Yi-VL开源零一万物多模态大模型,在MMMU和CMMMU两大权威榜单中占据领先地位
 发布于2024-11-23 阅读(0)
发布于2024-11-23 阅读(0)
扫一扫,手机访问
https://huggingface.co/01-ai https://www.modelscope.cn/organization/01ai



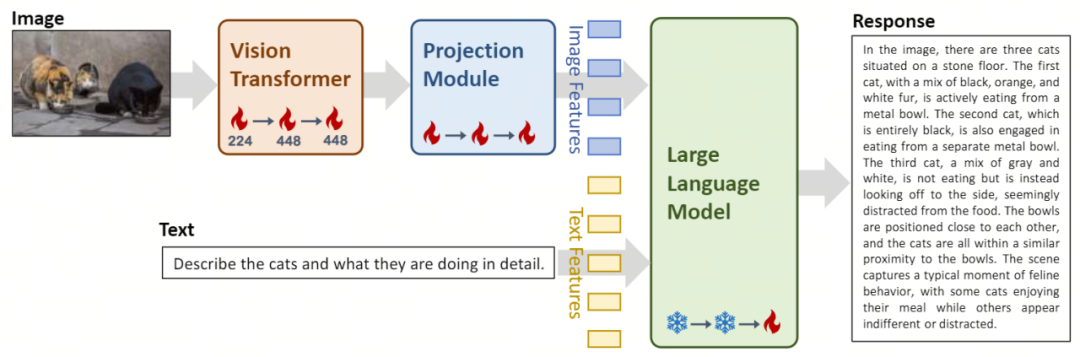
Vision Transformer(简称 ViT)用于图像编码,使用开源的 OpenClip ViT-H/14 模型初始化可训练参数,通过学习从大规模「图像 - 文本」对中提取特征,使模型具备处理和理解图像的能力。 Projection 模块为模型带来了图像特征与文本特征空间对齐的能力。该模块由一个包含层归一化(layer normalizations)的多层感知机(Multilayer Perceptron,简称 MLP)构成。这一设计使得模型可以更有效地融合和处理视觉和文本信息,提高了多模态理解和生成的准确度。 Yi-34B-Chat 和 Yi-6B-Chat 大规模语言模型的引入为 Yi-VL 提供了强大的语言理解和生成能力。该部分模型借助先进的自然语言处理技术,能够帮助 Yi-VL 深入理解复杂的语言结构,并生成连贯、相关的文本输出。
第一阶段:零一万物使用 1 亿张的「图像 - 文本」配对数据集训练 ViT 和 Projection 模块。在这一阶段,图像分辨率被设定为 224x224,以增强 ViT 在特定架构中的知识获取能力,同时实现与大型语言模型的高效对齐。 第二阶段:零一万物将 ViT 的图像分辨率提升至 448x448,这一提升让模型更加擅长识别复杂的视觉细节。此阶段使用了约 2500 万「图像 - 文本」对。 第三阶段:零一万物开放整个模型的参数进行训练,目标是提高模型在多模态聊天互动中的表现。训练数据涵盖了多样化的数据源,共约 100 万「图像 - 文本」对,确保了数据的广泛性和平衡性。
本文转载于:https://www.jiqizhixin.com/articles/2024-01-22-10 如有侵犯,请联系admin@zhengruan.com删除
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 三星计划推出入门级Galaxy Z Fold6,旨在加强中国市场折叠屏手机布局
- 据韩媒TheElec报道,三星计划推出一款入门级的GalaxyZFold6折叠屏手机,以巩固其在折叠屏手机市场的领导地位并进一步拓展中国市场。三星此举意味着他们首次尝试进入入门级折叠屏手机市场。然而,考虑到商业环境的不稳定性,三星内部对于此举是否会对盈利能力产生负面影响持谨慎态度。自2019年首款折叠屏手机GalaxyFold问世以来,三星已逐步构建起GalaxyZFold与GalaxyZFlip两大产品线,并保持着每年推出一款新品的稳定更新节奏。根据最新消息,今年三星折叠屏手机阵容将迎来重大变化。除了即
- 8分钟前 三星 0
-
 正版软件
正版软件
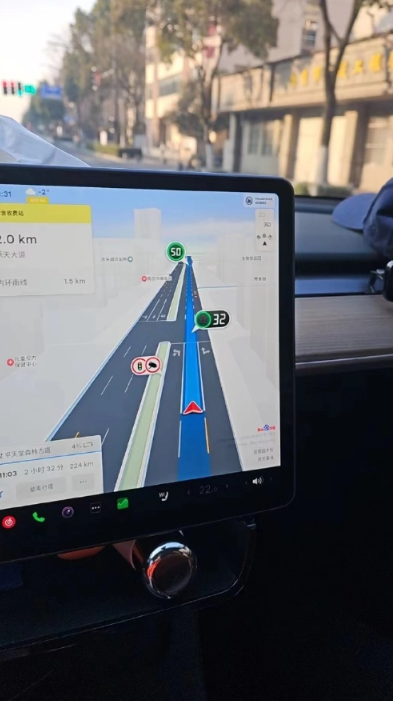
- 特斯拉中国版推出升级版,地图导航与娱乐功能双重提升
- 根据博主“不是郑小康”的消息,特斯拉计划在不久的将来为中国市场推出全新的车道级导航功能。据称,该功能有望在春节期间正式上线。根据该博主提供的截图信息,特斯拉正在测试的地图版本中,已经集成了一些实用功能,如红绿灯倒计时显示和车道级导航。地图界面设计简洁明了,右下角的百度标志显示了特斯拉与百度地图合作共同实现的功能。小编了解到,特斯拉中国团队最近向用户推送了2023.44.32版本更新。这个版本是专门为中国市场和中国车主量身定制的,其中特别增强了两项地图相关的功能。在导航过程中,地图右上角会显示接下来两个高速
- 21分钟前 特斯拉 0
-
 正版软件
正版软件
- Winamp移动版正式上架App Store和谷歌Play商店,为音乐爱好者带来全新选择
- 备受音乐爱好者关注的Winamp媒体播放器在移动市场上迈出了重要一步。近日,该播放器的移动应用程序(支持安卓和iOS系统)经过内测阶段后,正式版已在AppStore上架。这对于Winamp来说是一个重要的里程碑,标志着这款经典音乐播放器正式进军移动市场。音乐爱好者可以在手机上享受Winamp的卓越音质和丰富的功能,随时随地畅享音乐的魅力。这次推出的正式版本相信会满足用户的需求,并在移动市场上赢得更多的用户。尽管Winamp的移动应用在中国区的AppStore中没有中文支持且评论数为零,但在美国区已经有三条
- 33分钟前 winamp 0
-
 正版软件
正版软件
- 比亚迪元UP内饰谍照曝光,即将推出小型电动SUV
- 1月17日消息,近日,比亚迪元UP的内饰谍照曝光,预示着这款全新的SUV车型可能成为元Pro系列的新一代产品。主打小型纯电SUV市场,预计售价约10万元。根据内饰谍照显示,比亚迪元UP配备了一块尺寸庞大的中控屏幕,并保留了液晶仪表。与其他新能源汽车不同的是,元UP内饰保留了大量的实体按键和旋钮,这种设计有望提升车辆的实用性和操控便利性。尽管车辆座椅仍处于试验阶段,但从座椅颜色来看,元UP将采用年轻化设计的浅色座椅。这些调整将为驾驶者提供更好的驾驶体验和舒适度。据了解,该车已经通过工信部的申报,外观方面采用
- 48分钟前 比亚迪 0
-
 正版软件
正版软件
- 岩芯数智发布离线端侧部署的非Attention机制大型模型
- 1月24日,上海岩芯数智人工智能科技有限公司对外推出了一个非Attention机制的通用自然语言大模型——Yan模型。岩芯数智发布会上称,Yan模型使用了全新自研的“Yan架构”代替Transformer架构,相较于Transformer,Yan架构的记忆能力提升3倍、速度提升7倍的同时,实现推理吞吐量的5倍提升。岩芯数智CEO刘凡平认为,以大规模著称的Transformer,在实际应用中的高算力和高成本,让不少中小型企业望而却步。其内部架构的复杂性,让决策过程难以解释;长序列处理困难和无法控制的幻觉问题
- 1小时前 20:30 入门 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1809天前
-
 2
2
- Overture设置踏板标记的方法
- 1646天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1636天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1834天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1800天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1796天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1811天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1832天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00