Llama2通过元学习实现自我奖励,性能超越GPT-4的大型模型
 发布于2024-11-21 阅读(0)
发布于2024-11-21 阅读(0)
扫一扫,手机访问
人工智能的反馈(AIF)要代替 RLHF 了?

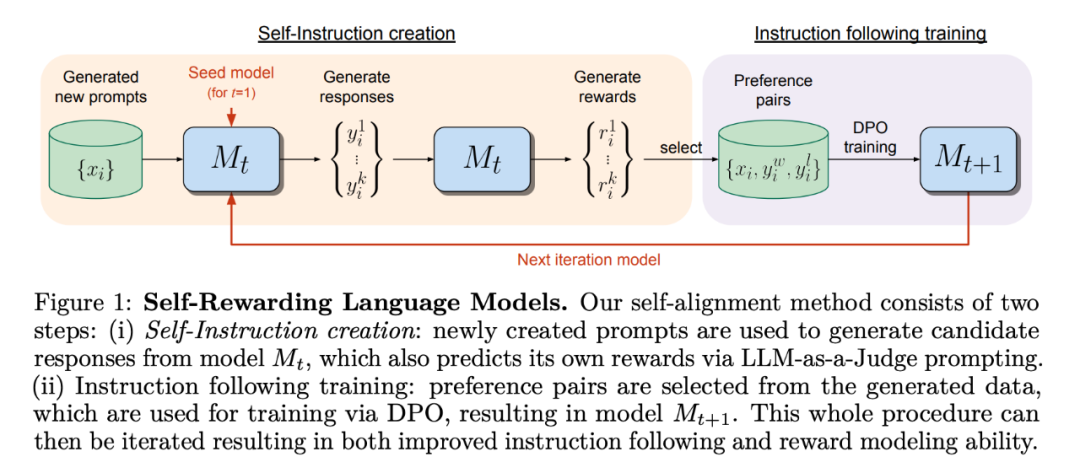
论文标题:Self-Rewarding Language Models
论文链接:https://arxiv.org/abs/2401.10020

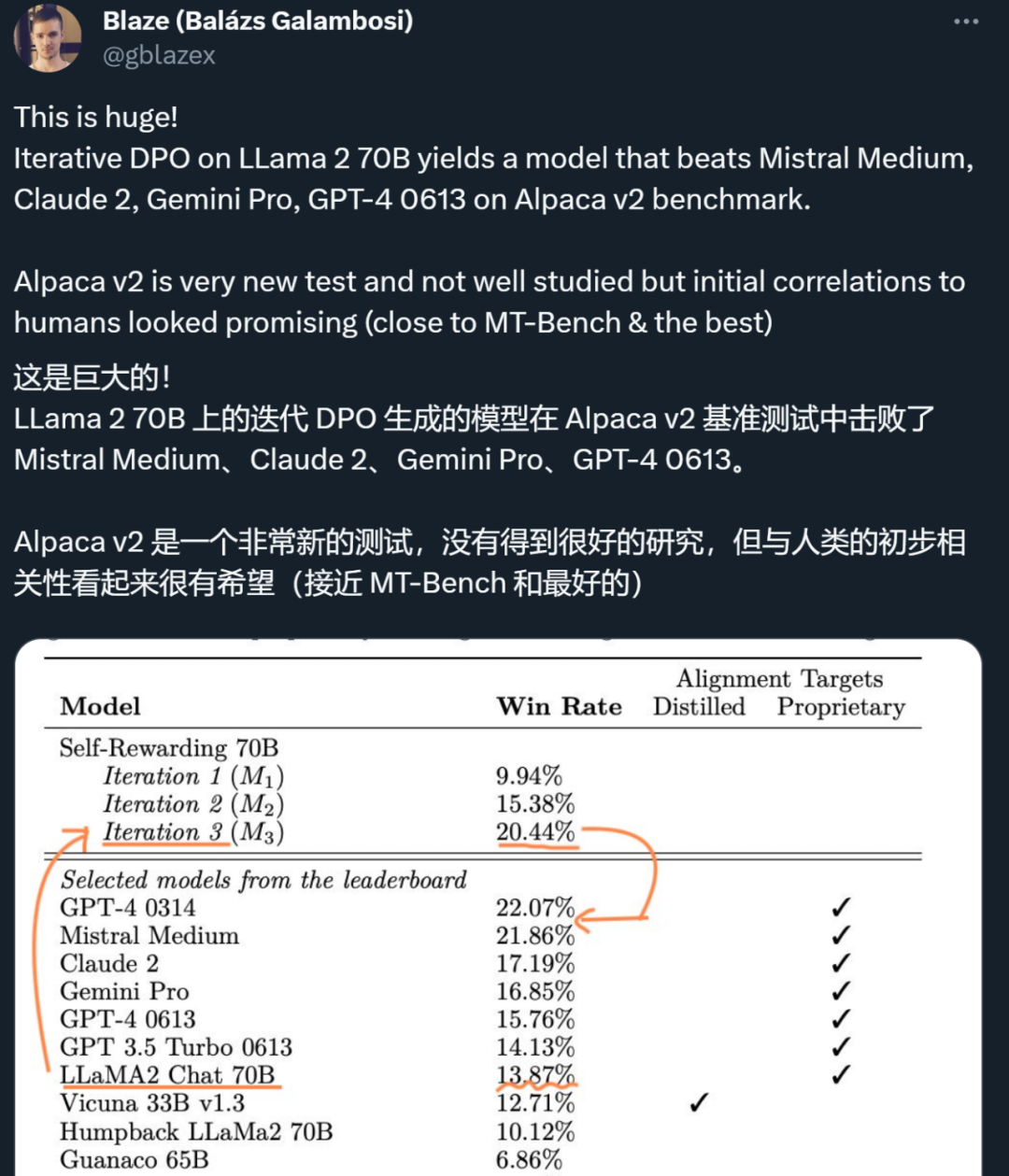
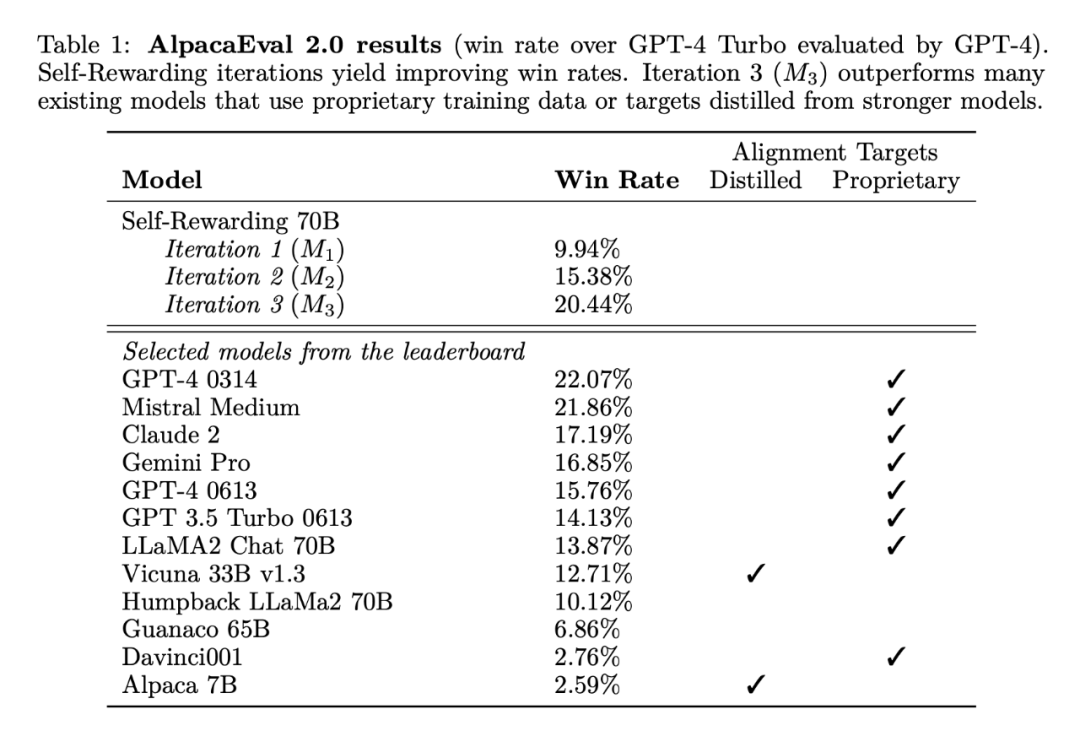
 研究者在 AlpacaEval 2 排行榜上评估了自奖励模型,结果如表 1 所示。他们观察到了与 head-to-head 评估相同的结论,即训练迭代的胜率比 GPT4-Turbo 高,从迭代 1 的 9.94%,到迭代 2 的 15.38%,再到迭代 3 的 20.44%。同时,迭代 3 模型优于许多现有模型,包括 Claude 2、Gemini Pro 和 GPT4 0613。
研究者在 AlpacaEval 2 排行榜上评估了自奖励模型,结果如表 1 所示。他们观察到了与 head-to-head 评估相同的结论,即训练迭代的胜率比 GPT4-Turbo 高,从迭代 1 的 9.94%,到迭代 2 的 15.38%,再到迭代 3 的 20.44%。同时,迭代 3 模型优于许多现有模型,包括 Claude 2、Gemini Pro 和 GPT4 0613。
EFT在SFT基线上有所改进,使用IFT+EFT与单独使用IFT相比,五个测量指标都有所提高。例如,与人类的成对准确率一致性从65.1%上升到78.7%。
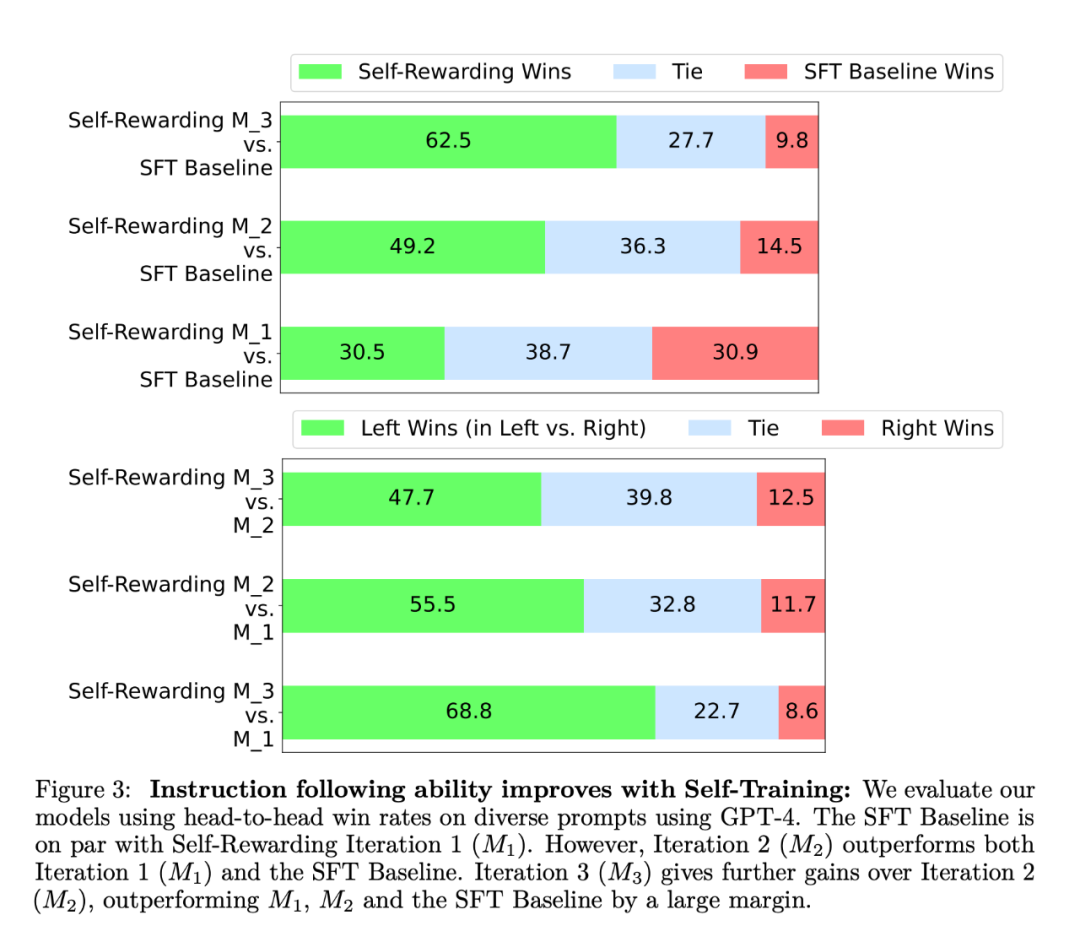
通过自我训练提高奖励建模能力。进行一轮自我奖励训练后,模型为下一次迭代提供自我奖励的能力得到了提高,此外它的指令跟随能力也得到了提高。
LLMas-a-Judge 提示的重要性。研究者使用了各种提示格式发现,LLMas-a-Judge 提示在使用 SFT 基线时成对准确率更高。
本文转载于:https://www.jiqizhixin.com/articles/2024-01-22-4 如有侵犯,请联系admin@zhengruan.com删除
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 福特Mustang Dark Horse即将在国内上市——力量与美感的完美融合的倒计时
- 福特中国今日揭开了备受期待的全新MustangDarkHorse车型的面纱,宣布该款美式肌肉车将于2月19日正式上市,并计划在今年第二季度开始交付给消费者。这款车型备受期待,翘首以盼的消费者将很快能够亲眼目睹并驾驭它。福特中国为车迷们带来了一款更加神秘、更加具有冲击力的Mustang车型,相信它将成为市场瞩目的焦点。新款MustangDarkHorse保留了Mustang系列一贯的坚韧风格,车身线条刚毅且充满力量感。前脸部分,该车采用了熏黑处理的格栅,搭配大尺寸散热开口的发动机舱盖,展现出强烈的运动气息。
- 11分钟前 福特 0
-
 正版软件
正版软件
- 2024年ICLR国际顶级会议揭晓,蚂蚁集团获选11篇论文
- 最近,ICLR2024,人工智能顶级会议,公布了录取结果。蚂蚁集团在这次会议中有11篇论文被接收,其中1篇被评为口头报告,3篇被选为焦点报告,另外7篇则为海报展示。蚂蚁集团在人工智能学术界的进展备受瞩目。(图:蚂蚁集团的《长视频中的多粒度噪声关联学习》被收录为Oral论文)今年ICLR组委会收到了7262篇论文投稿,录用率约为31%。根据录用结果,其中1.2%的论文被录用为Oral论文,这些作者将获得10分钟的口头演讲机会。另外5%的论文被录用为Spotlight论文,这些作者将有4分钟的聚光灯展示时间。
- 26分钟前 入门 ICLR 噪声关联 多模态技术 关联学习 0
-
 正版软件
正版软件
- 中国团队发现室温超导续集?最新论文证实LK-99可能出现迈斯纳效应,刚刚发布
- 一篇新的室温超导论文再次引起互联网上的轻微波动。最新论文中再次证明了室温下铜可能替代铅磷灰石(LK-99)中的迈斯纳效应存在。论文链接:https://arxiv.org/pdf/2401.00999.pdf,供大家参考。在室温下,用铜取代的铅磷灰石在25Oe的磁场下观察到抗磁性直流磁化,在零场冷却和场冷却测量之间存在明显的分歧,在200Oe下变为顺磁性。在冷却过程中发现了玻璃记忆效应。超导体的典型磁滞回线在250K以下被检测到,同时磁场的前后扫描不对称。我们的实验表明,在室温下,这种材料可能存在迈斯纳效
- 36分钟前 模型 AI 0
-
 正版软件
正版软件
- 中国公司统治苹果供应链:Vision Pro席卷市场
- 6月16日消息,苹果在今天的WWDC23开发者大会上正式发布了其首款增强现实产品VisionPro。该产品的主要供应商超过一半来自中国,其中包括立讯精密、高伟电子、德赛电池等中国厂商。根据发布的物料清单显示,苹果VisionPro的供应商数量中超过一半来自中国,其中包括7家大陆地区厂商和11家台湾地区厂商。大陆厂商中除了立讯精密外,还有高伟电子、德赛电池、歌尔股份、长盈精密、领益制造、兆威机电。台湾地区厂商则包括台积电、大立光、业成集团、日月光、和硕、台郡、臻鼎、欣兴、景硕、南电、采钰。据小编了解,苹果V
- 50分钟前 0
-
 正版软件
正版软件
- 年轻人首选的先锋潮机,华为 nova 12 系列超强综合体验正式上市!
- 2023年12月26日,问界M9及华为冬季全场景发布会上,全新的华为nova12系列正式亮相,这一次,nova12系列发挥“时尚先锋全能人像”定位优势,选用极为瞩目的蓝色作为主打色,打造吸睛的12号色,影像部分搭载了第二代物理可变光圈镜头,搭配全新鸿蒙智慧通信和HarmonyOS4等便捷体验,让年轻人在2024年新年拥有更多购机选择。今日,华为nova12及nova12Pro已正式迎来首销,下周的1月12日,华为nova12Ultra也将正式开售。“蓝”不住的实力,“蓝”不住的潮流,如果你需要一款能够时刻
- 1小时前 20:45 Nova nova12 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1807天前
-
 2
2
- Overture设置踏板标记的方法
- 1644天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1634天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1832天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1798天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1794天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1809天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1831天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00