UC伯克利华人发布全方位视角的3DHM框架,通过一张图片实现任意视频动作模仿
 发布于2024-11-26 阅读(0)
发布于2024-11-26 阅读(0)
扫一扫,手机访问
动作模仿需要考虑人物的姿势和外观变化,不仅要模仿肢体动作,还需要建模衣服和人物外观的变化。
 图片
图片
当输入图像为正面时,若模仿的视频动作包括转身,模型需预测衣服的背面和转动时的飘动样子。
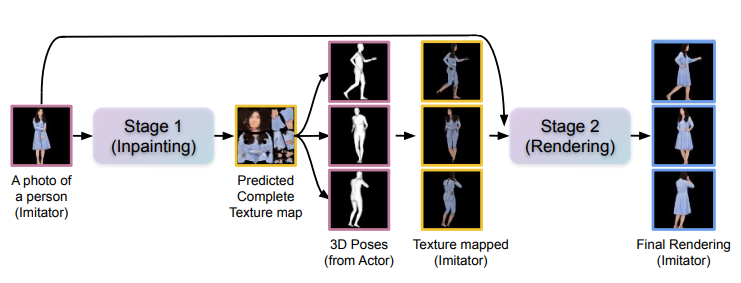
为了解决这个问题,加州大学伯克利分校的研究人员提出了3DHM框架,该框架基于扩散模型,并采用两阶段方法。首先,他们通过从单个图像生成纹理图来合成3D人体运动。然后,再渲染3D人体以模仿视频中演员的动作。这种方法有望为实现高质量的3D人体合成和动画提供新的解决方案。
 图片
图片
论文地址:https://arxiv.org/abs/2401.10889
3DHM模型中包含两个核心组件:
1. 学习人体和服装中不可见部分的先验知识。
研究人员利用填充扩散(in-filling diffusion)模型,通过在给定的单张图像中进行想象(hallucination),可以揭示出不可见部分。为了提高采样效率,在姿势和视点不变的条件下,研究人员在纹理图空间(texture map space)对该模型进行了训练。这种方法可以微调图像细节,使得原始图像更加完整和准确。通过这种技术,我们可以更好地理解和分析图像数据,并在各种应用中提供更好的结果。
2. 使用适当的服装和纹理渲染出不同的身体姿势。
研究人员开发了一个基于扩散模型的渲染pipeline,由3D人体姿势控制,从而可以生成目标人物在不同姿势下的逼真渲染,包括衣服、头发和看不见区域下的合理填充。
该方法可以生成一系列忠实于目标运动的3D姿态、在视觉上与输入更相似的图像;3D控件还能够使用各种合成相机轨迹来渲染人物。
实验结果表明,相比以前的方法,该方法在生成长时间运动和各种高难度的姿势上更有弹性(resilient)。
合成运动中的人物
 图片
图片
纹理贴图涂色(Texture map Inpainting)
第一阶段模型的目标是通过涂色模仿者的不可见区域,生成可信的完整纹理贴图。
研究人员首先将三维网格渲染到输入图像上,然后按照4DHumans的方法对每个可见三角形进行颜色采样,从而提取部分可见的纹理图。
输入(input)
先利用一种常用的方法来推断像素到表面的对应关系,从而建立一个不完整的UV纹理图,用于从单张RGB图像中提取三维网格纹理。同时计算可见性掩码,以显示哪些像素在3D中可见,哪些不可见。
目标(target)
由于建模的目的是生成完整的纹理贴图,因此使用视频数据生成伪完整纹理贴图。
由于4DHumans可以随着时间的推移追踪人物,因此会不断更新其内部纹理图,将其表示为可见区域的移动平均值。
但为了生成更清晰的图像,研究人员发现中值滤波比移动平均法更适合生成任务;虽然该技术可以应用于任何视频中,但在本阶段使用的是2,205个人类视频,对于每段人类视频,首先从每帧视频中提取部分纹理图。
由于每段视频都包含360度的人类视角,因此从整段视频中计算出一个伪完整纹理图,并将其设置为第1阶段的目标输出,具体来说是提取视频纹理图可见部分的整体中值。
模型(Model)
研究人员直接在Stable Diffusion Inpainting模型上进行微调,该模型在图像补全任务中表现出色。
 图片
图片
输入部分纹理贴图和相应的可见度掩码,然后得到复原的人类预测贴图;锁定文本编码器分支,并始终将「真人」(real human)作为固定稳定扩散模型的输入文本。训练好的模型称为 Inpainting Diffusion
人体渲染(Human Rendering)
第二阶段的目标是获得一个模仿actor动作的人的逼真渲染效果。
虽然中间渲染(根据演员的姿势和阶段1中的纹理贴图渲染)可以反映人体的各种动作,但这些SMPL网格渲染是紧贴人体的,无法表现出服装、发型和体形的逼真渲染效果。
例如,如果输入一个女孩穿着裙子跳舞的场景,中间的渲染可能是「跳舞」,但SMPL网格渲染却无法将裙子做成动画。
为了以完全自监督的方式训练模型,研究人员假定actor就是模仿者,毕竟一个好的actor应该是一个好的模仿者;然后就可以从4DHumans中获取任意视频和姿势序列,再获取任意单帧,并从阶段1中获取完整的纹理贴图,通过在三维姿势上渲染纹理贴图来获取中间渲染图。
有了中间渲染图和真实RGB图像的配对数据后,就可以收集大量的配对数据作为条件来训练第二阶段扩散模型。
输入(Input)
首先将第1阶段生成的纹理贴图(完全完整)应用到actor的三维身体网格序列中,并对模仿者执行演员动作的过程进行中间渲染。
需要注意的是,此时的中间渲染只能反映与三维网格相匹配的服装(贴身衣物),而无法反映SMPL身体以外的纹理,如裙子、冬季夹克或帽子的膨胀区域。
为了获得具有完整服装纹理的人体,研究人员将获得的中间渲染图和人体原始图像输入到渲染扩散中,以渲染出具有逼真外观的人体新姿势。
目标(Target)
由于在收集数据时假定actor是模仿者,所以基于中间渲染图和真实RGB图像的配对数据,可以在大量数据上训练该模型,而不需要任何直接的3D监督信号。
模型(Model)
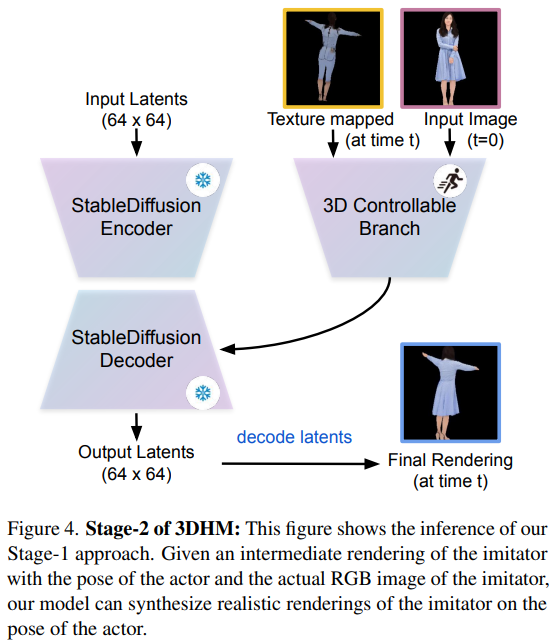
与ControlNet类似,研究人员直接克隆稳定扩散模型编码器的权重作为可控分支(可训练副本)来处理3D条件。
冻结预先训练好的稳定扩散模型,并输入噪声潜点(64×64),同时将时间t的纹理映射三维人体和原始人体照片输入到固定的VAE编码器中,得到纹理映射三维人体潜码(64 × 64)和外观潜码(64 × 64)作为条件潜码(conditioning latents)。
然后将这两个条件潜码输入渲染扩散可控分支,该分支的主要设计原则是从人类输入中学习纹理,并在训练过程中通过去噪处理将其应用于纹理映射的三维人类。
目标是从第1阶段生成(纹理映射)的三维人体中渲染出具有生动纹理的真人。
 图片
图片
通过扩散步骤程序和固定VAE解码器获得输出潜像,并将其处理为像素空间。
与第1阶段相同,锁定了文本编码器分支,并始终将「真人正在表演」(a real human is acting)作为固定稳定扩散模型的输入文本。
将训练好的模型称为渲染扩散(Rendering Diffusion)模型,逐帧预测输出。
实验结果
对比基线
用于对比的sota模型包括DreamPose、DisCo和ControlNet(姿势准确性比较)。
公平起见,所有方法的推理步骤都设为50步。
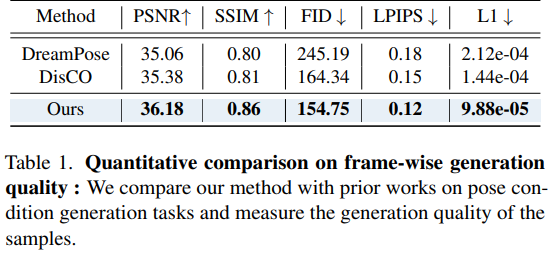
帧生成质量(Frame-wise Generation Quality)
研究人员在2K2K测试数据集上对比了3DHM和其他方法,该数据集由50个未见过的人体视频组成,分辨率为256×256。
每个人物视频拍摄30帧,代表每个未见者的不同视角,角度范围涵盖0度到360度,每12度取一帧,可以更好地评估每个模型的预测和泛化能力。
 图片
图片
从结果中可以看到,3DHM在不同指标上都优于其他基线方法。
视频级生成质量(Video-level Generation Quality)
为了验证3DHM的时间一致性,研究人员还报告了与图像级评估相同的测试集和基线实施的结果。
与图像级对比不同的是,将每连续的16个帧串联起来,形成每个未见过的人在具有挑战性的视角上的样本。
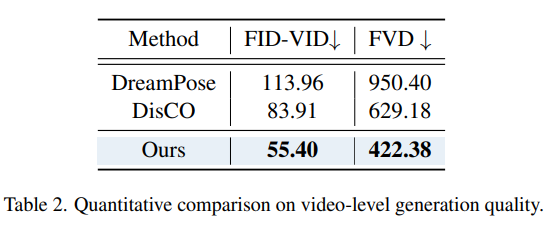
角度范围从150度到195度,每3度取一帧,可以更好地评估每个模型的预测和泛化能力。
根据50个视频的总体平均得分结果中可以看到,尽管3DHM是按每帧进行训练和测试的,但与之前的方法相比仍具有显著优势,也表明3DHM在保持三维控制的时间一致性方面表现出色。
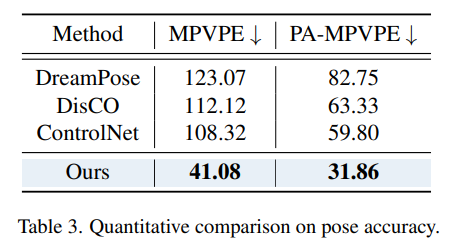
姿势准确率(Pose Accuracy)
为了进一步评估模型的有效性,研究人员首先通过先进的三维姿势估计模型 4DHumans从不同方法生成的人类视频中估计三维姿势,然后使用相同的数据集设置,并将提取的姿势与目标视频中的三维姿势进行比较。
由于ControlNet不输入图像,所以研究人员选择输入了相同的提示「真人正在活动」(a real human is acting)和相应的openpose作为条件。
 图片
图片
从结果中可以看到,3DHM能够按照所提供的三维姿势非常准确地合成出活动的人;同时,以前的方法可能无法通过直接预测姿势到像素的映射达到同样的性能。
还可以注意到,即使DisCO和ControlNet由Openpose控制,DreamPose由DensePose控制,3DHM也能在2D指标和3D指标上取得优异的结果。
参考资料:
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- fil币销毁多少了
- Filecoin网络已销毁超过5400万枚FIL,通过采用出块奖励销毁、交易费用销毁、惩罚措施销毁和治理销毁等机制实现。FIL销毁机制有助于控制FIL发行量、奖励诚实矿工、减少链上垃圾和资助网络发展。
- 8分钟前 0
-
 正版软件
正版软件
- 艾达币会有牛市吗?
- 艾达币的长期前景很有希望,受其强大的基础技术、蓬勃发展的生态系统和机构支持的推动。不过,市场波动、竞争和监管不确定性带来了潜在挑战。因此,需注意加密货币的波动性并谨慎投资。
- 18分钟前 0
-
 正版软件
正版软件
- 加密货币哪个软件好用
- 市面上最用户友好的加密货币软件包括:Coinbase:适合初学者,界面直观、安全可靠、支持多种加密货币。Binance:适合交易员,交易平台功能强大、费用低、币种丰富。Crypto.com:提供多元化金融服务、用户奖励、移动友好。Exodus:非托管钱包,安全性高、易于使用、支持多个资产类型。TrustWallet:移动设备专用非托管钱包,多币种支持、去中心化。
- 33分钟前 0
-
 正版软件
正版软件
- 谷歌员工爆料Python基础团队原地解散
- 什么?谷歌解雇了整个Python基础团队?与你直接共事的每个人,包括你的上级,都被裁员——哦,是职位被削减,而你被要求安排他们的替代者入职。这些人被告知在不同的国家担任同样的职位,但他们并不为此感到高兴,这是很艰难的一天。发布这一动态的ThomasWouters,简介是「Google员工、Python指导委员会、Python3.12和3.13的发布主管」。这个消息惊动了领域内的很多开发者,包括PyTorch创始人、Meta杰出工程师SoumithChintala:被讨论最多的,当然是裁撤的原因。谷歌并没有
- 48分钟前 AI 训练 0
-
 正版软件
正版软件
- 比特币每次减半前暴跌
- 比特币减半前暴跌的原因有:矿工抛售压力、投机者套利、谨慎情绪、挖矿难度调整、历史模式。
- 1小时前 17:25 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1884天前
-
 2
2
- Overture设置踏板标记的方法
- 1721天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1711天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1909天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1875天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1871天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1886天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1907天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00