揭密LLM巫师:代码预训练的魔力和UIUC华人团队分享的三大优势
 发布于2024-11-25 阅读(0)
发布于2024-11-25 阅读(0)
扫一扫,手机访问
大模型时代的语言模型(LLM)尺寸和训练数据都增加了,包括自然语言和代码。
代码是人类和计算机之间的媒介,将高级目标转换为可执行的中间步骤。它具有语法标准、逻辑一致、抽象和模块化的特点。
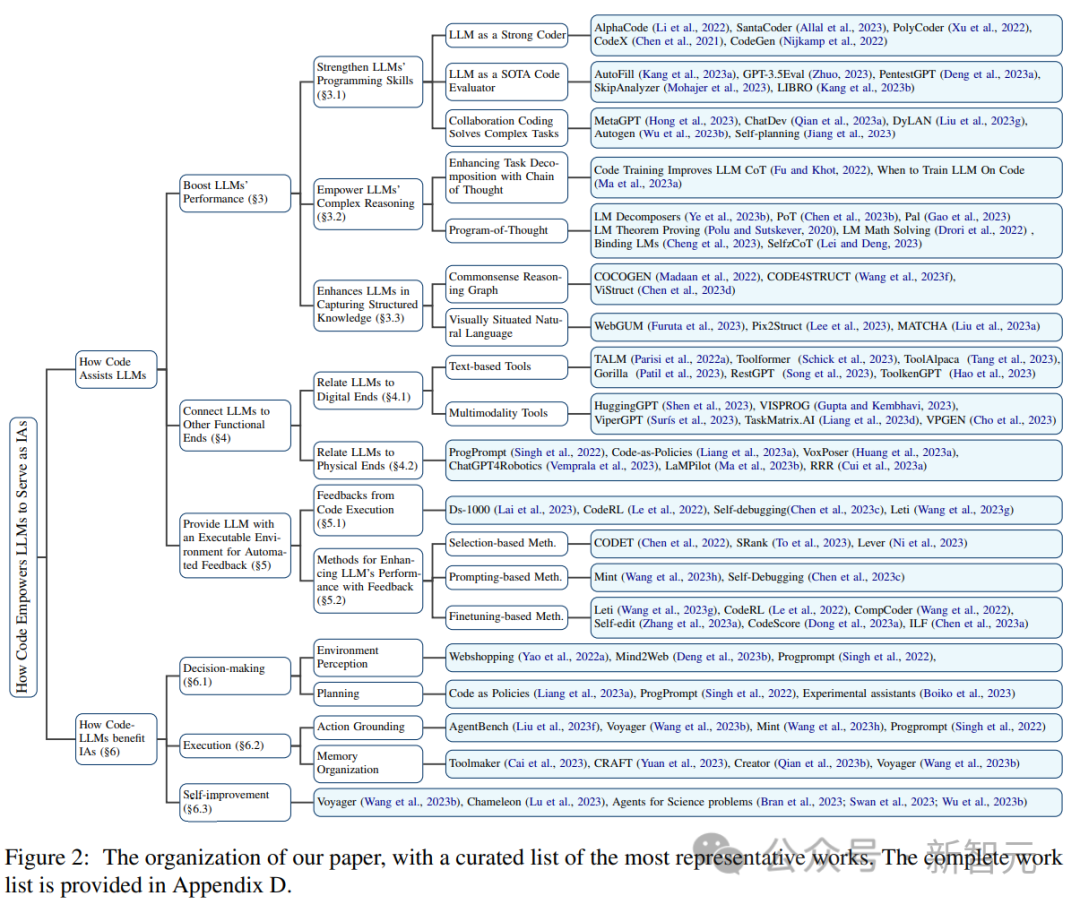
伊利诺伊大学香槟分校的研究团队最近发布了一篇综述报告,总结了将代码融入LLM训练数据的多种益处。

论文链接:https://arxiv.org/abs/2401.00812v1
具体来说,除了可以提升LLM在代码生成上的能力外,好处还包括以下三点:
1. 有助于解锁LLM的推理能力,使能够应用于一系列更复杂的自然语言任务上;
2. 引导LLM生成结构化且精确的中间步骤,之后可以通过函数调用的方式连接到外部执行终端(external execution ends);
3. 可以利用代码编译和执行环境为模型的进一步改进提供了更多样化的反馈信号。
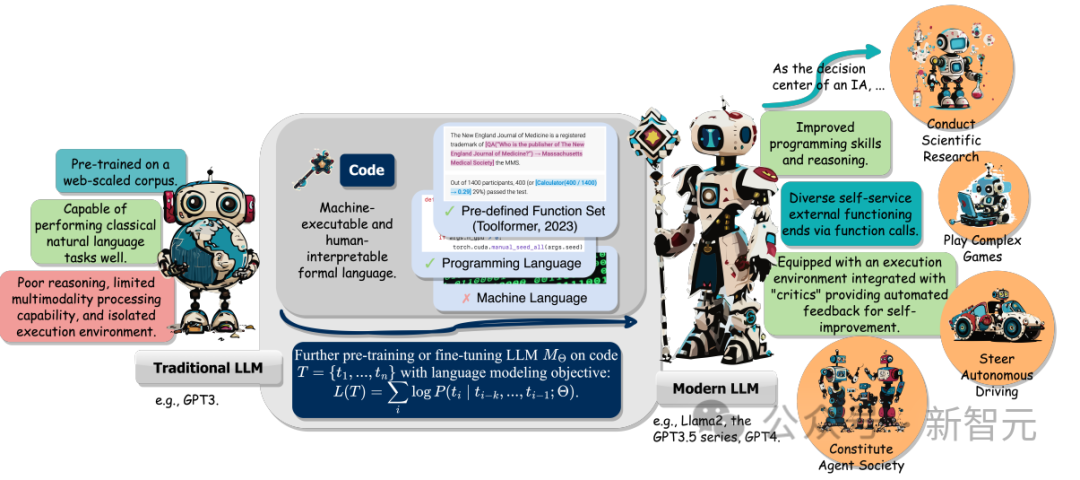
此外,研究人员还追踪了LLM作为智能智能体(intelligent agents,IA)时,在理解指令、分解目标、规划和执行行动(execute actions)以及从反馈中提炼的能力如何在下游任务中起到关键作用。
最后,文中还提出了「使用代码增强LLM」领域中关键的挑战以及未来的研究方向。
代码预训练提升LLM性能
以OpenAI的GPT Codex 为例,对 LLM 进行代码预训练后,可以扩大LLM的任务范围,除了自然语言处理外,模型还可以为数学理论生成代码、执行通用编程任务、数据检索等。
代码生成任务具有两个特性:1)代码序列需要有效执行,所以必须具有连贯的逻辑,2)每个中间步骤都可以进行逐步逻辑验证(step-by-step logic verification)。
在预训练中利用和嵌入代码的这两种特性,可以提高LLM思维链(CoT)技术在传统自然语言下游任务中的性能,表明代码训练能够提高LLM进行复杂推理的能力。
通过从代码的结构化形式中进行隐式学习,代码 LLM 在常识结构推理任务中也表现出更优的性能,例如与markup、HTML和图表理解相关的任务。
支持功能/函数终端(function ends)
最近的研究结果表明,将LLMs连接到其他功能终端(即,使用外部工具和执行模块增强LLMs)有助于LLMs更准确可靠地执行任务。
这些功能性目的使LLMs能够获取外部知识、参与到多种模态数据中,并与环境进行有效互动。

从相关工作中,研究人员观察到一个普遍的趋势,即LLMs生成编程语言或利用预定义的函数来建立与其他功能终端的连接,即「以代码为中心」的范式。
与LLM推理机制中严格硬编码工具调用的固定实践流程相反,以代码为中心的范式允许LLM动态生成tokens,并使用可适应的参数(adaptable parameters)调用执行模块,为LLM与其他功能终端交互提供了一种简单明了的方法,增强了其应用程序的灵活性和可扩展性。
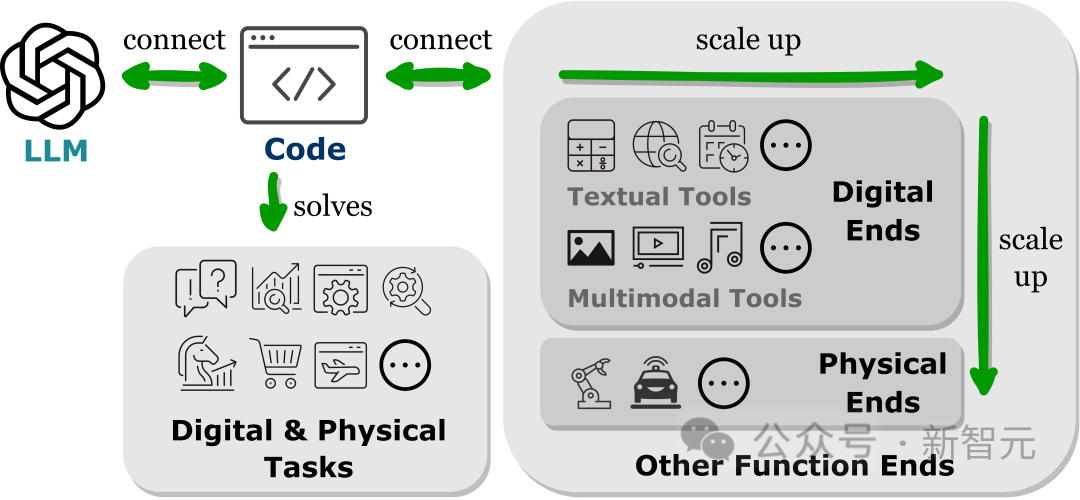
重要的是,这种范式可以让LLM与跨越不同模态和领域的众多功能终端进行交互;通过扩展可访问的功能终端的数量和种类,LLM可以处理更复杂的任务。
本文中主要研究了与LLM连接的文本和多模态工具,以及物理世界的功能端,包括机器人和自动驾驶,展现了LLM在解决各种模式和领域问题方面的多功能性。
提供自动反馈的可执行环境
LLMs表现出超出其训练参数的性能,部分原因是模型能够吸收反馈信号,特别是在非静态的现实世界应用中。
不过反馈信号的选择必须谨慎,因为嘈杂的提示可能会阻碍LLM在下游任务上的表现。
此外,由于人力成本高昂,因此在保持忠诚度(faithful)的同时自动收集反馈至关重要。
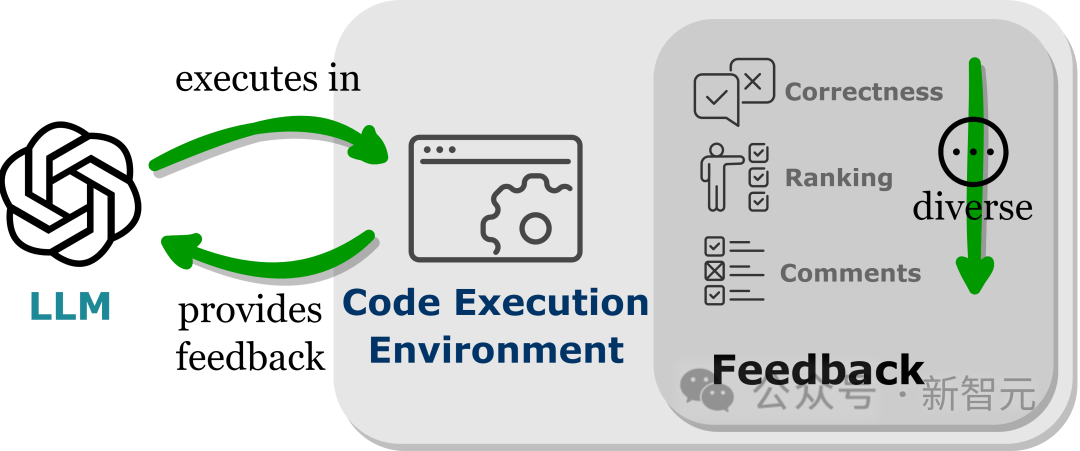
将LLMs嵌入到代码执行环境中可以实现上述条件的自动反馈。
由于代码执行在很大程度上是确定性的,LLMs从执行代码的结果中获取的反馈仍然忠实于目标任务;代码解释器还为LLMs查询内部反馈提供了一个自动路径,无需人工标注即可对LLMs生成的错误代码进行调试和优化。
此外,代码环境允许LLMs整合各种各样的外部反馈形式,包括但不限于二元正确性反馈,对结果的自然语言解释,以及奖励值排序,从而实现一个高度可定制的方法来提高性能。

当下的挑战
代码预训练与LLMs推理增强的因果关系
虽然从直觉上来看,代码数据的某些属性可能有助于LLMs的推理能力,但其对增强推理技能影响的确切程度仍然模糊不清。
在下一步的研究工作中,重要的是要研究在训练数据中加强认识:这些代码属性是否真的可以增强训练的LLMs的推理能力。
如果确实如此,对代码的特定属性进行预训练可以直接提高LLMs的推理能力,那么理解这种现象将是进一步提高当前模型复杂推理能力的关键。
不限于代码的推理能力
尽管通过代码预训练实现了对推理能力的增强,但基础模型仍然缺乏真正通用人工智能所期望的类似人类的推理能力。
除了代码之外,大量其他文本数据源也有可能增强LLM推理能力,其中代码的内在特征,如缺乏歧义、可执行性和逻辑顺序结构,为收集或创建这些数据集提供了指导原则。
但如果继续坚持在具有语言建模目标的大型语料库上训练语言模型的范式,很难有一种顺序可读的语言比形式语言更抽象:高度结构化,与符号语言密切相关,并且在数字网络环境中大量存在。
研究人员设想,探索可替代的数据模式、多样化的训练目标和新颖的架构将为进一步增强模型推理能力提供更多的机会。
以代码为中心范式在应用上的挑战
在LLMs中,使用代码连接到不同的功能终端的主要挑战是学习不同功能的正确调用方法,包括选择正确的功能(函数)终端以及在适当的时候传递正确的参数。
比如说一个简单的任务(网页导航),给定一组有限的动作原语后,如鼠标移动、点击和页面滚动,再给出一些例子(few-shot),一个强大的基础LLM往往需要LLM精确地掌握这些原语的使用。
对于数据密集型领域中更复杂的任务,如化学、生物学和天文学,这些任务涉及对特定领域python库的调用,其中包含许多不同功能的复杂函数,增强LLMs正确调用这些功能函数的学习能力是一个前瞻性的方向,可以使LLMs在细粒度领域中执行专家级任务。
从多轮互动和反馈中学习
LLMs通常需要与用户和环境进行多次交互,不断纠正自己以改善复杂任务的完成。
虽然代码执行提供了可靠和可定制的反馈,但尚未建立一种完全利用这种反馈的完美方法。
当下基于选择的方法虽然有用,但不能保证提高性能,而且效率低下;基于递归的方法严重依赖于LLM的上下文学习能力,这可能会限制其适用性;微调方法虽然做出了持续的改进,但数据收集和微调是资源密集型的,实际使用时很困难。
研究人员认为强化学习可能是一种更有效的利用反馈和改进的方法,可以提供一种动态的方式来适应反馈,通过精心设计的奖励功能,潜在地解决当前技术的局限性。
但仍然需要大量的研究来了解如何设计奖励函数,以及如何将强化学习与LLMs最佳地集成以完成复杂的任务。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 董明珠:格力电器在2023年实现290亿元利润,创税收历史新纪录
- 格力电器董事长董明珠在格力2024全球梦想盛典活动上透露了令人瞩目的消息。据董明珠透露,2023年,格力电器的利润预计将达到约290亿,这将创造历史新高的税收。董明珠表示,她希望在2024年,格力电器的税收能够超过200亿,为国家做出更大的贡献。这一消息引起了广泛的关注和期待。格力电器作为中国领先的家电企业,展现了其强大的实力和发展潜力。董明珠希望通过持续的创新和董明珠还表示,“展望未来,24年、25年,未来五年,我们争取翻一番”。她称,创新是企业的生命力,没有创新企业不可能发展她说,2023年形势复杂,
- 5分钟前 格力 董明珠 0
-
 正版软件
正版软件
- 中文LMM体质更适合的基准CMMMU来袭:30个以上细分学科,12K专家级题目齐聚
- 随着多模态大模型(LMM)的不断进步,对于评估LMM性能的需求也在增长。尤其在中文环境下,评估LMM的高级知识和推理能力变得更加重要。在这个背景下,为了评估基本模型在中文各种任务中的专家级多模态理解能力,M-A-P开源社区、港科大、滑铁卢大学和零一万物共同推出了CMMMU(ChineseMassiveMulti-disciplineMultimodalUnderstandingandReasoning)基准。该基准旨在提供一个全面的中文大规模多学科多模态理解和推理的评估平台。通过该基准,研究人员可以测试模
- 20分钟前 模型 数据 0
-
 正版软件
正版软件
- 多个异构大模型的融合带来非凡效果
- 随着LLaMA、Mistral等大语言模型的成功,许多公司开始创建自己的大语言模型。然而,从头训练新的模型成本高昂,且可能存在能力冗余。近日,中山大学和腾讯AILab的研究人员提出了FuseLLM,用于「融合多个异构大模型」。与传统的模型集成和权重合并方法不同,FuseLLM提供了一种新的方式来融合多个异构大语言模型的知识。与同时部署多个大语言模型或要求合并模型结果不同,FuseLLM使用轻量级的持续训练方法,将各个模型的知识和能力转移到一个融合的大语言模型中。这种方法的独特之处在于它能够在推理时使用多个
- 35分钟前 模型 AI 0
-
 正版软件
正版软件
- 2024年的AI和数字孪生:发展预测
- 人工智能(AI)和数字孪生是备受关注的技术领域,应用广泛。以下是它们的一些趋势:1.在城市中实施生成式人工智能到2024年,人工智能(AI)将在塑造城市技术格局方面发挥重要作用。城市已经取得了长足进展,特别是在交通管理和应急响应等领域运用人工智能。然而,过去18个月的突出发展是对生成式人工智能的潜力有了更深入的认识,尤其是在大型语言模型(LLM)的应用方面。生成式人工智能,以LLM为代表,展示了城市在提高效率和促进与信息的独特交互方面的潜在能力。预计城市将越来越多地采用LLM,主要是为了更好地为居民提供服
- 50分钟前 人工智能 数字孪生 0
-
 正版软件
正版软件
- 苹果:利用语言模型的自回归方法进行图像模型的预训练
- 1、背景在GPT等大模型出现后,语言模型这种Transformer+自回归建模的方式,也就是预测nexttoken的预训练任务,取得了非常大的成功。那么,这种自回归建模方式能不能在视觉模型上取得比较好的效果呢?今天介绍的这篇文章,就是Apple近期发表的基于Transformer+自回归预训练的方式训练视觉模型的文章,下面给大家展开介绍一下这篇工作。图片论文标题:ScalablePre-trainingofLargeAutoregressiveImageModels下载地址:https://arxiv.o
- 1小时前 23:00 模型 图像 预训练 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1811天前
-
 2
2
- Overture设置踏板标记的方法
- 1648天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1638天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1837天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1802天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1798天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1813天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1835天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00