深入解析机器学习评估的F1分数
 发布于2024-11-15 阅读(0)
发布于2024-11-15 阅读(0)
扫一扫,手机访问
准确性指标是衡量模型在整个数据集中正确预测的次数。然而,只有在数据集是类平衡的情况下,这个指标才是可靠的。也就是说,数据集中每个类别都有相同数量的样本。但是,现实世界的数据集往往严重失衡,这就导致准确性指标不再可行。 为了解决这个问题,人们引入了F1分数作为一种更全面完善的机器学习评估指标。F1分数综合了模型的精确率和召回率,可以更好地评估模型的准确性。精确率是指模型预测为正例的样本中有多少是真正的正例,而召回率是指模型能够正确预测出多少真正的正例。 F1分数的计算公式为:2 * (精确率 * 召回率) / (精确率 + 召回率)。通过综合考虑精确率和召回率,F1分数能够更准确地评估模型的表现,尤其在
F1分数概念
F1分数与混淆矩阵密切相关,用于评估分类器的准确度、精确度和召回率等指标。通过结合精确度和召回率,F1分数能够提供对模型综合性能的评估。
精度衡量模型做出的“积极”预测中有多少是正确的。
召回率测量数据集中存在的正类样本中有多少被模型正确识别。
准确率和召回率提供了一种权衡的关系,即提高一个指标会以另一个为代价。更高的准确率意味着更严格的分类器,会怀疑数据集中的实际正样本,从而降低召回率。另一方面,更高的召回率需要一个松懈的分类器,它允许任何类似于正类的样本通过,这会将一些边界情况的负样本误分类为“正类”,从而降低准确率。理想情况下,我们希望最大化准确率和召回率指标,以获得一个完美的分类器。
F1分数使用它们的调和平均值结合精确度和召回率,最大化F1分数意味着同时最大化精确度和召回率。
如何计算F1分数?
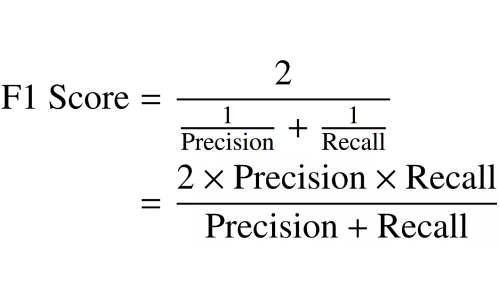
要理解F1分数的计算,首先需要认识混淆矩阵。上文我们提到F1分数是根据精确度和召回率定义的。其公式如下:
精度

F1分数计算为精度和召回分数的调和平均值,如下所示。它的范围为0-100%,较高的F1分数表示更好的分类器质量。
为了计算多类数据集的F1分数,使用了一对一技术来计算数据集中每个类的个体分数。取类精度和召回值的调和平均值。然后使用不同的平均技术计算净F1分数。
宏观平均F1分数

微平均F1分数是一种对多类数据分布有意义的指标。它使用“净”TP、FP和FN值来计算指标。
净TP是指数据集的类TP分数的总和,它是通过将混淆矩阵分解为对应于每个类的one-vs-all矩阵来计算的。
样本加权F1分数

Fβ分数是F1分数的通用版本。它计算调和平均值,就像F1分数一样,但优先考虑精度或召回率。“β”表示权重系数,该系数是用户设置的超参数,始终大于0。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 小米合作迪士尼推出限量版智能手机及其他产品,充满优惠
- 6月8日消息,小米即将在今晚举行一场备受关注的发布活动,据小编了解,该活动将推出一系列与迪士尼合作的限定版智能产品,引起了广大用户的期待。据悉,小米将发布迪士尼100周年限定版的智能手机、智能手环、真无线蓝牙耳机、词典笔和旅行箱等产品。这些限定版产品的主要元素是米奇,将为用户带来独特的迪士尼体验。除了手机和手环等智能产品,小米还将与迪士尼合作发布其他高人气智能生态产品,例如充电宝等。这些产品的发布将进一步丰富小米生态系统,并满足用户对迪士尼主题产品的需求。此次发布活动还将包括一系列福利内容,为参与活动的用
- 11分钟前 0
-
 正版软件
正版软件
- 深入解读机器学习中的线性回归
- 在机器学习中,线性回归是一种常见的监督学习算法,用于通过建立一个或多个自变量与连续的因变量之间的线性关系来预测。与传统的统计学中的线性回归类似,机器学习中的线性回归也是通过最小化损失函数来确定最佳拟合线。通过这个算法,我们可以利用已知的数据集来建立一个线性模型,然后利用这个模型来预测新的数据。这种算法在预测房价、销量等连续变量问题中得到广泛应用。线性回归在机器学习中有两种实现方式:批量梯度下降和正规方程。批量梯度下降是一种迭代方法,通过调整模型参数来最小化损失函数。正规方程是一种解析方法,通过求解线性方程
- 21分钟前 机器学习 线性回归 0
-
 正版软件
正版软件
- 相似矩阵的定义与用途
- 在机器学习中,相似矩阵是一种数学工具,用于衡量数据之间的相似性。它通常由一个nxn的矩阵表示,其中n是数据集中的样本数。相似矩阵的元素可以表示两个数据之间的相似度或距离。通过分析相似矩阵,我们可以识别出数据之间的模式和关联,进而进行分类、聚类等任务。相似矩阵在机器学习算法中具有广泛的应用,例如推荐系统、图像识别等领域。相似矩阵可以通过多种方法计算得到,如欧几里得距离、余弦相似度和相关系数等。其中,欧几里得距离是常用的计算相似矩阵的方法之一,用于计算两个向量间的距离。余弦相似度则衡量两个向量夹角的余弦值,表
- 36分钟前 机器学习 0
-
 正版软件
正版软件
- 加强神经进化中的拓扑结构
- 增强拓扑的神经进化是一种优化神经网络结构的算法。它的目标是通过增加网络的拓扑结构来提高性能。这种算法结合了遗传算法和进化策略等进化算法,能够自动地生成神经网络的拓扑结构并优化权重。除了优化网络的权重,增强拓扑的神经进化还会增加新的节点和连接,以增强网络的拓扑结构和功能。这种方法在图像识别、语音识别、自然语言处理和机器人控制等领域得到了广泛应用。通过增加网络的拓扑结构,神经进化可以有效地提升神经网络的性能,使其在复杂任务中更加灵活和高效。增强拓扑的神经进化方法包括以下步骤:1.初始化种群:随机生成一组初始的
- 51分钟前 人工神经网络 0
-
 正版软件
正版软件
- 使用Rust编写一个简单的神经网络
- Rust是一种系统级编程语言,专注于安全、性能和并发性。它旨在提供一种安全可靠的编程语言,适用于操作系统、网络应用和嵌入式系统等场景。Rust的安全性主要源于两个方面:所有权系统和借用检查器。所有权系统使得编译器能够在编译时检查代码中的内存错误,从而避免常见的内存安全问题。通过在编译时强制检查变量的所有权转移,Rust确保了内存资源的正确管理和释放。借用检查器则通过对变量的生命周期进行分析,确保同一个变量不会被多个线程同时访问,从而避免了常见的并发安全问题。通过这两个机制的结合,Rust能够提供高度安全的
- 1小时前 14:50 人工神经网络 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1801天前
-
 2
2
- Overture设置踏板标记的方法
- 1638天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1628天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1826天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1792天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1788天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1803天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1824天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00