一位艺术家创作的观点。由英国和美国的研究人员组成的团队,专门开发了一个定制的人工智能算法
- 8分钟前 0
-
 正版软件
正版软件
- 华为暂缓与懂车帝等平台的会员门店业务合作,回应原协议到期
- 本站1月3日消息,继此前余承东怒怼懂车帝风波后,现有传闻称:2024年1月起,华为鸿蒙智行旗下问界、智界停止与汽车之家、懂车帝、易车的合作,旗下门店均未开通三车平台会员。车fans创始人孙少军在微博上表示,他与华为总部和渠道的朋友确认过,华为已主动停止与中国三大汽车门户网站(懂车帝、易车网、汽车之家)的合作。华为方面表示,由于鸿蒙智行与部分平台会员门店业务原合作协议到期,在商务洽谈达成一致前暂缓会员门店业务合作。然而,其他合作业务仍会按照正常进行。实际上,华为余承东上个月还在微信朋友圈就问界M7冬测结果怒
- 13分钟前 华为 AITO 问界 0
-
 正版软件
正版软件
- 宏碁CES发布全新Predator Z57显示器:18000元定价,具备曲面屏和MiniLED背光技术
- 宏碁在CES展会上发布了四款全新的Predator系列显示器,包括三款不同尺寸的型号和一款引人注目的新品PredatorZ57。PredatorZ57显示器以其独特的曲面屏幕设计和出色的显示性能脱颖而出。它采用了DUHDVA面板,并结合MiniLED背光技术,其中包含高达2304个分区,为用户提供非凡的视觉体验。该显示器的屏幕分辨率达到了惊人的7620x2160,刷新率高达120Hz,能够与市场上的三星57英寸OdysseyNeoG9显示器一较高下。这款显示器将为用户带来令人难以置信的视觉效果和流畅的游戏
- 28分钟前 宏碁 0
-
 正版软件
正版软件
- SK 海力士加速HBM4研发并计划在2024年量产CXL内存
- SK海力士在本站12月24日发布了年度AI内存总结,并宣布计划在2024年启动HBM4的研发,并推动CXL内存的商业化量产工作▲SK海力士2023年8月发布的HBM3E产品SK海力士GSM团队的负责人王秀表示:“明年我们公司将开始量产和销售HBM3E,这将进一步巩固我们在市场上的领先地位。”他还说到:“我们计划全面开发后续产品HBM4,因此明年将代表SK海力士进入一个全新阶段。这将是我们值得庆祝的一年。”他表示,随着人工智能产业的快速发展,高带宽内存(HBM)产品将超越目前仅限于人工智能服务器的范围,并扩
- 43分钟前 SK海力士 0
-
 正版软件
正版软件
- 火爆发布:雷神猎刃 16与英特尔酷睿14代CPU震撼出击
- 12月27日消息,雷神公司宣布计划在1月推出其最新的游戏笔记本——猎刃16。这款笔记本以其全新设计和强大的散热性能为特色,预计将引起市场上的广泛关注。猎刃16采用了雷神独家的“飍”科技散热系统,这一系统配置了三个风扇,热管总长度达到了1.6米。这种设计使得笔记本在强大性能运行时,表面最高温度保持在39度,同时噪音控制在50dB以内,确保了用户在长时间使用中的舒适体验。据小编了解,雷神猎刃16的配置同样引人注目。它将搭载英特尔最新的酷睿14代HX系列处理器,用户可以根据需求选择i9-14900HX或i7-1
- 58分钟前 雷神 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1786天前
-
 2
2
- Overture设置踏板标记的方法
- 1623天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1613天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1811天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1777天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1773天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1788天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1809天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00