为何ICLR未接收Mamba论文?AI社区哗然
 发布于2024-11-22 阅读(0)
发布于2024-11-22 阅读(0)
扫一扫,手机访问
2023年,AI大模型领域的统治者Transformer的地位开始受到挑战。一种新的架构名为「Mamba」崭露头角,它是一种选择性状态空间模型,在语言建模方面与Transformer不相上下,甚至有可能超越它。与此同时,Mamba能够根据上下文长度的增加实现线性扩展,这使得它在处理实际数据时能够处理百万词汇长度的序列,并提升了5倍的推理吞吐量。这一突破性的性能提升令人瞩目,为AI领域的发展带来了新的可能性。
发布后的一个多月里,Mamba开始逐渐展现其影响力,并衍生出了MoE-Mamba、Vision Mamba、VMamba、U-Mamba、MambaByte等多个项目。在不断克服Transformer的短板方面,Mamba显示出了极大的潜力。这些发展显示出Mamba在不断发展和进步,为人工智能领域带来了新的可能性。
然而,这颗冉冉升起的"新星"在2024年的ICLR会议上遇到了挫折。最新的公开结果显示,Mamba的论文目前仍然处于待定状态,我们只能在待定决定一栏中看到它的名字,无法确定是被延迟决定还是被拒绝。
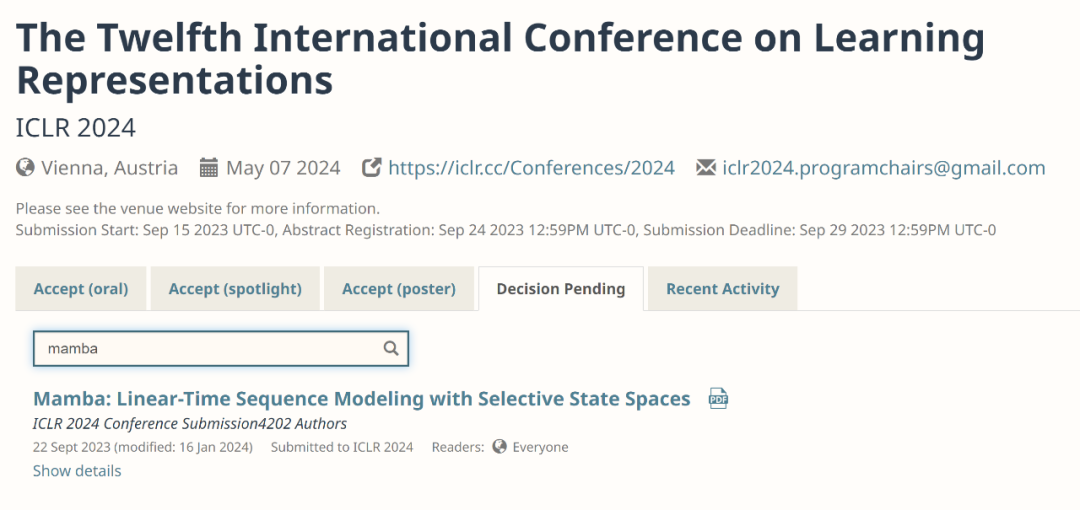
总体来看,Mamba收到了四位审稿人的评分,分别为8/8/6/3。有人表示,如果遭到这样的评分仍然被拒绝,确实令人感到不解。

要弄清其中的缘由,我们还得看一下打出低分的审稿人是怎么说的。
论文审稿页面:https://openreview.net/forum?id=AL1fq05o7H
为什么「not good enough」?
在评审反馈中,给出「3: reject, not good enough」打分的审稿人解释了自己对于 Mamba 的几点意见:
对模型设计的想法:
- Mamba 的动机是解决递归模型的缺点,同时提高基于注意力模型的效率。有很多研究都是沿着这个方向进行的:S4-diagonal [1]、SGConv [2]、MEGA [3]、SPADE [4],以及许多高效的 Transformer 模型(如 [5])。所有这些模型都达到了接近线性的复杂度,作者需要在模型性能和效率方面将 Mamba 与这些作品进行比较。关于模型性能,一些简单的实验(如 Wikitext-103 的语言建模)就足够了。
- 许多基于注意力的 Transformer 模型显示出长度泛化能力,即模型可以在较短的序列长度上进行训练,并在较长的序列长度上进行测试。这方面的例子包括相对位置编码(T5)和 Alibi [6]。由于 SSM 一般都是连续的,那么 Mamba 是否具有这种长度泛化能力呢?
对实验的想法:
- 作者需要与更强的基线进行比较。作者表示 H3 被用作模型架构的动机,然而他们并没有在实验中与 H3 进行比较。根据 [7] 中的表 4,在 Pile 数据集上,H3 的 ppl 分别为 8.8(1.25 M)、7.1(3.55 M)和 6.0(1.3B),大大优于 Mamba。作者需要展示与 H3 的比较。
- 对于预训练模型,作者只展示了零样本推理的结果。这种设置相当有限,结果不能很好地支持 Mamba 的有效性。我建议作者进行更多的长序列实验,比如文档摘要,输入序列自然会很长(例如,arXiv 数据集的平均序列长度大于 8k)。
- 作者声称其主要贡献之一是长序列建模。作者应该在 LRA(Long Range Arena)上与更多基线进行比较,这基本上是长序列理解的标准基准。
- 缺少内存基准。尽管第 4.5 节的标题是「速度和内存基准」,但只介绍了速度比较。此外,作者应提供图 8 左侧更详细的设置,如模型层、模型大小、卷积细节等。作者能否提供一些直观信息,说明为什么当序列长度非常大时,FlashAttention 的速度最慢(图 8 左)?
此外,另一位审稿人也指出 Mamba 存在的不足:该模型在训练过程中仍然像 Transformers 一样具有二次内存需求。
作者:已修改,求审阅
汇总所有审稿人的意见之后,作者团队也对论文内容进行了修改和完善,补充了新的实验结果和分析:
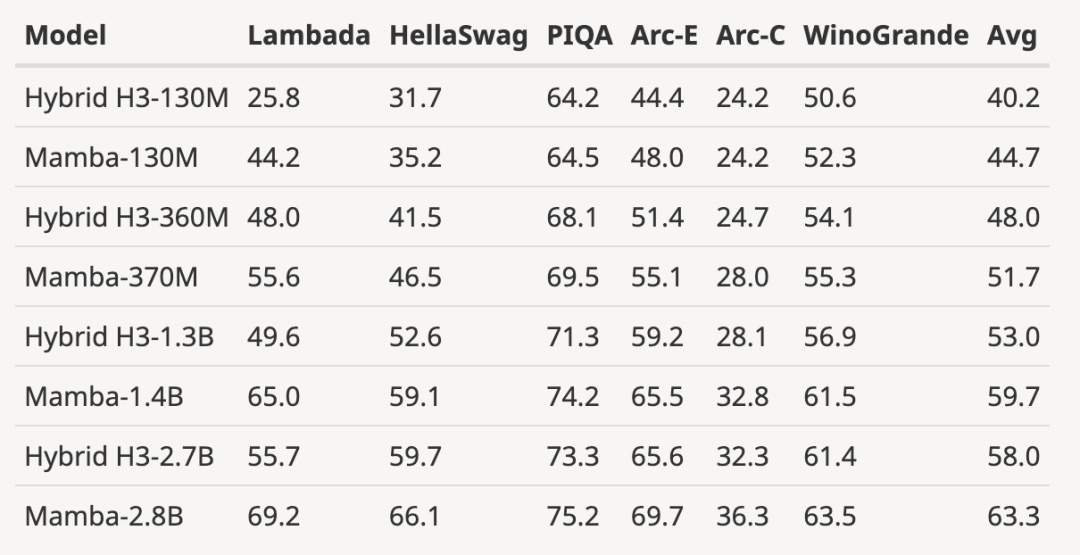
- 增加了 H3 模型的评估结果
作者下载了大小为 125M-2.7B 参数的预训练 H3 模型,并进行了一系列评估。Mamba 在所有语言评估中都明显更胜一筹,值得注意的是,这些 H3 模型是使用二次注意力的混合模型,而作者仅使用线性时间 Mamba 层的纯模型在各项指标上都明显更优。
与预训练 H3 模型的评估对比如下:
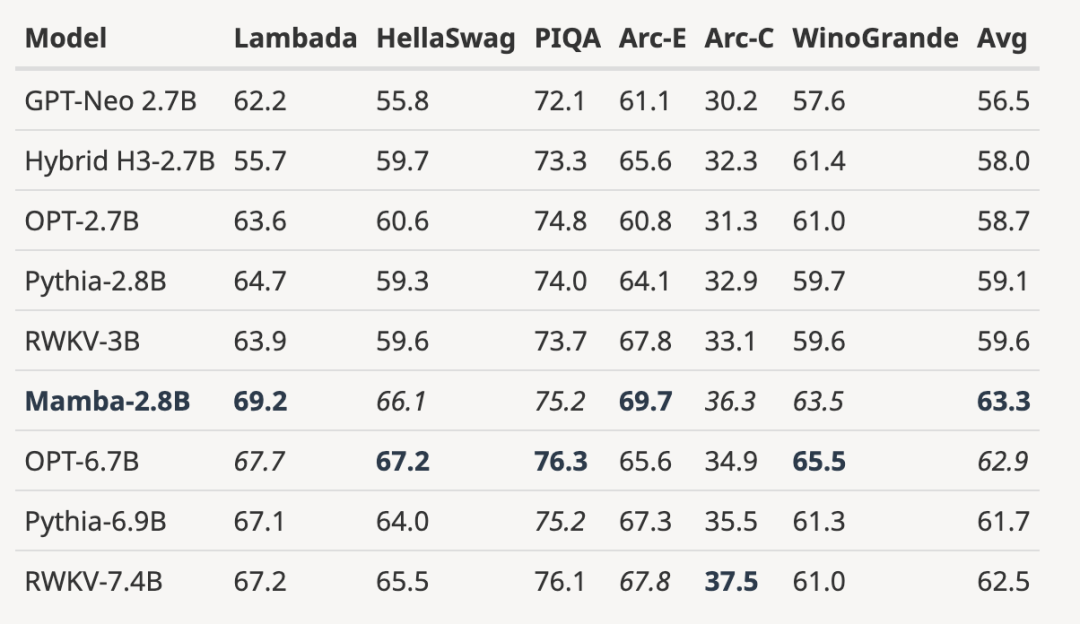
- 将完全训练过的模型扩展到更大的模型规模
如下图所示,与根据相同 token 数(300B)训练的 3B 开源模型相比,Mamba 在每个评估结果上都更胜一筹。它甚至可以与 7B 规模的模型相媲美:当将 Mamba(2.8B)与 OPT、Pythia 和 RWKV(7B)进行比较时,Mamba 在每个基准上都获得了最佳平均分和最佳 / 次佳得分。
- 展示了超出训练长度的长度外推结果
作者附上了一张评估预训练 3B 参数语言模型长度外推的附图:
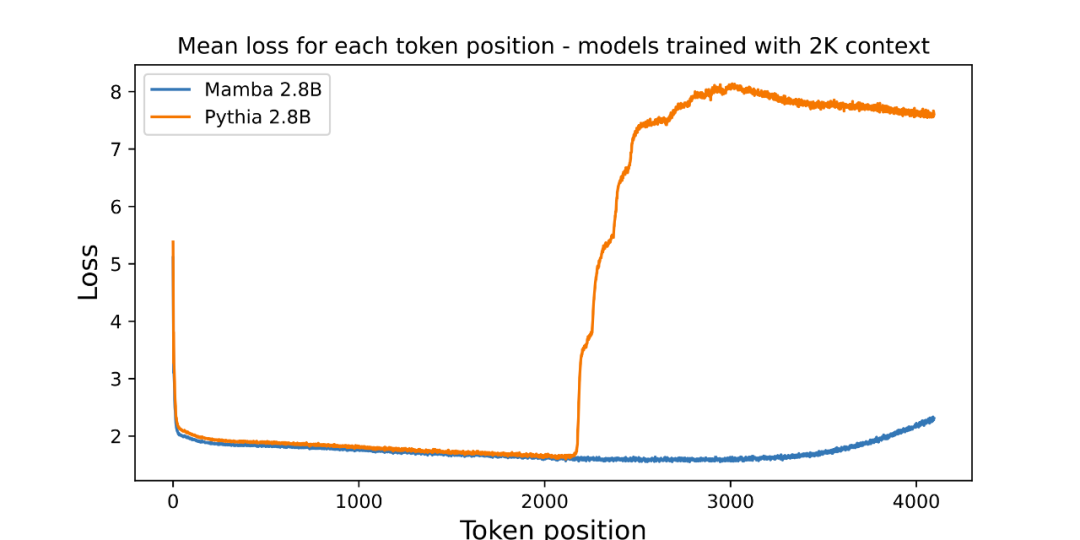
图中绘出了每个位置的平均损失(对数可读性)。第一个 token 的困惑度很高,因为它没有上下文,而 Mamba 和基线 Transformer(Pythia)的困惑度在训练上下文长度(2048)之前都有所提高。有趣的是,Mamba 的可解性在超过其训练上下文后有了显著提高,最高可达 3000 左右的长度。
作者强调,长度外推并不是本文模型的直接动机,而是将其视为额外功能:
- 这里的基线模型(Pythia)在训练时并没有考虑长度外推法,或许还有其他 Transformer 变体更具通用性(例如 T5 或 Alibi 相对位置编码)。
- 没有发现任何使用相对位置编码在 Pile 上训练的开源 3B 模型,因此无法进行这种比较。
- Mamba 和 Pythia 一样,在训练时没有考虑长度外推法,因此不具有可比性。正如 Transformer 有很多技术(如不同的位置嵌入)来提高它们在长度概括等轴上的能力一样,在未来的工作中,为类似的能力推导出 SSM 特有的技术可能会很有趣。
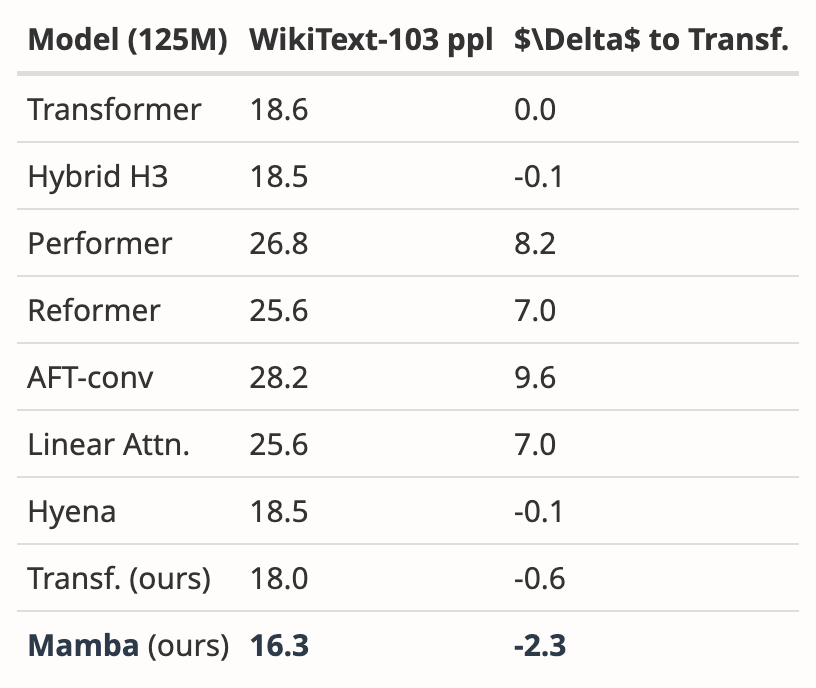
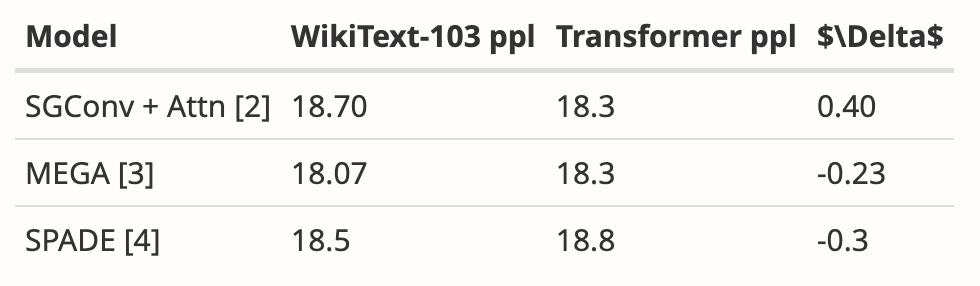
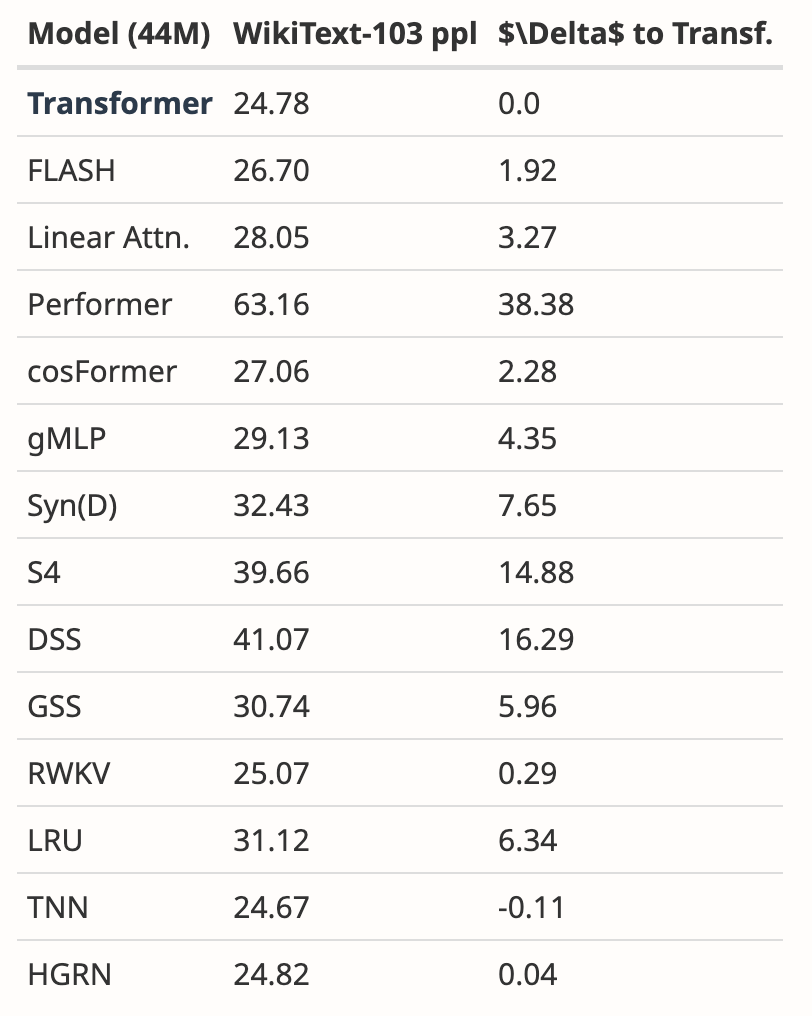
- 补充了 WikiText-103 的新结果
作者分析了多篇论文的结果,表明 Mamba 在 WikiText-103 上的表现明显优于其他 20 多个最新的次二次序列模型。
尽管如此,两个月过去了,这篇论文还处于「Decision Pending」流程中,没有得到「接收」或者「拒绝」的明确结果。
被顶会拒绝的那些论文
在各大 AI 顶会中,「投稿数量爆炸」都是一个令人头疼的问题,所以精力有限的审稿人难免有看走眼的时候。这就导致历史上出现了很多著名论文被顶会拒绝的情况,包括 YOLO、transformer XL、Dropout、支持向量机(SVM)、知识蒸馏、SIFT,还有 Google 搜索引擎的网页排名算法 PageRank(参见:《大名鼎鼎的 YOLO、PageRank 影响力爆棚的研究,曾被 CS 顶会拒稿》)。
甚至,身为深度学习三巨头之一的 Yann LeCun 也是经常被拒的论文大户。刚刚,他发推文说,自己被引 1887 次的论文「Deep Convolutional Networks on Graph-Structured Data」也被顶会拒绝了。
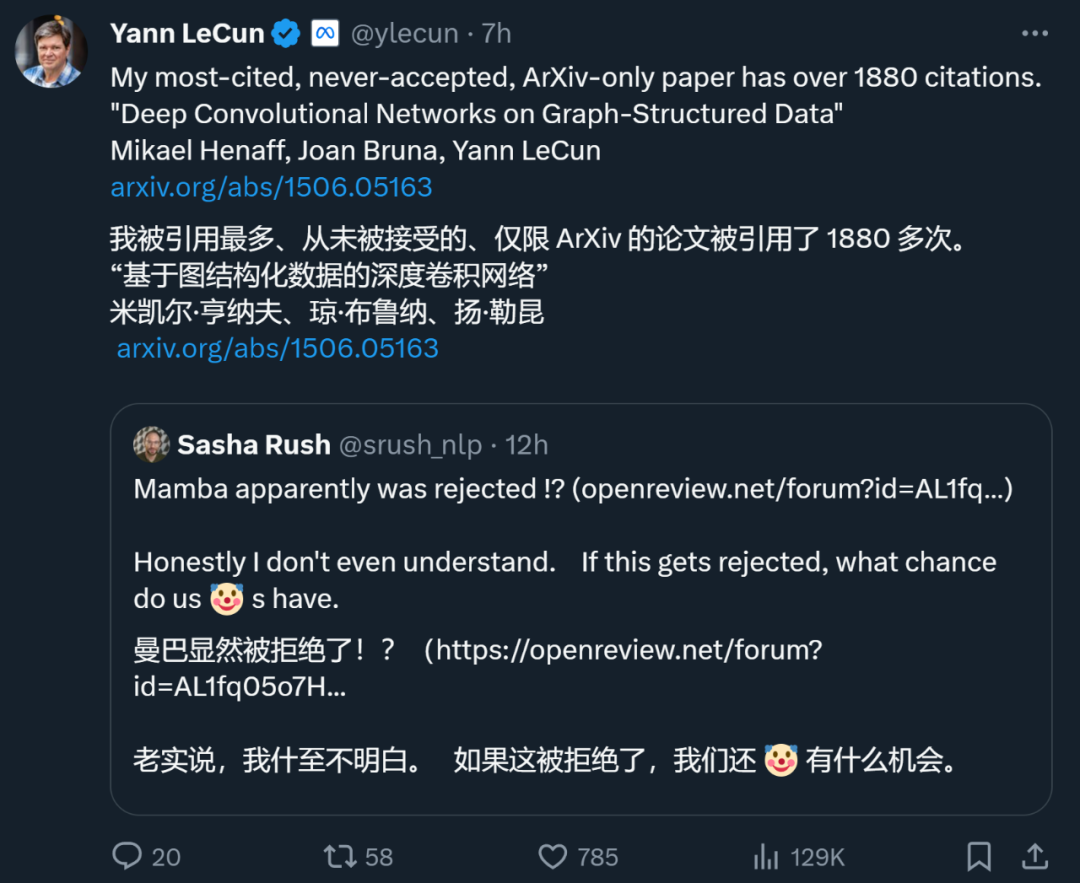
在 ICML 2022 期间,他甚至「投了三篇,被拒三篇」。

所以,论文被某个顶会拒绝并不代表没有价值。在上述被拒的论文中,很多论文选择了转投其他会议,并最终被接收。因此,网友建议 Mamba 转投陈丹琦等青年学者组建的 COLM。COLM 是一个专注于语言建模研究的学术场所,专注于理解、改进和评论语言模型技术的发展,或许对于 Mamba 这类论文来说是更好的选择。
不过,无论 Mamba 最终能否被 ICLR 接收,它都已经成为一份颇具影响力的工作,也让社区看到了冲破 Transformer 桎梏的希望,为超越传统 Transformer 模型的探索注入了新的活力。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 多维张量如何受到线性层的影响?
- 线性层是深度学习中最常用的层之一,在神经网络中起着重要作用。它被广泛应用于图像分类、物体检测、语音识别等任务。本文将重点介绍线性层在多维张量上的作用。首先,我们来回顾一下线性层的基本原理。对于一个输入张量x,线性层的计算公式如下:y=Wx+b其中,W和b分别是线性层的参数,W的形状为(n_out,n_in),b的形状为(n_out,)。n_in表示输入张量的大小,n_out表示输出张量的大小。假设输入张量是一个一维张量x∈R^n_in,输出张量也是一个一维张量y∈R^n_out。在线性层中,输入张量经过权
- 9分钟前 机器学习 0
-
 正版软件
正版软件
- 徑向基函數類神經網絡
- 径向基函数神经网络(RBFNN)是一种广泛应用于分类、回归和聚类问题的神经网络模型。它由两层神经元组成,即输入层和输出层。输入层用于接收数据的特征向量,输出层则用于预测数据的输出值。RBFNN的特殊之处在于其神经元之间的连接权重是通过径向基函数计算得到的。径向基函数是一种基于距离的函数,它可以度量输入数据与神经元之间的相似度。常用的径向基函数包括高斯函数和多项式函数。在RBFNN中,输入层将特征向量传递给隐藏层的神经元。隐藏层神经元使用径向基函数计算输入数据与其之间的相似度,并将结果传递给输出层的神经元。
- 14分钟前 人工神经网络 0
-
 正版软件
正版软件
- 蒙特卡洛模拟方法的典型模型和算法
- 蒙特卡洛模拟方法是一种基于随机采样的模拟方法,用于模拟复杂系统或过程,并获得其概率分布或特性。在机器学习领域,蒙特卡洛模拟方法被广泛应用于计算机视觉、自然语言处理和强化学习等问题。本文将介绍一些常见的蒙特卡洛模拟方法模型和算法。马尔可夫链蒙特卡洛(MCMC)马尔可夫链蒙特卡洛是基于马尔可夫链的蒙特卡洛模拟方法,用于计算复杂的概率分布。在MCMC算法中,我们需要定义一个状态转移概率矩阵,确保状态转移满足马尔可夫链的性质。然后,我们可以利用这个状态转移概率矩阵生成样本,并利用这些样本来估计概率分布。在MCMC
- 29分钟前 机器学习 0
-
 正版软件
正版软件
- 运营商线路故障导致网络波动,腾讯游戏回应“大量玩家掉线”问题已解决
- 本站1月12日消息,今日凌晨,大量网友反馈腾讯旗下《英雄联盟》《穿越火线》《英雄联盟手游》《地下城与勇士》《金铲铲之战》《和平精英》等游戏服务器崩溃,在线玩家集体掉线。今日上午,腾讯游戏官方微博给出回应:“今夜0时许,因运营商线路故障导致网络波动,部分区域服务器的用户出现掉线和暂时无法登录的情况。相关异常现已恢复。对于由此造成的不便,我们深表歉意。”本站发现,腾讯官方没有给出任何补偿内容,评论区则有不少呼吁补偿的声音。去年12月,腾讯视频也曾出现网络故障,具体表现包括不限于首页无法加载内容、VIP用户看不
- 44分钟前 腾讯游戏 0
-
 正版软件
正版软件
- TTS标注:类型和方法简介
- TTS标注是指在文本到语音合成过程中进行的标注工作。TTS技术则是指将文字自动转换为语音的技术。它的应用领域广泛,包括语音助手、语音导航、自动语音应答系统等。TTS标注的类型包括以下几种:文本标注:原始文本,包括语音识别转写和自然语言生成文本。音素标注:标注每个音素在文本中的位置及对应的音素内容,用于训练TTS模型中的音素分类器。韵律标注是指在文本中对基本语音单位(如音节或单词)进行标注,并记录它们的语音属性,如音高、时长和强度。这些标注用于训练文本转语音(TTS)模型中的韵律模型。语音标注:标注TTS生
- 59分钟前 人工智能 机器学习 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1808天前
-
 2
2
- Overture设置踏板标记的方法
- 1645天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1635天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1833天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1799天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1795天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1810天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1831天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00