本文经自动驾驶之心公众号授权转载,转载请联系出处。
论文:Fully Sparse 3D Panoptic Occupancy Prediction
链接:https://arxiv.org/pdf/2312.17118.pdf
这篇论文的出发点是什么?
占用预测在自动驾驶领域扮演着重要的角色。然而,传统的方法常常构建密集的3D体积,忽略了场景的稀疏性,从而导致高计算成本。此外,这些方法只能进行语义占用的预测,无法区分不同的实例。为了利用稀疏性并实现实例感知,研究人员引入了一种全新的完全稀疏全景占用网络,即SparseOcc。SparseOcc首先通过视觉输入重建稀疏的3D表示。随后,它利用稀疏实例查询来预测每个目标实例。通过这种方法,SparseOcc能够更高效地进行占用预测,并且能够区分不同的实例。这对于自动驾驶系统的性能提升至关重要。
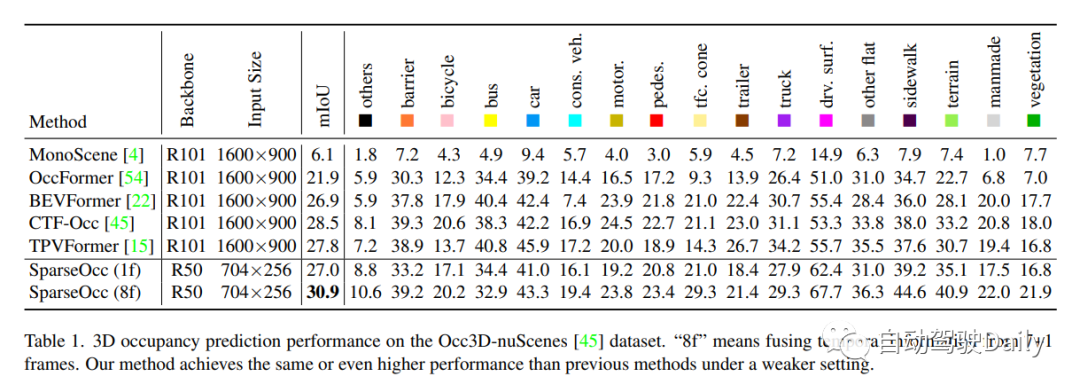
此外,作者还提出了第一个以视觉为中心的全景占用基准——SparseOcc。在Occ3D nus数据集上,SparseOcc实现了26.0的mIoU,并且能够保持每秒25.4帧的实时推理速度。此外,通过结合前8帧的时间建模,SparseOcc的性能进一步提升,达到了30.9的mIoU。作者还表示将在之后开源SparseOcc的代码。
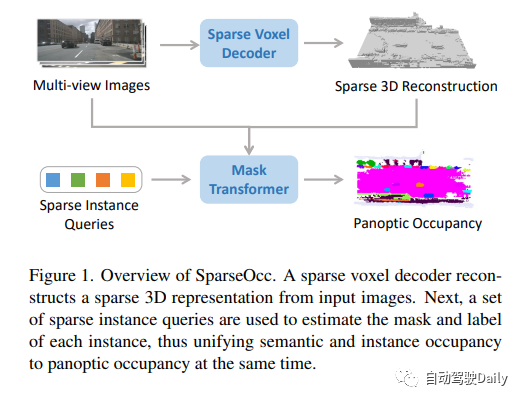
SparseOcc的结构和流程
SparseOcc包含两个主要步骤。首先,作者提出了一种稀疏体素解码器,用于重建场景的稀疏几何结构。该解码器仅对场景的非自由区域进行建模,从而显著减少了计算资源的消耗。其次,他们设计了一个mask transformer,利用稀疏实例查询来预测稀疏空间中每个目标的mask和标签。这个步骤有助于精确定位和识别目标。通过这两个步骤的组合,SparseOcc实现了高效的场景重建和目标分割。
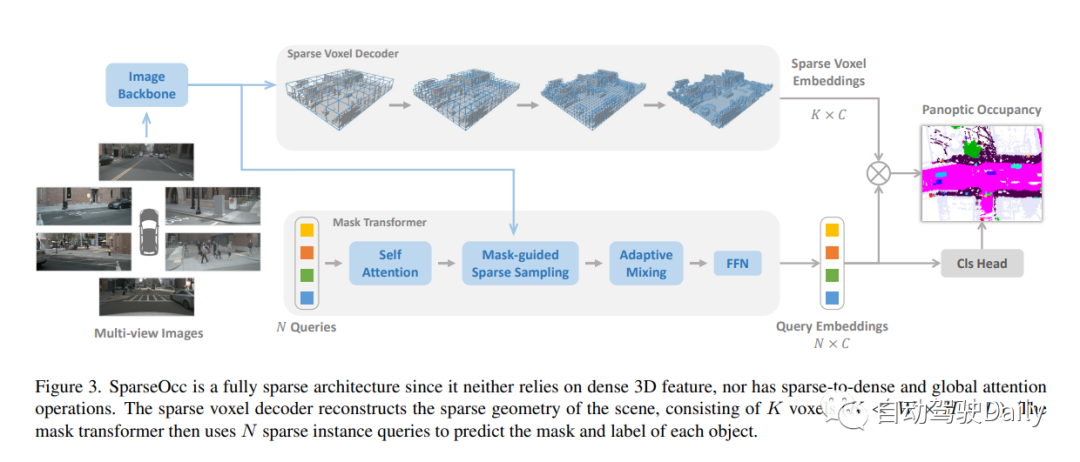
作者还提出了mask-guide的稀疏采样方法,以避免mask变换中的密集交叉注意。这样,SparseOcc可以同时利用这两种稀疏特性,形成完全稀疏的架构。它既不依赖于密集的3D特征,也不需要稀疏到密集的全局注意力操作。同时,SparseOcc还能够区分场景中的不同实例,将语义占用和实例占用统一为全景占用。
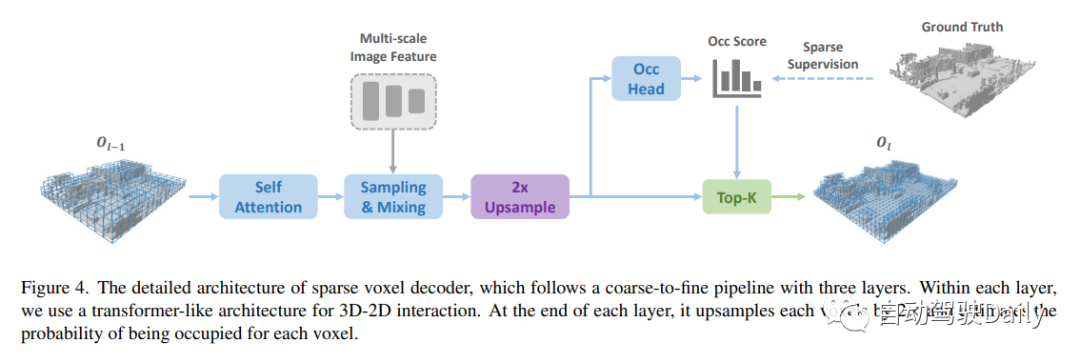
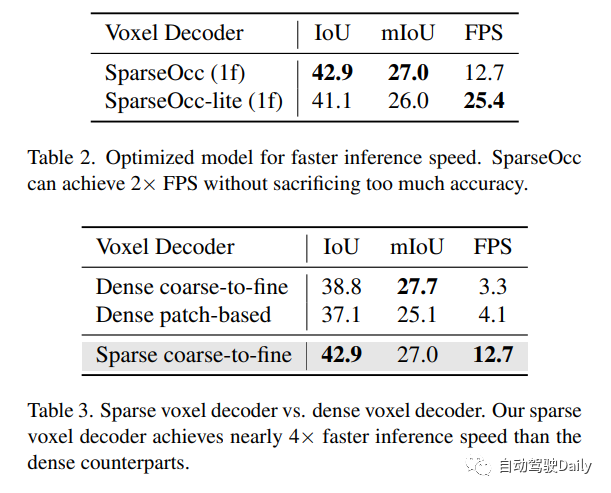
设计的稀疏体素解码器如图4所示。通常,它遵循从粗到细的结构,但采用一组稀疏的体素标记作为输入。在每个层的末尾,我们估计每个体素的占用分数,并基于预测的分数进行稀疏化。在这里,有两种稀疏化方法,一种是基于阈值(例如,仅保持分数>0.5),另一种是根据top-k。在这项工作中,作者选择top-k,因为阈值处理会导致样本长度不相等,影响训练效率。k是与数据集相关的参数,通过以不同分辨率对每个样本中非自由体素的最大数量进行计数而获得,稀疏化后的体素标记将用作下一层的输入!
时序建模。先前的密集占用方法通常将历史BEV/3D特征warp到当前时间戳,并使用可变形注意力或3D卷积来融合时间信息。然而,这种方法不适用于我们的情况,因为3D特征是稀疏的。为了处理这一问题,作者利用采样点的灵活性,将它们wrap到以前的时间戳来对图像特征进行采样。来自多个时间戳的采样特征通过自适应混合进行叠加和聚合。
loss设计:对每一层都进行监督。由于在这一步中重建了一个类不可知的占用,使用二进制交叉熵(BCE)损失来监督占用头。只监督一组稀疏的位置(根据预测的占用率),这意味着在早期阶段丢弃的区域将不会受到监督。
此外,由于严重的类别不平衡,模型很容易被比例较大的类别所支配,如地面,从而忽略场景中的其他重要元素,如汽车、人等。因此,属于不同类别的体素被分配不同的损失权重。例如,属于类c的体素分配有的损失权重为:
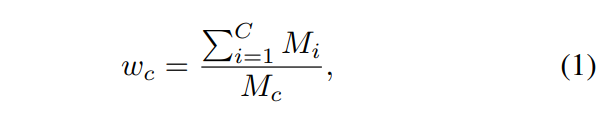
其中Mi是GT中属于第i类的体素的数量!
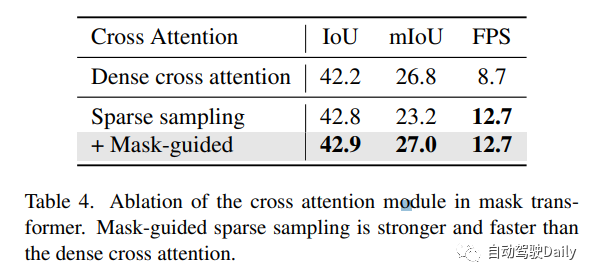
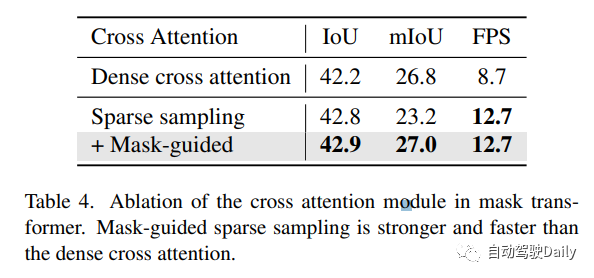
mask引导的稀疏采样。mask transformer的一个简单基线是使用Mask2Former中的mask交叉注意模块。然而,它涉及关键点的所有位置,这可能是非常繁重的计算。在这里,作者设计了一个简单的替代方案。给定前一个(l−1)Transformer解码器层的mask预测,通过随机选择掩码内的体素来生成一组3D采样点。这些采样点被投影到图像以对图像特征进行采样。此外,我们的稀疏采样机制通过简单地warp采样点(如在稀疏体素解码器中所做的那样)使时间建模更容易。

实验结果
Occ3D nuScenes数据集上的3D占用预测性能。“8f”意味着融合来自7+1帧的时间信息。本文的方法在较弱的设置下实现了与以前的方法相同甚至更高的性能!
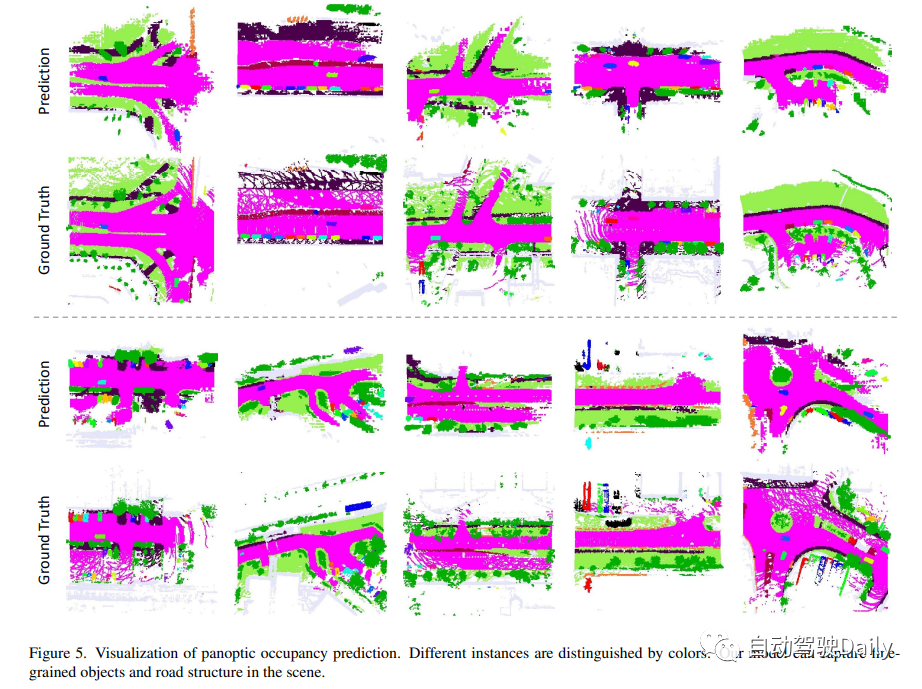
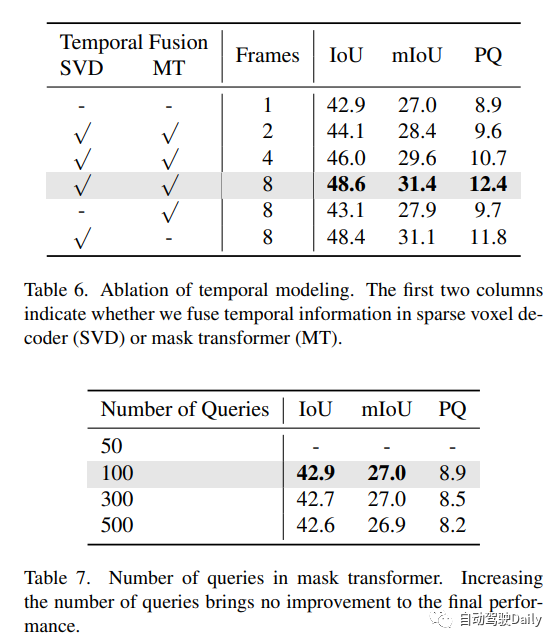
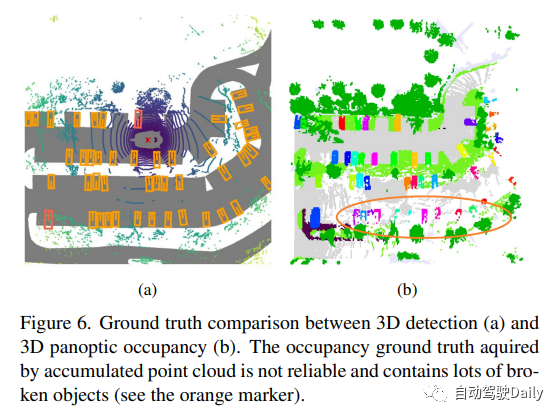

原文链接:https://mp.weixin.qq.com/s/CX18meq6DZcIhi0_DElfMw



