熵量化了事件的不确定性大小。在数据科学中,交叉熵和KL散度与离散概率分布相关,用于衡量两个分布的相似程度。在机器学习中,通过交叉熵损失来评估预测分布与真实分布的接近程度。
给定真实分布t和预测分布p,它们之间的交叉熵由以下等式给出:
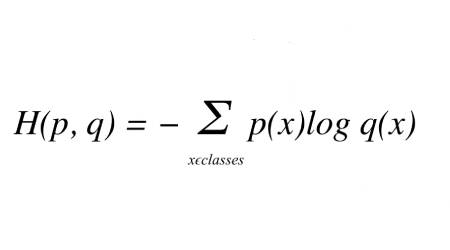
其中p(x)是真实概率分布(one-hot),q(x)是预测概率分布。
然而,在现实世界中,预测值与实际值的差异称为发散,因为它们背离了实际值。交叉熵是熵和KL散度的综合度量。
现在让我们使用分类示例了解交叉熵如何适合深度神经网络范例。
每个分类案例都有一个已知的类别标签,概率为1.0,其余标签概率为0。模型根据案例确定每个类别名称的概率。交叉熵可用于比较不同标签的神经通路。
将每个预测的类别概率与所需输出0或1进行比较。计算出的分数/损失根据与预期值的距离来惩罚概率。惩罚是对数的,对于接近于1的显著差异产生较大的分数,而对于接近于0的微小差异产生较小的分数。
在训练期间调整模型权重时使用交叉熵损失,其目的是最小化损失——损失越小,模型越好。



