华为推出新款盘古Agent,帮助智能体学会结构化推理能力
 发布于2024-11-06 阅读(0)
发布于2024-11-06 阅读(0)
扫一扫,手机访问
自 AI 诞生以来,开发能够解决和适应复杂工作的多任务智能体(Agent)一直是个重要的目标。
AI的智能体在许多应用中至关重要,研究人员经常使用强化学习方法来训练智能体的决策能力,通过与环境的互动来实现。基于模型和无模型的深度强化学习方法已经取得了很多人所熟知的成就,比如AlphaZero、改进的排序和乘法算法、无人机竞速以及聚变反应堆中的等离子体控制。这些成功案例都涉及到一个标准的强化学习流程,智能体在其中学习外部功能,即直接与外界互动以最大化奖励信号的策略。这个功能通常是由参数化神经网络生成动作,根据环境观测来决定
经典的强化学习方法使用单个映射函数来定义策略 π,但在复杂的环境中通常被证明是不够的,这与通用智能体在多个随机环境中交互、适应和学习的目标相矛盾。
在强化学习中,引入的先验通常是特定于任务的,并且需要广泛的工程和领域专业知识。为了实现泛化,最近的研究已经开始将大型语言模型(LLM)整合到智能体框架中,例如AutoGen、AutoGPT和AgentVerse等相关工作
近日,来自华为诺亚方舟实验室、伦敦大学学院(UCL)、牛津大学等机构的研究者提出了盘古智能体框架(Pangu-Agent)尝试来解决 AI 智能体面临的挑战。该研究作者包括伦敦大学学院计算机系教授汪军。

论文链接:请点击此处查看论文https://arxiv.org/abs/2312.14878
该工作在两个关键方面区别于先前的框架:i)将智能体的内部思维过程形式化为结构化推理的形式;ii)展示了通过监督学习和强化学习来微调智能体的方法。
标准强化学习侧重于直接学习从感知中输出行动的策略。虽然人们习惯于通过深度网络架构参数化策略,但作者认为,当通过基础模型策略跨任务扩展智能体时,标准 RL 管道中缺乏固有推理结构可能会成为一个重大瓶颈,因为梯度无法为所有深度网络提供足够的监督。
盘古 Agent 框架展示了结构化推理如何帮助强化学习克服这些挑战,利用大规模基础模型提供先验知识并实现跨广泛领域的泛化能力。
根据介绍,此工作的主要贡献包括:
- 证明了结构化推理在智能体框架中的重要性,盘古 Agent 的通用性足以有效涵盖现有智能体框架的任务范围。作为一个元智能体框架,它可以利用内部函数调用的顺序进行调整或微调,或者将决策委托给底层 LLM。使用者也可以轻松扩展智能体的功能,并组合或重用许多已经实现的方法。
- 作者在七个 LLM 和六个不同领域上进行了评估。该评估可用于告知研究人员如何初始化其智能体以及如何收集微调步骤的数据。
- 研究证明了框架的监督微调(SFT)和强化学习微调(RLFT)的影响。通过结构化推理,该工作成功实现了基于拒绝采样的 SFT 管道,大幅提高了 LLM 在 ALFWorld 领域的表现,成功率从 27% 增加到 82%。尽管 SFT 的好处已趋于稳定,但通过 RL 可以实现进一步增强,将 BabyAI 任务的成功率提高到 88%,甚至从 28% 提高到 91%。此外,跨领域实验显示通过 RL 管道训练的单个 LLM 能够同时在 ALFWorld (82%) 和 BabyAI(18 项任务中平均 58.7%)领域实现高性能。
这些发现突显了在基于大型模型训练智能体方面,结构化推理具有巨大的潜力
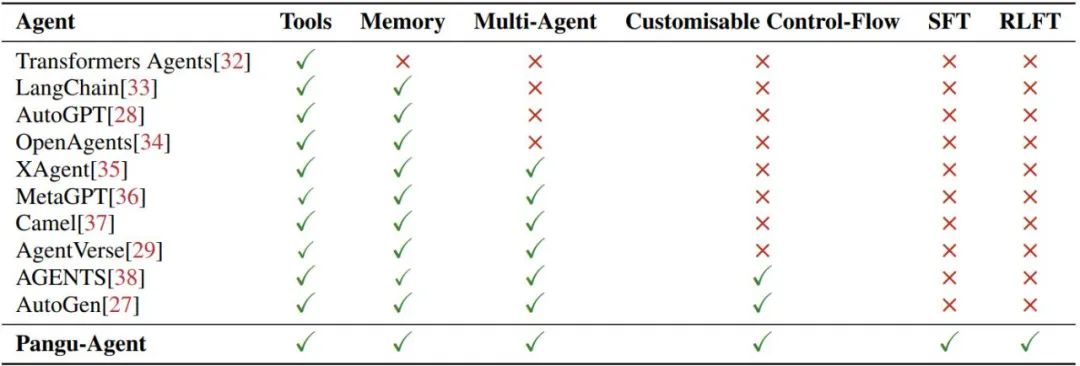 表 1:盘古 Agent 与最近一些大模型智能体的比较。
表 1:盘古 Agent 与最近一些大模型智能体的比较。
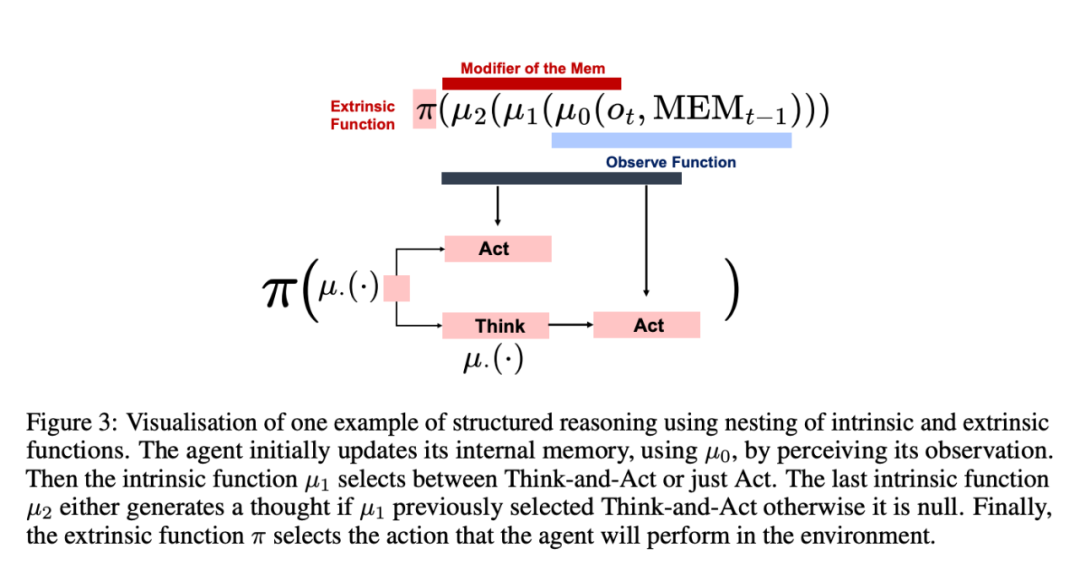
 图 2:三个内在函数的可视化,展示了该工作提出的范式在提高代理的模块化和灵活性方面的重要性。用户可以重新定义和重新配置内在函数,例如 µ1 (・) 以 LLM 作为输入来产生想法,或 µ2 (・) 利用工具来帮助改进推理。新智能体还支持嵌套这些内在函数来构建更通用的模块,以完成复杂且具有挑战性的决策任务。
图 2:三个内在函数的可视化,展示了该工作提出的范式在提高代理的模块化和灵活性方面的重要性。用户可以重新定义和重新配置内在函数,例如 µ1 (・) 以 LLM 作为输入来产生想法,或 µ2 (・) 利用工具来帮助改进推理。新智能体还支持嵌套这些内在函数来构建更通用的模块,以完成复杂且具有挑战性的决策任务。
Pangu-Agent 的范式
为了引入结构化推理,我们假设一系列内在函数 µ(・) 作用于并转换智能体的内部记忆。引入这些内在函数可以将典型的强化学习目标重新表述为支持多个「思考」步骤的目标。因此,典型的 RL 目标旨在找到一个以观察 o→ 的历史为条件的策略 π,以最大化回报 R,即 maxπ(・) R (π(・|o→)) 可以使用嵌套集重写(参见图 . 2) 内函数 µ→ (・) 为:
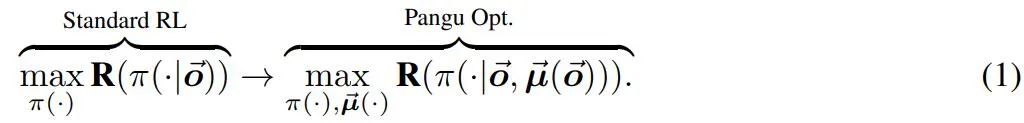
作者强调需要将这些函数与外部函数分开定义、学习和使用,这样用户就可以重新定义任何被认为对其任务有帮助的任意嵌套。我们可以根据方程重写盘古智能体的优化问题。更详细的形式为: 作者强调需要将这些函数与外部函数分开定义、学习和使用,这样用户就可以重新定义任何被认为对其任务有帮助的任意嵌套。我们可以根据方程重写盘古智能体的优化问题。更详细的形式为:作者强调需要将这些函数与外部函数分开定义、学习和使用,这样用户就可以重新定义任何被认为对其任务有帮助的任意嵌套。我们可以根据方程重写盘古智能体的优化问题。更详细的形式为:
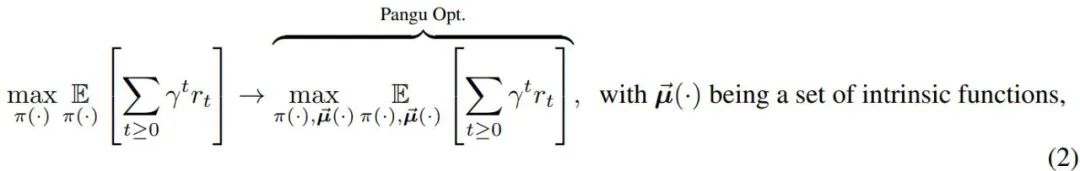
其中 rt 是时间步 t 的奖励,取决于环境观察 ot 和行动 at。此外,γ ∈ [0, 1) 是一个折扣因子,指定奖励随时间折扣的程度。外部函数仍然充当与外界交互的执行器,而那些额外分层的内部函数旨在封装系统架构师认为有益的任何内部推理过程。
有关 Pangu-Agent 的框架结构,内在函数是对代理的内存状态进行操作的一系列函数。内在函数对于塑造智能体的内部状态至关重要,并且可以影响其决策过程。通过利用这些功能,智能体可以根据观察历史和先前的知识调整其记忆状态,从而做出更明智且适合上下文的决策。
外部函数的目的是从语言模型中引发环境交互。与对智能体的内存状态进行操作的内部函数不同,外部函数通过生成要执行的动作来直接与环境交互。
盘古 Agent 公式的灵活性意味着可以分层创建许多复合方法。此外应该指出的是,该工作在盘古 Agent 代码库中提供的这些复合方法的实现并不总是原始算法的忠实再现,因为它们需要特定的任务细节。
受到最近搜索增强的 LLM 研究的启发,盘古 Agent 框架集成了三种树搜索算法 – 广度优先 / 深度优先搜索 (BFS/DFS) 和 蒙特卡洛树搜索(MCTS),以提高 LLM 的生成和决策能力的规划能力。具体来说,该框架利用 LLM 作为策略、模型和价值函数。通过与这个基于 LLM 的模拟环境交互,我们就可以构建一个 rollout 树,该树将使用树搜索算法进一步修剪,以实现更好的操作 / 生成效果。
盘古 Agent 兼容一系列任务,例如 ALFWorld、GSM8K、HotpotQA、WebShop 等。它的交互界面与 OpenAI Gym 类似,是一种开放式设计。
最后,该框架包含一个模板系统来为 LLM 生成输入提示词(Prompt),使用模板增强了提示制作的灵活性。
评估
最终,研究人员对Pangu-Agent的各种方法进行了全面的评估
首先,研究者考虑使用一阶嵌套法和复合法评估Pangu-Agent的结构推理能力(见图3);随后,利用监督学习和强化学习在三种不同的环境中评估Pangu-Agent的微调能力。结果显示,就Agent获得的收益而言,复合方法往往优于一阶嵌套方法。研究者表示,通过SFT和RLFT,Agent能够实现专业化,并进一步提高其在ALFWorld和BabyAI任务中的收益。在整个评估过程中,研究者测试了多种LLM,如GPT、Llama 2、OpenChat、Vicuna和Mistral
结构化推理评估
通过对内在函数(Intrinsic Functions)的内置支持,可以评估推理结构中的不同设计选择对 AI 智能体性能的影响。
首先在表 2 中,研究者评估了一阶嵌套,即只通过观察环境和对环境执行的操作来修改智能体记忆的设置。在文献中,这些方法被简单地称为不同的提示方法,例如:少样本提示法 (FS)、少样本思维链 (FS-CoT) 、零样本思维链(ZS-CoT)。这些方法的详细介绍见附录 A.1。
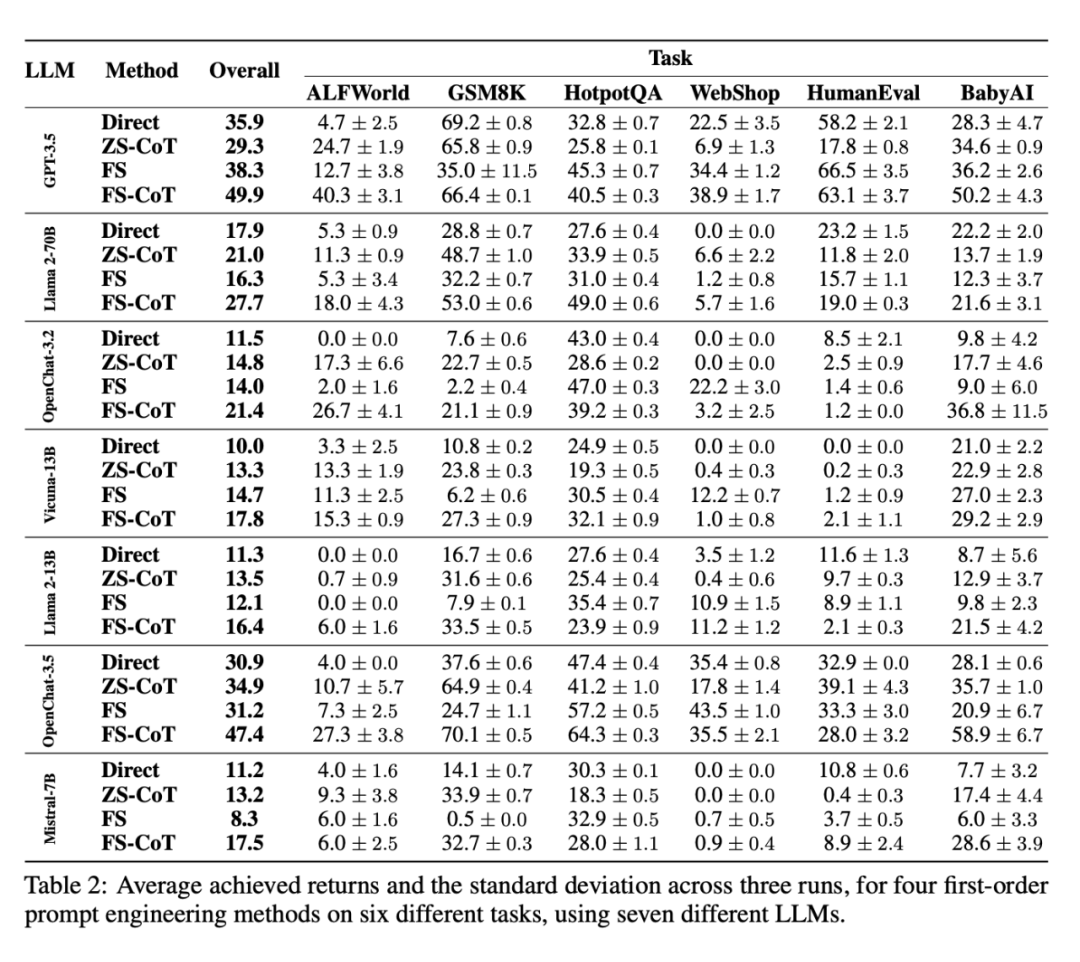
需要注意的是,由于 LLM 文本生成的非确定性,不同的运行所获得的回报可能会有很大差异。为了考虑这些差异,研究者将任务 - 方法 - LLM 的每种组合运行三次,并报告平均标准偏差。但是,一阶嵌套也有局限性,因为它们可能难以充分利用 LLM 的能力。正如此前所述,智能体需要能够处理语言模型的输出、重新查看其答案、更改其记忆,甚至使用工具。这里所说的复合方法是指在决定最终行动之前可能需要多个思考步骤的方法。
表 3 列出了四种复合方法的结果:具有自一致性的 FS-CoT(FS-CoTSC)、具有可选独立思考步骤的 FS-CoT(如 React )、具有映射步骤的 FS-CoT(如 66)、SwiftSage 和 Least-to-Most(另见附录 A.2)。所有这些方法都在每个环境时间步使用了多个固有函数步,缩略语的简要说明可参见表 7。
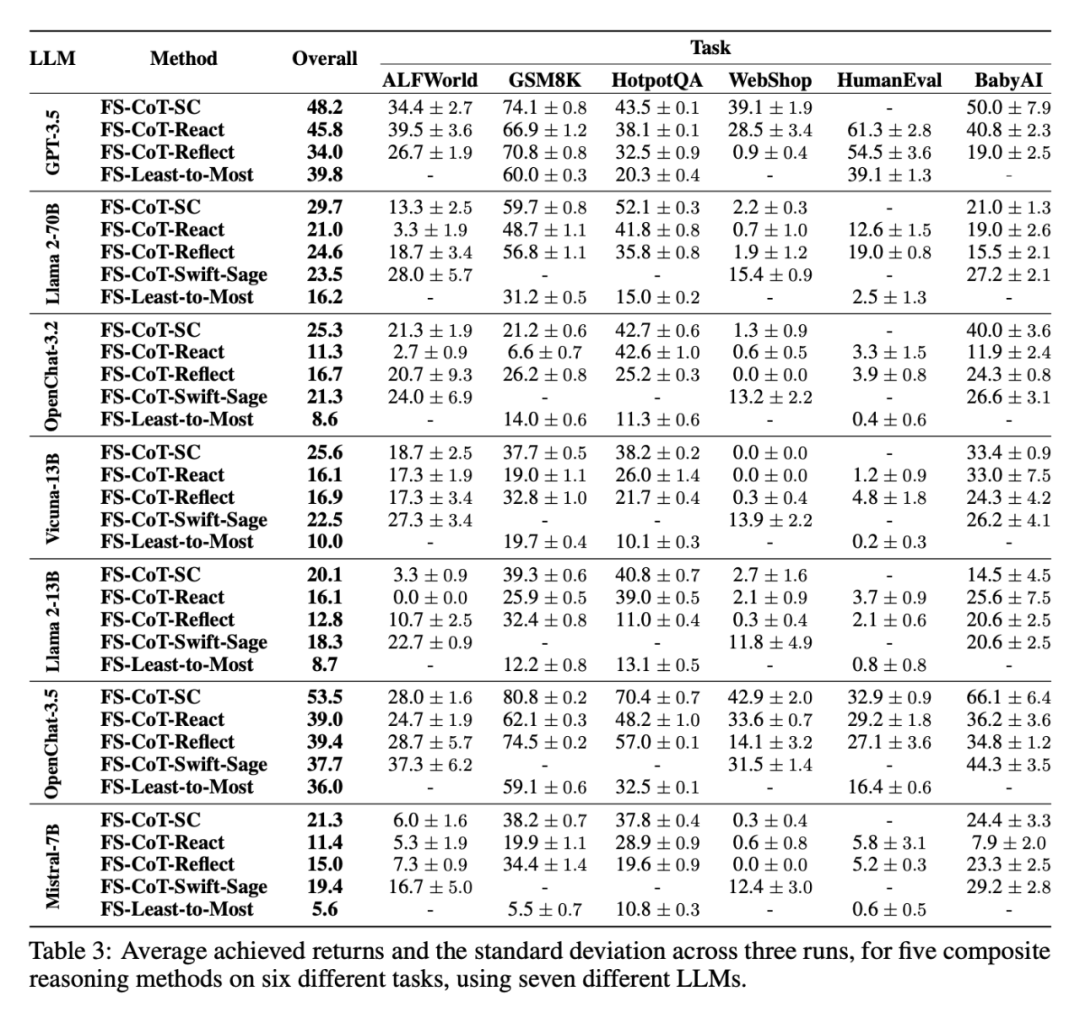
研究者观察到,结构相似但提示内容不同的方法为智能体带来的收益却大相径庭,这说明了精心设计提示的重要性。同样值得注意的是,不同的方法在某些 LLM 中比在其他 LLM 中效果更好,例如 React 在 OpenChat-3.2 中的平均表现比 FS 差,而 React 和 FS 在 GPT-3.5 中的平均收益表现类似。
值得注意的是,在所有 LLM 中,FS 在 GSM8K 中的性能比 Direct 差很多。这并不奇怪,因为 FS 只向 LLM 提供最终答案。因此,LLM 的目的是回答问题,而不需要生成中间步骤。然而,在 Direct 中,即使没有明确要求,LLM 也会生成中间步骤,因为互联网上类似的小学水平问题就是这样呈现的,而这些问题很可能就包含在这些 LLM 的训练集中。在将 ZS-CoT 与 FS 进行比较时,也能得出类似的结论。
在较小的LLM中,这一点尤为明显。研究者推测,如果在提示中添加「逐步思考」(think step-by-step)的引语,模型就更有可能生成能够正确解决当前问题的推理步骤
在 HumanEval 任务中,研究者注意到 GPT-3.5 相比其他模型的收益率差距更大。这可能是因为 HumanEval 是一项编码任务,要求 LLM 提供结构良好的回答。然而,较小规模的开源 LLM 更容易出现这些结构性错误,导致任务失败并获得 0 的评分
妨碍 LLM 性能的另一个因素是有限的上下文长度。在 WebShop 等涉及相对较大观测值的任务中,提示的长度需要截断,以保持在允许的上下文长度范围内。因此,LLM 在这项任务中的表现会受到很大影响,特别是在 Reflect 等方法中,提示中还会包含额外的信息。这也解释了为什么 Reflect 方法在 WebShop 中的表现往往不如其他方法。
在某些情况下,FS-CoT-SC 可以提高 LLM 的收益,尤其是在 GSM8K 中。但是,这需要付出额外的代价,即需要多次提示 LLM(本实验中为 5 次)以执行 SC 操作选择。在 HumanEval 等任务中,答案包含较长的文本答案,可能会有多个答案产生正确的结果,研究者发现无法应用 SC。这是因为 LLM 不会生成与之前相同的答案,而 SC 操作选择器无法选择最常见的答案。
外在函数评估:微调
虽然 LLM 在各种任务的回报率方面表现出色,但在实现 100% 成功率方面仍有很大的改进空间。接下来,研究人员讨论了 SFT 和 RLFT 对 Pangu-Agent 提高成功率的帮助
他们提出了两种不同的流程:一种是由 multi-turn 轨迹生成和 SFT 组成的 Bootstrap SFT (BSFT),另一种是由轨迹生成、SFT 和 RLFT 组成的三步流程。在执行 SFT 时,专家轨迹演示始终使用 OpenChat-3.5 LLM 收集,该 LLM 配备了 Pangu-Agent 框架的结构化推理能力。研究者使用 OpenChat-3.5 LLM 执行 BSFT,而 SFT-RLFT 管道则应用于 Llama 2-7B LLM,并考虑了两种不同的评估范式:为每个任务微调不同的 LLM,以及在多个任务中微调一个 LLM(例如多任务微调)。
One Model per Domain
BSFT:第一个实验展示了 Pangu-Agent 框架提供的固有函数和微调函数的结合。首先从一系列不同的提示方法中收集数据,特别是 ZS-CoT、FS-CoT、FS-CoT-React 和 FS-CoT-Reflect。收集完数据后,运行一个拒绝采样步骤,丢弃失败的轨迹,只保留在折扣回报方面表现最好的轨迹。然后可以在该数据集上执行 SFT 步骤,以进一步提高该方法的性能。表 4 中 「1-step SFT」一栏列出了经过单一 SFT 步骤训练后的模型结果。
根据表4的结果显示,在经过一轮拒绝采样后,模型在ALFWorld中能够表现出很好的性能,同时仍保持了在行动前产生想法的能力

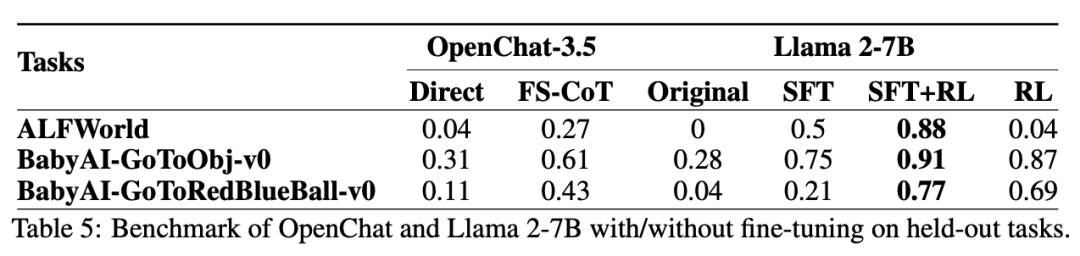
尽管如此,对于这些固有函数生成的完整轨迹进行微调的计算成本很高,而且很快就会达到收益递减的地步。研究者建议在各种任务中使用强化学习来实现更高的性能
如表 5 ,研究者首先对成功演示进行 SFT 微调,然后再进行 RL 微调,成功率的提高幅度最大。对于像 ALFWorld 这样的复杂领域,用于轨迹生成的 SFT 步骤和固有函数(FS-CoT)至关重要。这说明了 Pangu-Agent 框架的重要性,在该框架中,可以从固有函数和微调中获益。
更多研究细节,可参考原论文。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 门罗币在哪买
- 门罗币可以在加密货币交易所(如Binance、Kraken、Bittrex、CoinbasePro)、去中心化交易所(如Uniswap、Sushiswap)和点对点市场(如LocalBitcoins、Paxful)上购买,选择平台时需考虑费用、安全性、可用性、用户界面等因素,创建账户并通过身份验证后即可购买门罗币。
- 12分钟前 0
-
 正版软件
正版软件
- 在国内哪里购买狗狗币
- 在国内可以通过Binance、火币网、OKEx等加密货币交易所购买狗狗币。购买步骤包括:注册账户、实名认证、充值资金、下单购买、存储狗狗币。交易前请充分了解风险,选择信誉良好的交易所,保管好私钥,了解交易规则和费用。在国内哪里购买狗狗币狗狗币是一种加密货币,可以在国内各大加密货币交易所进行购买。BinanceBinance是国内最大的加密货币交易所之一,提供狗狗币的交易服务。火币网火币网也是一家国内知名的加密货币交易所,支持狗狗币的交易。OKExOKEx是另一家国内主流的加密货币交易所,同样提供狗狗币的交
- 17分钟前 0
-
 正版软件
正版软件
- 支付巨头Block开放商家10%销售额直接兑换比特币!会有多少资金?
- 本站(120bTC.coM):旗下拥有加密金融支付服务Square与移动支付应用CashApp的Block,昨(24)日稍晚宣布了一项新计划,允许使用Square服务的商家可将其日销售额的1-10%转入CashApp账户中,并兑换为比特币。Block:许多Square商家对比特币感兴趣Block对此解释称,比特币是一种经济赋权工具,许多使用Square服务的商家都对比特币感兴趣:比特币是一种经济赋权工具,为包括企业在内的全球经济参与者提供了一种参与货币体系创新的方式。根据Square相关商家的反应,他们许
- 32分钟前 比特币减半 比特币汇率 比特币支付 ArcBlock 0
-
 正版软件
正版软件
- 上周加密市场共发生 35 起公开融资事件,累计融资约 5.35 亿美元 | 投融资周报
- 整理:饼干,RootData据RootData不完全统计,2024年4月8日-4月14日期间,区块链和加密行业共发生35起公开投融资事件,累计融资约5.35亿美元。从赛道分布来看,获得融资的项目主要分布在基础设施和DeFi赛道。最热门的标签是Layer1公链,其中EVM并行化区块链Monad完成由Paradigm领投2.25亿美元,这是2024年迄今为止最大的加密货币领域融资。基于DeFi的EVM兼容链Berachain完成1亿美元B轮融资,FrameworkVentures等领投。其他热门项目还有ZK-
- 47分钟前 0
-
 正版软件
正版软件
- 钱包代币地址怎么改
- 要更改钱包代币地址,需要按以下步骤进行:1.备份钱包;2.选择并创建新代币地址;3.打开钱包配置文件并添加以下行:addresstype=legacyaddress=NEW_TOKEN_ADDRESS;4.保存配置文件并重新启动钱包,钱包将扫描并添加新地址。
- 1小时前 19:54 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1858天前
-
 2
2
- Overture设置踏板标记的方法
- 1695天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1685天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1883天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1849天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1845天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1860天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1881天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00