Pika北大斯坦福借助LLM开发新框架,提升复杂提示词的理解力
 发布于2024-11-23 阅读(0)
发布于2024-11-23 阅读(0)
扫一扫,手机访问
Pika北大斯坦福联手,开源最新文本-图像生成/编辑框架!
无需额外训练,即可让扩散模型拥有更强提示词理解能力。
面对超长、超复杂提示词,准确性更高、细节把控更强,而且生成图片更加自然。
效果超越最强图像生成模型Dall·E 3和SDXL。
比如要求图片左右冰火两重天,左边有冰山、右边有火山。
SDXL完全没有符合提示词要求,Dall·E 3没有生成出来火山这一细节。

还能通过提示词对生成图像二次编辑。
这就是文本-图像生成/编辑框架RPG(Recaption,Plan and Generate),已经在网上引起热议。

它由北大、斯坦福、Pika联合开发。作者包括北大计算机学院崔斌教授、Pika联合创始人兼CTO Chenlin Meng等。
目前框架代码已开源,兼容各种多模态大模型(如MiniGPT-4)和扩散模型主干网络(如ControlNet)。
利用多模态大模型做增强
一直以来,扩散模型在理解复杂提示词方面都相对较弱。
一些已有改进方法,要么最终实现效果不够好,要么需要进行额外训练。
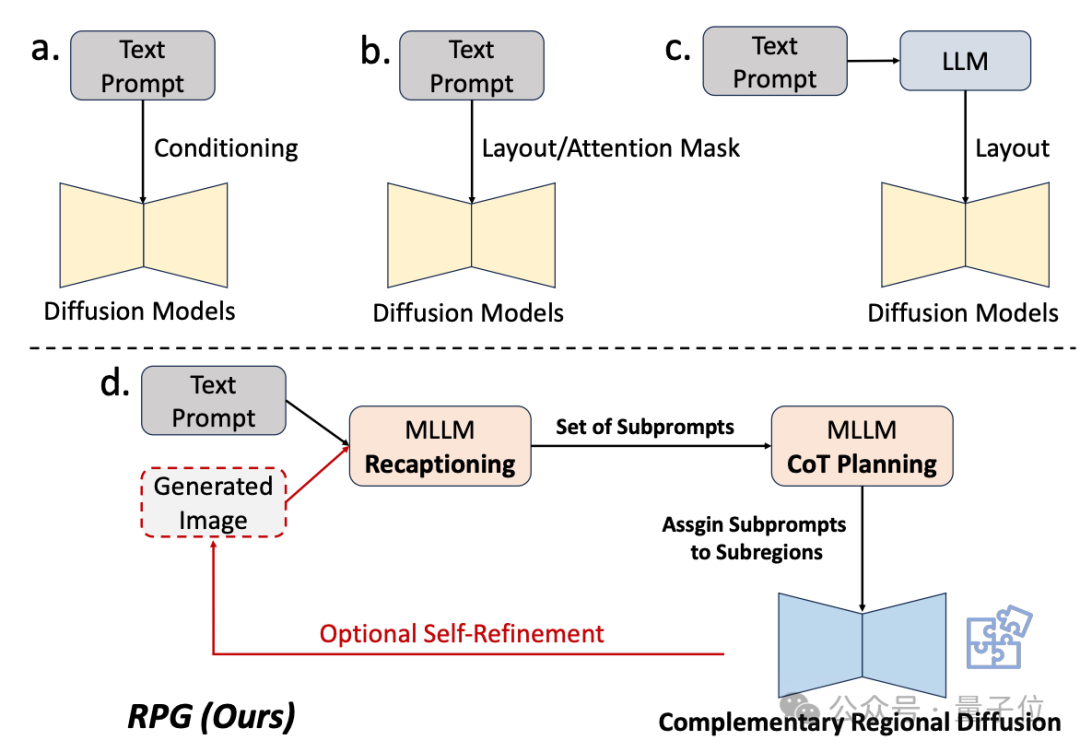
因此研究团队利用多模态大模型的理解能力来增强扩散模型的组合能力、可控能力。
从框架名字可以看出,它是让模型“重新描述、规划和生成”。
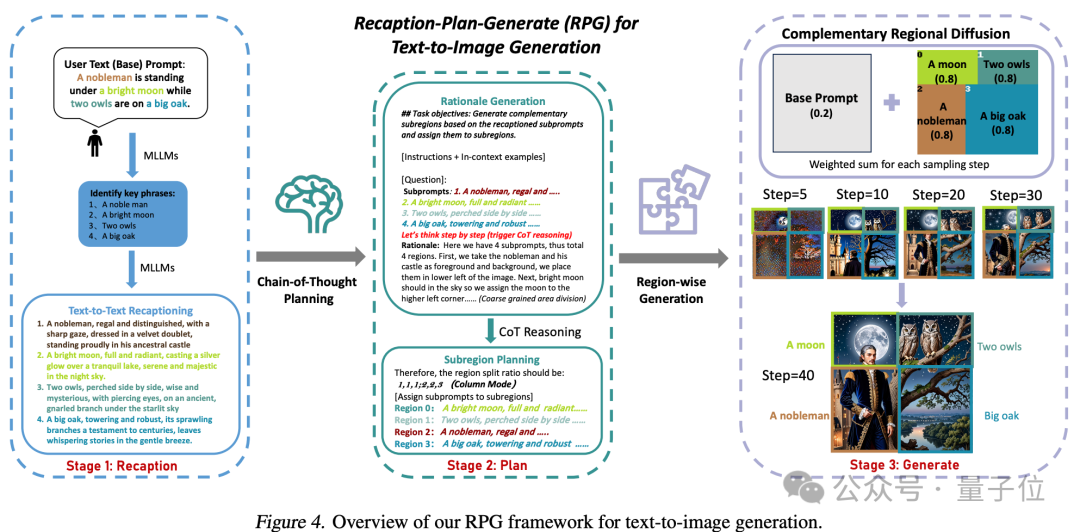
该方法的核心策略有三方面:
1、多模态重新描述(Multimodal Recaptioning):利用大模型将复杂文本提示拆解为多个子提示,并对每个子提示进行更加详细的重新描述,以此提升扩散模型对提示词的理解能力。
2、思维链规划(Chain-of-Thought Planning):利用多模态大模型的思维链推理能力,将图像空间划分为互补的子区域,并为每个子区域匹配不同的子提示,将复杂的生成任务拆解为多个更简单的生成任务。

3、互补区域扩散(Complementary Regional Diffusion):将空间划分好后,非重叠的区域各自根据子提示生成图像,然后进行拼接。
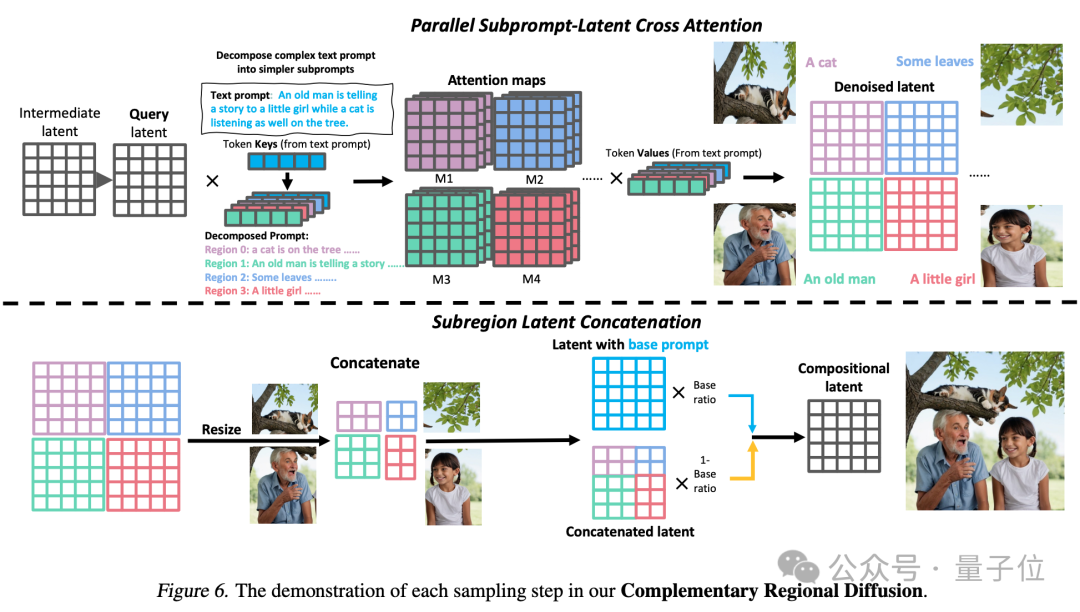
最后就能生成出一张更加符合提示词要求的图片。

RPG框架还可以利用姿态、深度等信息进行图像生成。
和ControlNet对比,RPG能进一步拆分输入提示词。
用户输入:在一间明亮的房间里,站着一位身穿香槟色长袖正装、正闭着双眼的漂亮黑发女孩。房间左边放着一只插着粉色玫瑰花的精致蓝花瓶,右边有一些生机勃勃的白玫瑰。
基础提示词:一个漂亮女孩站在她的明亮的房间里。
区域0:一个装着粉玫瑰的精致蓝花瓶
区域1:一个身穿香槟色长袖正装的漂亮黑发女孩闭着双眼。
区域2:一些生机勃勃的白玫瑰。

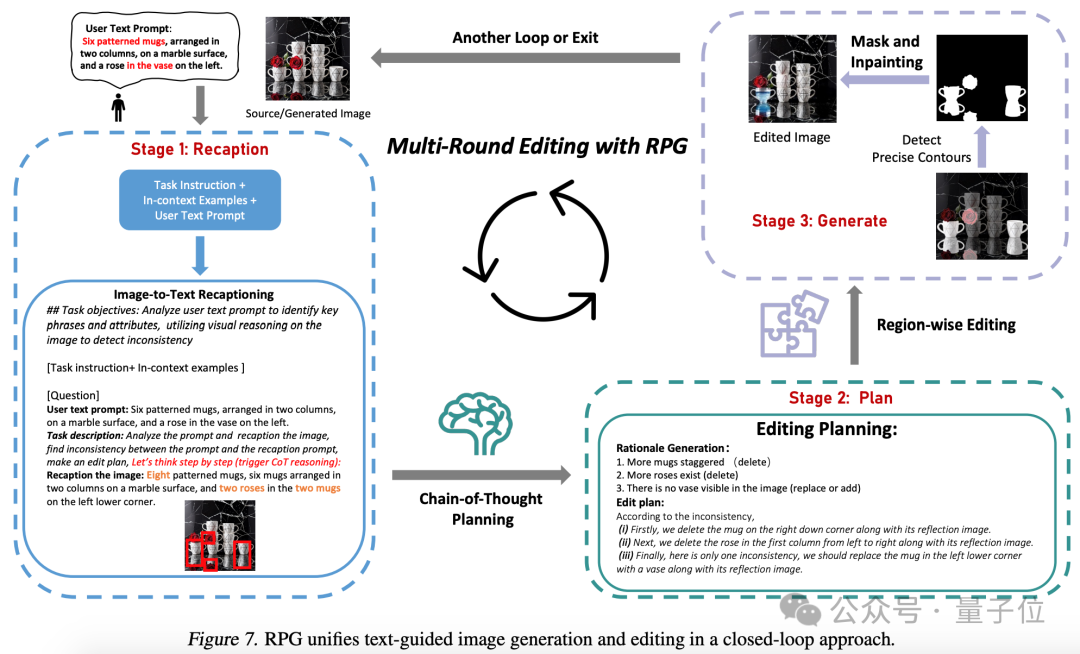
也能实现图像生成、编辑闭环。
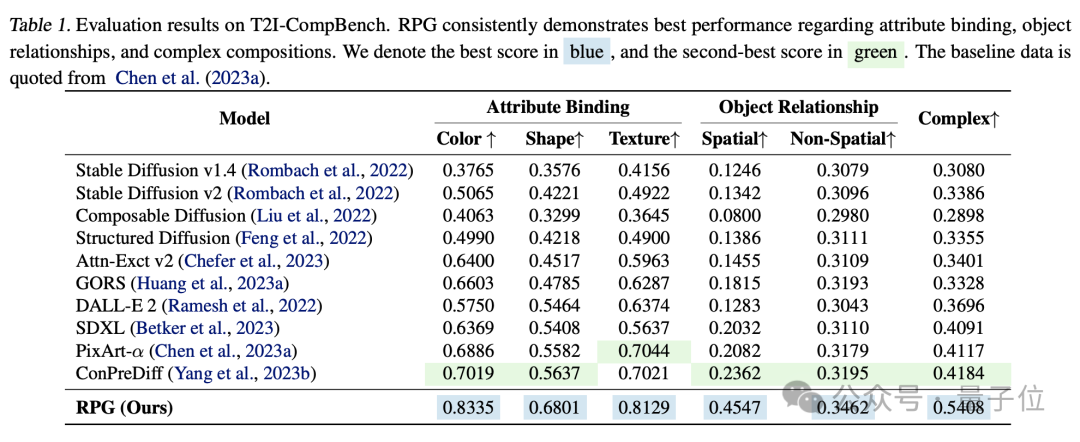
实验对比来看,RPG在色彩、形状、空间、文字准确等维度都超越其他图像生成模型。
研究团队
该研究有两位共同一作Ling Yang、Zhaochen Yu,都来自北大。
参与作者还有AI创企Pika联合创始人兼CTO Chenlin Meng。
她是斯坦福计算机博士,在计算机视觉、3D视觉方面有着丰富学术经历,参与的去噪扩散隐式模型(DDIM)论文,如今单篇引用已有1700+。并有多篇生成式AI相关研究发表在ICLR、NeurIPS、CVPR、ICML等顶会上,且多篇入选Oral。
去年,Pika凭借AI视频生成产品Pika 1.0一炮而红,2位斯坦福华人女博士创办的背景,使其更加引人注目。

△左为郭文景(Pika CEO),右为Chenlin Meng
参与研究的还有北大计算机学院副院长崔斌教授,他还是数据科学与工程研究所长。

另外,斯坦福AI实验室博士Minkai Xu、斯坦福助理教授Stefano Ermon共同参与这项研究。
论文地址:https://arxiv.org/abs/2401.11708
代码地址:https://github.com/YangLing0818/RPG-DiffusionMaster
下一篇:Golang的未来发展方向如何?
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 华为太空表亮相:拉瓦尔喷管灵感 诠释太空探索精神
- 华为于4月8日正式推出了全新的智能手表——华为WATCH4Pro太空探索。这款手表的设计灵感来源于火箭的拉瓦尔喷管,这一应用在火箭推进系统的关键组件,象征着人类对物理极限的挑战和对宇宙的无尽探索。华为WATCH4Pro,太空探索不仅是对航天科技的一种致敬,更是将高科技理念融入到日常生活中的一种尝试。该手表首次采用了航天级的超硬金刚钢材质,并通过先进的类金刚石涂层(DLC)技术,使得表壳和表带的硬度达到了普通钢属的两倍,显著增强了其耐磨和抗腐蚀能力。根据小编了解,华为WATCH4Pro太空探索在细节设计上也
- 12分钟前 0
-
 正版软件
正版软件
- tp怎么看别人的钱包地址
- 要查看他人的TP钱包地址,可请求其地址,然后使用TP钱包应用扫描二维码或通过电子邮件、社交媒体或区块浏览器获取地址。请注意安全提示,包括验证地址,并小心网络钓鱼诈骗。
- 17分钟前 0
-
 正版软件
正版软件
- 比特现金经历过几次减半
- 比特现金(BCH)已经历过两次减半,分别发生在2018年4月15日(区块高度504,000)和2020年4月8日(区块高度1,008,000)。在每次减半中,矿工区块奖励都减半,目的是为了控制BCH供应,防止通货膨胀,并保持其价值稳定。
- 32分钟前 0
-
 正版软件
正版软件
- 嘉实国际:目标2年内将香港比特币、以太坊现货ETF纳入沪港通
- 本站(120bTC.coM):嘉实国际是在香港首批发行比特币、以太坊现货ETF的三大发行商之一,其执行长韩同利周四在参与比特币亚洲峰会期间向南华早报表示,若未来两年「一切顺利」,该公司不排除申请将其加密货币现货ETF纳入沪港通计划。中国与香港ETF互通的机制是在2022年5月推出,让中国境内投资者可接触一系列香港上市指定ETF,是更大规模的沪港通计划的一环。据了解,沪港通于2014年启动,是中国境内与香港之间的市场互联互通计划。如果真能将加密货币ETF纳入沪港通,有望为市场带来重大信心提振,并提供大量新的
- 47分钟前 C2C平台 以太坊价格 以太坊养猫 以太坊钱包 嘉楠耘智 0
-
 正版软件
正版软件
- 炒币交易软件排名前十名有哪些
- 目前炒币交易软件排名前十包括:币安、火币、OKX、派安盈、Coinbase、Kraken、Gemini、Poloniex、Bitstamp、BitMEX。在选择交易软件时,应考虑安全性、币种选择、交易费、可用性、监管合规等因素。
- 1小时前 15:55 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1880天前
-
 2
2
- Overture设置踏板标记的方法
- 1717天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1707天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1905天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1871天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1867天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1882天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1903天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00