Transformer模型在20亿数据中学习物理世界,成功应用于视频生成挑战的通用世界模型
 发布于2024-11-25 阅读(0)
发布于2024-11-25 阅读(0)
扫一扫,手机访问
建立会做视频的世界模型,也能通过Transformer来实现了!
来自清华和极佳科技的研究人员联手,推出了全新的视频生成通用世界模型——WorldDreamer。
它可以完成多种视频生成任务,包括自然场景和自动驾驶场景,如文生视频、图生视频、视频编辑、动作序列生视频等。

据团队介绍,通过预测Token的方式来建立通用场景世界模型,WorldDreamer是业界首个。
它把视频生成转换为一个序列预测任务,可以对物理世界的变化和运动规律进行充分地学习。
可视化实验已经证明,WorldDreamer已经深刻理解了通用世界的动态变化规律。
那么,它都能完成哪些视频任务,效果如何呢?
支持多种视频任务
图像生成视频(Image to Video)
WorldDreamer可以基于单一图像预测未来的帧。
只需首张图像输入,WorldDreamer将剩余的视频帧视为被掩码的视觉Token,并对这部分Token进行预测。
如下图所示,WorldDreamer具有生成高质量电影级别视频的能力。
其生成的视频呈现出无缝的逐帧运动,类似于真实电影中流畅的摄像机运动。
而且,这些视频严格遵循原始图像的约束,确保帧构图的显著一致性。

文本生成视频(Text to Video)
WorldDreamer还可以基于文本进行视频生成。
仅仅给定语言文本输入,此时WorldDreamer认为所有的视频帧都是被掩码的视觉Token,并对这部分Token进行预测。
下图展示了WorldDreamer在各种风格范式下从文本生成视频的能力。
生成的视频与输入语言无缝契合,其中用户输入的语言可以塑造视频内容、风格和相机运动。

视频修改(Video Inpainting)
WorldDreamer进一步可以实现视频的inpainting任务。
具体来说,给定一段视频,用户可以指定mask区域,然后根据语言的输入可以更改被mask区域的视频内容。
如下图所示,WorldDreamer可以将水母更换为熊,也可以将蜥蜴更换为猴子,且更换后的视频高度符合用户的语言描述。

视频风格化(Video Stylization)
除此以外,WorldDreamer可以实现视频的风格化。
如下图所示,输入一个视频段,其中某些像素被随机掩码,WorldDreamer可以改变视频的风格,例如根据输入语言创建秋季主题效果。

基于动作合成视频(Action to Video)
WorldDreamer也可以实现在自动驾驶场景下的驾驶动作到视频的生成。
如下图所示,给定相同的初始帧以及不同的驾驶策略(如左转、右转),WorldDreamer可以生成高度符合首帧约束以及驾驶策略的视频。

那么,WorldDreamer又是怎样实现这些功能的呢?
用Transformer构建世界模型
研究人员认为,目前最先进的视频生成方法主要分为两类——基于Transformer的方法和基于扩散模型的方法。
利用Transformer进行Token预测可以高效学习到视频信号的动态信息,并可以复用大语言模型社区的经验,因此,基于Transformer的方案是学习通用世界模型的一种有效途径。
而基于扩散模型的方法难以在单一模型内整合多种模态,且难以拓展到更大参数,因此很难学习到通用世界的变化和运动规律。
而当前的世界模型研究主要集中在游戏、机器人和自动驾驶领域,缺乏全面捕捉通用世界变化和运动规律的能力。
所以,研究团队提出了WorldDreamer来加强对通用世界的变化和运动规律的学习理解,从而显著增强视频生成的能力。
借鉴大型语言模型的成功经验,WorldDreamer采用Transformer架构,将世界模型建模框架转换为一个无监督的视觉Token预测问题。
具体的模型结构如下图所示:
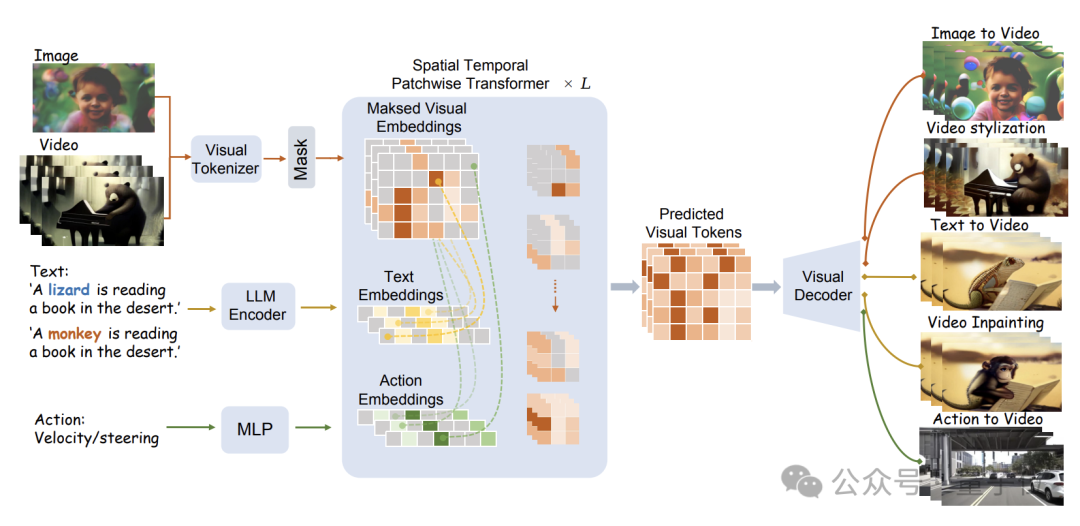
WorldDreamer首先使用视觉Tokenizer将视觉信号(图像和视频)编码为离散的Token。
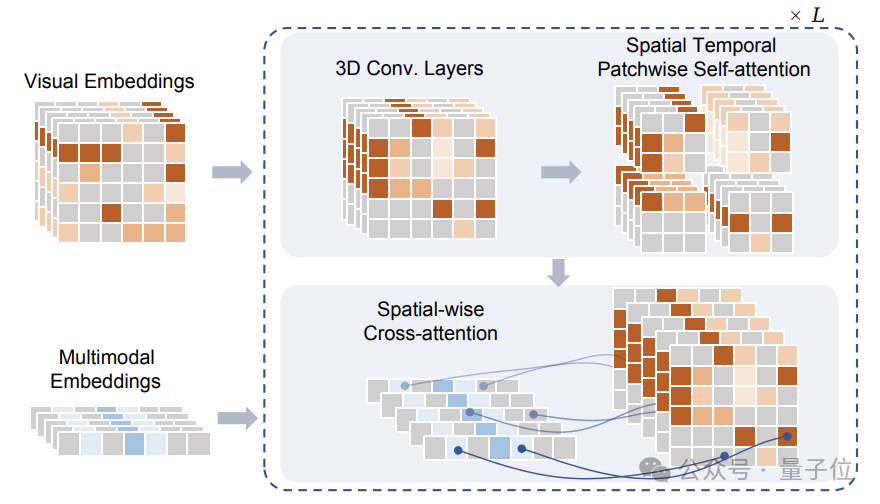
这些Token在经过掩蔽处理后,输入给研究团队提出的Sptial Temporal Patchwuse Transformer(STPT)模块。
同时,文本和动作信号被分别编码为对应的特征向量,以作为多模态特征一并输入给STPT。
STPT在内部对视觉、语言、动作等特征进行充分的交互学习,并可以预测被掩码部分的视觉Token。
最终,这些预测出的视觉Token可以用来完成各种各样的视频生成和视频编辑任务。
值得注意的是,在训练WorldDreamer时,研究团队还构建了Visual-Text-Action(视觉-文本-动作)数据的三元组,训练时的损失函数仅涉及预测被掩蔽的视觉Token,没有额外的监督信号。
而在团队提出的这个数据三元组中,只有视觉信息是必须的,也就是说,即使在没有文本或动作数据的情况下,依然可以进行WorldDreamer的训练。
这种模式不仅降低了数据收集的难度,还使得WorldDreamer可以支持在没有已知或只有单一条件的情况下完成视频生成任务。
研究团队使用大量数据对WorldDreamer进行训练,其中包括20亿经过清洗的图像数据、1000万段通用场景的视频、50万段高质量语言标注的视频、以及近千段自动驾驶场景视频。
团队对10亿级别的可学习参数进行了百万次迭代训练,收敛后的WorldDreamer逐渐理解了物理世界的变化和运动规律,并拥有了各种的视频生成和视频编辑能力。
论文地址:https://arxiv.org/abs/2401.09985
项目主页:https://world-dreamer.github.io/
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 多个异构大模型的融合带来非凡效果
- 随着LLaMA、Mistral等大语言模型的成功,许多公司开始创建自己的大语言模型。然而,从头训练新的模型成本高昂,且可能存在能力冗余。近日,中山大学和腾讯AILab的研究人员提出了FuseLLM,用于「融合多个异构大模型」。与传统的模型集成和权重合并方法不同,FuseLLM提供了一种新的方式来融合多个异构大语言模型的知识。与同时部署多个大语言模型或要求合并模型结果不同,FuseLLM使用轻量级的持续训练方法,将各个模型的知识和能力转移到一个融合的大语言模型中。这种方法的独特之处在于它能够在推理时使用多个
- 6分钟前 模型 AI 0
-
 正版软件
正版软件
- 2024年的AI和数字孪生:发展预测
- 人工智能(AI)和数字孪生是备受关注的技术领域,应用广泛。以下是它们的一些趋势:1.在城市中实施生成式人工智能到2024年,人工智能(AI)将在塑造城市技术格局方面发挥重要作用。城市已经取得了长足进展,特别是在交通管理和应急响应等领域运用人工智能。然而,过去18个月的突出发展是对生成式人工智能的潜力有了更深入的认识,尤其是在大型语言模型(LLM)的应用方面。生成式人工智能,以LLM为代表,展示了城市在提高效率和促进与信息的独特交互方面的潜在能力。预计城市将越来越多地采用LLM,主要是为了更好地为居民提供服
- 21分钟前 人工智能 数字孪生 0
-
 正版软件
正版软件
- 苹果:利用语言模型的自回归方法进行图像模型的预训练
- 1、背景在GPT等大模型出现后,语言模型这种Transformer+自回归建模的方式,也就是预测nexttoken的预训练任务,取得了非常大的成功。那么,这种自回归建模方式能不能在视觉模型上取得比较好的效果呢?今天介绍的这篇文章,就是Apple近期发表的基于Transformer+自回归预训练的方式训练视觉模型的文章,下面给大家展开介绍一下这篇工作。图片论文标题:ScalablePre-trainingofLargeAutoregressiveImageModels下载地址:https://arxiv.o
- 1小时前 23:00 模型 图像 预训练 0
-
 正版软件
正版软件
- 使知识图谱成为庞大模型的搭档
- 大型语言模型(LLM)具有生成流畅和连贯文本的能力,为人工智能的对话、创造性写作等领域带来了新的前景。然而,LLM也存在一些关键局限。首先,它们的知识仅限于从训练数据中识别出的模式,缺乏对世界的真正理解。其次,推理能力有限,不能进行逻辑推理或从多个数据源融合事实。面对更复杂、更开放的问题时,LLM的回答可能变得荒谬或矛盾,被称为“幻觉”。因此,尽管LLM在某些方面非常有用,但在处理复杂问题和真实世界情境时,仍存在一定的局限性。为了弥补这些差距,近年来出现了检索增强生成(RAG)系统,其核心思想是通过从外部
- 1小时前 22:50 人工智能 编码 结构化 0
-
 正版软件
正版软件
- 网友揭露了OpenAI新模型所使用的嵌入技术
- 前几天,OpenAI来了一波重磅更新,一口气宣布了5个新模型,其中就包括两个新的文本嵌入模型。嵌入是用数字序列来表示自然语言、代码等内容中的概念。它们能够帮助机器学习模型和其他算法更好地理解内容之间的关系,并且更容易执行聚类或检索等任务。通常,使用较大的嵌入模型(如存储在向量存储器中以供检索)会消耗更多的成本、算力、内存和存储资源。然而,OpenAI推出的两个文本嵌入模型提供了不同的选择。首先,text-embedding-3-small模型是一个较小但高效的模型。它可以在资源有限的环境下使用,并且在处理
- 1小时前 22:35 模型 AI 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1811天前
-
 2
2
- Overture设置踏板标记的方法
- 1648天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1638天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1837天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1802天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1798天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1813天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1835天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00