一篇综述,看穿基础模型+机器人的发展路径
 发布于2024-11-01 阅读(0)
发布于2024-11-01 阅读(0)
扫一扫,手机访问
无需改变原意,机器人是一种技术,可以有无限的可能性,尤其是当与智能技术结合时。最近,一些具有革命性应用的大型模型有望成为机器人的智能中枢,帮助机器人感知和理解世界,做出决策和规划
近日,CMU 的 Yonatan Bisk 和 Google DeepMind 的夏斐(Fei Xia)领导的一个联合团队发布了一篇综述报告,介绍了基础模型在机器人领域的应用和发展情况。报告的 first aurthor 是 CMU 的博士四年级学生胡亚非(Yafei Hu),他的研究集中在机器人和人工智能的交叉应用上。与他合作的是谢泉廷(Quanting Xie),专注于通过基础模型探索具身智能(embodied intelligence)。

论文地址:https://arxiv.org/pdf/2312.08782.pdf
开发能自主适应不同环境的机器人是人类一直以来的一个梦想,但这却是一条漫长且充满挑战的道路。之前,利用传统深度学习方法的机器人感知系统通常需要大量有标注数据来训练监督学习模型,而如果通过众包方式来标注大型数据集,成本又非常高。
此外,由于经典监督学习方法的泛化能力有限,为了将这些模型部署到具体的场景或任务,这些训练得到的模型通常还需要精心设计的领域适应技术,而这又通常需要进一步的数据收集和标注步骤。类似地,经典的机器人规划和控制方法通常需要仔细地建模世界、智能体自身的动态和 / 或其它智能体的动态。这些模型通常是针对各个具体环境或任务构建的,而当情况有变时,就需要重新构建模型。这说明经典模型的迁移性能也有限。
事实上,对于很多用例,构建有效模型的成本要么太高,要么就完全无法办到。尽管基于深度(强化)学习的运动规划和控制方法有助于缓解这些问题,但它们仍旧会受到分布移位(distribution shift)和泛化能力降低的影响。
虽然在开发通用型机器人系统上正面临诸多挑战,但自然语言处理(NLP)和计算机视觉(CV)领域近来却进展迅猛,其中包括用于 NLP 的大型语言模型(LLM)、用于高保真图像生成的扩散模型、用于零样本 / 少样本生成等 CV 任务的能力强大的视觉模型和视觉语言模型。
所谓的「基础模型(foundation model)」其实就是大型预训练模型(LPTM)。它们具备强大的视觉和语言能力。近来这些模型也已经在机器人领域得到应用,并有望赋予机器人系统开放世界感知、任务规划甚至运动控制能力。除了将现有的视觉和 / 或语言基础模型用于机器人领域,也有研究团队正针对机器人任务开发基础模型,比如用于操控的动作模型或用于导航的运动规划模型。这些机器人基础模型展现出了强大的泛化能力,能适应不同的任务甚至具身方案。也有研究者直接将视觉 / 语言基础模型用于机器人任务,这展现出了将不同机器人模块融合成单一统一模型的可能性。
尽管视觉和语言基础模型在机器人领域前景可期,全新的机器人基础模型也正在开发中,但机器人领域仍有许多挑战难以解决。
从实际部署角度看,模型往往是不可复现的,无法泛化到不同的机器人形态(多具身泛化)或难以准确理解环境中的哪些行为是可行的(或可接受的)。此外,大多数研究使用的都是基于 Transformer 的架构,关注的重点是对物体和场景的语义感知、任务层面的规划、控制。而机器人系统的其它部分则少有人研究,比如针对世界动态的基础模型或可以执行符号推理的基础模型。这些都需要跨领域泛化能力。
最后,我们也需要更多大型真实世界数据以及支持多样化机器人任务的高保真度模拟器。
这篇综述论文总结了机器人领域使用的基础模型,目标是理解基础模型能以怎样的方式帮助解决或缓解机器人领域的核心挑战。
在这篇综述中,研究人员使用的"基础模型(foundation models)"这个术语包含了机器人领域的两个方面:(1) 目前已存在的主要视觉和语言模型,主要是通过零样本和上下文学习来实现;(2) 使用机器人生成的数据专门开发和应用基础模型,解决机器人任务。研究人员总结了相关论文中关于基础模型的方法,并对这些论文的实验结果进行了元分析
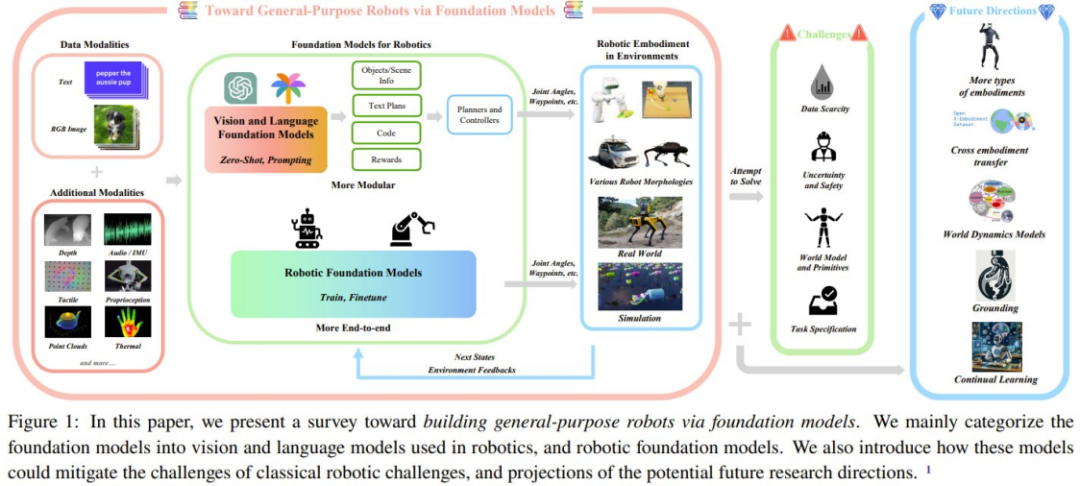
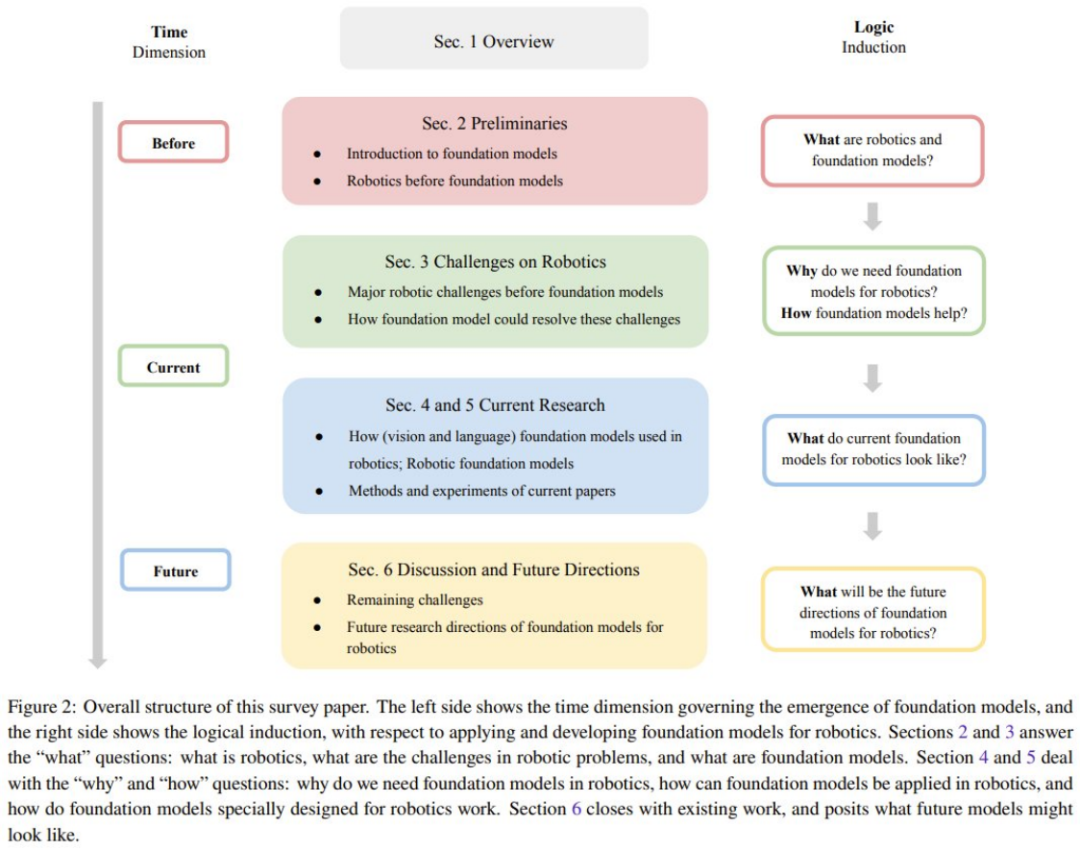
综述的整体结构
预备知识
为了帮助读者更好地理解这篇综述的内容,团队首先提供了一节预备知识的内容
他们首先将介绍机器人学的基础知识以及当前最佳技术。这里主要聚焦于基础模型时代之前机器人领域使用的方法。这里进行简单说明,详情参阅原论文。
- 机器人的主要组件可分为感知、决策和规划、动作生成三大部分。该团队将机器人感知分为被动感知、主动感知和状态估计。
- 在机器人决策和规划部分,研究者分经典规划方法和基于学习的规划方法进行了介绍。
- 机器的动作生成也有经典控制方法和基于学习的控制方法。
接下来该团队又会介绍基础模型并主要集中在 NLP 和 CV 领域,涉及的模型包括:LLM、VLM、视觉基础模型、文本条件式图像生成模型。
机器人领域面临的挑战
典型机器人系统的不同模块所面临的五大核心挑战。图 3 展示了这五大挑战的分类情况。
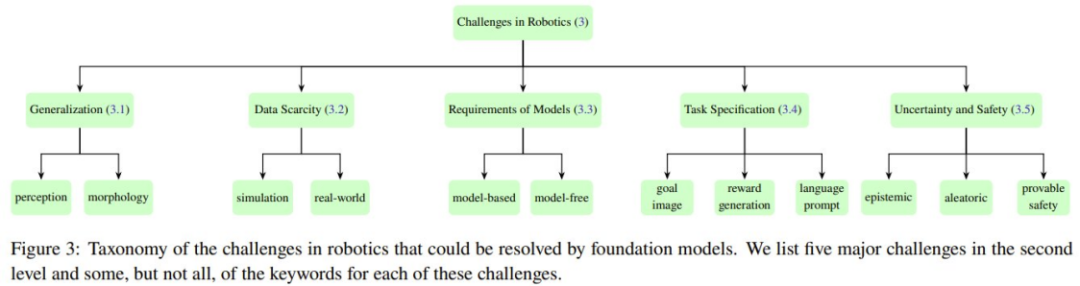
泛化
机器人系统往往难以准确地感知和理解其环境。它们也没有能力将在一个任务上的训练成果泛化到另一个任务,这会进一步限制它们在真实世界中的实用性。此外,由于机器人硬件不同,将模型迁移用于不同形态的机器人也很困难。通过将基础模型用于机器人,可以部分地解决泛化问题。而在不同机器人形态上泛化这样更进一步的问题还有待解答。
数据稀缺
为了开发出可靠的机器人模型,大规模的高质量数据至关重要。人们已经在努力尝试从现实世界收集大规模数据集,包括自动驾驶、机器人操作轨迹等。并且从人类演示收集机器人数据的成本很高。不过,由于任务和环境的多样性,在现实世界收集足够且广泛的数据的过程还会更加复杂。在现实世界收集数据还会有安全方面的疑虑。另外,在现实世界中,大规模收集数据非常困难,而要收集到训练基础模型所使用的互联网规模级的图像/文本数据,那就更困难了。
为了解决这些挑战,许多研究工作都试图在模拟环境中生成合成数据。这些模拟环境能够提供非常逼真的虚拟世界,使得机器人能够在接近真实场景的情况下学习和运用自己的技能。然而,使用模拟环境也存在一些局限性,特别是在物体多样性方面,这导致所学到的技能难以直接应用于真实世界情境
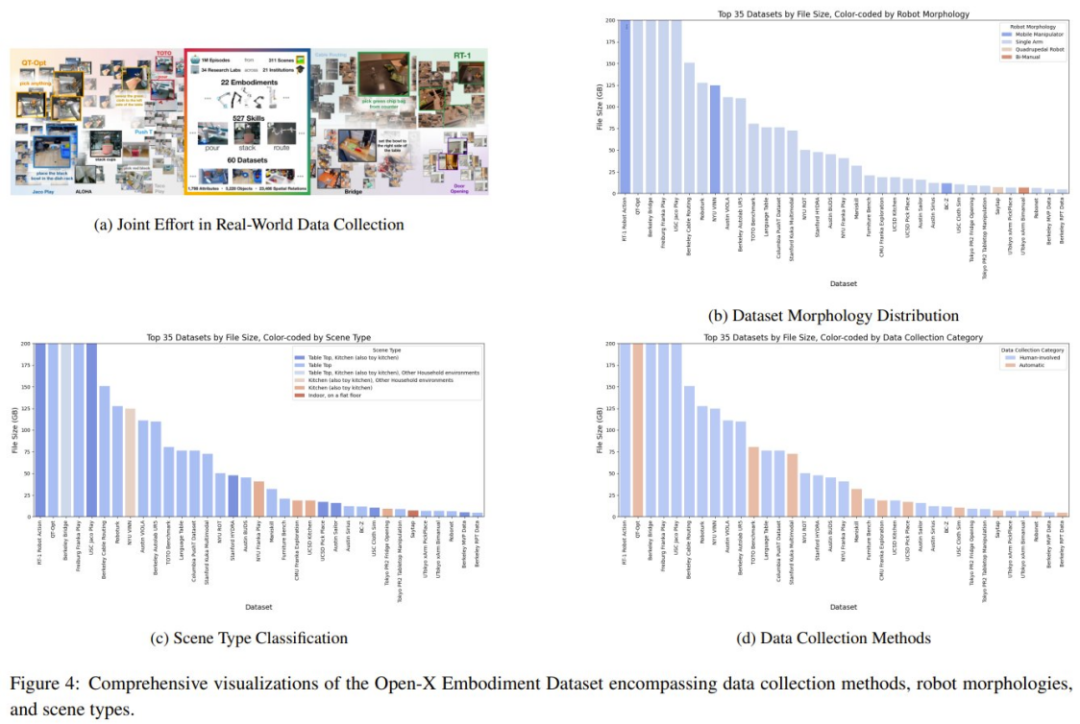
一种颇具潜力的方法是协作式数据收集,即将不同实验室环境和机器人类型的数据收集到一起,如图 4a 所示。但是,该团队深度研究了 Open-X Embodiment Dataset,发现在数据类型可用性方面还存在一些局限性。
模型和原语要求
经典的规划和控制方法通常需要精心设计的环境和机器人模型。之前的基于学习的方法(如模仿学习和强化学习)是以端到端的方式训练策略,也就是直接根据感官输入获取控制输出,这样能避免构建和使用模型。这些方法能部分解决依赖明确模型的问题,但它们往往难以泛化用于不同的环境和任务。
有两个问题需要解决:(1) 如何学习那些与模型无关,能够良好泛化的策略?(2) 如何学习优秀的世界模型,从而应用经典的基于模型的方法?
任务规范
为了得到通用型智能体,一大关键挑战是理解任务规范并将其根植于机器人对世界的当前理解中。通常而言,这些任务规范由用户提供,但用户只能有限地理解机器人的认知和物理能力的局限性。这会带来很多问题,包括能为这些任务规范提供什么样的最佳实践,还有起草这些规范是否足够自然和简单。基于机器人对自身能力的理解,理解和解决任务规范中的模糊性也充满挑战。
不确定性和安全性
为了在现实世界中部署机器人,一大关键挑战是处理环境和任务规范中固有的不确定性。根据来源的不同,不确定性可以分为认知不确定性(由缺乏知识导致不确定)和偶然不确定性(环境中固有的噪声)。
不确定性量化(UQ)的成本可能会高得让研究和应用难以为继,也可能让下游任务无法被最优地解决。有鉴于基础模型大规模过度参数化的性质,为了在不牺牲模型泛化性能的同时实现可扩展性,提供能保留训练方案同时又尽可能不改变底层架构的 UQ 方法至关重要。设计能提供对自身行为的可靠置信度估计,并反过来智能地请求清晰说明反馈的机器人仍然是一个尚未解决的挑战。
近来虽有一些进展,但要确保机器人有能力学习经验,从而在全新环境中微调自己的策略并确保安全,这一点还依然充满挑战。
当前研究方法概况
本文还总结了用于机器人的基础模型的当前研究方法。该团队将机器人领域使用的基础模型分成了两大类:用于机器人的基础模型和重写的内容是:机器人基础模型(RFM)。
机器人的基础模型是指无需额外微调或训练,以零样本的方式将视觉和语言基础模型用于机器人。机器人基础模型可以通过视觉 - 语言预训练初始化来进行热启动,或直接在机器人数据集上训练模型
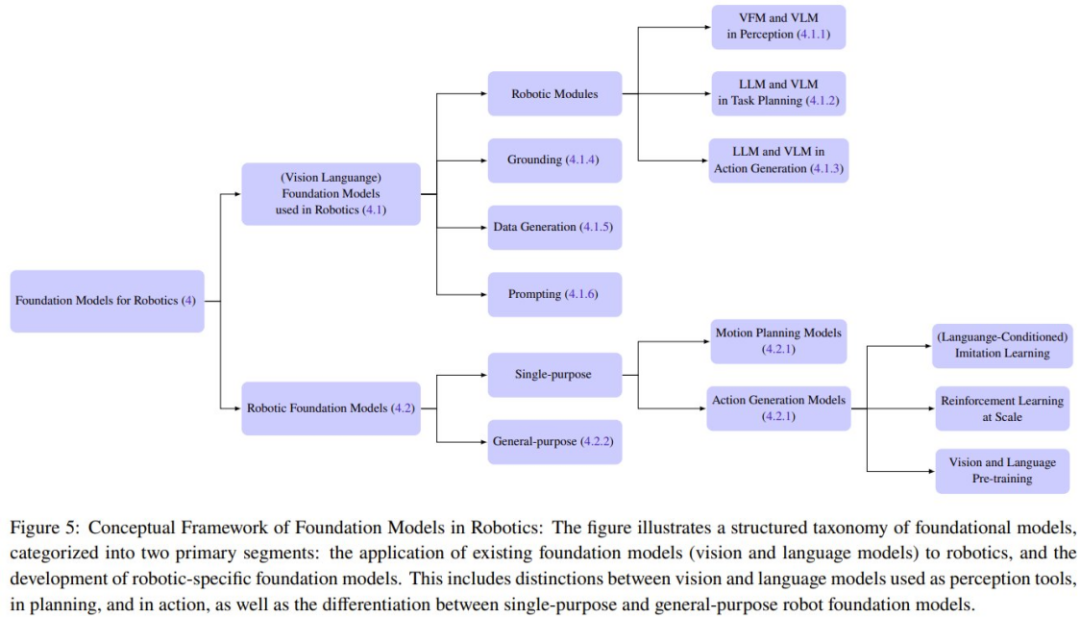
详细分类
用于机器人的基础模型
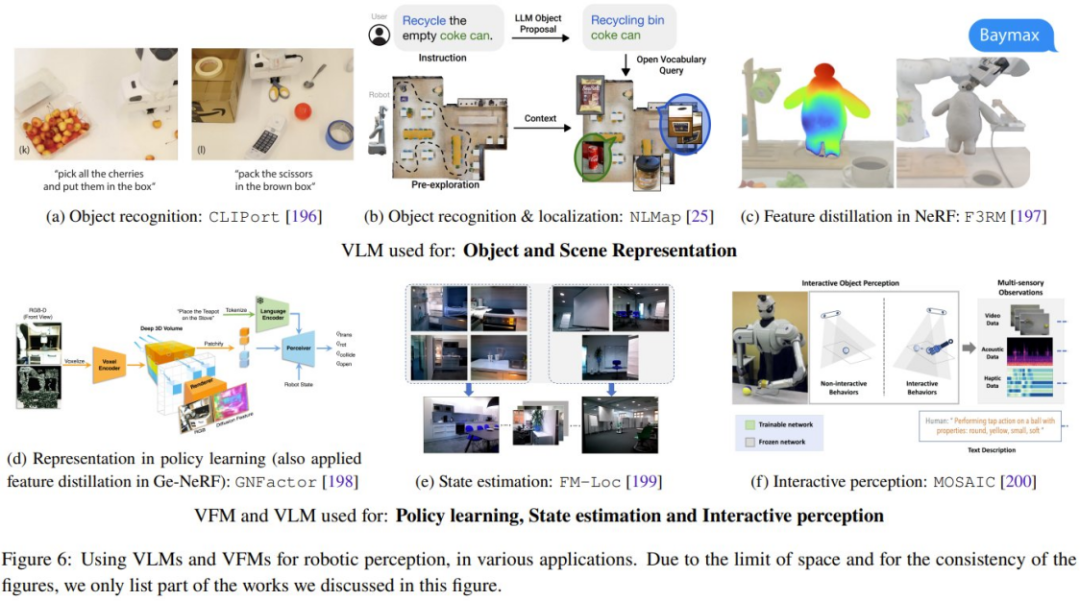
这段内容的重写如下:这部分内容关注于在机器人领域中将视觉和语言基础模型应用到零样本情境。其中,主要包括将VLM零样本部署到机器人感知应用中,以及将LLM的上下文学习能力应用于任务层面和运动层面的规划与动作生成。图6展示了一些典型的研究工作
重写的内容是:机器人基础模型(RFM)
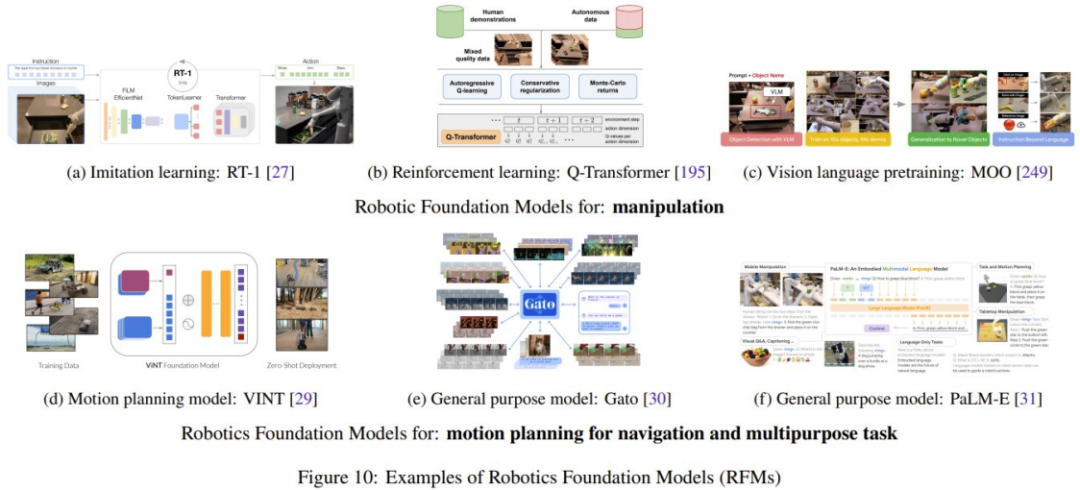
随着包含来自真实机器人的状态-动作对的机器人数据集的增长,重写的内容是:机器人基础模型(RFM)类别同样变得越来越有可能成功。这些模型的特点是使用了机器人数据来训练模型解决机器人任务。
研究团队在讨论中总结了不同类型的 RFM。首先是能够在单个机器人模块中执行特定任务的 RFM,也被称为单目标机器人基础模型。例如,能够生成控制机器人低层动作的 RFM 或者能够生成更高层运动规划的模型。文章中还介绍了能够在多个机器人模块中执行任务的 RFM,即通用模型,可以执行感知、控制甚至非机器人任务
基础模型在解决机器人挑战方面有什么作用?
前文列出了机器人领域面临的五大挑战。这里将介绍基础模型可以怎样帮助解决这些挑战。
所有与视觉信息相关的基础模型(如 VFM、VLM 和 VGM)都可用于机器人的感知模块。而 LLM 的功能更多样,可用于规划和控制。重写的内容是:机器人基础模型(RFM)通常用于规划和动作生成模块。表 1 总结了解决不同机器人挑战的基础模型。
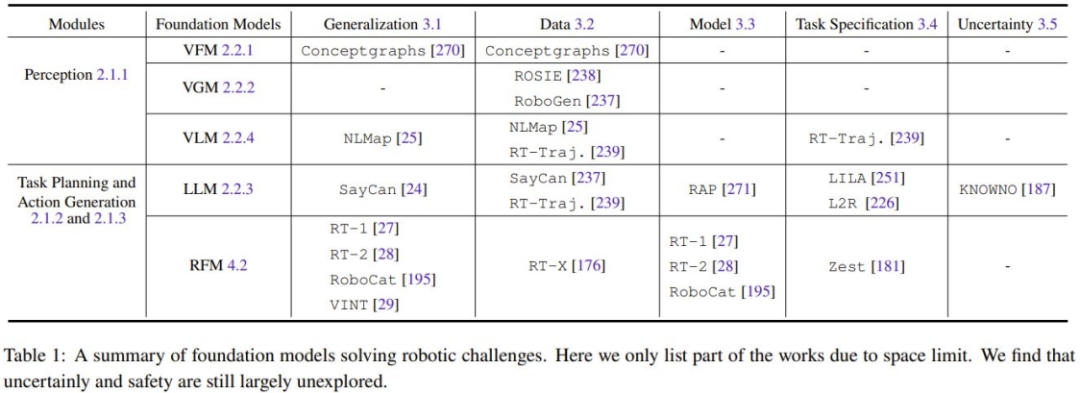
从表中可以看出,所有的基础模型都能够很好地泛化不同机器人模块的任务。特别是LLM在任务规范方面表现出色。另一方面,RFM则擅长应对动态模型的挑战,因为大多数RFM都是无模型方法。对于机器人的感知能力而言,泛化能力和模型的挑战是相互关联的。如果感知模型已经具备了良好的泛化能力,那么就不需要获取更多的数据来进行领域适应或额外微调了
另外,在安全挑战方面还缺乏研究,这会是一个重要的未来研究方向。
当前的实验和评估概况
这一部分总结了当前研究成果的数据集、基准和实验。
数据集和基准
仅依靠从语言和视觉数据集学到的知识是存在局限的。正如一些研究成果表明的那样,摩擦力和重量等一些概念无法仅通过这些模态轻松学习到。
因此,为了让机器人智能体能更好地理解世界,研究社区不仅在适应来自语言和视觉领域的基础模型,也在推进开发用于训练和微调这些模型的大型多样化多模态机器人数据集。
目前这些工作可以分为两个主要方向:一方面是从现实世界收集数据,另一方面是从模拟世界收集数据并将其迁移到现实世界。每个方向都有其优势和劣势。从现实世界收集的数据集包括 RoboNet、Bridge Dataset V1、Bridge-V2、. Language-Table、RT-1 等。常用的模拟器包括 Habitat、AI2THOR、Mujoco、AirSim、Arrival Autonomous Racing Simulator、Issac Gym 等
对当前方法的评估分析(Meta-Analysis)
该团队的另一大贡献是对本综述报告中提到的论文中的实验进行了元分析,这可以为理清以下问题有所帮助:
1. 人们研究解决的是哪些任务?
2. 训练模型使用了哪些数据集或模拟器?测试用的机器人平台有哪些?
3. 研究社区使用了哪些基础模型?解决任务的效果如何?
4. 这些方法中更常使用哪些基础模型?
表 2-7 和图 11 给出了分析结果。
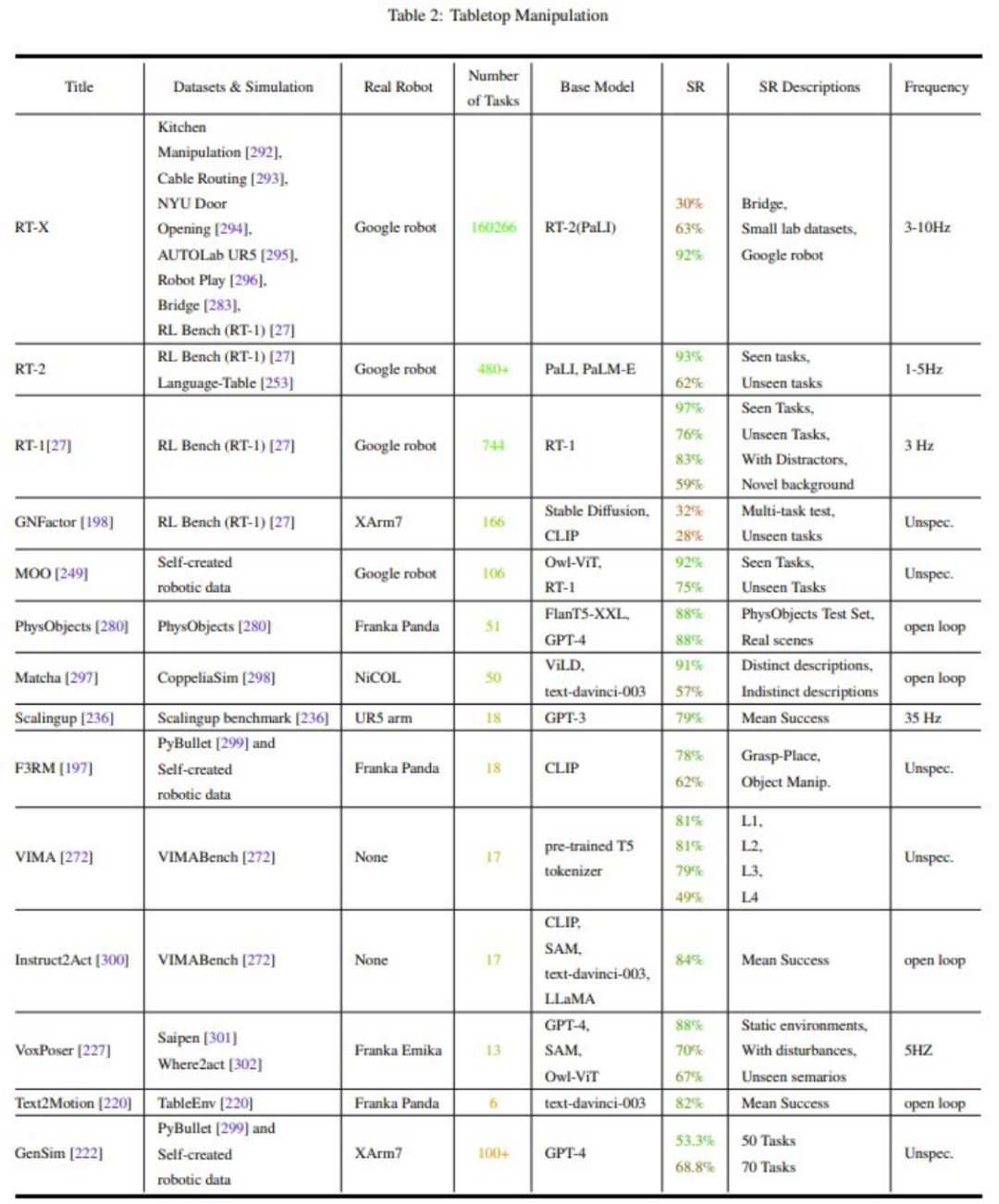
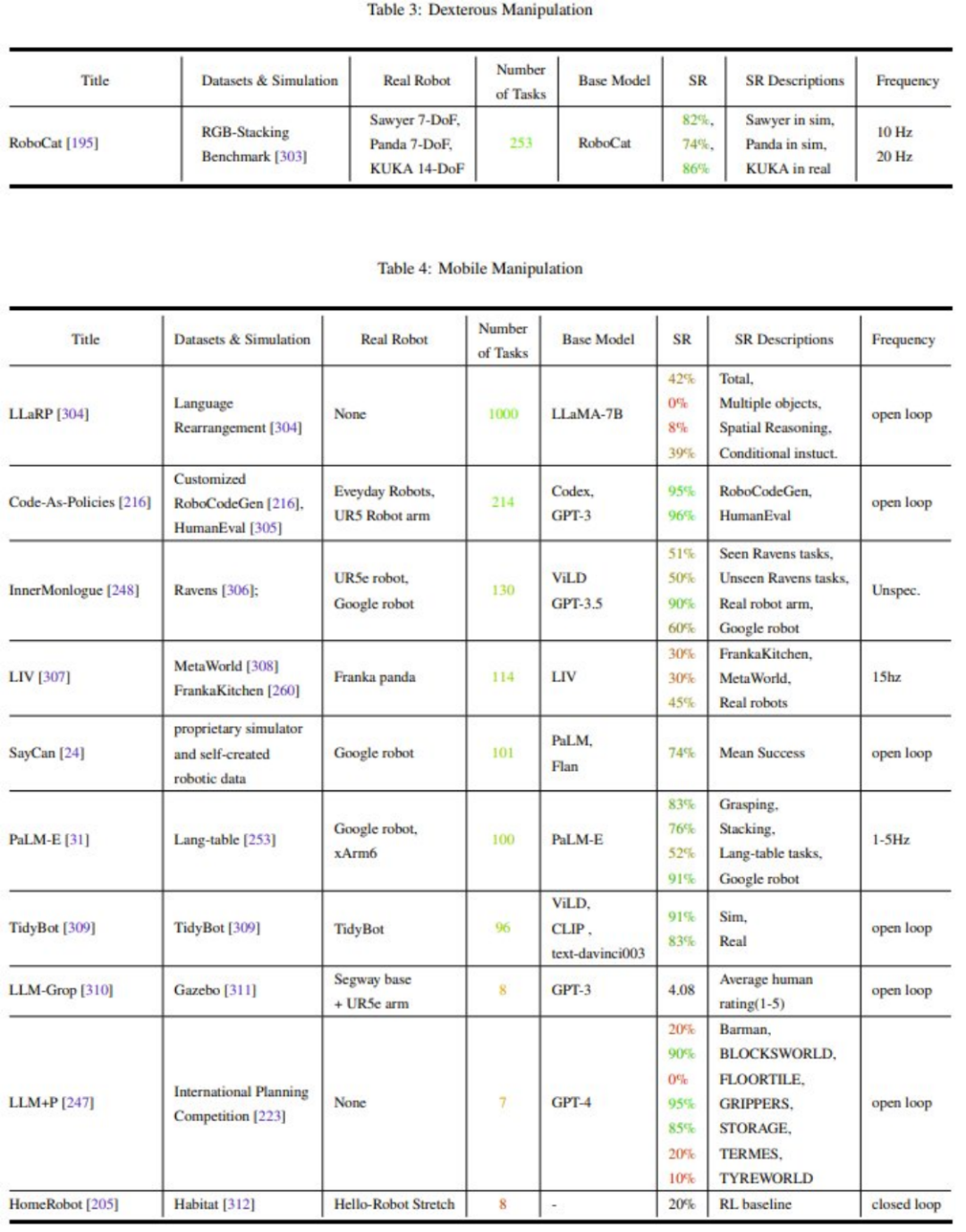
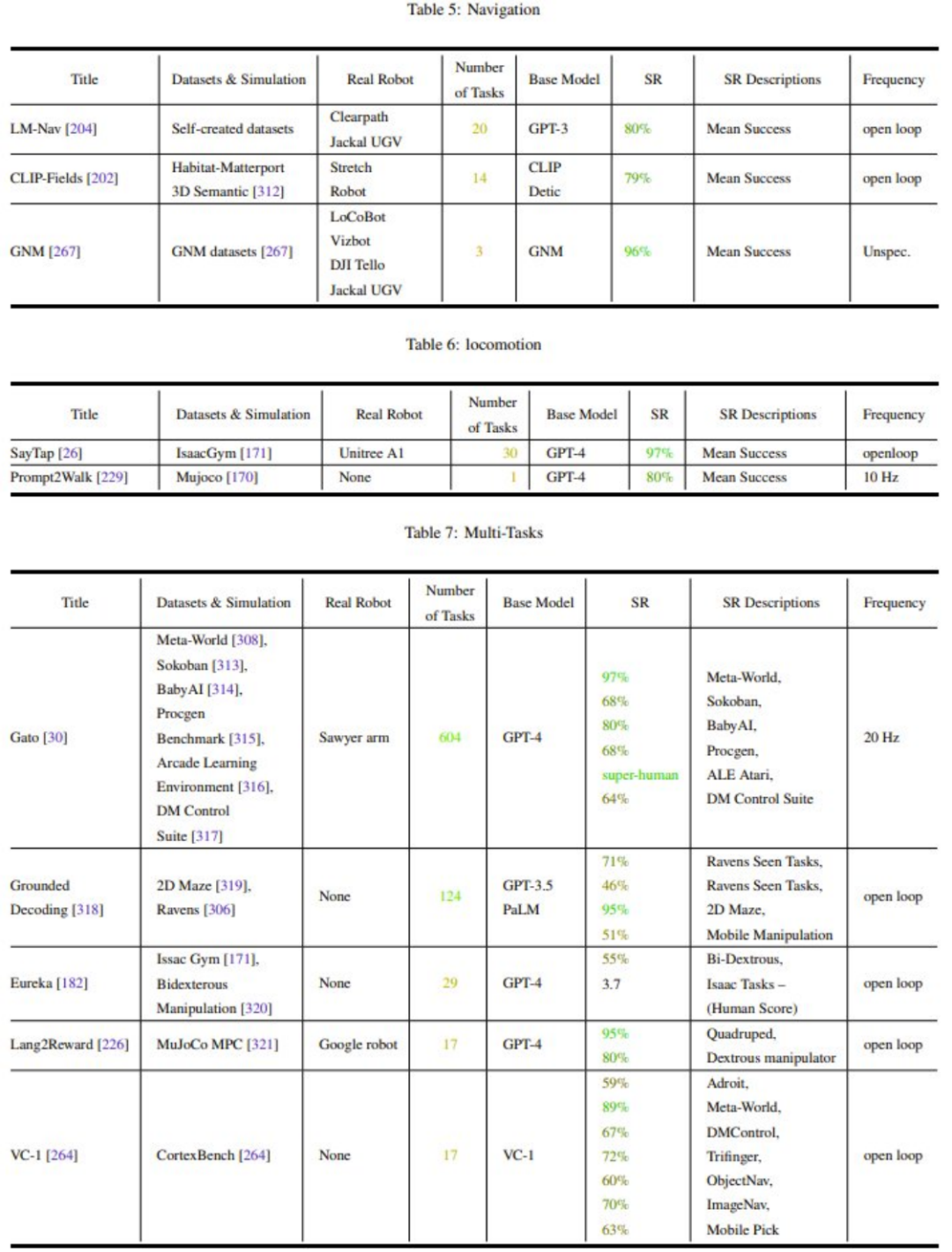
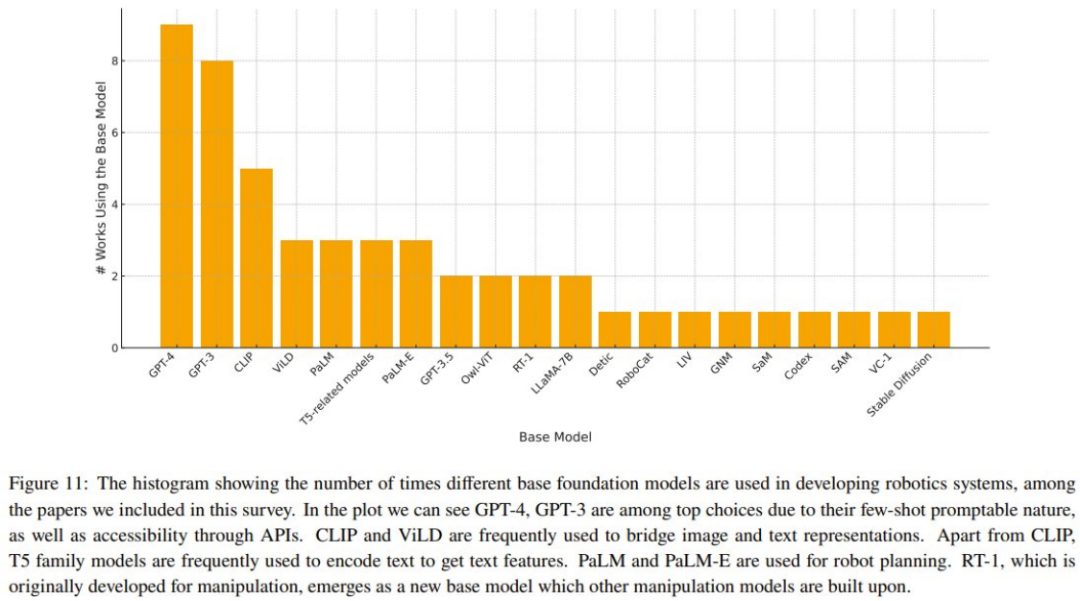
该团队通过 Meta-analysis 得到的一些主要观察:
研究社区对机器人操作任务(Manipulation)的关注不平衡
泛化能力(Generalization)和稳健性需要提升
对低层动作(Low-level Control)的探索很有限
控制频率太低(<15Hz),无法部署在真实机器人中(一般需要 100Hz)
缺乏统一的测试基准(Metrics)和测试平台(Simulation or Hardware),使得对比变得非常困难。
讨论和未来方向
该团队总结了一些仍待解决的挑战和值得讨论的研究方向:
- 如何为机器人具身设定标准基础(grounding)?
- 安全(Safety)和不确定性(Uncertainty)?
- 端到端方法(end-to-end)和模块化(Modular)方法是否无法兼容?
- 对具身的物理变化的适应能力
- 世界模型(World Model)方法还是与模型无关的方法?
- 新型机器人平台和多感官信息
- 持续学习(Continue Learning)
- 标准化和可复现能力(Reproducibility)
上一篇:win102004闪屏解决方法
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- vivo新机通过3C认证,iQOO Z9系列即将发布
- 近期,vivo手机备受瞩目,引发了广泛关注。除了即将发布的vivoXFold3系列折叠屏手机,其子品牌iQOO也即将推出全新机型,令人期待。根据消息透露,vivo最新型号为V2343A的手机已通过国家3C认证,支持80W快充技术,预计会成为即将发布的iQOOZ9系列的一款新机型。此前已经宣布的iQOOZ9Turbo(V2352A)搭载了高通骁龙8sGen3处理器,并且已通过3C认证,因此这款新机很可能是iQOOZ9系列中的标准版。iQOOZ9海外版已先行发布,搭载了联发科天玑7200处理器,并配备了一块6
- 5分钟前 vivo 0
-
 正版软件
正版软件
- 全球首创双光源固态激光雷达导航避障 石头V20树立导航避障新标准
- 2024年3月29日,石头科技全球发布会在京举行,石头科技发布两款旗舰级扫拖机器人新品,包括先锋旗舰石头自清洁扫拖机器人V20以及顶尖科技的石头自清洁扫拖机器人G20S。其中,石头V20搭载全新星阵领航系统,以全球首创的双光源固态激光雷达再次刷新扫拖机器人的导航能力;石头G20S则将巅峰科技全面拉满,在清洁力、全能性以及智能性三大方面都做到了行业内的天花板,引领扫地机器人行业全面进阶阶段。同时,照相的还有推出不久便获得市场热烈反响的P10SPro。除了多款扫拖机器人新品之外,石头科技总裁全刚在发布会上还宣
- 15分钟前 产业 0
-
 正版软件
正版软件
- iPhone 15系列新机预计8月大规模量产 富士康郑州园区迎来宿舍升级
- 07月12日消息,备受瞩目的苹果iPhone15系列新机有望在8月份大规模量产。为了确保新机量产顺利,位于中国郑州的富士康园区进行了重要的升级工程,提升了员工待遇并改善了员工宿舍条件。据小编了解,富士康园区内的宿舍公寓升级改造工程已在近期完成,该举措旨在进一步确保iPhone15系列新机的顺利量产。改造涵盖了富士康园区内的裕鸿、华鸿、豫康北区、富鑫等五个公寓小区,共有30栋楼和7568间公寓,近日已全部完成改造并通过验收。富士康今年非常重视员工的生活条件改善。报道称,富士康的iDPBG部门高管日前对郑州园
- 30分钟前 0
-
 正版软件
正版软件
- 微软再次发布修复Win11中Defender LSA误报问题的KB5007651更新
- 7月5日消息,微软在昨日对微软健康中心页面进行了更新,并宣布将于7月5日针对Win11Version21H2/22H2版本发布KB5007651(版本1.0.2306.10002)更新,旨在进一步解决LSA误报问题。根据我们从微软健康中心页面获得的信息,LSA误报问题的时间表如下:今年3月,微软发布了KB5007651更新(版本号1.0.2302.21002),该更新要求用户强制安装。然而,一些用户报告称在安装该更新后,WindowsSecurity显示“LocalSecurityauthoritypro
- 45分钟前 微软 0
-
 正版软件
正版软件
- 理想汽车 Mind GPT 大模型通过国家备案,训练数据规模达 3 万亿 Token
- 本网站3月28日消息,理想汽车宣布,全自研多模型认知大模型MindGPT正式通过国家《生成式人工智能服务管理暂行办法》备案,成为首个通过该备案的汽车厂商自研大模型。据介绍,MindGPT是在汽车智能座舱落地的全自研多模态认知大模型,训练数据规模达3万亿Token。理想汽车称:Mind+GPT是一个可以使用的大模型,也是行业唯一一个不需要任何指令词就可以使用的大模型,也是行业唯一一个真正围绕车载场景打造的大模型。它仍然拥有听觉和执行能力全面进化的理念同学,支持方言自由说、指令自由说、简洁模式以及全时全车免唤
- 1小时前 14:50 大数据 理想 Mind 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1839天前
-
 2
2
- Overture设置踏板标记的方法
- 1676天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1666天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1864天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1830天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1826天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1841天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1862天前
-
 9
9
相关推荐
- vivo新机通过3C认证,iQOO Z9系列即将发布
- 全球首创双光源固态激光雷达导航避障 石头V20树立导航避障新标准
- iPhone 15系列新机预计8月大规模量产 富士康郑州园区迎来宿舍升级
- 微软再次发布修复Win11中Defender LSA误报问题的KB5007651更新
- 理想汽车 Mind GPT 大模型通过国家备案,训练数据规模达 3 万亿 Token
- 华为三折屏手机即将面世,预计二季度亮相市场
- 智己汽车刘涛预热智己L6:四驱超强续航,固态电池更安全
- 2024年2月中国大陆电竞显示器市场逆势增长,销量同比大涨36.4%
- 快狗打车 2023 年收入 7.53 亿元同比下降 2.6%,经调亏损收窄 25.6%
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00