升级至高画质:NTU拓展视频超分辨率技术「Upscale-A-Video」
 发布于2024-11-02 阅读(0)
发布于2024-11-02 阅读(0)
扫一扫,手机访问
扩散模型在图像生成方面取得了显著成功,但将其应用于视频超分辨率仍存在挑战。视频超分辨率要求输出保真度和时间一致性,而扩散模型的固有随机性使这变得复杂。因此,有效地将扩散模型应用于视频超分辨率仍是一个具有挑战性的任务。
来自南洋理工大学 S-Lab 的研究团队提出了一种名为Upscale-A-Video的文本指导潜在扩散框架,用于视频超分。该框架通过两个关键机制确保时间一致性。首先,在局部范围内,它将时间层集成到U-Net和VAE-Decoder中,以保持短序列的一致性。其次,在全局范围内,该框架引入了流指导循环潜在传播模块,无需训练即可在整个序列中传播和融合潜在,从而增强整体视频的稳定性。这种框架的提出为视频超分提供了一种新的解决方案,具有较好的时间一致性和整体稳定性。

论文地址:https://arxiv.org/abs/2312.06640
通过扩散范式,Upscale-A-Video 获得了很大的灵活性。它允许使用文本 prompt 来指导纹理的创建,并且可以调节噪声水平,以在恢复和生成之间平衡保真度和质量。这一特性使得该技术在保持原始内容意义不变的同时,能够微调细节,从而实现更精确的结果。
实验结果表明,Upscale-A-Video在合成和现实世界基准上的表现超过了现有方法,呈现出令人印象深刻的视觉真实感和时间一致性。
我们先来看几个具体例子,例如,借助 Upscale-A-Video,「花果山名场面」有了高清画质版:

相比于 StableSR,Upscale-A-Video 让视频中的松鼠毛发纹理清晰可见:

方法简介
一些研究通过引入时间一致性策略来优化图像扩散模型以适应视频任务。这些策略包括以下两种方法:首先,通过时间层微调视频模型,如3D卷积和时间注意力,来提升视频处理性能。其次,使用零样本机制,例如跨帧注意力和流指导注意力,来在预训练模型中进行调整,以提高视频任务的表现。这些方法的引入使得图像扩散模型能够更好地处理视频任务,从而提升视频处理的效果。
尽管这些解决方案显著提高了视频稳定性,但仍然存在两个主要问题:
当前在 U-Net 特征或潜在空间中运行的方法难以保持低级一致性,纹理闪烁等问题仍然存在。
现有的时间层和注意力机制只能对短的局部输入序列施加约束,限制了它们确保较长视频中全局时间一致性的能力。
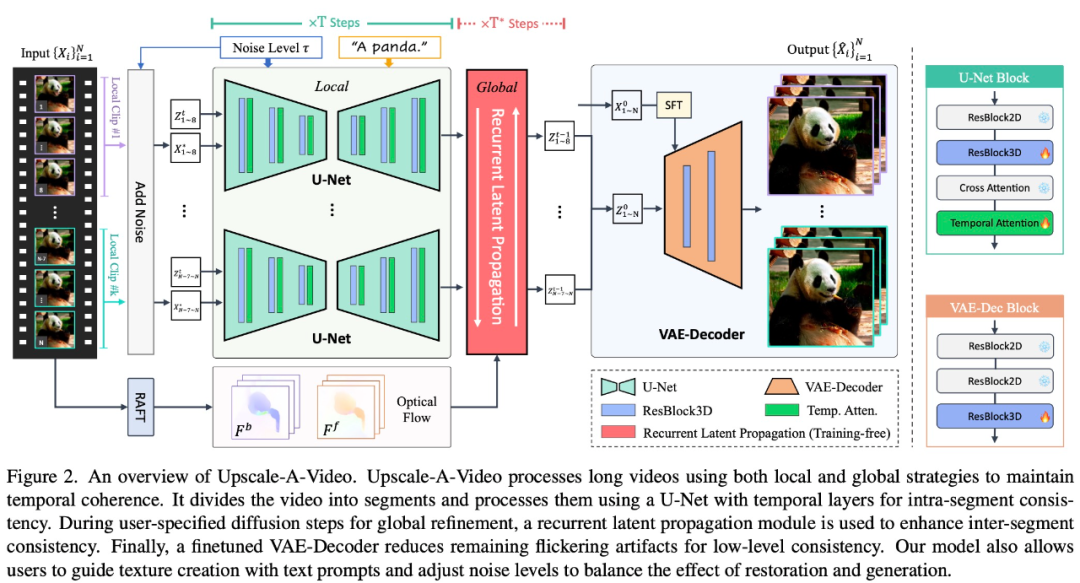
为了解决这些问题,Upscale-A-Video 采用局部-全局策略来维持视频重建中的时间一致性,重点关注细粒度纹理和整体一致性。在局部视频剪辑上,该研究探索使用视频数据上的附加时间层来微调预训练图像 ×4 超分模型。
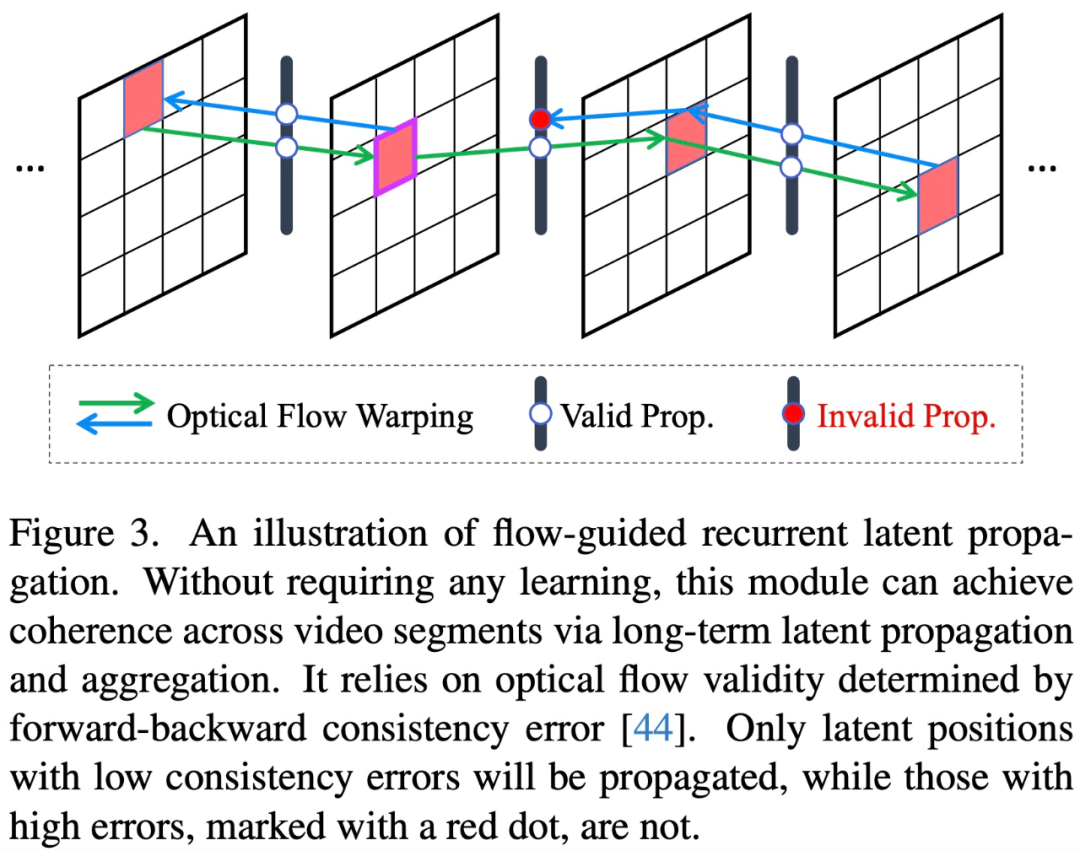
具体来说,在潜在扩散框架内,该研究首先使用集成的 3D 卷积和时间注意力层对 U-Net 进行微调,然后使用视频条件输入和 3D 卷积来调整 VAE 解码器。前者显著实现了局部序列的结构稳定性,后者进一步提高了低级一致性,减少了纹理闪烁。在全局范围内,该研究引入了一种新颖的、免训练的流指导循环潜在传播模块,在推理过程中双向进行逐帧传播和潜在融合,促进长视频的整体稳定性。
Upscale-A-Video 模型可以利用文本 prompt 作为可选条件来指导模型产生更真实、更高质量的细节,如图 1 所示。

Upscale-A-Video 将视频划分为多个片段,并使用具有时间层的 U-Net 对其进行处理,以实现片段内的一致性。在用户指定的全局细化扩散期间,使用循环潜在传播模块来增强片段间的一致性。最后,经过微调的 VAE 解码器可减少闪烁伪影,实现低级一致性。
实验结果
Upscale-A-Video 在现有基准上实现了SOTA性能,展现出卓越的视觉真实感和时间一致性。
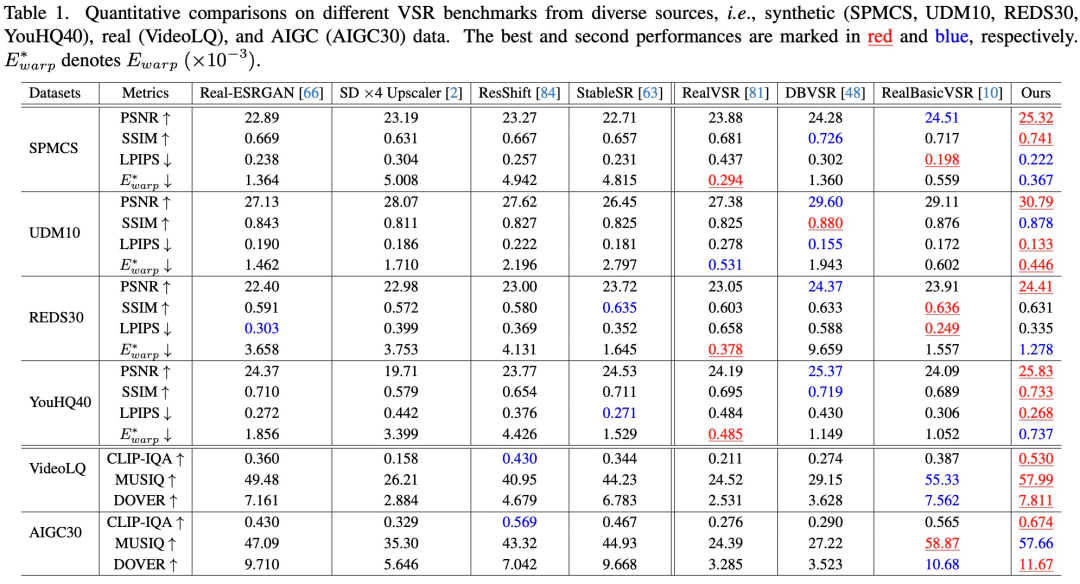
定量评估。如表 1 所示,Upscale-A-Video在所有四个合成数据集中实现了最高的 PSNR,表明其具有出色的重建能力。
定性评估。该研究分别在图 4 和图 5 中展示了合成和真实世界视频的视觉结果。Upscale-A-Video 在伪影去除和细节生成方面都显著优于现有的 CNN 和基于扩散的方法。


产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 荣耀MagicBook X 16 2023:性价比之选 预计售价3000元左右
- 7月5日消息,荣耀计划于今晚19点左右正式发布全新笔记本电脑MagicBookX162023。该产品以轻薄高性能和品质标杆为主打,预计售价约为3000元左右,预计将在市场上展现出较高的性价比。据介绍页面显示,荣耀笔记本电脑MagicBookX162023采用英特尔的12代酷睿i512450H处理器,拥有八核心十二线程,并配备了全新颠覆性能的混合CPU架构和Intel7工艺。该处理器的单核睿频最高可达4.4GHz,带来出色的性能表现。据小编了解,这款笔记本电脑配备一块16英寸大尺寸屏幕,分辨率为1920×1
- 9分钟前 0
-
 正版软件
正版软件
- 媒体播放器通用框架 FFmpeg 7.0 发布,带来原生 VVC 解码器
- 本站4月5日消息,流行的开源多媒体框架FFmpeg大约每6个月发布一次主线版本更新,而今天就推出了代号为Dijkstra的7.0版本。此版本修复了多个bug,提高了性能和稳定性。对于大多数用户来说,7.0+版本得到注意的更新之处在于:原生VVC解码器(目前处于实验阶段)得到支持,以及IAMF的支持,以及多线程FFmpeg命令行工具。“本站备注:FFmpeg是一个开放源码的自由软件,可以执行音频和视频多种格式的录影、转换、串流功能,包含了libavcodec——这是一个用于多个项目中音频和视频的解码器库,以
- 15分钟前 框架 解码器 FFmpeg 0
-
 正版软件
正版软件
- 甲骨文宠儿力压GPT-4斩获竞技场首胜,不绑定厂商,不做聊天机器人,Transformer最年轻作者带飞大模型创业新星
- 编辑|诺亚、伊风出品|51CTO技术栈(微信号:blog51cto)近日在开源模型界,CommandR+风头正劲。在Arena榜单上,按下Command+R键超过13000名支持者的票,一次跃升至第6位,其表现为GPT-4-0314旗帜相当!在一众对垒GPT-4的开放权重模型中,斩获该榜单有史以来的首胜。图源:https://twitter.com/lmsysorg/status/17776301337而Arena榜单,是近日用纯C语言手搓GPT-2的AI大神AndrejKarpathy提过的唯二信任的测
- 30分钟前 GPT-4 AI 机器人 0
-
 正版软件
正版软件
- 变形金刚主题联名款,雷神带来全新电子产品系列
- 5月30日消息,雷神宣布与变形金刚展开新一轮合作,将推出一系列联名款新品。据透露,雷神将以变形金刚经典形象为灵感,1:1还原复刻擎天柱,并将此形象应用于桌面显示器、键鼠、笔记本电脑和电脑主机以及路由器等多个产品上。预计这一系列新品将于6月3日开始预售。雷神此次与变形金刚的联名款产品不仅限于电脑领域,而是涵盖了多个电子产品类别。根据官方宣布的消息,雷神将推出一款联名款桌面显示器,该显示器将采用变形金刚的经典形象进行设计,给用户带来全新的视觉体验。此外,联名款键鼠套装也将是雷神与变形金刚合作的亮点之一。据小编
- 45分钟前 雷神 0
-
 正版软件
正版软件
- 新款奥迪A8L Horch创始人版豪华上市,售价公布引领尊贵风潮
- 最新款奥迪A8LHorch创始人版近日发布,推出了两款不同配置的车型,价格分别为130.00万元和207.68万元。这款旗舰轿车在外观和内饰方面都进行了全面升级,同时还提供了多样化的个性化定制选项。这一款车型的推出对于热爱汽车的消费者来说是一次不可错过的体验,让他们可以享受到更高级、更奢华的驾驶体验。新款奥迪A8LHorch创始人版在外观设计上延续了现款车型的经典元素,如六横十二纵的镀铬前中网和两侧的数字矩阵式LED大灯。车身侧面的Horch&Cie王冠标识和20寸轮毂上的“H”王冠徽标则凸显了其独特身份
- 1小时前 10:50 奥迪 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1842天前
-
 2
2
- Overture设置踏板标记的方法
- 1679天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1669天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1867天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1833天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1829天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1844天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1865天前
-
 9
9
相关推荐
- 荣耀MagicBook X 16 2023:性价比之选 预计售价3000元左右
- 媒体播放器通用框架 FFmpeg 7.0 发布,带来原生 VVC 解码器
- 甲骨文宠儿力压GPT-4斩获竞技场首胜,不绑定厂商,不做聊天机器人,Transformer最年轻作者带飞大模型创业新星
- 变形金刚主题联名款,雷神带来全新电子产品系列
- 新款奥迪A8L Horch创始人版豪华上市,售价公布引领尊贵风潮
- 2024款睿蓝X3 PRO CVT小新版闪亮上市
- 大模型加持后,数字人“更像人”了吗?
- 蔚来李斌谈150度电池包:象征意义大于实际意义
- 英特尔推出 PresentMon 2.0 版本更新,优化 FPS 帧数指标参考点
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00