进阶版Lightning Attention-2:无限序列长度、持续稳定计算力、增强建模精度
 发布于2024-11-14 阅读(0)
发布于2024-11-14 阅读(0)
扫一扫,手机访问
当前大语言模型的应用受到了序列长度限制的制约,这限制了其在人工智能领域中的应用。例如,在多轮对话、长文本理解和多模态数据处理与生成方面存在一定的挑战。造成这种限制的根本原因是目前大语言模型普遍采用的Transformer架构,其计算复杂度与序列长度呈二次关系。因此,随着序列长度的增加,计算资源的需求会呈几何倍数增长。因此,如何高效地处理长序列一直是大语言模型所面临的挑战之一。
过去的方法主要集中在让大语言模型在推理阶段适应更长的序列。其中一种方法是采用Alibi或类似的相对位置编码,以使模型能够自适应不同长度的输入序列。另一种方法是使用RoPE或类似的相对位置编码进行差值,对已经训练完成的模型进行短暂的微调,以扩展序列长度。这些方法使得大模型具备了一定的长序列建模能力,但训练和推理的开销并未减少。
OpenNLPLab团队开源了一种名为Lightning Attention-2的新型线性注意力机制,旨在解决大语言模型长序列问题。这种机制使得训练和推理长序列与1K序列长度的成本保持一致,从而实现了一劳永逸的解决方案。即使在遇到显存瓶颈之前,增加序列长度也不会对模型训练速度产生负面影响,因此可以实现无限长度的预训练。此外,与1K Tokens相比,超长文本的推理成本也保持一致甚至更低,从而极大地降低了当前大语言模型的推理成本。如下图所示,当模型大小为400M、1B和3B时,随着序列长度的增加,FlashAttention2加持的LLaMA的训练速度开始快速下降,而Lightning Attention-2加持的TansNormerLLM的速度几乎没有变化。
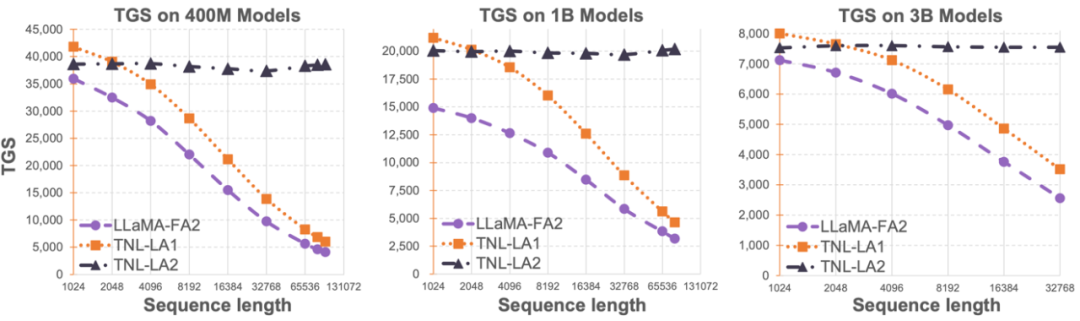
图 1

- 论文:Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
- 论文地址:https://arxiv.org/pdf/2401.04658.pdf
- 开源地址:https://github.com/OpenNLPLab/lightning-attention
Lightning Attention-2 简介
让大模型的预训练速度在不同序列长度下保持一致听起来是一个不可能的任务。然而,自从2020年线性注意力横空出世以来,研究人员一直在努力使线性注意力的实际效率符合其理论线性计算复杂度。在2023年中期之前,关于线性注意力的研究主要集中在与Transformer架构的精度对齐上。终于,在改进的线性注意力机制问世后,它在精度上能够与最先进的Transformer架构相媲美。 然而,线性注意力中最关键的“左乘变右乘”的计算trick在实际实现中远慢于直接左乘的算法。这是因为右乘的实现需要使用包含大量循环操作的累积求和(cumsum),而大量的I/O操作使得右乘的效率远低于左乘。 因此,要让大模型的预训练速度在不同序列长度下保持一致,仍然面临着挑战。研究人员需要进一步探索和改进线性注意力的实现方式,以提高其计算效率并减少I/O操作。这将有助于实现预训练速度的一致性,从而更好地应对不同序列长度的任务需求。
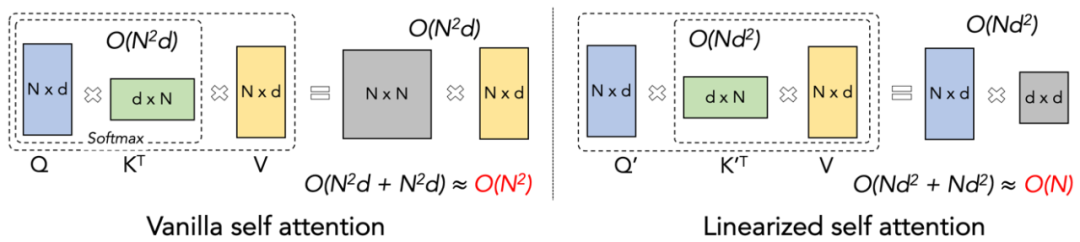
图 2
为了更好的理解 Lightning Attention-2 的思路,让我们先回顾下传统 softmax attention 的计算公式:O=softmax ((QK^T)⊙M_) V,其中 Q, K, V, M, O 分别为 query, key, value, mask 和输出矩阵,这里的 M 在单向任务(如 GPT)中是一个下三角的全 1 矩阵,在双向任务(如 Bert)中则可以忽略,即双向任务没有 mask 矩阵。
作者将 Lightning Attention-2 的整体思路总结为以下三点进行解释:
1. Linear Attention 的核心思想之一就是去除了计算成本高昂的 softmax 算子,使 Attention 的计算公式可以写为 O=((QK^T)⊙M_) V。但由于单向任务中 mask 矩阵 M 的存在,使得该形式依然只能进行左乘计算,从而不能获得 O (N) 的复杂度。但对于双向任务,由于没有没有 mask 矩阵,Linear Attention 的计算公式可以进一步简化为 O=(QK^T) V。Linear Attention 的精妙之处在于,仅仅利用简单的矩阵乘法结合律,其计算公式就可以进一步转化为:O=Q (K^T V),这种计算形式被称为右乘,相对应的前者为左乘。通过图 2 可以直观地理解到 Linear Attention 在双向任务中可以达到诱人的 O (N) 复杂度!
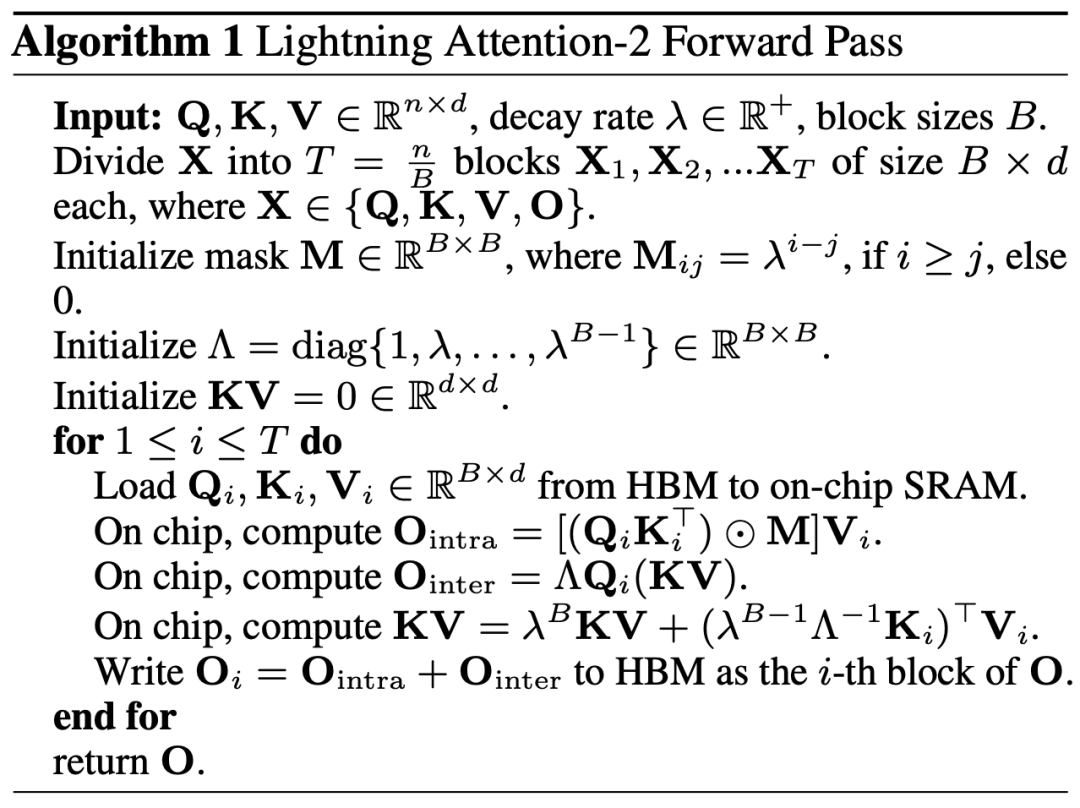
2. 但是随着 decoder-only 的 GPT 形式的模型逐渐成为 LLM 的事实标准,如何利用 Linear Attention 的右乘特性加速单向任务成为了亟待解决的难题。为了解决这个问题,本文作者提出了利用 “分而治之” 的思想,将注意力矩阵的计算分为对角阵和非对角阵两种形式,并采用不同的方式对他们进行计算。如图 3 所示,Linear Attention-2 利用计算机领域常用的 Tiling 思想,将 Q, K, V 矩阵分别切分为了相同数量的块 (blocks)。其中 block 自身(intra-block)的计算由于 mask 矩阵的存在,依然保留左乘计算的方式,具有 O (N^2) 的复杂度;而 block 之间(inter-block)的计算由于没有 mask 矩阵的存在,可以采用右乘计算方式,从而享受到 O (N) 的复杂度。两者分别计算完成后,可以直接相加得到对应第 i 块的 Linear Attention 输出 Oi。同时,通过 cumsum 对 KV 的状态进行累积以在下一个 block 的计算中使用。这样就得到了整个 Lightning Attention-2 的算法复杂度为 intra-block 的 O (N^2) 和 inter-block 的 O (N) 的 Trade-off。怎么取得更好的 Trade-off 则是由 Tiling 的 block size 决定的。
3. 细心的读者会发现,以上的过程只是 Lightning Attention-2 的算法部分,之所以取名 Lightning 是因为作者充分考虑了该算法过程在 GPU 硬件执行过程中的效率问题。受到 FlashAttention 系列工作的启发,实际在 GPU 上进行计算的时候,作者将切分后的 Q_i, K_i, V_i 张量从 GPU 内部速度更慢容量更大的 HBM 搬运到速度更快容量更小的 SRAM 上进行计算,从而减少大量的 memory IO 开销。当该 block 完成 Linear Attention 的计算之后,其输出结果 O_i 又会被搬回至 HBM。重复这个过程直到所有 block 被处理完毕即可。
想要了解更多细节的读者可以仔细阅读本文中的 Algorithm 1 和 Algorithm 2,以及论文中的详细推导过程。Algorithm 以及推导过程都对 Lightning Attention-2 的前向和反向过程进行了区分,可以帮助读者有更深入的理解。
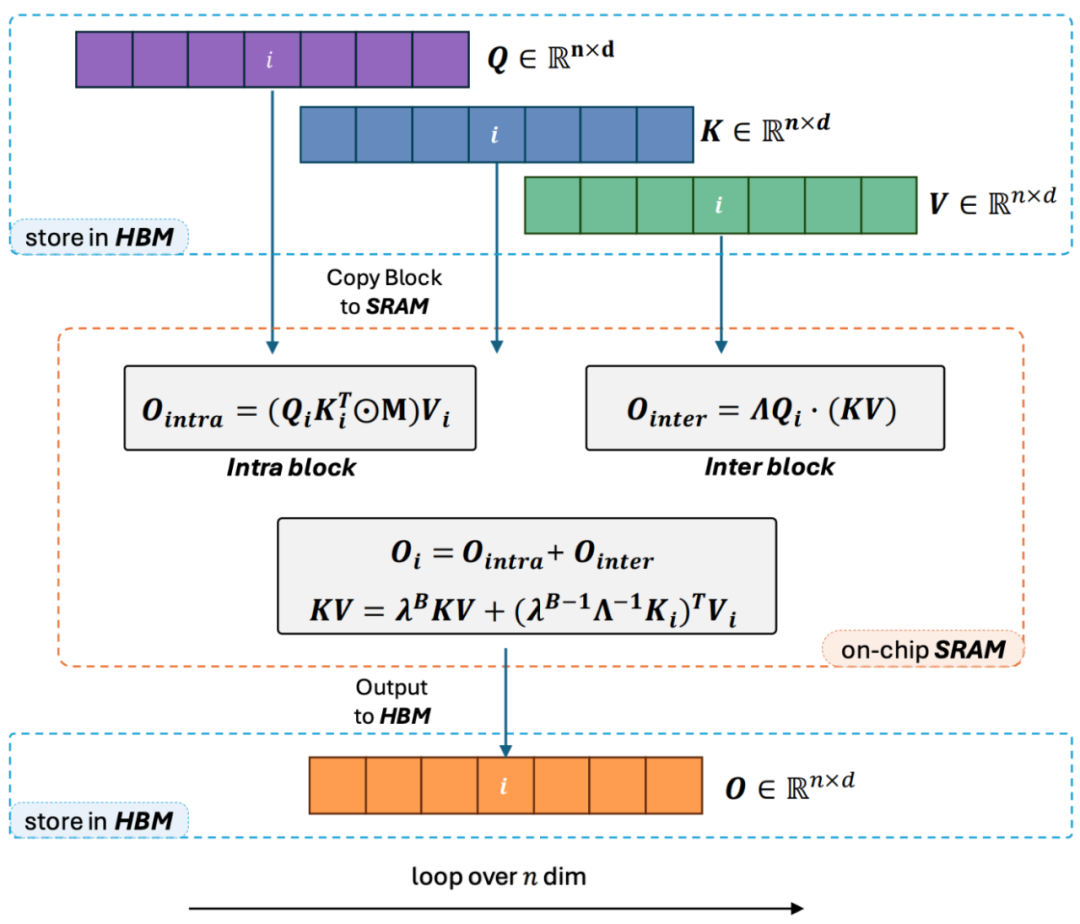
图 3

Lightning Attention-2 精度对比
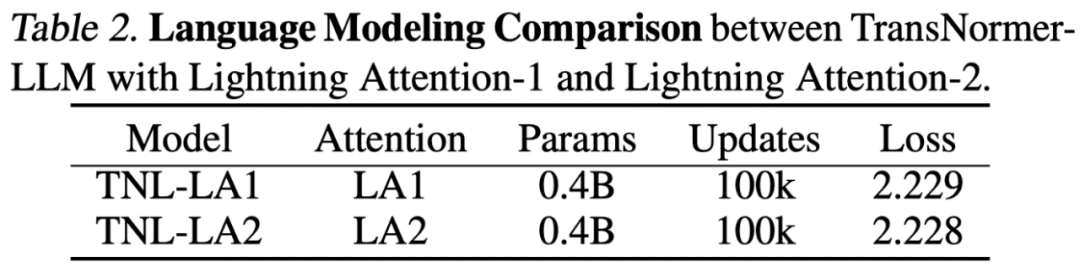
研究人员首先在小规模(400M)参数模型上对比了 Lightning Attention-2 与 Lightning Attention-1 的精度区别,如下图所示,二者几无差别。
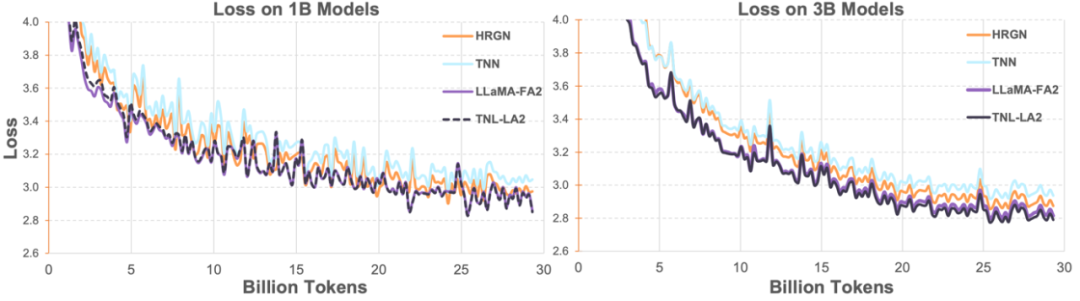
随后研究人员在 1B、3B 上将 Lightning Attention-2 加持的 TransNormerLLM(TNL-LA2)与其它先进的非 Transformer 架构的网络以及 FlashAttention2 加持的 LLaMA 在相同的语料下做了对比。如下图所示,TNL-LA2 与 LLaMA 保持了相似的趋势,并且 loss 的表现更优。这个实验表明,Lightning Attention-2 在语言建模方面有着不逊于最先进的 Transformer 架构的精度表现。
在大语言模型任务中,研究人员对比了 TNL-LA2 15B 与 Pythia 在类似大小下的大模型常见 Benchmark 的结果。如下表所示,在吃掉了相同 tokens 的条件下,TNL-LA2 在常识推理和多项选择综合能力上均略高于基于 Softmax 的注意力的 Pythia 模型。

Lightning Attention-2 速度对比
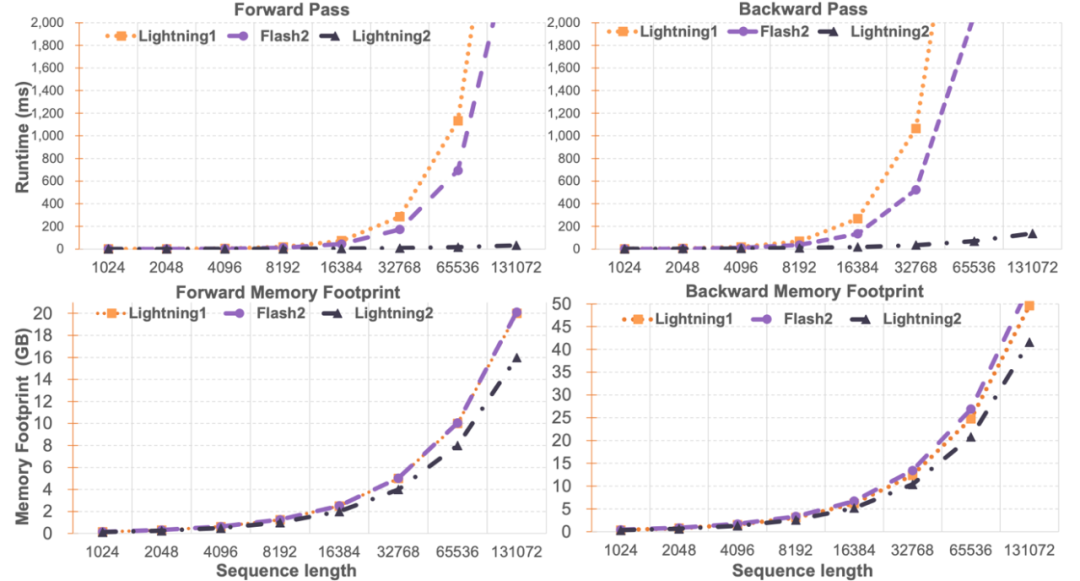
研究人员对 Lightning Attention-2 与 FlashAttention2 进行了单模块速度与显存占用对比。如下图所示,相比于 Lightning Attention-1 和 FlashAttention2,在速度上,Lightning Attention-2 表现出了相比于序列长度的严格线性增长。在显存占用上,三者均显示出了类似的趋势,但 Lightning Attention-2 的显存占用更小。这个的原因是 FlashAttention2 和 Lightning Attention-1 的显存占用也是近似线性的。
笔者注意到,这篇文章主要关注点在解决线性注意力网络的训练速度上,并实现了任意长度的长序列与 1K 序列相似的训练速度。在推理速度上,并没有过多的介绍。这是因为线性注意力在推理的时候可以无损地转化为 RNN 模式,从而达到类似的效果,即推理单 token 的速度恒定。对于 Transformer 来说,当前 token 的推理速度与它之前的 token 数量相关。
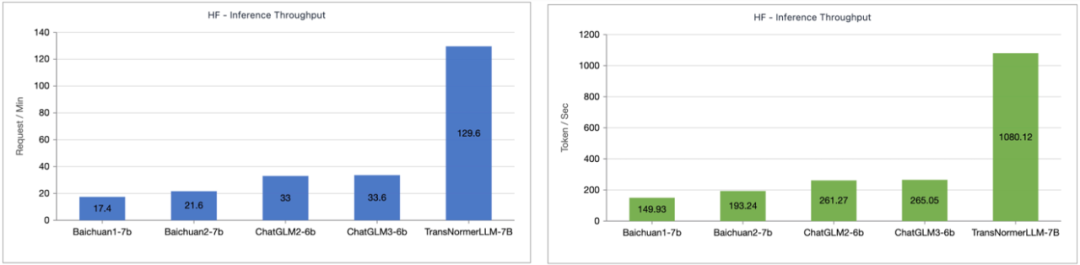
笔者测试了 Lightning Attention-1 加持的 TransNormerLLM-7B 与常见的 7B 模型在推理速度上的对比。如下图所示,在近似参数大小下,Lightning Attention-1 的吞吐速度是百川的 4 倍,ChatGLM 的 3.5 倍以上,显示出了优异的推理速度优势。
小结
Lightning Attention-2 代表了线性注意力机制的重大进步,使其无论在精度还是速度上均可以完美的替换传统的 Softmax 注意力,为今后越来越大的模型提供了可持续扩展的能力,并提供了一条以更高效率处理无限长序列的途径。OpenNLPLab 团队在未来将研究基于线性注意力机制的序列并行算法,以解决当前遇到的显存屏障问题。
上一篇:利用人工智能实现图像超分辨率重构
下一篇:PHP错误排查与性能优化指南
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
-
 正版软件
正版软件
- Linux发行版对于AMD Ryzen Zen 2处理器提供了持续的支持,并对L3缓存进行了优化以提升性能
- 6月3日消息,根据国外科技媒体NeoWin的报道,Linux发行版并不计划效仿Windows11,相反,他们将继续为基于AMDRyzenZen2处理器的用户提供支持,并通过对L3缓存(LLC)的优化来进一步提升性能。近日发布的select_idle_sibling()补丁为Linux内核带来了一些改进。该补丁允许操作系统将任务分配给被标记为“闲置”状态的处理器线程,不仅限于识别本地L3缓存中的闲置线程。这一变化在AMDZen2设备上特别重要,因为在处理特定LLC的工作队列时,通常会出现核心闲置的情况。据小
- 17分钟前 Linux 0
-
 正版软件
正版软件
- 微软开启macOS和iOS平台测试,全新的自动裁剪功能即将推出!
- 7月1日消息,微软今天发布博文,邀请Microsoft365Insider项目成员参与测试新功能和特性。据悉,此次测试将针对macOS、iOS和安卓平台应用进行,涵盖了自动裁剪和合并PDF文件两个重要功能。据小编了解,微软在此次测试中特别邀请了macOS和iOS平台的Microsoft365Insider项目成员,让他们在Word、PowerPoint和Excel应用程序中体验自动裁剪功能。这项新功能能够自动识别图片中最重要的部分并裁剪其余部分,取代了以往繁琐的手动裁剪操作。用户只需简单点击,即可快速完成
- 32分钟前 微软 0
-
 正版软件
正版软件
- 佳明Lily 2智能手表支持页面意外曝光,日本市场即将上市细节揭秘
- 佳明(Garmin)宣布即将推出新一代智能手表Lily2,引起了广泛关注。据悉,这款新品有望在近期正式上市。近日,佳明日本的支持页面意外曝光了Lily2Sport的清晰照片。从照片中可以看出,Lily2继续沿用了初代的设计风格,采用光面表圈与磨砂表身的搭配,展现出独特的美感。同时,这款手表也是专为女性用户打造的,相信会受到不少消费者的喜爱。根据我们的了解,除了Lily2Sport之外,泄露的图片还展示了四款Lily2Classic的不同款式。这些款式还提供了皮革和尼龙材质的表带选择,以满足消费者的不同需求
- 47分钟前 佳明 0
-
 正版软件
正版软件
- 苹果macOS用户即将享受全新功能:畅玩Windows游戏
- 6月7日消息,苹果在今天举办的WWDC2023开发者大会上揭示了一项令人振奋的计划,他们将在macOS系统中推出一种新的功能,允许用户模拟运行Windows10和Windows11系统的游戏。这一消息对于广大游戏玩家来说无疑是个令人兴奋的消息。据小编了解,在此次活动中,苹果详细介绍了如何通过引入metalShaderConverter和metal调试工具来提升游戏性能,并显著减少前期准备所需的时间。这意味着用户可以更轻松地在macOS平台上畅玩Windows游戏,无需单独购买Windows设备。值得一提的
- 1小时前 04:55 苹果 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1801天前
-
 2
2
- Overture设置踏板标记的方法
- 1638天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1628天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1826天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1792天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1788天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1803天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1824天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00