快速掌握篮球技巧的「灌篮高手」模拟人形机器人,无需任务奖励,完全复制人类招式
 发布于2024-11-17 阅读(0)
发布于2024-11-17 阅读(0)
扫一扫,手机访问
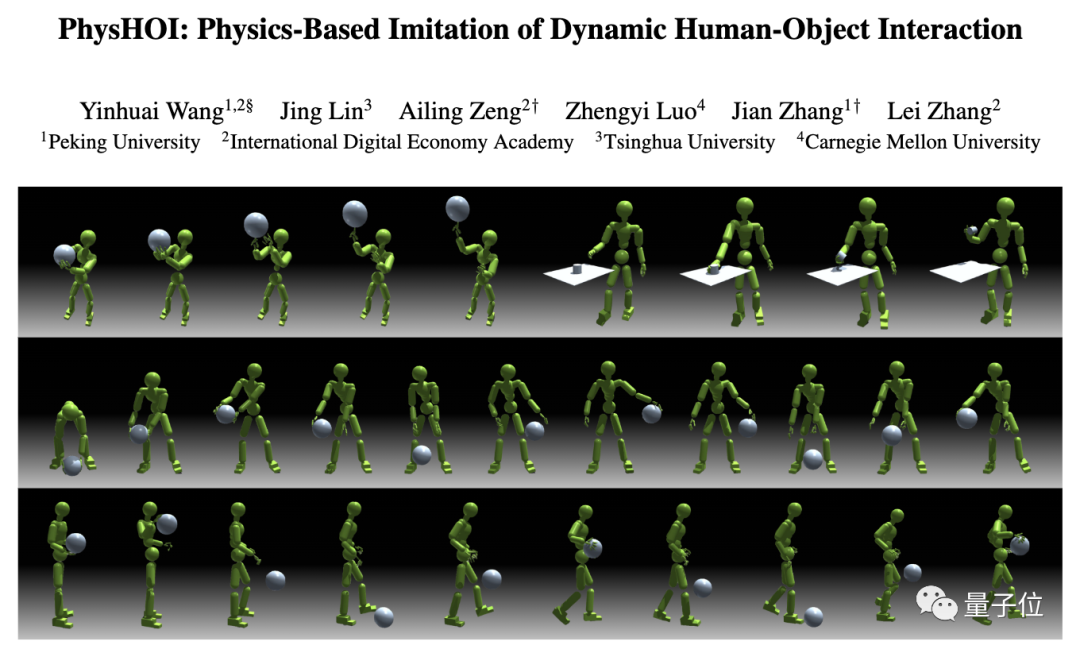
投篮、运球、手指转球…这个物理模拟人形机器人会打球:
 图片
图片
会的招数还不少:
 图片
图片
一通秀技下来,原来都是跟人学的,每个动作细节都精确复制:
 图片
图片
这就是最近一项名为PhysHOI的新研究,能够让物理模拟的人形机器人通过观看人与物体交互(HOI)的演示,学习并模仿这些动作和技巧。
重点是,PhysHOI无需为每个特定任务设定具体的奖励机制,机器人可以自主学习和适应。
而且机器人的身上总共有51x3个独立控制点,所以模仿起来能做到高度逼真。
 图片
图片
一起来看具体是如何实现的。
模拟人形机器人变身「灌篮高手」
这项工作由来自北京大学、IDEA研究院、清华大学、卡内基梅隆大学的研究人员共同提出。
 图片
图片
经研究人员介绍,此前大多数类似工作,存在模仿动作孤立、需特定任务的奖励、未涉及灵巧的全身运动等局限。
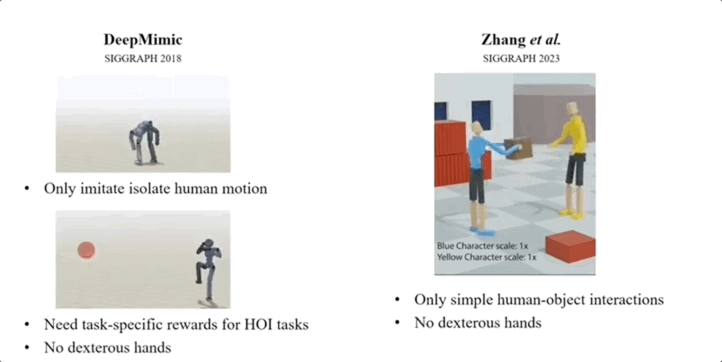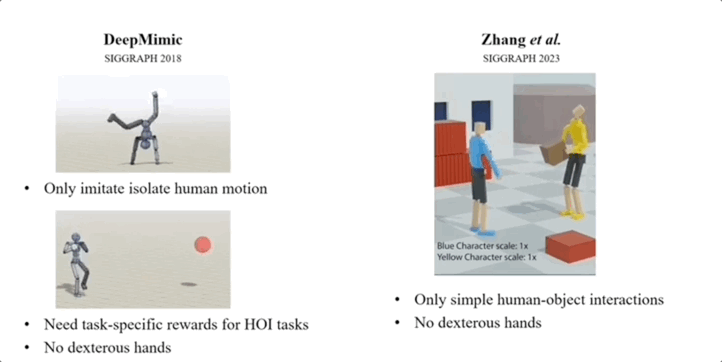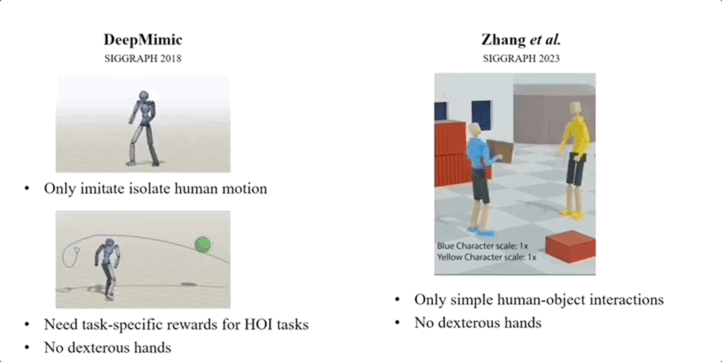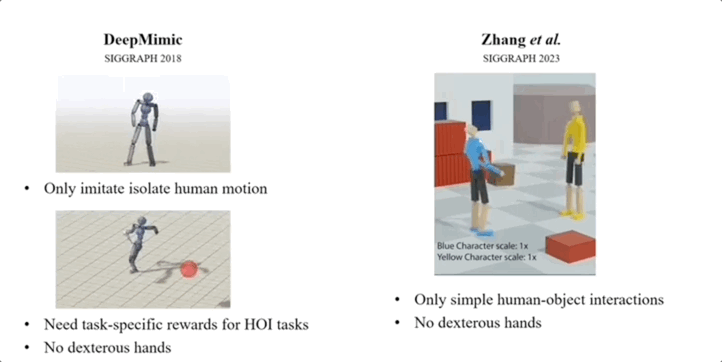 图片
图片
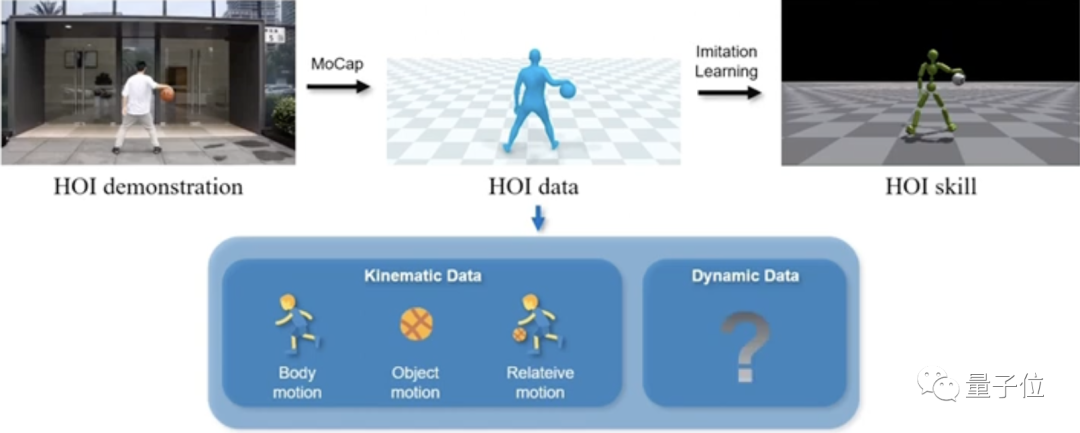
而他们提出的PhysHOI,应用动作捕捉技术提取HOI数据,然后使用模仿学习来学习人体运动和物体控制,解决了这些问题。
其中,HOI数据重要组成部分之一是涵盖了人体运动、物体运动、相对运动的运动学数据(Kinematic Data),记录了位置、速度、角度等信息。
另外,动态数据(Dynamic Data)反映了运动过程中的实时变动和更新,也很重要。
 图片
图片
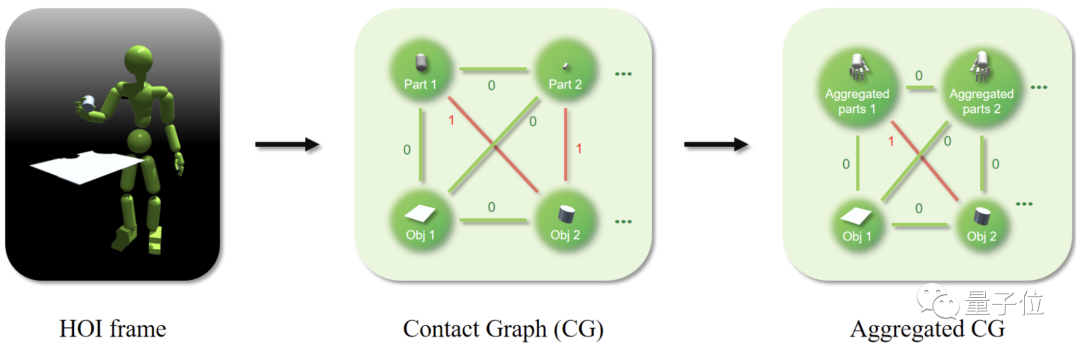
为了弥补HOI数据中动态信息的不足,研究人员引入了接触图(contact graph,CG)。
 图片
图片
CG的节点由机器人的肢体部件和物体组成;每条边则是一个二进制接触标签,只表达“接触”或“不接触”两种状态。
此外,还可以将多个肢体部件放到一个节点中,形成一个聚合CG(Aggregated CG)。
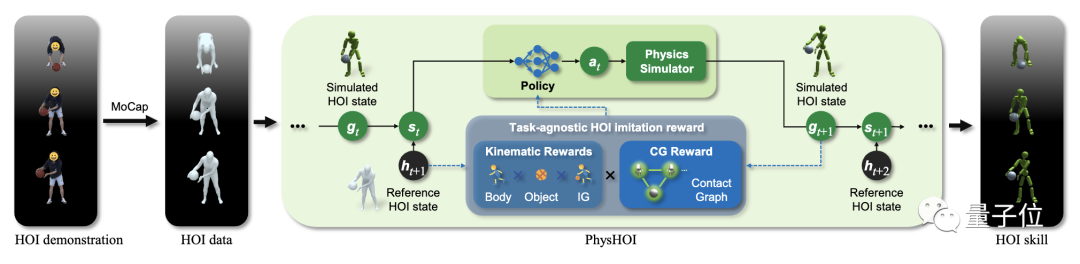
具体来说,PhysHOI方法是:
首先通过运动捕捉获取参考HOI状态序列,包含人体运动、物体运动、交互图和接触图。
 图片
图片
然后用第一帧的信息初始化物理模拟环境,构建包含当前模拟状态和下一个参考状态的系统状态。
接下来输入策略网络生成的动作控制人形机器人,物理模拟器根据动作更新场景中人体和物体的状态,计算包含运动匹配、接触图等多个方面的奖励。
利用奖励、状态和动作样本优化策略网络,采用更新后的策略网络开始新一轮的模拟过程,如此循环直至网络收敛,最终获得能够重现参考HOI技能的控制策略。
值得一提的是,研究人员在这当中设计了一个与任务无关的HOI模仿奖励,无需针对不同任务自定义奖励函数,包括体现运动匹配度的身体和物体奖励、反映接触正确性的接触图奖励,避免了使用错误身体部位接触物体等局部最优解。
接触图奖励是关键
研究人员在两个HOI数据集上测试了PhysHOI。
其中引入了BallPlay数据集,包含多种全身篮球技能。
 图片
图片
他们在GRAB数据集的S8子集中选择了5个抓取案例,以及BallPlay数据集的8个篮球技能。
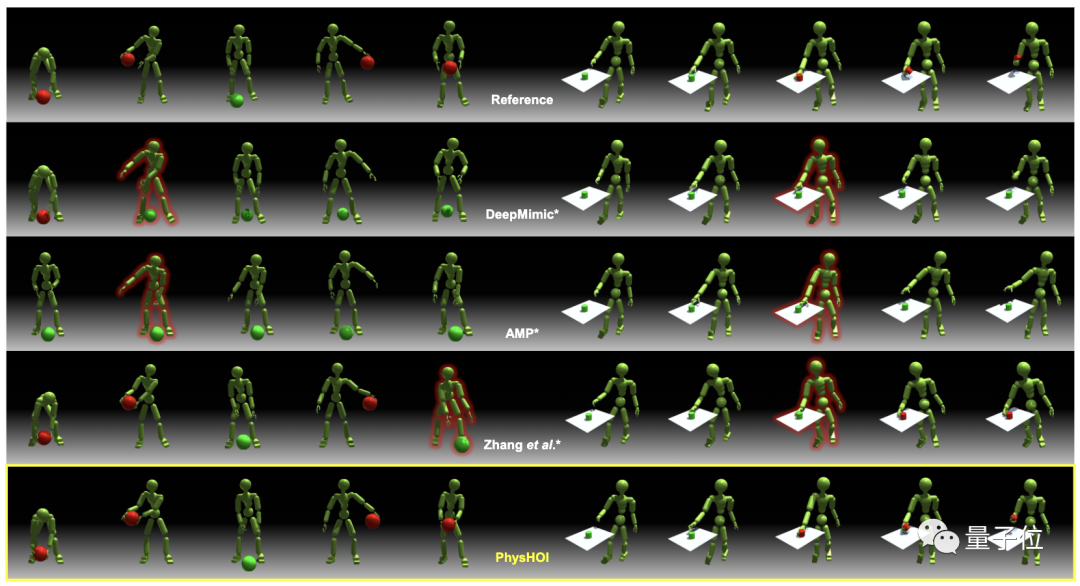
以此前的DeepMimic、AMP等方法作为基线,为公平比较,研究人员将其做了修改,以适应HOI模仿任务。
 图片
图片
结果显示,以往只使用运动学奖励的方法无法准确复现交互,球会掉落或抓握失败。
而在接触图的指导下,PhysHOI成功进行了HOI模仿。
PhysHOI在两个数据集上都获得最高的成功率,分别为95.4%和82.4%,同时也取得最低的运动误差,显著优于其它方法。
 图片
图片
消融研究表明,接触图奖励能有效避免只使用运动信息的方法陷入局部最优,指导机器人实现正确接触。
 图片
图片
如果没有接触图奖励,人形机器人可能无法控制球,或者错误地使用身体其它部位控制球:
 图片
图片
论文链接:https://arxiv.org/abs/2312.04393
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 机器学习中的向量范数:曼哈顿范数、欧几里得范数、切比雪夫范数
- 向量范数是衡量向量大小的指标,广泛应用于评估模型误差。在机器学习和深度学习中具有重要作用。机器学习的项目可以视为一个n维向量,其中每个维度表示数据的属性。因此,我们可以使用标准的基于向量的相似性度量来计算它们之间的距离,如曼哈顿距离、欧几里得距离等。简而言之,范数是一种函数,它可以帮助我们量化向量的大小。向量范数的性质向量范数满足以下4种性质:非负性:始终是非负的。确定性:零向量时,它才为零三角不等式:两个向量之和的范数不超过它们的范数之和。同质性:将向量乘以标量将向量的范数乘以标量的绝对值。机器学习中常
- 13分钟前 机器学习 0
-
 正版软件
正版软件
- OPPO Enco R2耳机与Reno系列合作,打造卓越的音质体验
- 6月1日消息,除了OPPOReno10系列,今天正式开售的还有OPPOEncoR2耳机。这款耳机以其独特的轻奢外观设计和出色的音质表现成为影音娱乐的好伴侣。据小编了解,OPPOEncoR2是OPPO为其Reno10系列量身打造的最佳配件,能够实现与Reno10系列的互联,提升整体音质体验。这款耳机由OPPO老牌蓝光团队把控,内置了13.4mm大尺寸动圈,能够呈现更加澎湃有力的声音。同时,采用了HiFi级钕磁铁和进口铜铝线圈的组合,使得高频更加通透细腻,无论是流行歌曲还是古典乐都能轻松驾驭。OPPOEnco
- 28分钟前 0
-
 正版软件
正版软件
- iPad专利:具备磁性电圈的屏幕下方,可为Apple Pencil提供充电
- 6月7日消息,苹果公司近日获得一项新的iPad技术专利。这项专利揭示了一种创新的充电方式,通过iPad屏幕下方的磁性电圈为ApplePencil手写笔提供充电功能。根据专利描述,用户不再需要单独为ApplePencil进行充电操作。ApplePencil上引入了感应接收线圈,只需将其放在iPad表面,即可实现自动充电。这项技术实现了ApplePencil与iPad之间的双向通信,通过感应充电电路进行交互,大大减少了功耗。据小编了解,在使用ApplePencil的过程中,iPad还能主动为其提供充电。这一功
- 43分钟前 苹果 0
-
 正版软件
正版软件
- 联想发布卓越的人机交互体验,推出天禧AI生态的“四端一体”战略
- 【CNMO新闻】12月26日,2023联想天禧AI生态伙伴大会在北京正式召开,联想与英特尔、百度、网易有道等头部企业、400余家行业开发者和媒体齐聚一堂,以“AI生态共赢未来”为主题,共同探讨未来AI生态发展及应用。联想集团副总裁、中国区消费业务群总经理张华重磅发布联想天禧AI生态“四端一体”战略,个人智能体“小乐同学”首次亮相,并面向广大生态开发者伙伴,正式启动智能体小程序招募计划,携手共赢未来。“四端一体”战略正式发布,打造内嵌AI的全终端布局随着联想小新Pro16笔记本搭载英特尔MeteorLake
- 58分钟前 0
-
 正版软件
正版软件
- 不同发展阶段的人脸识别技术与常见数据集
- 人脸识别早期阶段——基于机器学习早期的方法主要侧重于与计算机视觉专家合作,提取手工特征,并使用传统的机器学习算法训练有效的分类器进行检测。然而,这些方法的局限性在于需要专家制作有效的特征,并且每个组件都需要单独优化,导致整个检测管道不够优化。为了解决这个问题,人们提出了更复杂的特征,如HOG、SIFT、SURF和ACF。为了增强检测的鲁棒性,还开发了针对不同视图或姿势训练的多个检测器的组合。然而,这些模型的训练和测试时间较长,对检测性能的提升有限。人脸识别更加先进的技术——基于深度学习近年来,面部识别方面
- 1小时前 03:40 人工智能 机器学习 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1803天前
-
 2
2
- Overture设置踏板标记的方法
- 1640天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1629天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1828天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1794天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1790天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1805天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1826天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00